基于门控循环单元和胶囊特征的文本情感分析
2020-09-29杨云龙孙建强宋国超
杨云龙,孙建强,宋国超
(山东科技大学计算机科学与工程学院,山东青岛 266590)
0 引言
近年来,在社交媒体中发表自己的观点已变得非常流行,对社交网络文本信息中蕴涵的观点和情感进行挖掘,提取其情感的特征,可以有效地辅助决策者进行决策。许多神经网络模型在情感分析领域都取得了良好的性能,如递归自动编码器[1-2]、循环神经网络(Recurrent Neural Network,RNN)[3-4]、卷积神经网络(Convolutional Neural Network,CNN)[5-7]以及CNN-BiLSTM(Convolutional Neural Network-Bidirectional Long Short-Term Memory)网络[8]等。
对传统神经网络的优化工作也得到了研究者的广泛关注,并取得了重大进展。例如:文献[9]提出了通过批评学习用规则优化卷积神经网络的情感分析方法,文献[10]提出了基于特定目标的句子对建模模型,文献[11]提出了基于特定方面的关系分类模型。
从当前国内外文本情感分析的研究现状[12]来看,尽管以上的神经网络模型取得了很大的成功,但仍存在一些缺陷。现有的模型要求文本有正确的语法结构,使用标量来表示情绪。这就使得模型所能表达的效果是非常有限的,因为情绪及其所包含的意义是微妙和复杂的。若不能将特征向量化,即不考虑属性信息,对情感的分析将会出现偏差。因此,需要将情感词汇、否定词(例如no,not)和强度词(例如very)向量化输入到模型中,实现更精确的预测。G-Caps(Gated Recurrent Unit-Capsule)有更好的情感表达能力。
门控循环单元(Gated Recurrent Unit,GRU)[13]方法可以很好地将文本上下文特征的关联进行有效的整合,对情感文本有良好的分类效果。GRU 同时避免了传统RNN 中出现的梯度消失问题,具有更强的记忆功能。G-Caps 模型不需要人工作业的先验知识也能显示文本属性的强度。为了捕获文本的信息特征[14],G-Caps 模型将标量信息向量化,使得文本特征的表示更加丰富。实验结果证明将特征向量化的模型会产生更准确的分类效果。
1 相关工作
早期的情感分析方法大多是基于人工定义的规则,这些方法虽可以表达一定程度的情感,但需要大量人力资源。近年来,随着深度学习技术的发展,基于神经网络的方法成为主流。在此基础上,许多研究者将语言知识应用于情感分析。但这些方法无法表达文本中出现的像感情强弱这样的属性。
1.1 基于规则的情感分析
基于规则的方法[15-16]融入到模型中,以实现预测精度方面的最佳效果。文献[17]使用句子级注释的数据对简单模型进行训练,并试图对情感词汇、否定词和强度词的语言角色进行建模,从而在分类效果上得到了提升。也有从社会数据中自动构建情感词典的研究[18]。基于注意的长短时记忆(Long Short-Term Memory,LSTM)网络进行方面级情感分类[19],其核心思想是在注意机制中添加方面信息。
1.2 基于深度学习的情感分析
文献[9]提出了一种通过批判学习规则优化卷积神经网络的方法,该方法由三个关键部分组成:基于特征的预测器、基于规则的预测器和批判学习网络。批判学习网络可以判断知识规则的重要性并自适应地使用规则。文中提出的滤波器初始化策略,能够考虑复杂的规则,在情感分析方面表现出良好的性能。文献[20]提出了在循环神经网络中加入自定义胶囊模型的方法,并引入了3 个模块:表示模块、概率模块和重建模块,在传统神经网络的基础上提高了分类效果的准确率。
本文提出的G-Caps 模型,在不使用语言规则的条件下依然能表现出优异的性能。模型中的胶囊结构[21]能够将特征向量化,捕捉到能表征文本情感强度的信息,提取其中的属性特征并进行特征重组,从而对不同类别的文本进行有效的分类。
2 G-Caps模型
本文提出的模型结构如图1所示。
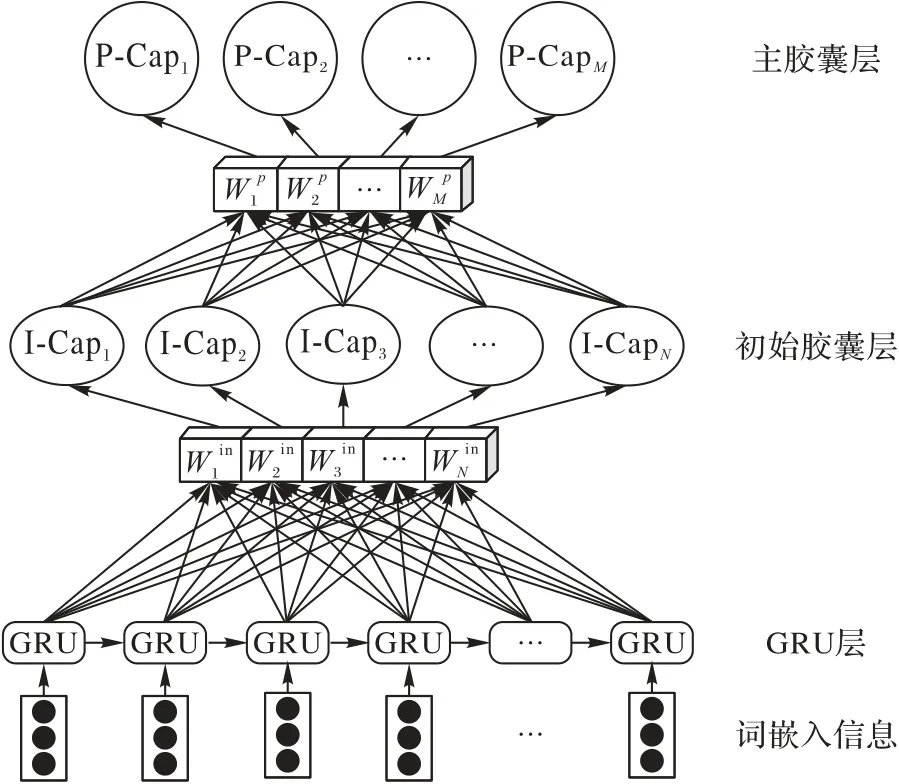
图1 G-Caps模型结构Fig.1 Structure of G-Caps model
它由三层网络结构组成:GRU 层、初始胶囊层和主胶囊层。本章会对这三层网络的关键部分进行详细的介绍。
2.1 GRU模型
GRU 解决了传统循环神经网络中出现的梯度弥散的问题,在保留了长短时记忆网络很好的记忆功能的同时,较少的参数也使得GRU的训练过程能够更快一些。
图2 展示了本文GRU 模型神经单元结构,其中有两个控制信息传输的门,分别是重置门(reset gate)和更新门(update gate)。
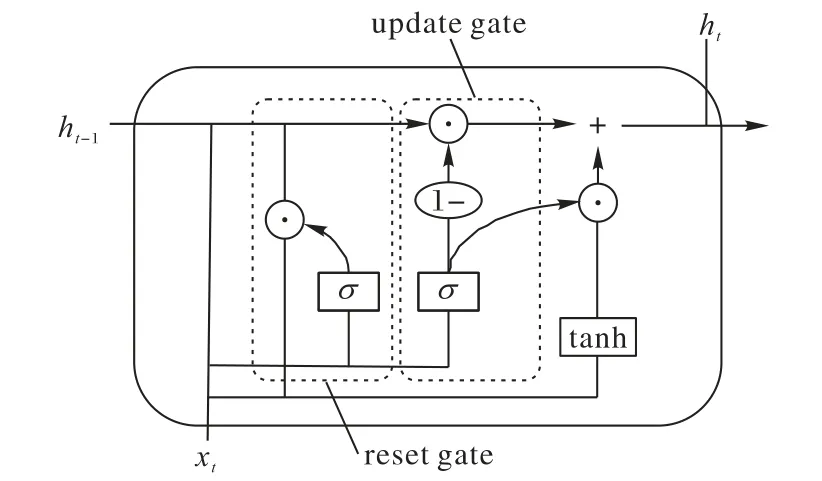
图2 GRU单元结构Fig.2 Structure of GRU cell
GRU中更新门用于控制前一时间节点的隐藏层状态ht-1保存到当前时间节点的程度。更新门接收ht-1和xt进行运算并使用激活函数处理,激活结果越大就能使越多的信息被保存。其表达式为:

2.2 初始胶囊层
初始胶囊层的作用是对GRU 层提取的整体信息进行初始的特征向量化。上层神经单元传递到本层的标量信息无法表达文本特征,但却记忆了上下文之间的语义信息。
本文使用变换矩阵Win∈RN×d×d来生成GRU 层到初始胶囊层的预测量∈Rd,并采用权重共享的方式。其中d表示的维度,N表示初始胶囊层的胶囊个数。具体地,每一个预测量的计算为:

其中gi是GRU层的标量信息,是偏倚项。
对于每个胶囊层的单元,如图3 所示,通过动态路由的方式增加或减小连接强度来表达文本中存在的特征,相较于CNN中的最大池策略更有效。在不损失具体空间信息的情况下,它能检测到在文本的不同位置是否存在相似或相同特征。

图3 动态路由过程示意图Fig.3 Process of dynamic routing
动态路由的基本思想是以迭代的方式构造一个非线性映射,以确保每个预测量发送到随后的胶囊层中适当的单元:



2.3 主胶囊层
相较于初始胶囊层使用标量信息gj|i作为输入,主胶囊层将特征向量uj作为输入,图4 中将这些输入利用动态路由算法进行特征间的重新组合,从而提取到更能表征文本特征的关键信息:
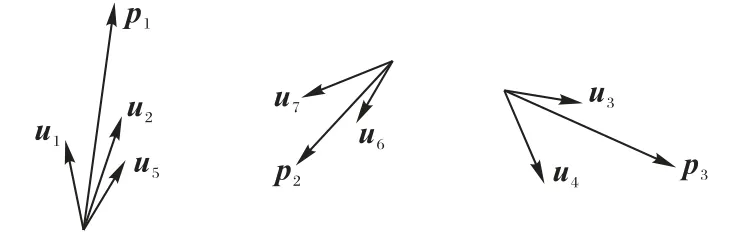
图4 特征向量间的组合Fig.4 Combinations among feature vectors
3 实验与分析
3.1 实验环境
本文的实验开发平台如下:操作系统为CentOS 7,CPU 为Intel Xeon W-2102,GPU为GTX1060,开发工具为PyCharm。
3.2 实验数据
为了评估本模型的有效性,本文使用情感分析的基准数据集MR(Movie Reviews)[22],将其中80%的数据用作训练,20%的数据用作测试。本实验使用300维Word2vec初始化文本的词嵌入信息,同时使用1E-3 学习率的Adam 优化算法来训练模型。本实验对MR数据集进行5次路由迭代,因为它优化损失更快,并在最后收敛到较低的损失。
3.3 实验参数
本文在固定其他参数的前提下,依次改变可变参数的数值,以得到使实验效果较好的最优参数。
表1 列出了GRU 层的主要参数及参数值。表2 中列出的是初始胶囊层的主要参数及参数值。表3 列出了主胶囊层的参数及参数值。为了使各个层能够自适应地进行学习,加快模型的收敛速度,本文使用Adam进行网络参数的迭代更新。
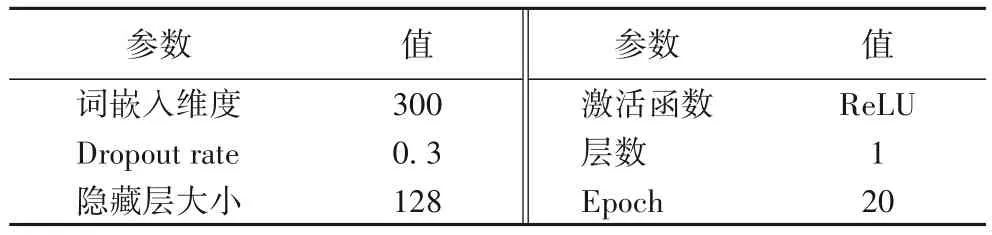
表1 GRU层参数列表Tab.1 Parameters of GRU layer
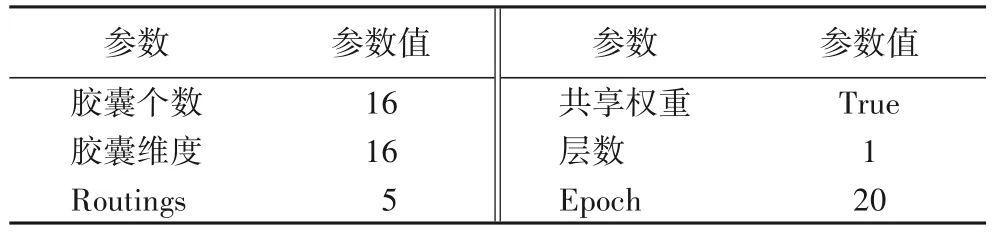
表2 初始胶囊层参数列表Tab.2 Parameters of initial capsule layer
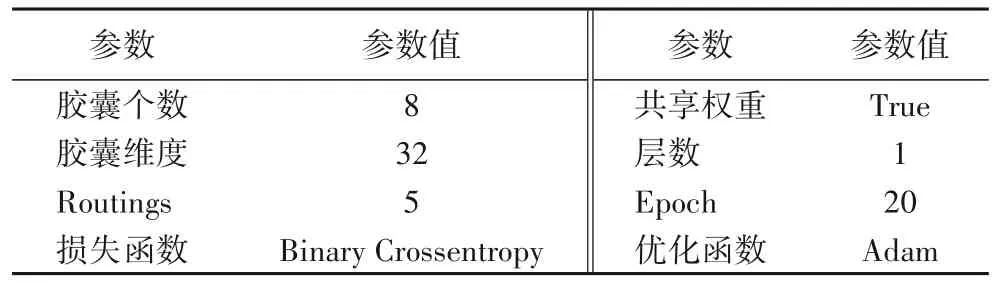
表3 主胶囊层参数列表Tab.3 Parameters of main capsule layer
3.4 实验结果及分析
为了评估本文模型在情感分类方面的效果,本文分别与传统的深度神经网络CNN_LSTM(Convolutional Neural Network_Long Short-Term Memory)[23]、BiLSTM(Bidirectional Long Short Term Memory)[24],改进后网络模型Text-CNN(Text-Convolutional Neural Network)[6]、CNN-Rule(Convolutional Neural Network-Rule)[25]、CNN+INI (Convolutional Neural Network+INItializing convolutional filters)[26]、CL_CNN(Critic Learning_Convolutional Neural Network)[9]进行了对比实验。

表4 传统模型的情感分类结果 单位:%Tab.4 Sentiment classification results of traditional models unit:%
本文在与传统神经网络结构进行比较时,相同参数的设置一致,例如Batch_size 和Epoch 等,这些参数的变化会对实验结果产生一定的影响。图5 为本文模型和传统神经网络模型的效果比较。虽然本文模型在迭代刚开始时的效果比CNN_LSTM 和BiLSTM 模型要差一些,但到了中间时刻本文模型的效果就逐渐赶超了传统的模型并稳定超过了它们。
如表4 所示,和CNN_LSTM、BiLSTM 相比,G-Caps 模型的准确率分别提高了5.3 个百分点和7.6 个百分点。本文模型将向量特征当作有效信息进行提取,对比传统网络结构模型取得了良好的分类效果。
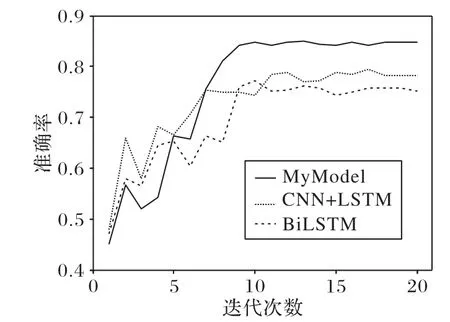
图5 与传统神经网络的比较Fig.5 Comparison with traditional neural networks
与改进后的神经网络Text-CNN 和CL_CNN 相比,本文模型有更简单的网络结构;与基于规则的网络模型CNN-Rule相比,本文模型没有定义规则时的人工的大量投入。如表5 所示,除本文模型外,分类效果最好的CL_CNN 的准确率为84.3%。G-Caps 与其相比仍高出0.5 个百分点,证明了本文提出的利用GRU 模型捕获整体上下文语义信息,之后通过胶囊从语义信息中提取到特征信息模型的切实有效性。
4 结语
本文研究了将动态路由用于文本分类的胶囊网络模型。该模型获取文本的整体信息,并通过动态路由过程进行特征提取,以达到有效的分类结果。选取基准数据集并对多个模型进行对比实验,证明了本文模型在情感分类中的有效性。下一步的工作重心,是研究本文模型在多情绪分类任务中的有效性。
