中文情感分析中的方面抽取研究
2020-09-28郭朋朋
郭朋朋
摘要:近年来,基于方面的情感分析研究受到了学术界和工业界的广泛关注。此类研究的难点在于如何抽取出情感所针对的方面。关于方面抽取的研究有很多,但这些研究往往只关注词句本身的信息,而忽略了词性所蕴含的信息。由此,该研究基于双向的长短期记忆网络、全连接网络和条件随机场提出了一种新的网络模型。该模型通过引入预训练词性向量的方法将词性信息融入模型中,这使得模型对文本信息的提取更加的全面。最后通过实验对这种方法的有效性进行了评估。
关键词:情感分析;方面;双向的长短期记忆网络;条件随机场;词性向量
中图分类号:TP391.1 文献标识码:A
文章编号:1009-3044(2020)16-0086-03
Abstract:In recent years, the research on aspect-based sentiment analysis has received extensive attention from academia and industry. The difficulty of this research is how to extract the aspects that emotions have expressed on. There are many studies on aspect extraction, but these studies often only focus on the information of the sentence, and ignore the information contained in the part of speech. Therefore, this study proposed a new network model based on bilateral long short-term memory, fully connected layer, and conditional random fields. The model also incorporates part-of-speech information into the model by pre-trained part-of-speech vector. This makes the model's extraction of text information more comprehensive. Finally, the effectiveness of this method was evaluated through experiments.
Key words: sentiment analysis;aspect;bilateral long short-term memory;conditional random fields; part-of-speech
1引言
基于方面的情感分析(Aspect-Based Sentiment Classification)是情感分析的一种,相较于基于段落(Wang et al.,2019[1]; Wu et al.,2017[2])和基于篇章(Tang and Qin,2015[3]; Rhanoui et al.,2019[4])的情感分析,基于方面的情感分析更具有挑战性。解决这一问题的前提在于如何从文本中抽取出评论针对的方面,这里所说的方面是指评论的对象。以中文商品评论为例:“手机收到了,电池很好,很耐用,外观中规中矩可以接受,就是价格有点略贵。”,在这句评论中“电池”“外观”和“价格”即是所谓的方面。针对方面抽取问题的研究方法有很多,大致可分为两类,分别是基于无监督学习的方法(Liao et al.,2019[5];He et al.,2017[6])和基于有监督学习的方法(Li and Lam,2017[7];Xu et al.,2019[8])。在这些研究中,基于神经网络的方法越来越受到研究者的青睐。这种方法的主要思路是将方面抽取任务转换成序列标注任务,通过神经网络对其进行自动标注,从而实现对方面的抽取。其中比较有代表性的研究有很多,如Li and Lam(2017)[7]利用双向长短期记忆网络(Bi-LSTM)对评论中的方面进行抽取,实验证明这种方法的抽取效果大幅度超过当时主流的条件随机场(CRF)(Lafferty,2001[9])算法。Xu等人(2019)[8]利用两次词嵌入配合多层卷积神经网络(CNN)结构来实现对方面的抽取,同样也可以取得比较好的效果。此外,还有研究者同时使用卷积神经网絡和长短期记忆网络两种神经网络用于方面抽取。
2模型介绍
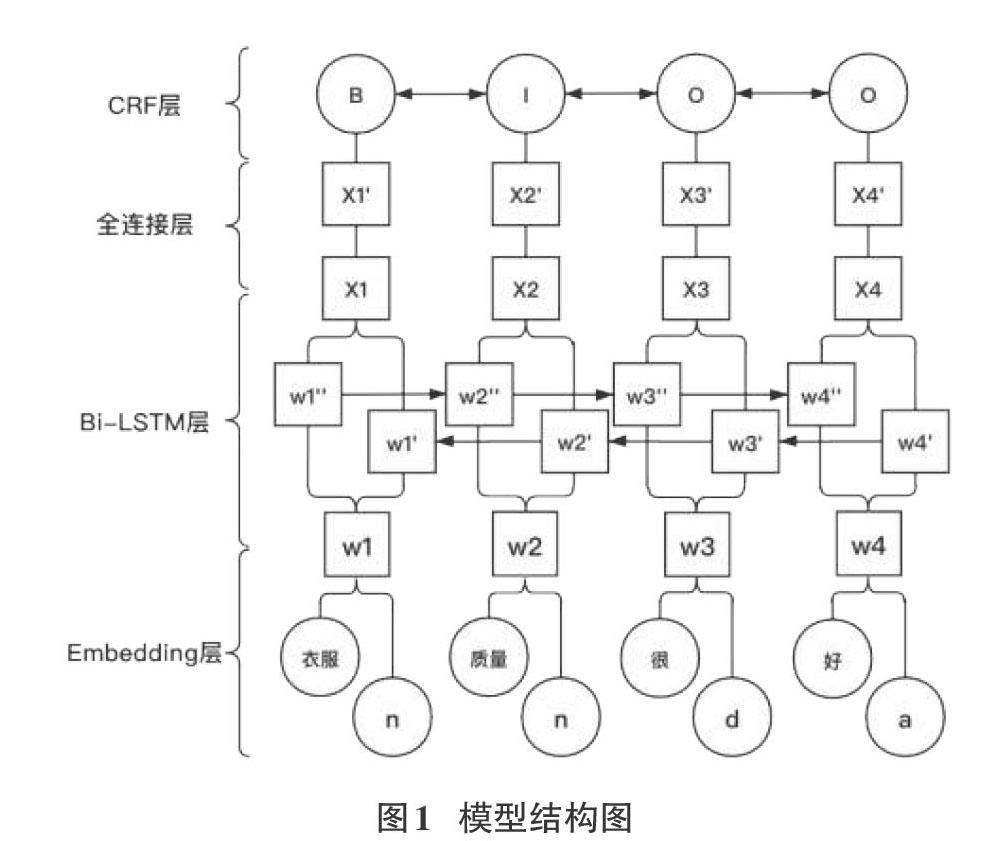
该研究提出的模型结构图如图1所示,模型分别由Embedding层、Bi-LSTM层、全连接层和CRF层组成,下面将对这些结构进行详细介绍。
Embedding层:Embedding层的作用是将词和其对应的词性进行向量化。这层的输出W由词向量和词性向量通过拼接而来。即W=(w1,w2···wn),其中wi=xi+yi,xi和yi分别代表一句话中第i个词的词向量和词性向量。这里的词性向量不是采用简单的one-hot编码获得,词性向量和词向量一样都是过word2vector预训练获得。词性向量的训练语料是文本语料对应的词性序列。
Bi-LSTM层:长短期记忆网络(LSTM)是由Hochreiter和Schmidhuber(1997)提出,单个LSTM单元是由三个门结构组成,其分别为输入门、忘记门和输出门。门结构的引入能够选择性的记住和遗忘历史信息,这能够有效的避免由于序列过长而产生的梯度消失问题。双向的长短期记忆网络(Bi-LSTM)可以同时保留前向和后向两个方向的信息,这种能力将有助于该研究对方面的抽取。
全连接层:这里只使用了一层的全连接层,所以参数W和b的形状由Bi-LSTM层输出维度和标签数决定。
CRF层:条件随机场(CRF)由Lafferty等人(2001)[9]提出,其结合了最大熵模型和隐马尔科夫模型的特点,它是一种典型的判别式模型,经常被用在序列标注类任务中。本文使用CRF替代softmax函数,这样可以为最后预测的标签添加一些约束来保证预测标签的合法性。
3试验
3.1数据集
由于没有专门的中文评论数据集,该实验通过编写爬虫程序从京东商城上抓取评论数据。为了避免单一商品数据集的局限性,该实验分别抓取了五种商品的评论数据混合后用于实验。这些商品分别为衬衫、红酒、洗衣液、手机和电脑。评论数据共计119M,进行清洗后,使用北京大学开源的分词工具pkuseg(Sun et al.,2012[10]; Xu et al.,2016[11])對其进行分词和词性标注。分词后的语料将用于词向量的训练,对应词性序列集用于词性向量的训练。此外,分别从五种商品评论中各随机挑选出500条评论,共计2500条评论用于手工标注。手工标注采用BIO方法进行标注。标注后按照6:2:2的比例随机划分训练集、验证集和测试集。
3.2模型超参数
通过多次实验,选定了模型的超参数。预训练词向量维度选定为150维,词性向量选定为50维。Bi-LSTM中的隐藏神经元个数num_units设为100,激活函数选择tanh函数。
3.3对比实验
为了验证该研究提出模型的有效性,实验添加了五组对比实验,其分别为:
Bi-LSTM+FC:模型输入只有词向量信息,模型由双向长短期记忆网络(Bi-LSTM)和全连接层(FC)构成。
POS(one-hot)+Bi-LSTM+FC:模型输入除了词向量信息以外还添加了词性信息,词性向量采用one-hot离散表示,模型由双向长短期记忆网络(Bi-LSTM)和全连接层(FC)构成。
POS(word2vector)+Bi-LSTM+FC:模型输入除了词向量信息以外还添加了词性信息,词性向量通过word2vector预训练得到,模型由双向的长短期记忆网络(Bi-LSTM)和全连接层(FC)构成。
Bi-LSTM+FC+CRF:模型输入只有词向量信息,模型由双向长短期记忆网络(Bi-LSTM)、全连接层(FC)和条件随机场(CRF)构成。
POS(one-hot)+Bi-LSTM+FC+CRF:模型输入除了词向量信息以外还添加了词性信息,词性向量采用one-hot离散表示,模型由双向长短期记忆网络(Bi-LSTM)、全连接层(FC)和条件随机场(CRF)构成。
3.4试验结果及分析
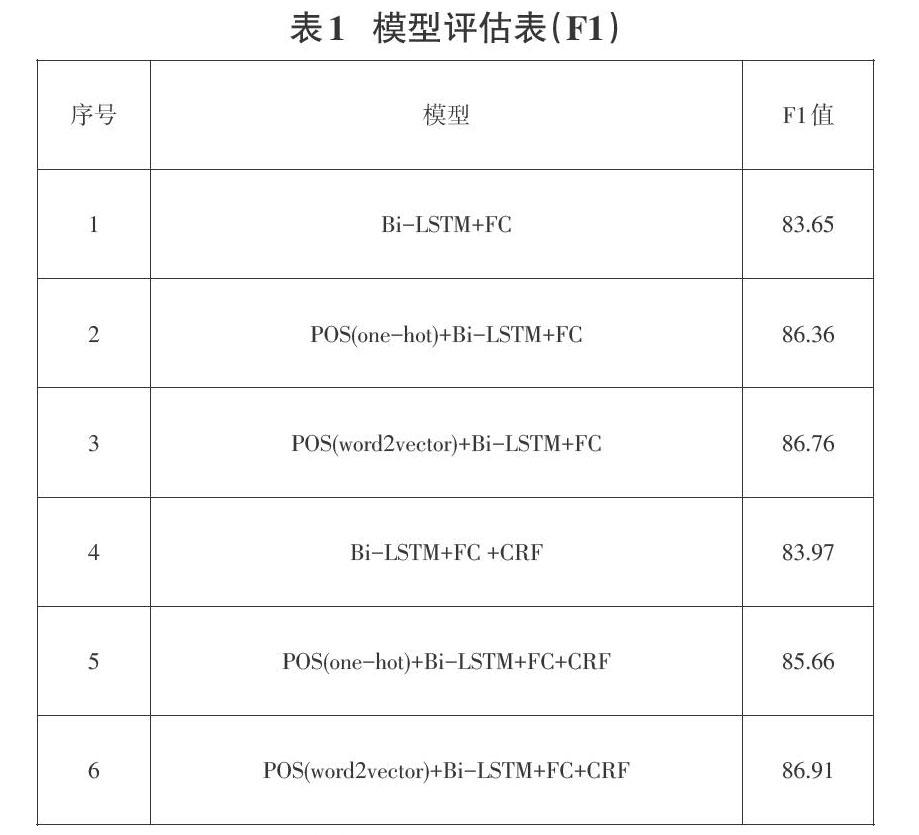
各模型F1评估值如表1所示,其中前五组模型为对照模型,模型6为该研究提出的模型。
通过观察模型评估值F1可以发现,模型2和模型3的F1值都明显高于模型1,模型5和模型6的F1值都明显高于模型4。两类基础模型在添加了词性信息后,F1值都有很大的提升,这说明在模型中引入词性信息是有效的。模型3的F1值高于模型2,模型6的F1值高于模型5,这说明采用预训练词性向量引入词性信息的方法比采用one-hot方式获得的词性向量引入词性信息的方法更为有效。同时,相较于前5个对照模型,该研究提出的模型抽取效果最佳,F1值可达86.91。
4 结论
在中文方面抽取任务中,该实验基于双向长短期记忆网络、全连接网络和条件随机场构建的网络模型在融入预训练的词性信息后,其模型性能优于普通的双向长短期记忆网络模型。
参考文献:
[1] Hao Wang,Bing Liu,Chaozhuo Li,et al.Learning with Noisy Labels for Sentence-level Sentiment Classification[C]//Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Hong Kong, China: Association for Computational Linguistics,2019: 6285-6291.
[2] Fangzhao Wu, Jia Zhang, Zhigang Yuan,et al.Sentence-level Sentiment Classification with Weak Supervision[C]//SIGIR '17: The 40th International ACM SIGIR conference on research and development in Information Retrieval. Tokyo,Japan: Association for Computing Machinery,2017:973-976.
[3] Duyu Tang, Bing Qin, Ting Liu. Learning Semantic Representations of Users and Products for Document Level Sentiment Classification[C]//S Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing. Beijing, China: Association for Computational Linguistics,2015: 1014-1023.
[4] Maryem Rhanoui, Mounia Mikram, Siham Yousfi,et al. A CNN-BiLSTM Model for Document-Level Sentiment Analysis[J]. Machine Learning and Knowledge Extraction, 2019,1(3):832-847.
[5] Ming Liao, Jing Li, Haisong Zhang,et al. Coupling Global and Local Context for Unsupervised Aspect Extraction[C]//Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Hong Kong, China: Association for Computational Linguistics, 2019: 4578-4588.
[6] Ruidan He, Wee Sun Lee, Hwee Tou Ng,et al.An Unsupervised Neural Attention Model for Aspect Extraction[C]//Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics. Vancouver, Canada: Association for Computational Linguistics,2017:388-397.
[7] Xin Li, Wai Lam. Deep multi-task learning for aspect term extraction with memory interaction[C]//Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. Copenhagen, Denmark: Association for Computational Linguistics, 2017:2886–2892.
[8] Hu Xu, Bing Liu, Lei Shu,et al.Double Embeddings and CNN-based Sequence Labeling for Aspect Extraction[C]//Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics. Melbourne, Australia: Association for Computational Linguistics,2019:592-598.
[9] Lafferty J D, Andrew McCallum,Pereira F C N. Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data[C]//Proceedings of the Eighteenth International Conference on Machine Learning. San Francisco, United States: Morgan Kaufmann Publishers,2001: 282-289.
[10] Xu Sun, Houfeng Wang, Wenjie Li. Fast Online Training with Frequency-Adaptive Learning Rates for Chinese Word Segmentation and New Word Detection[C]//Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics. Jeju Island, Korea: Association for Computational Linguistics, 2012:253-262.
[11] Jingjing Xu, Xu Sun. Dependency-based Gated Recursive Neural Network for Chinese Word Segmentation[C]//Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics. Berlin, Germany: Association for Computational Linguistics, 2016: 567-572.
【通聯编辑:朱宝贵】
