基于卷积神经网络的人脸表情识别
2020-09-28姚梦竹黄官伟
姚梦竹 黄官伟

摘要:表情识别在医学、商业和刑事侦查等领域中有着广泛的应用前景。针对表情识别技术的研究历时半个世纪,经历了由传统的手工提取特征向卷积神经网络自动提取特征的飞跃。卷积神经网络由于其自学习能力因而得到了广泛应用,但仍存在训练时间过长、参数量过大等问题。该文针对以上问题,在Xception神经网络的基础上简化了模型的网络层级,删除了传统神经网络的全连接层并使用深度可分离卷积替代传统的卷积层,构造了mini-Xception网络模型。通过在Fer2013公开人脸表情数据集上进行实验,取得了66%的识别精度。改进后的模型显著降低了训练参数量并缩短了训练时间,提高了模型的泛化能力。
关键词:表情识别;卷积神经网络;批量归一化;图像分类
中图分类号:TP18 文献标识码:A
文章编号:1009-3044(2020)16-0019-05
开放科学(资源服务)标识码(OSID):
Abstract: Facial expression recognition has a broad application prospect in the areas such as medicine, business and criminal investigation. The research on facial expression recognition has been going on for half a century, the manual feature extraction has been improved to the automatic feature extraction based on the convolutional neural network (CNN). CNN has been widely used due to its self-learning characteristics, but there are still some problems such as too long training time and too many parameters. Aiming at the above problems, this paper simplifies the construction of the model Xception Neural Network, removes the full connection layer and uses the depthwise separable convolution to construct the model Mini-xception. Good results have been achieved on the DataSet Fer2013. The new model reduces the number of parameters and the training time, which contributes to the stronger generalization ability of the model.
Key words: facial expression recognition;convolutional neural network; batch normalization; image classification
1 背景
人类的面部表情是其最直接有效的情绪表达方式,人脸表情在医学诊断、刑事侦查以及日常的人际交往中扮演着重要的角色。针对表情识别技术的研究被认为是未来人机情感交互的主要发展方向[1]。美国的心理学家Ekman和Friesen [2]经过大量的实验与测试后,将人类的表情定义为以下六类:生气(Angry)、厌恶(Disgust)、恐惧(Fear)、高兴(Happy)、悲伤(Sad)和惊讶(Surprise)。伴随着信息技术的飞速发展,国内外研究者针对人脸表情识别技术提出了许多新的研究方法。针对人脸面部表情的研究为人工智能注入了全新血液,已成为计算机视觉领域的研究热点。从20世纪70年代至今,表情识别经历了由手工提取特征到计算机自动提取特征的创新性变革,这一变革是表情识别研究的一次飞跃[3]。
人脸表情识别的主要框架分为三个步骤:图像预处理、特征提取和表情分类,如图1所示。
图片预处理实现了图片大小及色彩的调整,使计算机读入的图片更易被处理。通过图像的预处理,可以尽量消除光照、角度等无关因素对模型的影响。图片经处理后再输入模型进行训练,可大大提高模型识别的精确度。特征提取是指利用计算机对图像中包含的信息进行提取,获取能够表征该图像所属类别的属性信息。由于最终的分类环节是基于提取到的特征组合来对图像进行分类,所以从训练集中提取的特征在表情分类中扮演着至关重要的角色。早期的研究使用传统的手工特征提取方法,主要有局部二值模式(LBP)、梯度方向直方图(HOG)、主成分分析法(PCA)等。LBP将局部特征进行比较,并通过图像的局部灰度变化关系来表征图像的局部纹理特征[4]。LBP能避免光照不均、图像移位等带来的影响,有效地表征图像纹理信息,且运算速度快;但是,LBP对图像噪聲的敏感度高,并且没有考虑到中心像素与邻域像素的差值幅度,导致数据信息的部分丢失。Albiol[5]等人于2008年提出了HOG-EBGM算法,该算法使用HOG描述符,采用了尺度变换和图像旋转的不变性。该算法对较微小的位移、光照不均及面部旋转角度等具有更好的鲁棒性。手工提取特征会提取到对分类结果无意义的特征,或忽略了对分类结果影响较大的特征,为解决这一难题,基于卷积神经网络的人脸表情识别便应运而生。
2 卷积神经网络概述
卷积神经网络是受到生物学视觉系统的感受野机制的启发而提出的,即一个神经元只接受其所支配的刺激区域内的信号。经过近半个世纪的研究,卷积神经网络已从早期的理论原型发展成为可投入到实际应用的网络模型。标准的卷积神经网络由输入层、数个卷积层、池化层和全连接层堆叠而成,如图2所示。
卷积神经网络中包含多层结构,并通过反向传播来揭示海量数据中的复杂关系。其具有局部连接、子采样和权重共享的特征,这些特征使得神经网络能够在平移的过程中维持高度不变,并在缩放和旋转的过程中具有一定的不变性。
1998年LeCun[6]等人提出了LeNet-5网络,该网络架构由2层卷积层和3层池化层构成,已成为标准的“模版”,主要应用于手写数字的识别和图像分类等较为单一的任务。2012年Alex Krizhevsky 等[7]在LeNet-5网络架构的基础上堆叠了更多层,并首次采用 ReLU 作为激活函数,建立了AlexNet神经网络。该模型在海量图像的分类研究中取得了重大进展。传统的卷积操作是将通道相关性与空间相关性进行联合映射,Szegedy等[8] 假设卷积通道相关性和空间相关性可进行退耦,将二者分开映射,提出了Inception模块的方法。每个Inception模块内使用不同过滤器的并行卷积塔进行堆叠,降低网络的复杂程度。该神经网络中采用1*1, 3*3和5*5的卷积核对特征进行提取,降低了网络中训练参数的数量,以此来提高神经网络内部计算资源的利用率。Inception模型经过改进后,将所有1*1的卷积层进行拼接,增加其中3*3的卷积分支数量,使其与1*1的卷積通道数量相等,由此得到Extreme Inception,如图3所示。
2016年Chollet等[9]在Inception模型的基础上提出进一步的假设,即神经网络的通道相关性与空间相关性是可完全分离的,并使用深度可分离卷积[10]来替换Inception中的模块,由此得到Xception网络结构。Xception与Extreme Inception极为类似但略有不同。前者先对每个信道的空间性进行常规卷积,再对每个信道进行1*1的逐点卷积。在每一次卷积操作后都加入批量归一化BN[11]层和激活函数ReLU。中间部分的模块则采用残差相连的方式,减少神经网络的训练难度。其结构如图4所示。
2.1 深度可分离卷积
深度可分离卷积将传统的卷积操作分解成一个深度卷积和一个1*1的逐点卷积。若输入的特征图的大小为[DF*DF*M],输出的特征图的大小为[DF*DF*N],卷积核为[DK*DK],则传统的卷积操作的计算量为[DK*DK*M*N*DF*DF];深度可分离卷积的总计算量为[DK*DK*M*DF*DF+M*N*DF*DF]。二者的计算量之比为[1N+1D2K],大大地降低了神经网络中的参数量。
2.2 Batch Normalization层
当网络的层级结构较多时极易出现网络训练的收敛速度变慢等情况。Xception模型在网络的每一层输入之前插入一个归一化BN层,对上一层输出的数据先做归一化处理再送入下一层。BN层可将每层输入的数据分布控制在均值为0,方差为1的范围内,保证数据的稳定性,可有效地避免因输入数据分布的变动导致的过拟合问题。其公式为:
2.3 ReLU 激活函数
激活函数的应用可提高神经网络的非线性建模的能力,增强模型的表达能力,以此来提高神经网络的分类精确度。Relu 函数属于非饱和函数。当函数的输入为正值,输出值与输入值成线性关系,导数为1,无梯度弥散现象,能够解决饱和函数的“梯度消失”问题,可加快收敛速度。ReLU激活函数为:
2.4 Softmax层
Softmax回归模型是在Logistic回归应用于多分类问题上的推广,Xception网络架构使用Softmax层在神经网络中对表情进行分类。在Softmax中将x分为j类的概率为:
其中,[Pyi=j|xi;θ]是图像x对应于每个表情分类j的概率,[θ]为待拟合参数。
2.5 参数优化
本文在模型训练过程中使用Adam优化器[12]动态地调整学习率。Adam算法具有梯度对角缩放的不变性,适用于处理含有大量参数的问题,且在训练过程中只需要进行少量的手动调整。其参数更新公式为:
其中,[θ]为待更新的参数,[η]为学习率,[mt] 为梯度第一时刻的均值,[υt] 为第二时刻的方差。
3 基于卷积神经网络的表情识别
在构建神经网络模型时,首先要对输入的图像数据进行预处理操作。由于输入的原始图像可能存在光线不均、角度偏移等问题,因此在输入卷积神经网络进行训练前,要先对图像进行光照补偿、角度仿射变换和人脸位置检测等预处理。本文采取Fer2013数据集[13],由35887张人脸图片组成,均为48×48的灰度图像。其中有4953张angry图片,547张disgust,5121张fear,8989张happy,6077张sad,4002张surprise,6198张neutral,分别对应数字标签0-6。
3.1 图像预处理
3.1.1 光照补偿
本文采用对图像进行灰度直方图均衡化处理来削弱光照对图像的影响。经过均衡化处理的图像,其像素尽可能均衡地分布于尽可能多的灰度等级。直观来看,就是对图像的灰度直方图进行拉伸,使其像素分布尽可能均匀,如图5所示。
3.1.2 数据增强
Fer2013数据集是在非实验环境下获取的,其数据量相对于CK+等其他表情数据集更大,且样本更符合自然状态下的人脸表情,但当中包括了很多遮盖、侧脸和角度倾斜等干扰因素,并且存在许多非人脸的图像。对Fer2013进行数据增强,即对一张人脸进行镜像、旋转处理。其参数如表1所示。
3.2 构建CNN
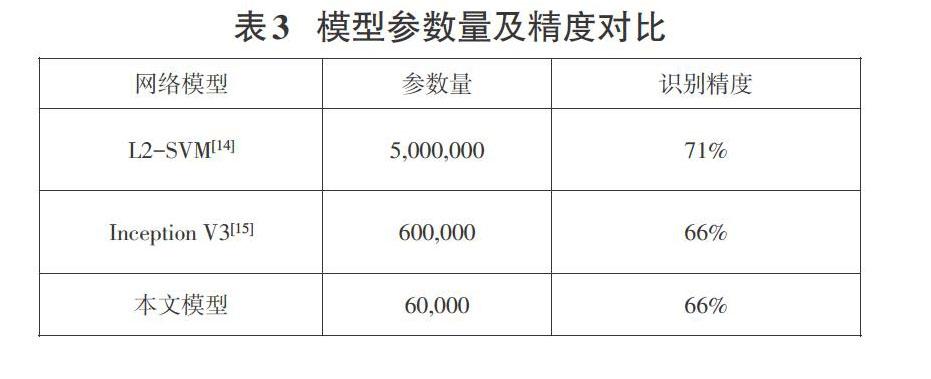
输入的数据通过卷积层提取特征,再经由池化层对提取到的特征进行降维,最终由全连接层将降维后的特征“连接”起来进行分类。对于多分类问题而言,增加其中间的隐藏层可提高分类精度,但与此同时其训练时间也会显著变长。由于本文的研究对象都是48*48的灰度图像,且数据库规模较小,分类级别只有七种,因此选择较为简单的网络模型。本文在Xception网络结构的基础上简化了卷积层的模块数量,并删除了最后的全连接层,构建了一个mini-Xception模型。具体参数如图7所示。
本文的Mini-Xception由4个模块组成,共有11个卷积层,其中包括8个深度可分离卷积和3个常规卷积。除去第一个常规卷积模块外,其余部分采用残差连接的堆叠结构。最后一个卷积层后连接全局平均池化层,须设置参数,对每一通道的特征图取其均值作为最终的输出值。在每个卷积层后都加入批量归一化BN和ReLU激活函数,减少因每层输入分布的变动导致的过拟合问题,提高模型的泛化能力。本网络均采用了1*1或3*3的小卷积核,加强对表情特征的提取能力,并删除了传统网络的全连接层。经过Softmax 激活函数的处理后,最终的输出为一个7维的特征向量,分别对应7种表情分类。
4 实验结果
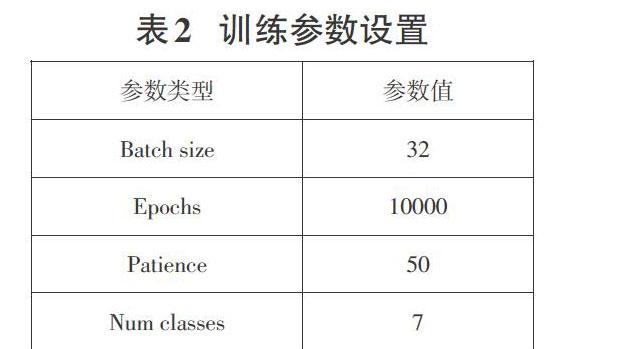
本文的研究基于Keras深度学习平台,采用经预处理的Fer2013表情数据集作为训练模型。随机抽取测试集的20%作为验证集,剩余部分作为训练样本,且训练集与验证集的样本数据无交叉。其训练参数设置如表2所示。
表4为本文模型表情识别的混淆矩阵。Mini-Xception对happy的识别率可达87%,而对scare的识别度最低,仅为41%。在识别过程中可以观察到,sad和scare, angry和disgust 的识别难度较大。CNN提取到了能被理解的人脸表情特征信息,这些信息帮助CNN对捕获的人脸的情绪进行预测。angry和disgust具有相似的眉毛特征和皱起的嘴角,易产生错误分类。戴眼镜的人常被错误地分类为angry或scare, 因为深色的眼镜框常与这两种表情特征下的皱眉混淆;另外,由于眉毛上扬角度相似,happy和surprise也常被混淆。并且,在使用经过滤镜美化的非自然状态下的图像进行识别时,其结果往往与肉眼所见大相径庭。这也证明,人类的表情非常复杂,其种类并不止宏观划分的7种,表情识别是一种复杂且模糊的研究。
5 结束语
表情识别是情感识别的重要部分,该技术具有巨大的应用价值,是人工智能发展的热点方向。本文介绍了目前最新的神经网络模型Xception,并对该模型的精简版进行了实现,取得了一定的效果。当然,本研究仍有提高的空间,比如对Fer2013数据集中的非人脸样本等噪声数据进行清洗,对错误标注的表情分类进行修正,利用仿射变换将人脸进行对齐等。将来的研究会对Fer2013数据集上的样本优化及适用于其他类似数据集的网络模型进行研究。
参考文献:
[1] Zeng Z H, Pantic M, Roisman G I, et al. A survey of affect recognition methods: audio, visual, and spontaneous expressions[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2009, 31(1): 39-58.
[2] Ekman P, Friesen W V. Constants across cultures in the face and emotion[J]. Journal of Personality and Social Psychology, 1971, 17(2): 124-129.
[3] 徐琳琳, 張树美, 赵俊莉. 构建并行卷积神经网络的表情识别算法[J]. 中国图象图形学报, 2019, 24(2): 227-236.
[4] Ojala T, Pietik?inen M, Harwood D. A comparative study of texture measures with classification based on featured distributions[J]. Pattern Recognition, 1996, 29(1): 51-59.
[5] Albiol A, Monzo D, Martin A, et al. Face recognition using HOG–EBGM[J]. Pattern Recognition Letters, 2008, 29(10): 1537-1543.
[6] LeCun Y, Bottou L, Bengio Y, et al. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998, 86(11): 2278-2324.
[7] Krizhevsky A, Sutskever I, Hinton G E. ImageNet classification with deep convolutional neural networks[J]. Communications of the ACM, 2017, 60(6): 84-90.
[8] Szegedy C, Liu W, Jia Y Q, et al. Going deeper with convolutions[C]//2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 7-12, 2015. Boston, MA, USA. IEEE, 2015:1-9.
