基于多现场可编程门阵列异构平台的流水线技术优化方法
2020-09-28胡延步邵翠萍李慧云
胡延步 邵翠萍 李慧云
1(中国科学院深圳先进技术研究院 深圳 518055)2(西安电子科技大学 西安 710071)
3(中国科学院人机智能协同系统重点实验室 深圳 518055)
4(粤港澳人机智能协同系统联合实验室 深圳 518055)
1 引 言
随着大数据、人工智能等领域[1-2]的发展,数据的产生量、存储量和运算量都在飞快地发展。另一方面,摩尔定律的持续放缓使得传统中央处理器(Central Processing Unit,CPU)难以满足人工智能领域的高算力要求。而异构计算[3]融合了不同的芯片架构,如 CPU、现场可编程门阵列(Field Programmable Gate Array,FPGA)、图形处理器(Graghics Processing Unit,GPU)、专用集成电路等。整个异构平台通过合理地控制与分配运算使得架构中的芯片各专所长,从而构成了强大的异构计算系统。与 GPU 相比,FPGA[4-5]的功耗更低,不仅能利用硬件单元进行并行计算,同时还具有可编程的优点,故比专用集成电路更具灵活性。将 FPGA 与嵌入式 CPU 相结合,可以有效补充 CPU 算力不足与功耗高的问题。以赛灵思(Xilinx)和英特尔为代表的 FPGA 厂商[6]在认识到异构计算的重要性后,纷纷推出搭建安谋架构的 CPU(ARM)+FPGA 的片上系统异构芯片。但在运行日益复杂的深度学习模型时,单块 FPGA 芯片[7-9]往往会出现硬件资源不足的情况,而在追求高算力和低功耗的深度学习推理模型下,多 FPGA 异构平台成为了一种新的探索目标和解决方案。
多 FPGA 异构平台中,ARM 负责多 FPGA 的控制与调度。目前国内外常用的多 FPGA 异构控制方法为并行控制、分布式控制和流水线控制。与并行控制和分布式控制相比,流水线控制在控制逻辑上更简单,也更符合深度学习算法推理的数据流过程。但国内外在 FPGA 板之间分配算法任务等流水线问题仍缺乏系统性方法。首先,在任务划分方面,大多数案例仅依据算法中运算量大的层级,如卷积神经网络(Convolutional Neural Network,CNN)的卷积层,进行简单的主观划分。因此,需要多次划分比较甚至遍历才能获得理想的流水线平衡,同时这也限制了获得更优良流水线性能及吞吐率的可能。例如,Morisita 等[10]设计的多 FPGA 平台由于任务不均衡导致其流水线利用率仅 60%。其次,在通信延迟方面,Yoshimi 等[11]构建了超长的流水线结构,但并未考虑板间传输延迟造成的显著影响,故而吞吐率不高;Guo 等[12]虽然针对特定任务进行了合理划分与部署,但由于缺少通用性且通信方案固定,因此限制了流水线优化的灵活性。此外,在模块内优化方面,大多数研究在使用高层次综合(High-level Synthesis,HLS)工具进行 FPGA 板内模块开发时,并未充分利用数据关系与循环流水线技术进行并行加速设计。
本文通过搭建多 FPGA 流水线异构平台,充分发挥多 FPGA 与流水线技术的优势,以提高异构平台的吞吐率。具体地,从三方面对多 FPGA 异构平台的流水线技术进行优化:①利用二分法将任务划分问题求解难度降低,并将任务均衡地划分部署到各 FPGA 中,从而提高了流水线的平衡度;②根据板间传输延迟的相对大小优化流水线结构,若延迟较小或任务运行延迟较大则将板间延迟加入流水线的级内,反之则将板间延迟作为模块级流水线的单独一级;③并行优化计算单元模块,考察任务中多层嵌套循环的数据关系并重新部署代码结构,通过使用循环展开与循环流水线技术在时间和空间上进行并行加速,同时合理使用 FPGA 内的块级随机访问存储器(BlockRAM,BRAM)以优化访存。
2 背 景
2.1 异构计算
异构计算是指使用不同体系结构的硬件设备或不同类型指令集的硬件设备组成一个系统进行计算的方法。使用异构系统将不同的计算任务交由不同的平台处理,可以充分发挥各类设备的优势,以获得更高的计算性能。
常见的异构计算平台[13]包括 GPU、FPGA 和数字信号处理器等。GPU 具有多核多线程、高度并行、高存储带宽等特点,在高性能计算中的应用日益广泛。2019 年超威公司推出了更为先进的 Zen 2 架构[14],进一步提升了 GPU 性能,此应用处理器更是实现了异构系统的单片化,将 CPU 和 GPU 集成于同一芯片上,大幅缩减了主机与从机间数据传输的时间。FPGA 作为一种可编程器件,于 2012 年正式加入异构计算的行列。从硬件架构上来看,FPGA 与异构计算加速设备的平台模型没有明显的对应关系,但可编程的优点使其成为一种更加灵活的异构计算平台。例如,在处理分支跳转指令时,FPGA 采用逻辑电路同时执行各个分支语句,而 GPU 则需要串行处理不同分支语句。异构计算作为面对大规模处理任务时的通用解决方案,已经部署应用于越来越多的场合中。异构计算一般由一组异构机器、将各异构机器连接起来的高速网络及相应异构计算支撑软件组成。
2.2 多 FPGA 异构平台
由于单板 FPGA 片上计算资源与高速缓存较少,在运行规模庞大的算法任务时不能满足高性能和高能源效率的要求,因此搭建多 FPGA 异构平台成为一种需要。多 FPGA 异构平台具有不同的布置与处理方式,如分布式计算平台与并行计算平台。Lin 等[15]和林常航等[16]提出基于 Zynq 开发板的 Hadoop 集群 Z Cluster。该平台整体采取主从结构,由 1 台 PC 机作为主设备(用作任务调配和对外通信),8 块 Zynq 板作为从设备(用作并行计算的运行设备)。这种 ARM+FPGA 的模式既能在一定程度上弥补嵌入式处理器计算能力不足的缺陷,又能发挥其低功耗的优势,组成具有较好拓展性及较高性能的分布式计算环境。Neshatpour 等[17-18]提出一种由一个主设备和多个从设备共同组成的并行计算平台。其中,该平台的主设备采用台式机(负责任务的分配和调度),从设备是 Zedboard(负责被分配任务的计算,并将计算的结果反馈给主设备进行综合处理),二者通过 PCIe 相连。
分布式计算平台适合用于同时计算不同的算法任务,而并行计算方式适合用于分支结构复杂的算法任务。但是,这两种方式并不适合数据流形式的深度学习推理,因而在多板控制上应用流水线技术[19-20]成为最佳选择。与多周期方式相比,流水线处理方式在连续运行的情况下极大地提高了吞吐率。但在应用流水线技术设计多 FPGA 平台时,仍存在较多问题,如任务划分问题、流水线结构问题和板内设计问题。
3 基于多 FPGA 异构平台流水线技术的优化方法
本文采用的多 FPGA 异构流水线方式[21]如图 1 所示。首先,把每个 FPGA 节点作为流水线的一级,使用 RapidIO 对板间的传输进行连接,并通过片内 AXI 总线将中间数据传输到 SRIO 的 IP 核进行编码打包;然后,通过 GTX 协议,在物理层上以 SFP+的光纤接口连接到下一个 FPGA 节点的 SFP+光纤接口中;最后,通过 SRIO 核进行解码,恢复出传输的数据并送到该节点 FPGA 计算单元中。
本文针对基于多 FPGA 异构的流水线平台,进行如下整体设计与优化方案:①对整体的总任务进行划分并将划分后的各个子任务部署在多 FPGA 节点之中;②针对不同 FPGA 节点板间传输延迟的影响,对流水线结构进行优化;③优化部署后对不同 FPGA 节点内负责执行各子任务的计算单元进行并行加速优化设计。
3.1 多 FPGA 的任务划分方法
任务划分的目的是平衡各 FPGA 的流水线以最大化吞吐率。具体地,先拆分任务层级结构,再将拆分的多个子层级划分部署于多个 FPGA 节点中。假设对于一个任务网络(如 CNN 网络),在不破坏网络层级结构的前提下,按照该任务的层级结构将网络拆分为多个细小的子层级,若数量为m,按照网络的运行顺序分别表示为M1,M2,…,Mm,则m个子层级的相应运行延迟为L(Mi),其中i=1, 2, …,m,而这些排列好的L(Mi)组成数组M。当 FPGA 节点内部使用近似并行优化策略时,各子层级的运行延迟与运算量近似成正比。因此,任务划分即为优化板级流水线结构,亦即将流水线中最长的一级延迟降至最低,同时也是将任务量尽量均衡地部署在多 FPGA 中。对于任务划分问题,有多种方法可求解。为了适配问题求解的通用性与易用性,需要设计一个对任意数组M以及 FPGA 节点数K进行自动计算划分结果的程序或方法,因此本文提出任务二分迭代法。
二分法是单调函数求根中的常用方法,其基本思想是利用零点定理确定根的存在区间,将含根的区间对分,通过判别对分点函数的符号,将有根区间缩小一半。然后,重复以上过程,将根的存在区间缩到充分小,从而求出满足精度要求的根的近似值。二分法寻根具有计算量低的优势,同时,二分法的引入是为了通过迭代方式逐步求得每个 FPGA 应该部署到哪些子层级中。为达到这一目标还需引入约束值LM,其中LM的引入是对 FPGA 设备运算量部署/运行延迟进行约束或参考。由于数组M的元素都是正数,如果以元素的角标作为函数x的自变量、以元素的累加和减去约束值LM作为函数因变量f(x),那么离散函数f(x)就构成了单调递增函数,这符合利用二分法求值的前提。
首先设置约束值LM,再根据二分法使选取子层级的运行延迟L(Mi)之和尽可能接近LM,即做出了 1 次单次划分。由于每次单次划分后的结果相对约束值存在一定的偏差,因此在每次单次划分后需要不断迭代上述过程,最终得出一个优良的任务划分结果,因此该法称为任务二分迭代法。 设运算量/执行延迟最大的子层级为Mt,其对应的执行延迟为L(Mt),则LM表示为:


3.2 针对板间延迟的流水线结构优化
在多 FPGA 系统中应用流水线,不可避免地要考虑板间传输延迟的影响。由于板间传输延迟与任务划分部署结果及板间通信方案均有关,因此为了探索不同场景下板间传输延迟的影响及其应对方法,提出 2 种针对板间延迟的流水线结构优化方案:(a)将板间延迟加入到板内作为流水线的一部分;(b)将板间延迟单独作为流水线的一级。

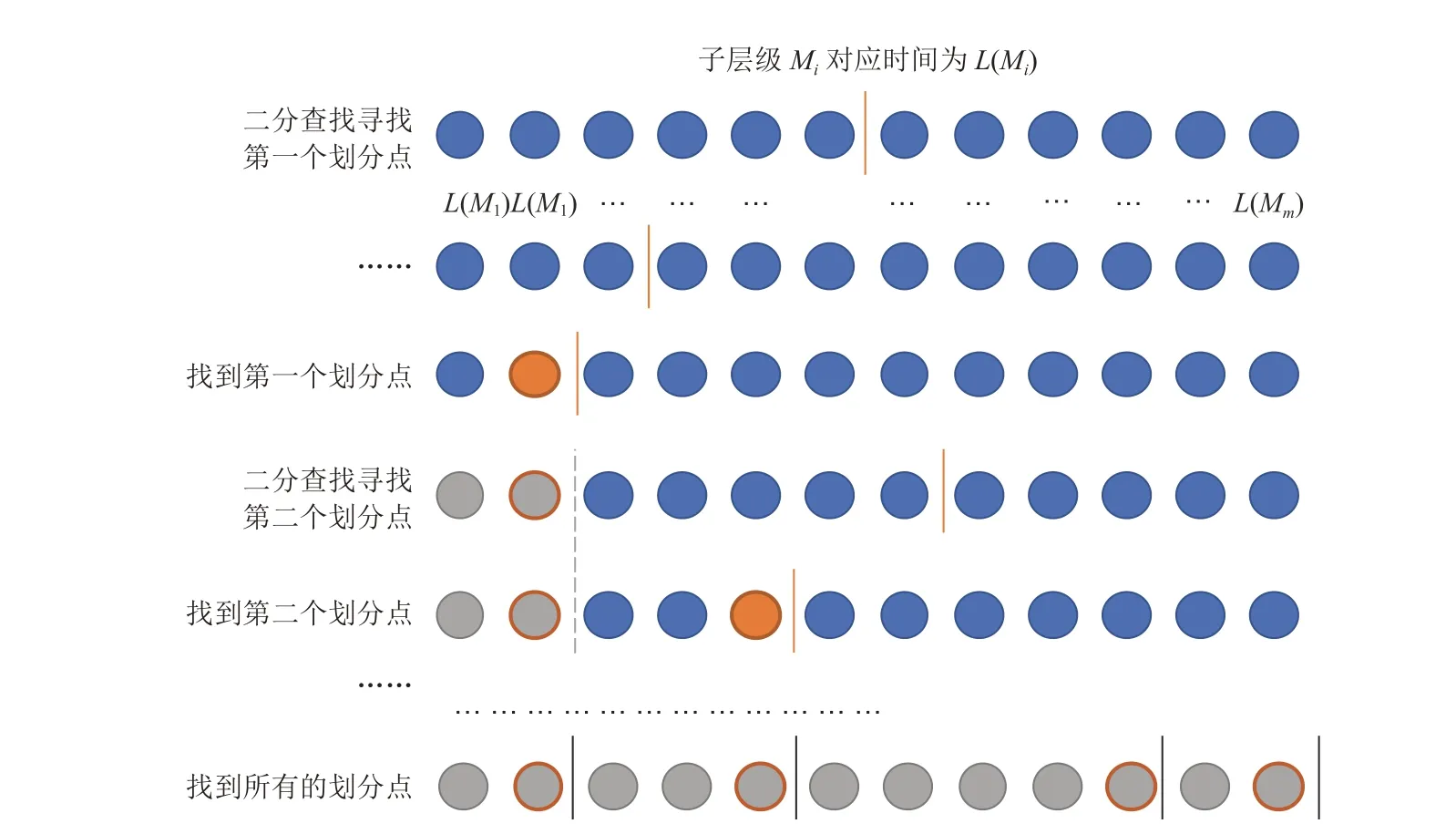
图2 任务二分迭代法的划分示意图Fig. 2 Schematic diagram of task dichotomy iteration method

图3 针对板间延时的流水线结构的设计优化方案Fig. 3 Design optimization scheme of pipeline structure for interboard delay

3.3 计算单元并行优化方法



图4 优化前后的卷积计算代码Fig. 4 The convolution computation code before and after optimization

表1 数据共享关系Table 1 Data sharing relationship

对数据关系进行重排和将循环展开后,循环个数将变为 4 个嵌套的完美循环。在展开后的循环层级中使用流水线技术,可以达到时间上的优化,提高模块内的吞吐率。也就是说,循环展开是一种空间优化技术,而流水线是一种时间优化技术,两者结合将得到良好的模块内并行优化结果。优化前后的卷积计算代码如图 4 所示,综合后的硬件框架如图 5 所示。
4 实验验证
4.1 实验建立
实验选择的任务为经典 CNN 网络——AlexNet。由于全连接层参数多会导致 BRAM 资源不足且功耗较高,因此舍弃全连接层,并对 AlexNet 进行修改。按照前文所述方法列出各子层级信息并使用 HLS 得到各子层级的延迟信息与资源信息,具体如表 2 所示。为说明任务二分迭代法的通用性,实验平台为由 3/4 块 Zynq7035 搭建的K=3/4 的 FPGA 异构开发平台,而流水

表2 初步综合后的网络子层级信息Table 2 Network sub-level information after preliminary synthesis

图5 代码优化综合后的硬件框架示意图Fig. 5 The hardware framework diagram after code optimization and synthesis

4.2 实验结果

图6 传统的任务划分结果Fig. 6 Traditional task segmentation results

图7 使用二分迭代法后的任务划分结果Fig. 7 The results of task partition after using dichotomy iteration method




图8 不同任务数下两种方案的总时间比较Fig. 8 The total time of the two schemes is compared with the number of tasks
4.2.3 计算单元并行优化结果

图9 不同阶段优化方法的吞吐率与能效比实验结果(K=4 )Fig. 9 Experimental results of throughput and energy efficiency of optimization methods in each stage are compared when K=4
在任务划分与流水线结构优化后,根据 3.3 小节所述优化卷积层代码从而并行优化各 FPGA 节点的计算单元。各阶段优化方法的吞吐率与能效比实验结果如图 9 所示,图中从左到右为优化的顺序。传统方法采用图 6 方法部署任务,且未优化流水线结构与计算单元。此方法单次任务运行延迟为 517.7 ms,吞吐率为 7.73 imgs/s,总功耗为 8.57 W,能效比为 0.9 imgs/J。而采用本文的任务划分方法后,吞吐率提升为 9.09 imgs/s;之后针对板间延迟优化流水线结构,吞吐率提升为 9.48 imgs/s;最后并行优化计算单元,单次任务运行延迟为 328 ms,吞吐率为 24.4 imgs/s,总功耗为 13.18 W,能效比为 1.85 imgs/J。与传统方法相比,本文方法完成所有优化步骤后的平台吞吐率提高了 215.6%,能效比提高了 105.5%,单次任务的运行时间也减少了 36.6%。
5 讨论与分析
现有的异构计算研究主要以单板为主,尽管目前对多 FPGA 异构平台的研究还比较少,但其具有良好的应用前景,同时构建多 FPGA 流水线结构非常契合深度学习推理的需求。然而,在多 FPGA 异构平台的流水线结构中,对流水线技术各方面的优化还缺乏系统方法。Zhang 等[22]在多 FPGA 的任务划分问题上提出吞吐率最大化和单次延迟最小化的穷举法,时间复杂度为O(m2×K)(m为子任务的数量,K为 FPGA 数量),但该方法没有具体讨论板间通信延迟的影响。Liang 等[23]针对多 FPGA 流水线问题提出板间延迟模块化流水线方法,但在任务划分方面仍使用传统方法,且在计算单元并行优化中没有分析数据关系。
与上述多 FPGA 异构平台流水线方式相比,本文提出的任务划分法降低了吞吐率最大化问题的求解次数与难度,最坏情况下时间复杂度仅为O(K/2×log2m)。不仅针对板间通信延迟优化了流水线结构,而且在板内也优化了循环流水线,并根据数据关系重排数据结构。同时,本文方法合理利用 BRAM,最终在时间、空间方面提高了吞吐率与能效比。
6 结 论
本文提出一种基于多 FPGA 异构平台的流水线技术优化方法:①将总体任务采用任务二分迭代法合理划分部署于多 FPGA 中,该方法满足通用性,克服了人工划分的诸多缺点,达到了更好的流水线平衡,提高了吞吐率;②基于板间延迟影响优化流水线结构,比较了两种流水线结构处理办法,其中选择将板间延迟作为流水线一级的优化方法提高了吞吐率;③并行优化计算单元模块,包括重排数据关系、循环展开和使用流水线技术,该优化既提高了吞吐率也提高了能效比。AlexNet 的实验结果表明,与传统方法相比,本文方法吞吐率提高了 215.6%,能效比提高了 105.5%,单次任务运行时间减少了 36.6%。未来将对上述优化方法作进一步的研究,如其对资源利用率的影响等,同时采用更多的方法对该平台进行优化。
