山西省林火驱动因子及分布格局研究
2020-09-28马文苑冯仲科成竺欣王凤阁
马文苑,冯仲科,成竺欣,王凤阁
(1.北京林业大学 精准林业北京市重点实验室,北京 100083;2.应急管理部森林防火预警监测信息中心,北京 100054)
森林是生物遗传多样性最为丰富的生态系统[1-3],在水土保持、气候调节和碳循环等方面发挥着重要作用[4-5]。火灾是森林生态系统的主要干扰因素之一,影响着森林生态系统中的生物多样性、物种组成和生态系统结构等因素[6],同时森林火灾也威胁着森林资源和人民的生命财产安全[7]。因此,研究林火发生驱动因子和林火分布格局非常重要,这可以帮助防火部门准确评估森林火灾风险,并有效地进行森林防火工作。
林火驱动因子通常分为四大类:气象、植被、地形和人类活动(包括基础设施和社会经济)[8-9],这些因素对森林火灾的影响各有不同。在影响范围上,气象对林火的影响发生在较大范围,而植被、地形和人类活动的影响发生在小范围[10]。在影响方式上,气象因素通常被认为是影响林火发生的决定因素[11];植被是燃烧三要素中的可燃物,直接影响着火能力[12];地形会影响植被的数量和结构,从而影响林火发生的可能性,同时还能影响林火蔓延的速度和方向;人类活动通过建筑扩张、交通网建设和户外活动等行为影响林火的空间分布和频率[13]。这些因素也以各种方式相互影响,对这些因素及其相互作用的研究可以为森林火灾的空间分布和发生概率提供更细致的分析。
对于林火驱动因子和分布格局的研究多以数学和统计学方法为基础[14],通过建立林火发生的条件与气象、地形、人类活动等各种要素之间关系的数学模型计算森林火灾发生的概率。逻辑斯蒂回归是林火研究中一种常用的方法,该模型对于林火发生具有较高的预测准确率,已被广泛地运用在我国的林火研究中[15-17],但是林火发生概率与一些影响因子之间存在复杂的非线性关系,逻辑斯蒂模型在解释非线性关系时具有局限性[18]。随机森林(Random forest, RF)算法是一种以决策树为分类器的机器学习算法,可以处理大量的自变量并能够自动选择重要的变量,不受变量间多重共线性的影响[19]且能够更灵活地评估变量之间复杂的交互关系,近几年已有国内外学者将其应用于林火驱动因子的研究[17,20-21]。然而,随机森林模型也有一些限制,它不能计算具体的回归系数和置信区间[19,22]。这两种模型各有优缺点,故本研究使用逻辑斯蒂和随机森林两种模型对比研究山西省林火驱动因子。
我国对林火驱动因子和分布格局的研究主要集中在东北大兴安岭林区[17,21]以及福建[15,18,20]、云南[23]、湖南[24]等南方林区,对山西的林火相关研究很少。然而山西省地处黄土高原,缺林少绿,生态脆弱,保护现有的森林资源尤为重要。本研究基于2010—2017年卫星监测热点数据分析山西省近期林火驱动因子和火险分布格局,以期为山西省森林防火部门提供参考,减少因火灾导致的山西省森林资源的损失。
1 研究区概况
山 西 省 位 于110°14′~114°33′E、34°34′~40°44′N之间,地处黄河中游东岸、华北西部的黄土高原东翼,总面积15.67万km²。其境内地貌类型复杂多样,80%为山地、丘陵,20%为高原、盆地、台地等,大部分地区海拔在1 000 m以上。山西属于温带大陆性季风气候,具有四季分明、雨热同步、光照充足、南北气候差异显著、冬夏气温悬殊、昼夜温差大的特点。全省降水量季节分布不均,夏季降水相对集中,且省内降水分布受地形影响较大。
山西的森林资源短缺,现有的森林资源是由残留的天然次生林和解放后新造的人工林组成的,主要是由松属和栎属的部分树种组成的温性、暖温性针叶林和落叶林,呈现从南到北递减的趋势。山西南部和东南部是植被类型最多、种类最丰富的地区,是落叶阔叶林和针阔混交林分布区;中部是以针叶林及落叶灌丛为主、落叶阔叶林为次的分布区;北部和西北部是温带灌草丛和半干旱草原分布区,森林植被较少。
2 数据与方法
利用山西省2010—2017年卫星监测热点数据、日值气象数据、数字高程模型(Digital elevation model, DEM)数据、全国基础地理数据、地表覆盖数据、归一化植被指数(Normalized difference vegetation index, NDVI)数据,分别基于逻辑斯蒂回归和随机森林算法分析山西省主要林火驱动因子,建立山西省林火发生概率模型,并对比分析两种模型的预测结果和拟合精度,选择拟合效果好的模型对山西省森林火险等级进行区划。
2.1 数据来源与处理
2.1.1 因变量
2010—2017年卫星监测热点数据由应急管理部森林防火预警监测信息中心提供,数据包括热点时间、经度、纬度、地类等信息,从中筛选出地类为林地的数据作为本研究中使用的林火数据(共1 435条),数据分布如图1所示。

图1 2010—2017年山西省森林热点数据分布Fig.1 Forest thermal abnormal point in Shanxi from 2010 to 2017
建立林火预测模型时,除了需要林火数据外,还需建立一定量的随机点作为非火点参与建模,火点和非火点共同构成样本点,本研究根据前人经验[20],将火点与非火点的比例设置为1:1.5。建立非火点时需遵循3个原则:1)非火点要保证落在地类为林地的区域;2)每个非火点距热点至少500 m;3)遵循时间和空间上双随机。使用ArcGIS 10.2软件建立非火点,以山西省2010年30 m地表覆盖数据作为依据提取的林地范围,该数据来源于全国地理信息资源目录系统网站(http://www.webmap.cn)的30 m全球地表覆盖数据集GlobeLand30。在每个火点周围建立500 m的缓冲区,用山西省林地范围减去火点缓冲区的范围作为创建非火点的范围。在创建非火点后,在Excel软件中对非火点进行随机日期赋值,保证时间上的随机。
2.1.2 自变量
从气象、地形、植被、人类活动4个方面选取了16个因素作为影响山西省林火发生的初始变量(表1)。
气象初始变量有日平均地表气温、日降水量、日平均气压、日平均相对湿度、日照时数、日平均气温、日平均风速,数据来源于中国气象数据网(http://data.cma.cn)的《中国地面气候资料日值数据集(V3.0)》。提取样本点气象数据时,先在ArcGIS10.2软件中使用泰森多边形法匹配样本点和与其距离最近的气象站点[20],使用空间连接工具将落在每个多边形中的火点和非火点与气象站点对应,接着在Excel软件中根据样本点对应的气象站点和日期匹配气象数据。
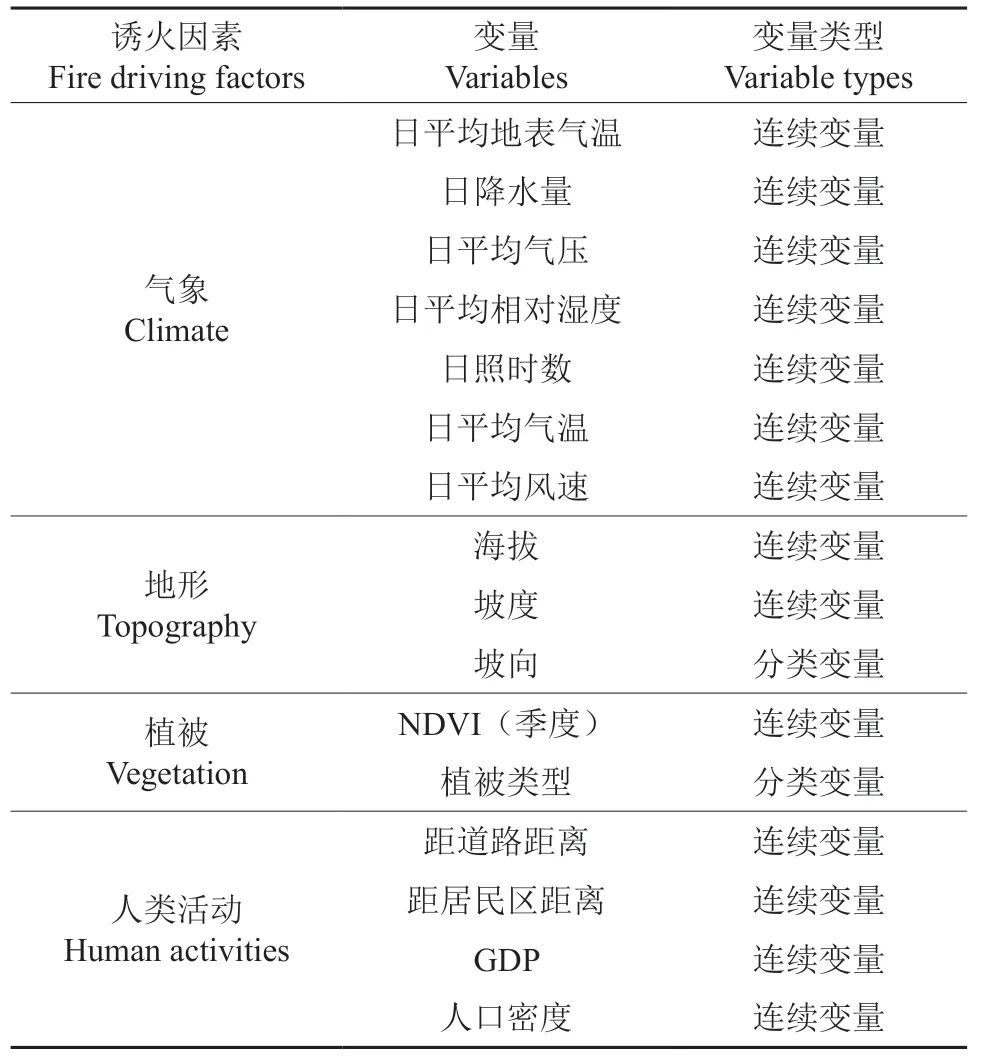
表1 初始诱火因素变量Table 1 The initial driving factors of forest fire
地形初始变量有海拔、坡度和坡向,这3种数据均从山西省DEM数据中提取。DEM数据来源于中国科学院计算机网络信息中心地理空间数据云平台(http://www.gscloud.cn)的GDEMV2 30M数字高程数据。使用ArcGIS 10.2软件中Spatial Analyst工具包中的“表面分析”工具提取整个山西省的坡度和坡向数据,使用“提取分析”工具提取样本点对应的海拔、坡度和坡向。
植被初始变量有季度NDVI和植被类型。由于山西省四季分明,不同季度气候差异较大,可能对植被状态产生相应的影响,故本研究选取2010—2017年每一季度的NDVI作为一个可能影响林火发生的初始变量,数据来源于中国科学院资源环境科学数据中心(http://www.resdc.cn)的中国季度植被指数(NDVI)空间分布数据集,分辨率为1 000 m,季度划分为春(3—5月)、夏(6—8月)、秋(9—11月)、冬(12月—次年2月)[25]。在提取样本点的NDVI数据时,将样本点按年份和季度进行分类,使用ArcGIS软件的“提取分析”工具对分类数据进行批处理提取样本点的季度NDVI数据。植被类型数据来源于中国科学院资源环境科学数据中心(http://www.resdc.cn)的中国100万植被类型空间分布数据,使用ArcGIS10.2软件的“提取分析”工具提取样本点的植被类型。
人类活动初始变量有距道路距离、距居民区距离、GDP、人口密度。道路网和居民区分布数据来源于全国地理信息资源目录系统网站(http://www.webmap.cn)的《1∶25万的全国基础地理数据库》,使用ArcGIS10.2软件分析工具中的“近邻分析”功能计算每个样本点距道路和居民点的距离。GDP和人口密度数据来源于国家地球系统科学数据中心(http://www.geodata.cn),分辨率1 km,时间为2015年,使用ArcGIS10.2软件的“提取分析”工具提取样本点对应的的GDP和人口密度。
2.1.3 数据归一化
由于模型各因子的量纲不同且数据级存在差别,为消除量纲、避免太大的数值引发数值问题和平衡各因素的贡献,对数据进行归一化处理。根据不同数据的特点选取不同的归一化方式,对海拔、平均地表气温、日最高地表气温、日最低地表气温、降水量、平均气压、日照时数、平均风速、最大风速、平均气温、日最高气温、日最低气温、样本点-居民点距离、样本点-道路距离、NDVI这15种数据采用公式(1)进行归一化。

式中:xi、分别表示数据归一化前后的值;xmax、xmin分别表示样本数据中的最大值和最小值。坡度的归一化公式为:

式中:α表示坡度值。
平均相对湿度和最小相对湿度的归一化公式为:

式中:φ表示湿度值。
对坡向进行分类处理,分类方式如表2所示[26]。
2.2 研究方法
2.2.1 逻辑斯蒂模型
逻辑斯蒂回归模型属于广义线性模型的一种,它的因变量取值是不连续的,可以是二项或多项分类,它的自变量可以是连续变量也可以是分类变量[27]。
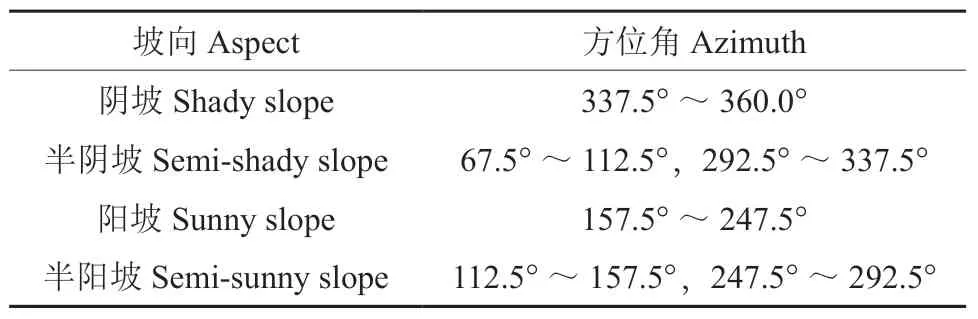
表2 坡向分类Table 2 Classification standard of aspect
设林火发生概率为P,林火不发生的概率为(1-P),林火发生概率与火险因子的逻辑斯蒂表达式为:
式中:β0为常量,β1,β2,…,βn为各个自变量Xi的系数。
2.2.2 随机森林模型
随机森林算法是一种统计学理论,既可以解决回归问题,也可以解决分类问题。随机森林算法利用bootstrap重抽样方法从原始样本中抽取多个样本,然后对每个样本进行决策树建模,在处理回归问题时,以每棵决策树输出的均值作为最终系数;在处理分类问题时,以投票的方式决定最终预测类别。它的优点是可以处理大量的输入变量,可以评估变量的重要性,并且一般不会出现过拟合的情况[28-29]。
用n来表示林火数据,用m来表示自变量数量,ntree和mtry是两个重要参数。随机森林算法使用bootstrap重抽样方法从n个样本数据随机抽取ntree个容量为n的样本集,以此为基础创建ntree棵分类回归树,并在每株分类回归树的每个节点处随机抽取mtry个自变量(mtry≤m)。选取分类能力最强的变量进行分支,每棵树都不需进行任何剪枝,任其自由生长到最大限度。最后得到ntree个决策输出,在分类问题中,选取这ntree个决策输出的众数作为随机森林算法的最终预测结果。随机森林模型不能计算具体的回归系数,但可以通过变量局部依赖图描述自变量对林火发生概率的影响。
2.2.3 多重共线性诊断
在进行逻辑斯蒂回归前,需先对自变量进行多重共线性(Multicollinearity)诊断,剔除存在多重共线性的变量以提高模型精度。多重共线性是指方程中解释变量之间存在完全或近似完全的线性关系,即某一种解释变量可以用其他解释变量的线性组合来表示[30],如果模型中引入了具有多重共线性的自变量,模型的参数估计精度会降低,且可能会排除对模型有重要影响的自变量。本研究使用方差膨胀因子(Variance inflation factor,VIF)诊断法进行多重共线性诊断,方差膨胀系数的表达式为:
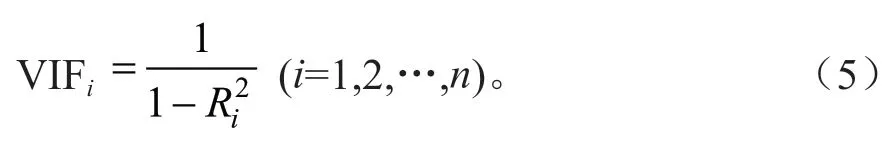
式中:Ri为自变量xi对其余(n-1)个自变量做线性回归分析的复相关系数。
当0<VIF<10时,变量之间不存在多重共线性;当10≤VIF<100时,变量之间存在较强的多重共线性;当100≤VIF时,变量之间存在严重的多重共线性。
2.2.4 ROC曲线
ROC曲线(Receiver operating characteristic curve)是一种坐标图式的分析方法,常被用来评价分类模型的预测精度和确定临界值。它通过设定出多个不同的临界值,计算出一系列敏感性和特异性,再以敏感性为纵坐标、(1-特异性)为横坐标绘制成曲线,通过曲线下的面积(Area under the curve,AUC)评价模型精度,AUC值越大,模型精度越高,最靠近坐标图左上方的点为敏感性和特异性均较高的临界值。
3 结果与分析
建模时,将样本划分为60%(2 151条数据)训练样本和40%(1 434条数据)测试样本,并重复5次样本划分以消除样本分布对模型结果的影响。
3.1 林火驱动因子选择结果
3.1.1 逻辑斯蒂回归选择结果
在进行逻辑斯蒂回归前,需先对自变量进行多重共线性诊断,但多重共线性诊断只适用于连续变量,不适用于分类变量,所以“坡向”和“植被类型”不进行诊断,直接进入模型显著性检验阶段。
多重共线性诊断结果如表3所示,剔除了平均地表气温和人口密度两个变量后,剩余12个变量的VIF值均小于10,不存在多重共线性。

表3 多重共线性诊断结果Table 3 The results of multicollinearity diagnosis
使用SPSS 18.0软件将通过多重共线性诊断的变量应用逻辑斯蒂回归模型的“wald向前”原则对5个训练样本进行拟合,得到5个中间模型,选取在5个中间模型中出现3次或3次以上的自变量进入全样本数据的拟合。表4为模型特征变量选择的结果。
通过多重共线性诊断和显著性检验的8个变量作为逻辑斯蒂回归模型选取出的山西省主要林火驱动因子进入全样本拟合,拟合结果如表5所示。
由表5可知,日照时数、日平均气温和日平均风速3个变量与林火发生概率呈正相关关系;海拔、坡度、日平均相对湿度、距道路距离、距居民区距离5个变量与林火发生呈负相关关系。
3.1.2 随机森林算法选择结果
在使用随机森林算法对林火数据进行拟合时,不需要预先对特征变量进行多重共线性诊断,16个变量直接进入基于随机森林算法的变量选择阶段。使用R语言中varSelRF程序包对5个训练样本进行随机森林算法特征变量的选择计算,得到5个中间模型的变量子集,然后在5个变量子集中选择出现3次或3次上的变量作为主要林火驱动因子进入模型的拟合阶段。变量选择结果如表6所示,共选出8个变量作为山西省林火主要驱动因子。

表4 逻辑斯蒂模型特征变量选择结果†Table 4 The results of variable selection based on logistic regression

表5 全样本数据逻辑斯蒂模型拟合结果†Table 5 The results of logistic regression model for all data
使用平均准确率下降度(Mean decrease accuracy)评价变量重要性,对5个训练样本和全样本的特征变量进行重要性排序(图2)可得,日平均相对湿度的重要性明显大于其它变量,其重要性在5个训练样本和全样本中均排在第一位,排在第2位的是日照时数。总体来看,气象因素中的湿度是对山西林火发生影响最大的因子,人类活动因素对山西省林火发生的影响要小于气象因素和植被因素,地形因素没有被RF模型选为林火驱动因子。
为了分析选择出的8个变量对森林火灾发生概率的影响区间,使用全样本拟合结果,通过R语言中的partialPlot函数绘制森林火灾发生与各主要林火驱动因子之间局部依赖图(图3)。林火驱动因子的取值为横坐标,纵坐标为函数依赖值,在本研究中为logit(P)/2,其中P为林火发生概率,纵坐标值越大说明林火发生概率越大。
由图3可得,日平均相对湿度与林火发生概率总体呈负相关关系。日照时数、GDP、日平均风速与林火发生概率总体呈正相关关系。季度NDVI、日平均气温、日平均地表气温先与林火发生呈正相关关系,在大于一定阈值后,与林火发生概率呈负相关关系,但有一定的波动。日平均气压对林火发生概率的影响较为复杂,其对林火发生概率的影响呈波动状态。
基于逻辑斯蒂回归和随机森林算法共同选择出的山西省主要林火驱动因子为日平均相对湿度、日照时数、日平均气温和日平均风速,且根据两个模型的全样本拟合结果,日平均相对湿度均与林火发生概率呈负相关关系,日平均风速和日照时数均与林火发生概率呈正相关关系。

表6 随机森林算法特征变量选择结果†Table 6 The results of variable selection based on random forest algorithm

图2 变量重要性排序Fig.2 The ranking of variable importance based on random forest algorithm

图3 变量局部依赖图Fig.3 Partial dependence plots
3.2 模型拟合结果
使用ROC曲线、AUC值、预测准确率对两个模型进行评价对比。预测准确率基于ROC曲线计算出的最佳临界值(Cut-off值)确定。
由图4和表7可得,6个样本的随机森林模型的AUC值均大于0.92,对样本的预测准确率均大于84%,说明逻辑斯蒂回归模型和随机森林模型对山西省林火发生预测均具有较高的准确性。将两个模型的ROC曲线和评价指标进行对比,发现随机森林模型的预测效果优于逻辑斯蒂回归模型。每个样本逻辑斯蒂回归模型的AUC值和预测准确率均低于随机森林模型,随机森林模型更适用于山西省林火发生预测。

图4 两个模型的ROC曲线Fig.4 The ROC of two models

表7 两个模型的评价指标对比Table 7 The comparison of two models evaluation
3.3 山西省森林火险等级区划
由于随机森林算法对林火发生预测模型的拟合效果优于逻辑斯蒂回归模型,使用随机森林算法对全样本的林火发生概率预测结果进行山西森林火险等级的划分。将林火发生概率划分为Ⅰ级~Ⅴ级5个森林火险等级,划分方式如表8所示[16]。

表8 火险等级区划Table 8 The standard of forest fire-risk grade division
使用克里金插值法绘制山西省森林火险等级区划图。由于山西省不同季节气候差异明显,不同季节的森林火险分布可能有差别,故做出4个不同季节的森林火险等级区划图(图5)和总的森林火险等级区划图(图6)进行分析。
由图5可知不同季节山西省的森林火险分布有明显差别。春季山西省高火险区最多,除朔州市外,其余各市均存在Ⅴ级火险区,东部的高火险区多于西部。夏、秋、冬季山西省的高火险区较少,夏季高火险区主要分布在临汾市和晋城市交界处;秋季和冬季林火发生概率较低,没有Ⅴ级火险区,Ⅳ级火险区主要分布在长治市和晋城市的交界地区。总体来看,山西省的高火险区主要分布在阳泉市、长治市和晋城市以及忻州市东部、晋中市北部、吕梁市东南部和太原市中部,山西省东部的火险区多于西部(图6)。
4 结论和讨论
1)本研究基于逻辑斯蒂回归和随机森林算法选出的林火发生驱动因子不同,但都选出了日平均相对湿度、日照时数、日平均气温和日平均风速,由此可得,气象因素是影响山西省林火发生的主要因素。在分析山西省森林火险等级区划时,不同季节的森林火险分布明显不同,这也说明了气象因素对山西省林火发生有着重大影响。气象因素主要影响着燃烧三角中可燃物和温度两个要素,这两个要素很大程度上决定了林火发生的时间和地区[11]。其中,相对湿度和风速通过影响森林可燃物的含水量影响林火发生,往往与林火发生概率呈负相关关系[18]。日照时数会对生物量积累产生积极影响,往往与林火发生概率呈正相关关系[20]。温度对林火发生的影响比较复杂,存在影响阈值[20]。在本研究中,RF模型结果也显示林火发生概率随日平均气温的升高先增加后减少,出现这种情况可能是因为虽然高温会使植物蒸发量增加,从而降低森林燃料的含水量[18],但山西省属温带大陆性季风气候,其特点是雨热同期,在高温天气往往伴随着降水量和相对湿度的增加,这会抑制林火发生,故而当日平均气温超过一定阈值时,会对林火发生概率产生消极影响。根据研究结果,山西省防火部门须对选出的4个气象因子进行重点监测,山西省林火易发生于平均气温8~18 ℃、相对湿度低、日照时长和风速高的天气,须在这些天气采取更严格的防火措施。

图5 山西省四季森林火险等级区划Fig.5 Forest fire risk distribution in four seasons in Shanxi province
2)使用逻辑斯蒂回归和随机森林算法分析林火发生概率,随机森林算法的模型拟合效果更好,预测准确率更高,说明随机森林算法比逻辑斯蒂回归更适用于山西省的森林火灾预测预报。这是因为相比于逻辑斯蒂回归,随机森林算法在异常值和噪声方面有很高的容忍度,且能够更灵活地评估变量之间复杂的交互关系[19,22],在之前的林火驱动因子研究中,随机森林算法也表现出比逻辑斯蒂回归更好的拟合效果[17,20-21]。
3)在逻辑斯蒂回归的多重共线性诊断阶段,日最低地表气温、日最高气温等4个因素被剔除,但使用随机森林算法进行因子选择时,日最低地表气温和日最高气温是选出的主要林火驱动因子。这说明林火驱动因子之间存在着复杂的关系,多重共线性诊断只考虑自变量间是否存在相关性,有可能会剔除掉对模型有重要影响的因子[21]。
4)由山西省森林火险等级区划图可以看出,一些高火险区分布在行政区边界处。这是因为行政区边界处往往位于山区,森林植被丰富,更易发生森林火灾。因此在制定火灾管理策略时不能只考虑行政区划,还应考虑具体的火险区划,根据火险分布的实际情况制定管理措施。
5)本研究中的气象要素只选取了日值气象数据,然而对于降水等要素,林火发生前一段时间内的累积值也很重要,在接下来的研究中会考虑在模型中引入一些中期气象要素。除研究中使用的逻辑斯蒂回归和随机森林算法外,还有一些模型被用于林火发生预测,如地理加权回归模型。该模型引入了空间加权矩阵,可解决由于特征变量的空间异质性和空间自相关性带来的模型误差,下一步可对该模型进行研究,分析林火驱动因子随空间位置变化对山西省林火发生概率的影响。另外,本研究所选取的初始气象因素为平均因素,没有选取极端因素,日后会进一步研究探讨极端天气对林火发生概率的影响。

图6 山西省森林火险等级区划Fig.6 Forest fire risk distribution in Shanxi province
