基于混合效应的马尾松单木断面积预估模型
2020-09-28陈振雄孟京辉王建军王景弟李志刚
杜 志,陈振雄,孟京辉,王建军,王景弟,李志刚
(1.国家林业和草原局 中南调查规划设计院,湖南 长沙 410014;2.北京林业大学国家林业和草原局森林经营工程技术研究中心,北京 100083;3.慈利县林业局,湖南 慈利 427200;4.慈利县天心阁林业工作站,湖南 慈利 427200)
森林生长和收获模型是描述林分或林木生长规律的数学表达式,它是森林经营管理的重要工具[1]。森林生长和收获模型可以分为三类,即全林分模型、径阶分布模型以及单木生长模型[2]。单木生长模型是以单木生长量为因变量,林木大小、林木间的竞争以及立地条件为自变量的数学表达式[3-4],它不仅能够准确地预估人工纯林的生长与收获,还广泛地应用于异龄混交林和天然林中。此外,单木模型还可以模拟不同经营措施下林木的生长动态,它的模拟结果比其他几类生长模型更准确,从而为森林质量的精准提升提供理论支持[5-8]。国内外学者对多种树种构建了生长模型,如孟宪宇等[9]以华北落叶松Larix principisrupprechtii人工林为研究对象,采用生长量修正分析方法构建了与距离无关的单木生长模型;杜纪山[10]以单木的直径为因变量,林木大小、林木间的竞争以及立地条件为自变量,构建了与距离无关的单木直径生长量模型。大部分学者构建生长模型采用的方法是传统回归方法,即最小二乘法。林分生长和收获模拟数据往往具有层次结构、重复测量等特点[11-12],表现为数据之间存在异方差和自相关,因而不满足普通回归分析中的独立性假设,即独立、等方差、正态分布,会得到有偏的参数估计[13-15]。而混合模型作为一种处理分组数据的有力工具,可以灵活地解决这一问题,从而提高预测精度并解释随机误差的来源[16-18]。
马尾松Pinus massoniana是阳性树种,不耐庇荫,喜光、喜温,适合生于年均温13~22 ℃、年降水量800~1 800 mm的地区。马尾松分布范围广,是松属分布最广的树种,东从东部平原地区,西至云贵高原和四川盆地,北自山东及河南南部,南至广西、广东、台湾、海南等地,遍布全国16个省(区、市)。它是我国主要的用材树种之一,在全国1 400多个乔木树种的重要值排序中位居第三,在我国的森林资源总量中占有很重要的地位。根据第九次全国森林资源清查,马尾松林面积和蓄积分别为804.30万hm2和6.26亿m3,占我国乔木林面积和蓄积的4.47%和3.67%。马尾松具有重要的生态价值和经济效益。因此,构建精度较高的生长预估模型对于马尾松的经营管理十分必要。
本研究基于湘西地区2004、2009、2014年三期全国森林资源一类清查固定样地数据,运用逐步回归法,构建马尾松林胸高断面积预估模型。同时在构建模型的基础上引入样地随机效应,运用单水平线性混合模型的方法构建不同参数个数的混合效应模型,筛选最佳的变量组合,同时利用独立样本数据对胸高断面积预估模型进行检验,以期构建的模型能为湘西地区马尾松的生长和经营提供参考依据。
1 数据和方法
1.1 数据来源
试验数据来源于湘西地区2004、2009、2014年三期全国森林资源一类清查固定样地,本次筛选的样地数量为180块,样地为面积667 m2的正方形。样地信息包括样地测量因子和样木测量因子,样木测量因子主要包括树种名称、胸径、材积等。样地测量因子包括坡度、坡向、坡位、海拔、土层厚度等立地因子以及优势树种、郁闭度、林种、龄级等林分因子。剔除不满足条件及数据异常的样地后,3期数据共得到样地100块,马尾松的株数为3 737株。
1.2 方 法
1.2.1 变量选择及基础模型的构建
单木断面积生长模型常常描述为林木大小、竞争及立地条件的线性函数,本研究充分考虑以上因素对于马尾松单木断面积的生长,选择的变量如下:
1)林木大小:主要包括期初胸径(DBH)及其变形形式,即期初胸径(DBH)、期初胸径的平方(DBH2)、期初胸径的对数(logDBH)以及期初胸径的倒数(1/DBH)。
2)林分竞争:为了使模型具有更好的通用性或适用性,选择了以下与距离无关的竞争指标,即每公顷株数(NT)、每公顷断面积(BA)、大于对象木的胸高断面积和(BAL)和对象木胸径与林分平均平方胸径之比(RD)。
3)立地条件:充分考虑了海拔(EL)、坡度(SL)及坡向(ASP)的影响,同时依据Stage[19]提出的公式对坡度和坡向进行了组合,即SlCos=SL×cos (ASP)。
不同形式的因变量会导致不同的模型表现。在预分析中,对不同形式的因变量进行了测试,根据残差图和评价指标,发现log[(DBH22-DBH2)+1]效果最好,因此选择log[(DBH22-DBH2)+1]作为模型的因变量。其中,DBH、DBH2分别指期初胸径和期末胸径。因变量加入常数1的作用是避免断面积生长量为0时无法参与模型的计算。
基础模型的构建依据相关性分析,选择与因变量相关性强的变量进入模型,对进入模型的变量进行回归系数显著性检验和共线性检验,最终回归系数显著(P<0.05)且方差膨胀因子(VIF)小于5的变量进入模型。
1.2.2 混合效应模型的构建
采用单水平线性混合效应模型的方法构建湘西地区马尾松单木断面积预估模型,模型的一般形式如下:

式中:yi为第i个样地的观测值;Xi为已知固定效应设计矩阵;β为未知的固定效应参数向量;Zi为已知随机效应设计矩阵;bi为未知的随机效应参数向量;ei为误差向量;n为样地个数;D为随机效应协方差矩阵;σ2为模型的误差方差值;Ri为组内方差协方差结构。在混合效应模型构建过程中需明确以下问题:
1)参数效应的确定
混合模型构建过程中最重要的一步是确定参数效应,即哪个参数为固定参数,哪个参数为混合参数。本文中参数效应的确定采用的是把基础模型中所有参数均作为混合参数,对其不同组合进行模拟,最后根据拟合统计量进行选择。
2)随机效应方差-协方差结构的确定
测试林业上常用的3种随机效应方差-协方差结构即对角矩阵(DM)、复合对称矩阵(CS)和广义正定矩阵(General positive-definite matrix)来确定最优的随机效应方差-协方差结构。
3)误差方差-协方差结构的确定
由于建模数据来源于固定样地的复测数据,这类数据往往存在异方差和自相关性的问题,为了确定误差的方差-协方差结构,必须考虑以上两方面问题。在林业上通常采用式(2)来描述该问题:

式中:σ2为误差方差;Gi为误差方差异质性矩阵;Γi为误差相关性结构。
文中方差异质性的描述选择指数函数、幂函数和常数加幂函数3种,误差相关性的表达选择林业上常用的复合对称(CS)、一阶自回归[AR(1)]与一阶自回归移动平均结构[ARMA(1,1)]。
1.2.3 模型的选择与检验
模型的筛选依据赤池信息准则(AIC)、贝叶斯信息准则(BIC)越小越好、对数似然值(Loglikelihood)越大越好的原则,同时要对筛选出的混合模型进行似然比检验(LRT),避免过多参数化问题的产生。
利用筛选出的模型进行独立样本数据检验之前,需要利用式(3)计算随机效应参数值。

式中:D为随机效应参数方差-协方差矩阵;Zk为已知设计矩阵;Rk为误差方差-协方差矩阵;ek为误差向量。
模型检验的结果通过平均绝对误差(Bias)、均方根误差(RMSE)和决定系数(R2)进行评价。
2 结果与分析
2.1 基础模型结果
本研究采用逐步回归,依据相关性分析,选择与因变量相关性强的变量进入模型,对进入模型的变量进行回归系数显著性检验和共线性检验,最终模型形式如下:
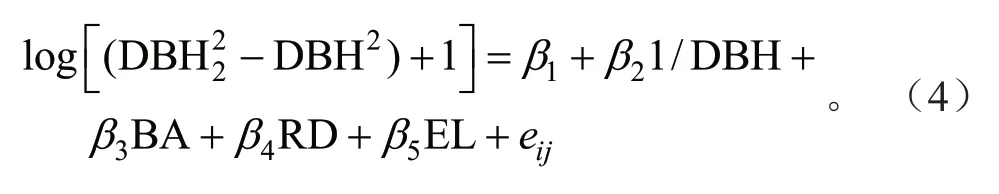
参数估计及其统计描述如表1所示。1/DBH、BA、RD和EL对马尾松单木断面积的生长有显著影响(P<0.05)且VIF小于5。该基础模型的R2为0.364,从模型的残差图(图1)可以看出存在异方差性。
2.2 混合效应模型
考虑不同随机参数的组合,对等式(4)进行拟合,基于样地效应的马尾松单木断面积生长混合效应模型收敛的情况共有31种(表2)。根据AIC、BIC和Log-likelihood可以看出,混合效应模型的模拟效果都优于传统模型。此外,只含有一个随机效应参数时,模拟3效果最好;当含有2个随机效应参数时,模拟9效果最好;当包含3个随机效应参数时,模拟20效果最好;当含有4个随机效应参数时,模拟27效果最好;当含有5个随机效应参数时,得到模拟32。与此同时,可以看出模拟27的拟合效果优于其他任意一个组合的拟合效果,模拟精度最高。

表1 传统方法模拟马尾松单木胸高断面积预估模型的结果Table 1 The simulated result of Pinus massoniana individual tree basal area prediction model based on conventional method
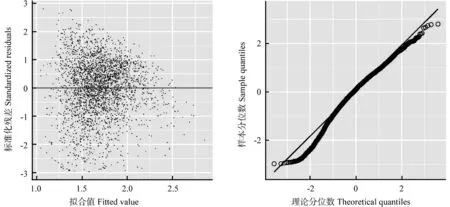
图1 基础模型的残差图和QQ图Fig.1 Residual plot and QQ plot of the basic model
表2 胸高断面积生长量线性混合模型收敛结果†Table 2 The simulated results of basal area growth based on linear mixed model
为了比较变量参数个数的差异,本研究对以上5种模拟进行了似然比检验,其结果见表3。根据结果模拟27即等式(5)作为最佳参数组合的混合效应模型。

式中:β1~β5是固定效应;b1~b4是随机效应。
3种随机效应方差-协方差结果如表4所示。根据AIC、BIC、Log-likelihood和LRT,选择广义正定矩阵为最终的随机效应方差-协方差结构。
由于基础模型的残差图表明存在异方差性,因此使用指数函数、幂函数和常数加幂函数对模型误差的方差结构进行模拟。从表5可以看出,引入异方差函数后,混合效应模型在AIC、BIC和Loglikelihood方面得到了改善。根据LRT结果,在这3个异方差函数中,幂函数表现最佳,作为该模型最终的异方差函数。此外,由于加入自相关结构后模型未能收敛,因此在最终的模型中未考虑。

表3 不同参数变量的模型似然比Table 3 Model likelihood ratios for different parameter variables

表4 胸高断面积线性混合效应模型随机效应参数的方差-协方差矩阵Table 4 The linear mixed-effects individual-tree basal area increment model using the random effects variance-covariance structures

表5 考虑异方差结构矩阵后混合效应模型的比较结果Table 5 The comparison results of mixed models with heteroscedasticity structure in different variance functions
确定了参数效应、随机效应方差-协方差结构以及误差方差-协方差结构,采用极大似然法在R语言中获得的马尾松单木断面积生长混合效应模型,最终结果如下:

其中:

此外,混合效应模型即式(6)的残差图和QQ图如图2所示。由图2可以看出,引入随机效应后,模型的残差图得到了改善。
2.3 模型的检验
本研究采用80%的数据共有2 857株马尾松构建了马尾松的胸高断面积预估模型,采用剩余的20%马尾松数据对构建的模型进行检验,比较线性混合模型与传统最小二乘方法的精度。表6显示,传统最小二乘方法的3个指标值计算结果Bias为0.328 1,RMSE为0.426 4,确定系数R2为0.333 2。考虑样地效应的混合效应模型的Bias为0.223 4,RMSE为0.315 2,确定系数R2为0.604 6。可以看出混合效应的平均绝对残差与均方根误差低于一般的线性模型,确定系数R2由0.333 2提高到0.604 6。

图2 混合效应模型的残差图与QQ图Fig.2 Residual plot and QQ plot of final mixed-effects model
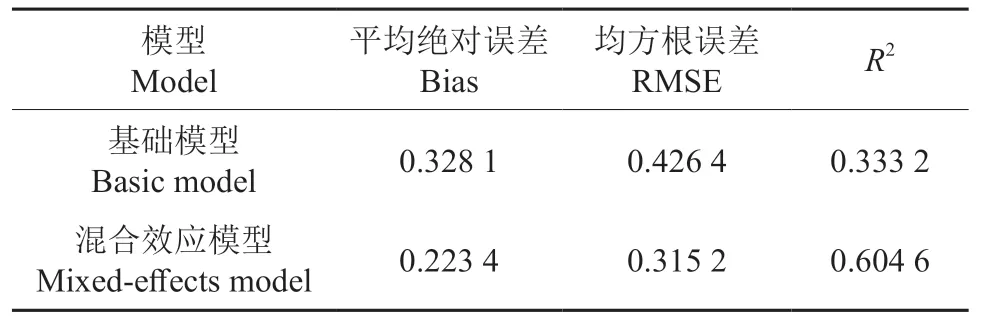
表6 传统模型与混合效应模型验证拟合统计Table 6 Fitting statistics for validation of the basic model and mixed-effects model
3 结论与讨论
从林木本身大小(DBH)、林分的胸高断面积(BA)、林分竞争指数(RD)以及立地条件海拔(EL)对湘西地区马尾松林生长影响效果明显。其中林分的生长与胸径的倒数呈负相关,与林木的胸径呈正相关,即林木个体的林木胸径越大,林分的竞争能力也越强,林分林木生长量也越大。王建军等[2]、Zhao等[20]、Cannell等[21]分别以杉木Cunninghamia lanceolata、硬阔树种以及云杉Picea asperata和松树得到了相同的结论。BA是一个间接反映树木间竞争的指标,胸高断面积生长量与林分的胸高断面积呈反比,BA越大树木间的竞争压力越大,胸高断面积生长量越小。RD是指林木的胸径与平均胸径的比值,它是反映林木竞争强弱的指标,其值越大说明林木的竞争力越强,树木获取光照、水分以及营养物质的能力越强,因此RD与胸高断面积生长量呈正比。
由于林木生长和收获数据不满足独立同分布的假设,本研究运用层次混合效应模型方法,构建了湘西地区马尾松林的胸高断面积预估模型。根据AIC、BIC和Log-likelihood可以看出,考虑不同随机参数组合混合效应模型的模拟效果都优于传统模型,通过比较不同随机参数组合的混合效应模型,发现包含int、1/DBH、BA、RD的4个变量的组合效果最佳。同时选择广义正定矩阵为最终的随机效应方差-协方差结构,考虑基础模型方差存在异方差性,在消除异方差时,指数函数、幂函数和常数加幂函数均能在一定程度上缩小残差的变化范围,但幂函数形式的拟合效果较好。在模型检验中,与传统的模型相比,混合效应模型的Bias、RMSE其相对值均显著减少,模型的决定系数从0.333 2提高到了0.604 6。混合效应模型大大提高了预估的精度,混合效应模型优于传统模型。
马尾松为我国重要用材树种,分布范围广,生长立地条件复杂,以湘西地区为研究区域时,海拔对马尾松单木断面积的生长呈现显著影响。然而,在省或更大区域上,温度、降水、土壤类型等因子可能是影响马尾松生长的重要参数。将来要充分利用好全国第九次森林资源连续清查成果,分析我国马尾松分布地区,筛选生长典型区域,综合考虑地区气候环境、立地条件等多因素,客观全面地构建单木断面积预估模型,为马尾松生长预估和经营管理提供科学依据。
