基于深度学习与多模态医学影像融合识别阈下抑郁患者
2020-09-25尹小龙李德民单保慈
尹小龙,李德民,图 娅,单保慈
(1.郑州大学物理学院,河南 郑州 450001;2.北京中医药大学针灸推拿学院,北京 100029;3.北京师范大学认知神经科学与学习国家重点实验室,北京 100875;4.中国科学院高能物理研究所 北京市射线成像技术与装备工程技术研究中心,北京 100049;5.中国科学院大学核科学与技术学院,北京 100049)
阈下抑郁(subthreshold depression, StD)是发生率高、危害广泛的精神类症状,为介于正常和抑郁之间的一种状态,临床符合2项以上抑郁指标但未达到抑郁症诊断标准时即诊断StD[1]。目前主流观点认为StD是抑郁症的前驱期,造成诸多负面影响,如影响个体健康、降低生活质量及增加社会医疗成本等。相比健康人,StD患者发展为抑郁症、焦虑症等精神疾病的风险更高[2-3]。既往抑郁分类研究[4-6]主要使用传统的机器学习方法,多针对抑郁症(major depressive disorder, MDD)患者与正常对照者(normal control, NC),对StD研究较少。近年来,深度学习(deep learning, DL)技术逐步兴起,通过构建多层神经网络,可从数据中自动学习更高维度和更抽象的特征,省去手工提取特征步骤,神经网络的层数越多,能够提取到的特征越丰富,对于高维度神经成像数据而言,较传统机器学习方法更为简便、有效[7-8];其中适于图像处理的卷积神经网络 (convolutional neural network, CNN)算法在医学影像领域得到了普遍应用[9-11]。基于CNN算法,本研究尝试通过输入2种不同模态的影像学数据实现识别StD患者与正常人。
1 资料与方法
1.1 一般资料 收集于北京师范大学认知神经科学与学习国家重点实验室接受MR和fMR扫描的56例StD患者(StD组)和70名正常人(normal control, NC组)。StD组男14名,女42名,年龄18~62岁,平均(29.5±14.5)岁。纳入标准:流行病学研究中心抑郁量表(center for epidemiologic studies depression scale, CES-D)评分结果≥16分,且汉密尔顿抑郁量表(Hamilton depression scale, HAMD)评分结果7~17分。排除标准:①其他精神疾病或头部外伤史;②过去4周内曾参与其他临床试验;③服用抗精神病类药物或接受其他系统治疗;④其他需要治疗的严重疾病;⑤有自杀计划或行为;⑥处于妊娠或哺乳期;⑦MR检查禁忌证。NC组男21例,女49例,年龄18~63岁,平均(32.4±15.6)岁。纳入标准: CES-D评分<16分;排除标准同StD组。本研究经院伦理委员会批准,受试者均签署知情同意书。
1.2 仪器与方法 采用Siemens 3T MR仪。首先采集T1加权结构像,采用梯度回波三维成像序列,扫描参数:TR 2 530 ms,TE 3.39 ms,FOV 256 mm×256 mm ,翻转角70°,层厚1.33 mm,矩阵256×256,空间分辨率1.00 mm×1.00 mm×1.33 mm;随后进行8 min静息态功能成像,扫描参数:TR 2 000 ms,TE 30 ms,FOV 240 mm×240 mm,翻转角90°,层厚4.8 mm,空间分辨率3.00 mm×3.00 mm×4.80 mm,期间封闭受试者视听,并确保其在扫描过程中处于清醒状态。
1.3 数据预处理 对原始数据进行预处理。结构像预处理采用基于Matlab2017a的SPM 12软件(https://www.fil.ion.ucl.ac.uk/spm/software/spm12/),首先将原始DICOM数据转换为NIfTI格式数据,再将转化后图像标准化到蒙特利尔神经研究所(Montreal Neurological Institute, MNI)标准人脑空间坐标上,进行2 mm×2 mm×2 mm体素大小重采样。功能成像预处理采用基于SPM12的DPARSF软件(http://www.rfmri.org/DPABIDiscussion),流程如下:①数据格式转换,将原始DICOM数据转换为NIfTI格式数据;②时间层校正;③头动校正;④空间标准化,对T1像和平均功能像进行标准化,并行3 mm×3 mm×3 mm体素大小重采样;⑤回归白质和脑脊液信号;⑥采用4 mm半值全宽(full width at half-maximum, FWHM)高斯核空间平滑图像;⑦去线性漂移,去除高频生理噪音和低频漂移;⑧低频滤波(滤波频段0.01~0.08 Hz)。
1.4 数据分析
1.4.1 结构像 采用CNN算法分析结构像数据,以3D-CNN对结构像数据进行训练,所用神经网络分为卷积层、池化层和全连接层3个部分,网络结构为10个网络层,包含4个卷积层、4个池化层和2个全连接层。网络结构示意图见图1。
1.4.2 功能像 针对功能连接进行分析。首先根据自动解剖标记图谱(automated anatomical labeling, AAL)将全脑划分为116个脑区,提取每个脑区的时间序列,计算各脑区时间序列之间的相关性(Pearson相关),得到反映各脑区活动强度相关性的相关矩阵,并输入构建的人工神经网络中,后者为Kawahara提出的专用于分析相关矩阵的人工神经网络BrainNetCNN[12],十字形卷积核。
所用神经网络分为卷积层、全连接层和Dropout层3个部分。其中Dropout层的作用是以一定比例随机断开部分神经元连接,从而防止过拟合。所用神经网络结构为6个网络层,包含3个卷积层、2个全连接层和1个Dropout层。网络结构示意图见图2。
1.4.3 模态融合 网络融合指将两种模态的数据分别输入到对应的神经网络中,输出中间提取到的特征图,对两种模型输出的特征向量进行拼接操作,再经全连接层进一步加权处理,直至得到最终分类结果。网络融合可充分利用各种模态包含的信息,达到提升总体分类精度的效果。具体融合过程见图3。
2 结果
本研究中纳入StD组患者CES-D评分(25.61±5.96)分,HAMD(10.64±2.69)分;NC组CES-D评分(5.89±4.13)分。
将经预处理的结构像数据输入到3DCNN中,随机将数据集分成2部分,其中70%作为训练集,用于训练网络模型和调整网络参数,30%作为测试集,用于测试模型的分类效果和泛化能力。采用十折交叉法进行验证,结果显示单独使用结构像进行分类的精度为73.02%。自经预处理的功能像数据中提取相关矩阵,输入到BrainNetCNN中,采用相同训练方法,单独使用功能像数据进行分类的精度为65.08%。将2种模态数据输入到融合后的神经网络中,经过150次训练后,十折交叉验证结果显示最终分类精度可达78.57%。ROC曲线及相应评价指标见图4,ROC曲线距离左上角越近,其AUC越大,代表模型的性能越好。不同模态评价指标的对比结果显示采用模态融合方法可提高分类精度(表1)。本研究方法与其他分类方法比较见表2。
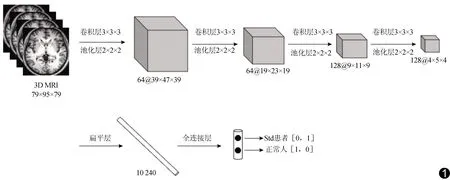
图1 3D-CNN网络模型示意图 输入MRI数据作为神经网络,输出两种分类结果之一,所用人工神经网络包含卷积层、池化层和全连接层,其中分类标签[0,1]代表StD患者,[1,0]代表正常人
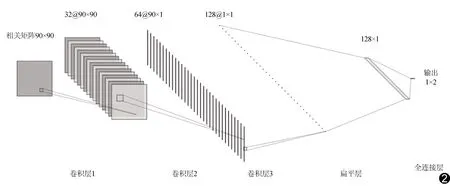
图2 BrainNetCNN网络模型示意图 输入功能连接相关矩阵作为神经网络,输出为StD患者和正常人2种分类结果之一, 所用人工神经网络包含卷积层、池化层与全连接层
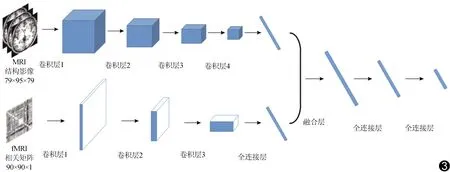
图3 网络融合结构示意图 输入预处理后的MRI和fMRI功能连接相关矩阵作为神经网络,中间的特征图经过全连接层处理输出2个64×1的特征向量,再将2个向量拼接起来,得到1个64×2的向量,最后经过全连接层处理得到最终二分类结果。所用人工神经网络包含卷积层、池化层与全连接层
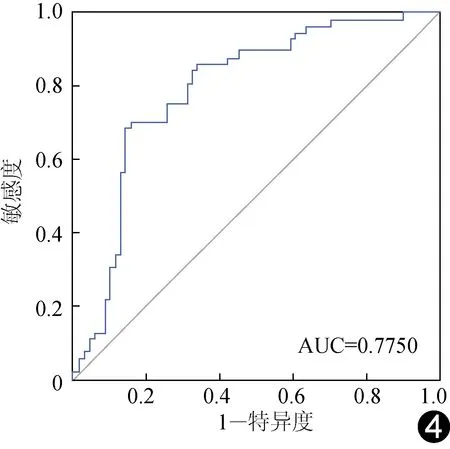
图4 采用模态融合方法得到的ROC曲线
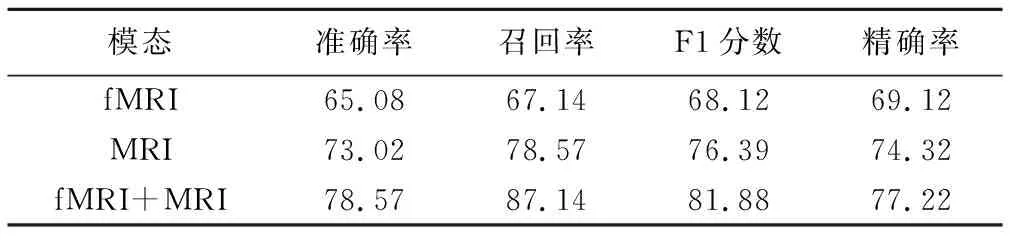
表1 分类结果比较(%)
3 讨论
CNN是主流DL代表算法之一[13]。本研究将CNN分别用于结构MRI和fMRI,利用构建的神经网络模型分类识别StD患者,同时采用网络融合技术综合考虑不同模态影像数据所含特征[14],结果显示DL方法比传统的机器学习方法表现更好,验证了所提出方法的有效性。
以往使用单一模态成像只能获取部分信息。采用多种模态相结合,获取的组织形态与功能信息互为补充,更有利于诊断与治疗疾病。传统CNN卷积核一般为矩形。本研究采用十字形卷积核,其优势在于能有针对性地分析各脑区之间的连接强度,从而提取出更具表现力的特征。本研究提出的多模态CNN集成分类效果比单一CNN表现更好,且综合分析结构像和功能像较单独分析一种模态成像能够获得更高的分类精度,为诊断StD提供了一种新思路。
DL技术比传统浅层机器学习技术更为强大,其优势在脑部疾病的诊断及研究中表现尤为突出[15]。相较于传统机器学习方法,本研究采用DL方法训练得到的神经网络模型具有更好的性能表现。一方面,DL技术无需手工提取特征,省去了人工提取特征步骤,并可提取到更高维度的特征;另一方面,影像数据为高通量、高维度数据,利用DL技术能从数据中学习高度复杂和抽象的特征信息。

表2 分类方法比较
StD患者在脑部结构变化之外还存在功能方面改变,例如在结构方面,StD可致苍白球和中央前回部分结构变化,表现为灰质体积减少[16],在功能方面则可使默认网络与腹侧纹状体之间的功能连接显著增强[17]。采用多种模态数据能够综合各方面特征,相较于单模态影像信息得到更优结果。本研究结果显示,采用多模态影像数据结合方法可比采用单一模态数据显著改善准确率、召回率、精确率及F1分数。
本研究提出的方法具有以下优点:影像预处理部分不需要分割,可降低计算成本,避免分割引起的误差;通过融合不同模态,模型的最后几层集合了2种模态的不同特征,展现出更为优异的分类性能[18]。
