改进的YOLOv3红外图像行人检测算法
2020-09-24史健婷张贵强
史健婷, 张贵强
(黑龙江科技大学 计算机与信息工程学院, 哈尔滨 150022)
0 引 言
计算机视觉技术在安防监控、车载无人驾驶等领域有着广阔的发展前景[1-2]。行人检测技术是研究和判断所给图像或者在每帧视频序列中,是否存在需要检测的行人,并且能够准确和快速的找到目标具体位置的技术。近年来,道路安全问题越来越引起人们的关注,在人们寻找降低交通事故发生的方法同时,行人检测技术应运而生。尤其是在无人驾驶技术方面,有关行人检测技术方面的研究得到广泛的关注[3]。
传统的可见光技术无法应用于夜间或者无人驾驶领域。与传统情况相比,红外热成像仪基于物体相对温度的信息,受各种因素影响较小,在诸多方面有着广泛的应用,但是红外设备采集到的图像没有色彩,在行人检测时,准确率较低。传统的行人检测算法有Haar小波特征[4]、HOG+SVM[5]、DPM[6]等,传统的行人检测主要通过人工设计的方法,提取图像特征,识别和分类进行检测目标。然而传统的算法,设计复杂,尤其是在复杂的场景中难以设计出合理的方法,权值参数难以得到较准确的数值,泛化能力不强。近年来,卷积神经网络(Convolutional neural network,CNN)在行人检测研究方面取得了重大的突破[7]。卷积神经网络(CNN)通过大量的数据能够自动学习出目标的原始特征,相比于手工设计的特征而言,具有更强的判别能力和泛化能力[8]。在RCNN算法提出之后,深度学习迎来了一个新的热潮[9-10]。一系列的改进算法,包括Fast RCNN[11]、Faster RCNN[12]、SSD[13]、YOLO[14]等在多个图像处理领域的表现超越了传统算法。相较于传统方法,深度学习方法在检测效果上既提高了效率又提高了检测速度,之后出现了YOLOv2算法、YOLO9000算法和YOLOv3算法。其中YOLOv3针对小物体检测以及红外图像行人检测,采用DarkNet或者ResNet等主干网的分类器,具有搭建环境简单,背景检测失误率低,通用性强等优点。然而相比于其他RCNN系列目标检测算法,YOLOv3识别物体的精准性差,召回率低。针对上述问题,笔者改进YOLOv3算法以提高红外图像行人的检测精准度。
1 YOLOv3网络算法结构
2015年,Redmon和Ali Farhadi等提出基于单个神经网络的YOLO目标检测系统,YOLOv3算法是在YOLO和YOLOv2算法基础上改进的,其结构主要包含网络输入、结构和输出。
1.1 网络输入
YOLOv3网络一般输入大小为320×320、416×416、608×608,文中介绍416×416,大小必须是32的整数倍,这样才有利于后面的训练测试和分析。YOLOv3网络主要采用5次下采样,YOLOv3网络以DarkNet-53主干网路为基础,每次采样的步长为2,因此主干网络的最大部幅为2∧5=32。DarkNet-53的结构如图1[15]所示。
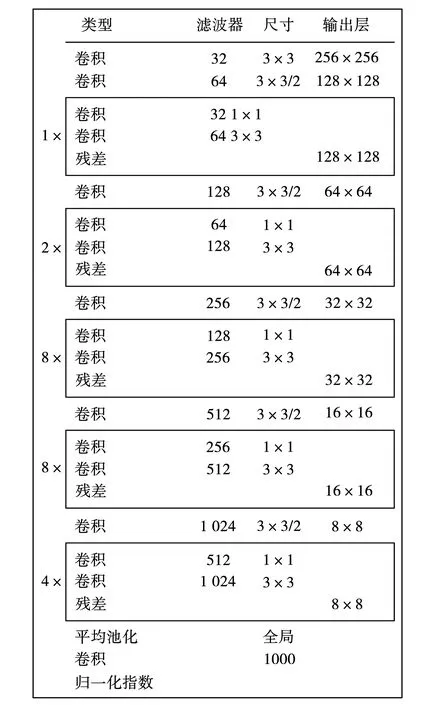
图1 DarkNet-53的结构Fig. 1 Structure of DarkNet-53
1.2 网络结构
为了产生更好的分类效果,首先YOLOv3算法训练一个DarkNet-53的主干网络,对于检测小目标来说通过训练能学习到想要学习的特征,其次检测模型做预先初始化操作。通过不断实验,发现利用主干网络DarkNet-53训练产生的结果,确实得到更好的效果。与其他主干网络如ResNet相比,在速度方面快了很多,训练简单方便,网络结构相比于ResNet少了很多。同时,DarkNet-53采用了ResNet这种跳层连接方式,取得了不错的效果。
YOLOv3网络是一个全卷积网络,使用了DarkNet-53的前面52层,但是没有使用全连接层以及池化层的,而且使用了许多残差结构进行跳层连接。残差结构的使用有助于网络结构在很深的情况,保持收敛性,使得训练进行下去,而且网络越深,训练的结果越好,分类和检测得到的效果越理想,而且残差中的1×1的卷积,在一定程度上减少了计算量。YOLOv3使用三种类型降采样,分别为32倍、16倍和8倍降采样,为了保证网络越深的特征所展现的效果越好,在使用降采样进行检测之后,进行上采样,对深层特征进行目标检测。利用YOLOv3在下采样产生浅层特征,进行route层操作。之后进行张量拼接,将DarkNet中间层和后面的某一层的上采样进行拼接。
1.3 输出
以输入416×416×3为参考,图1输出三种尺度分别为52×52、26×26、13×13,这样使网格会有个中心位置,可以检测不同尺寸大小的目标。网络输出需要对锚框进行预测,以及对特征层的每一个网格预测三个边界框,对于每一个边界框分别预测每个框的位置,检测物体预测的位置和M个类别。边界框坐标预测公式为:
bx=σ(tx)+cx,
by=σ(ty)+cy,
bw=pwetw,
bh=pheth,
式中:tx、ty、tw、th——边界框的预测输出;
cx,cy——网格的坐标;
pw、ph——预测前的边界框大小,即锚框的宽和高;
bx、by、bw、bh——得到的边界框的中心坐标和大小。
YOLOv3算法的置信度公式为
式中:Pr(o)——边界框是否有对象的概率值;

Cij——第i个网格的第j个边界框的置信度。
假设一个图片被分割成A×A个网格,且有N个锚框。即每个网格有N个边界框,每个边界框有四个位置参数,L个置信度。设置一个参数,有Pc类别概率,当置信度表示为当前边界框含有物体的情况时,最终模型输出层的输出维度为
Z=A×A×[N×(4+L+Pc)],
式中:Z——输出层的输出维度;
A——一个网格长度;
N——锚框的个数;
Pc——类别概率。
2 改进的YOLOv3检测算法
YOLOv3网络相比于v1、v2及其他网络结构,更加注重对于特征的利用,在整体网络结构中加入了特征融合,使用route层将三个检测尺度所对应的13×13、26×26和52×52维度的特征信息从网络的浅层传递到深层。结合浅层信息,在一定程度上能提高输入检测器特征的丰富性。但从整体网络结构设计上,YOLOv3只是融合了浅层特征信息,没有对融合后的特征进行优化,整体特征相对“粗糙”。同时经过实验验证,使用YOLOv3模型对红外行人目标进行检测时,存在着目标漏检等问题。基于上述问题,文中优化YOLO网络结构进行,利用网络结构的特征,优化主干网络,加强了模块与模块间的特征传递,针对于网络检测部分,二次优化浅层和深沉融合后的特征信息完善信息的丰富度。
2.1 强连接主干网络
在YOLOv3中,其主干网络借鉴了残差结构的思想,通过使用短跳层完成了残差模块的设计。将原来YOLOv2的层级结构替换为了模块级联结构,且依靠残差的优势加深了整体网络结构的深度,在一定程度上提升了检测能力。但是对于文中的检测目标而言,其具有形态小、特征少的特点,虽然采用了残差结构但对于特征的提取及利用仍不足。因此,在原残差结构的基础上对模块与模块之间的连接进行了强化,在每种维度的残差模块组中,前后两个残差模块都会融合上一个维度残差模块的特征信息。具体模块与模块间的连接如图2所示。
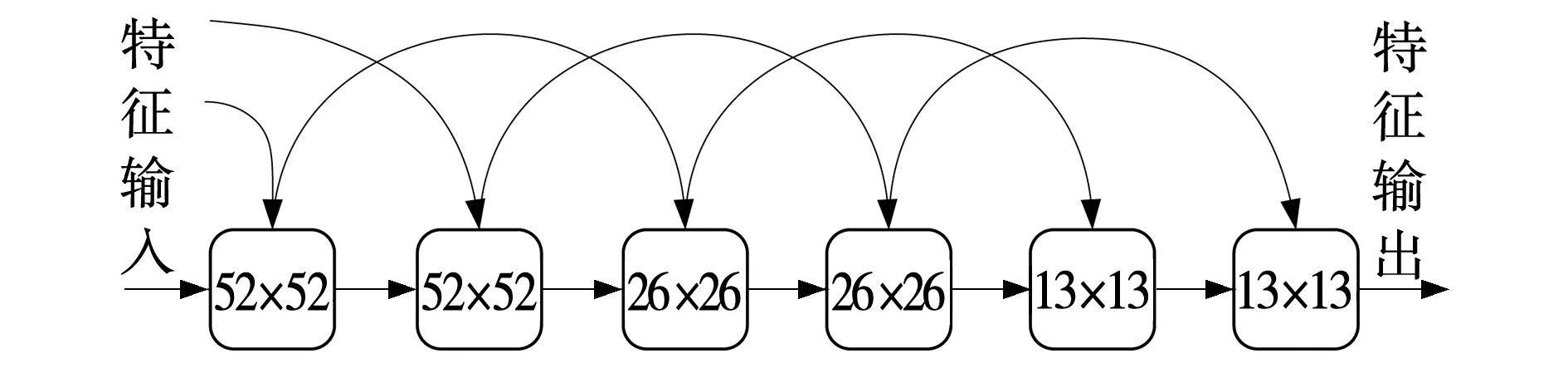
图2 模块与模块的残差连接Fig. 2 Residual connection between modules
优化后的主干网络与原网络相比增加了上下相邻维度间残差模块的首尾连接,使层网络的特征信息能够依靠这些连接传递到深层。网络的浅层特征信息里包含有丰富的目标形态特征,通过强化连接的方式,不断融合目标的形态特征与语义特征,相比于原主干网络,强化连接后网络特征丰富度有了大幅度的提升。
2.2 编解码特征处理
在YOLOv3中设置了13、26和52三个尺度的检测器,在26和52尺度的检测模块中融合主干网络中相应尺度对应的最后一个残差模块的输出。文中优化了对于该特征的融合,提升特征融合后的特征表征力。在完成特征融合后,重构优化了设计的编解码模块融合后的特征模块,所使用的两个编解码模块结构如图3所示。

图3 编解码模块Fig. 3 Encoding and decoding module
从图3可以看出,特征融合后特征图经历一个缩放的过程即为编码过程与解码过程。首先通过下采样的方式将特征图逐层缩小到13×13,之后再通过上采样将特征图还原到与检测器所对应的尺寸。通过route层将浅层和深层的特征融合后,先经由下采样操作获取全局特征,之后再经上采样放大特征图提取局部特征,最终经由常规卷积操作进行特征整合。上下采样能够更加充分的利用浅层网络的表征信息,即通过全局特征获取目标区域位置信息,再通过局部特征获取目标的结构纹理信息,能够对目标进行更精准的定位及检测。基于上述网络优化策略,将优化后的网络命名为YOLO-Ⅱ(Intimate)。
3 实验结果与分析
实验环境配置如下:操作系统为Ubuntu 18.04,神经网络框架为Darknet,CUDA版本为10.0,cuDNN加速包为7.6.4,使用RTX2080ti型号的GPU进行卷积计算加速。
3.1 实验结果
该实验所采用的数据集来自OSU Thermal Pedestrian Database。首先对数据集进行数据清洗,挑选出易标注样本1 500张,难标注样本400张和负样本200张,组成2 100张的训练集,300张易标注样本和200张难标注样本组成500张测试集。YOLOv3在原先改进的Densenet基础上,借鉴了Faster RCNN算法中的anchor机制,通过anchor粗略估算目标的位置区域。当anchor的尺寸与目标面积不相符时,会对检测精度造成直接影响。默认设置的anchor大小并不适用于本次数据集,使用K均值聚类的方式重新计算出适用于小目标行人数据集的九个anchor。新计算得到的九组尺寸分别为:(15,40)、(21,43)、(17,56)、(23,59)、(29,52)、(21,73)、(27, 73)、(34,78)和(47,60)。经过多次设置不同超参数迭代训练,最后取最优的训练结果,通过对训练日志可视化,可得出损失函数Loss曲线及IOU曲线的变化过程,如图4~5所示。

图4 不同模型的Loss曲线Fig. 4 Loss curve of different model
对上述两幅训练日志图进行分析,从图4的Loss曲线变化图可以观察到,当网络迭代到7 500次后损失函数趋于稳定无明显下降,之后继续进行迭代确保网络完成学习。通过与图5的YOLOv3的Loss曲线变化图进行对比,可以明显的观察出YOLO-Ⅱ整体起伏较小,网络较为稳定、鲁棒性好。对IOU曲线进行分析可以明显的观察到,当网络迭代7 500次时IOU值在0.95~1.00之间轻微震荡,IOU值较高,预测框区域与目标区域的拟合性良好,同YOLOv3的IOU曲线图对比也能明显的对比出二者的优劣,说明了强连接网络的对于目标位置的预测有一定的提升帮助。
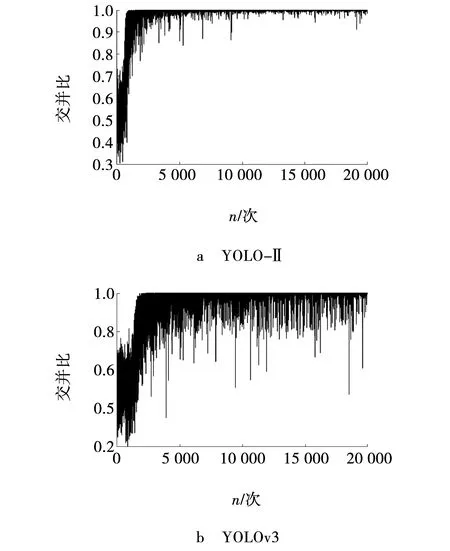
图5 不同模型的IOU曲线Fig. 5 IOU curve of different model
3.2 模型检测性能的对比
根据训练得到的两个模型,对YOLO-Ⅱ与YOLOv3以及SSD算法进行横向对比测试。为了更详细的反映优化后网络鲁棒性的提高,增加了测试指标进行对比,测试结果如表1所示。召回率与准确率曲线,如图6所示。YOLO-Ⅱ算法行人检测的实际结果如图7所示。

图6 召回率与准确率曲线对比Fig. 6 Comparison of recall and accuracy curves
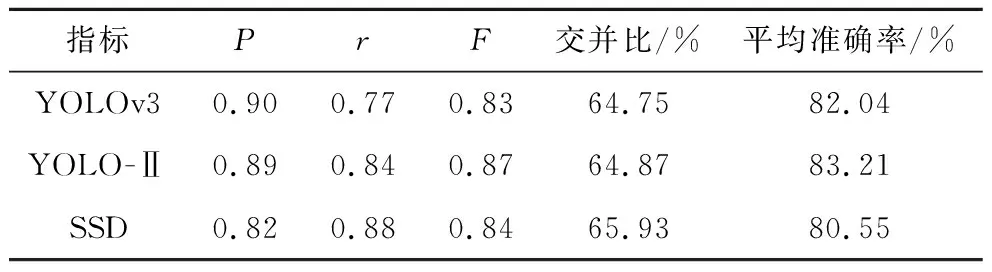
表1 模型检测性能对比Table 1 Comparison of model detection performance

图7 利用YOLO-Ⅱ算法实现行人检测Fig. 7 Actual results of YOLO-Ⅱalgorithm application
从表1可以看出,YOLO-Ⅱ的整体鲁棒性要优于YOLOv3,在召回率的对比中,YOLO-Ⅱ高于YOLOv3 0.07%,说明对于目标的查全率YOLO-Ⅱ更好,且IOU数值也更优。YOLO-Ⅱ与SSD的对比,YOLO-Ⅱ在精度,平均准确率和F等指标上要优于SSD,召回率和交并比两项指标要略低于SSD。综合上述指标分析对于主干网络及检测网络部分的优化在提升网络性能方面有巨大帮助。
从图7可以看出,行人检测测试中可以得出行人检测的准确率,如图8所示。
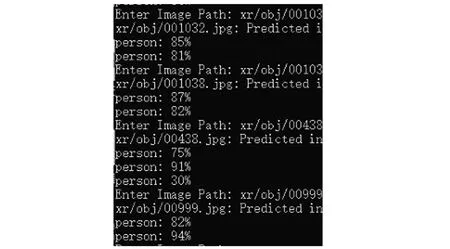
图8 行人检测准确率Fig. 8 Precision of pedestrian detection
由图8可见,除1人外其余行人检测的平均准确率超过83%。1人检测准确率低的主要原因可能存在人工标注失误产生的误差,导致检测不准确,红外图像中的物体亮度与物体的表面温度有关,行人模糊,与树影重叠,导致检测时难以检测出是其他物体还是人。红外图像仅有一个颜色通道,提供的信息更少,并且红外图像往往有分辨率低、物体边缘模糊、含有噪声、对比度较低等问题,使红外图像中能够提取到的特征信息减少[16]。在进行目标检测时候,目标不具有纹理等细节特征,从而导致检测不准确,待检测的行人目标在图像中像素区域小,不易被检测。
4 结束语
提出了一种改进的YOLOv3红外图像行人检测算法YOLO-Ⅱ。优化后的YOLO-Ⅱ对灰度图及小目标的检测能力有明显提升,提高了红外检测的实用性。文中对低像素及小目标的检测环境,根据实际检测情况在YOLOv3的基础上进行优化,借鉴了DenseNet密集连接的改进方案,优化主干网络,加强了模块与模块间的特征传递。对网络检测部分二次优化浅层和深层融合后的特征信息,完善了信息的丰富度,增强了特征信息的传递能力,有效地提高了检测精度。经测试,优化后的YOLO-Ⅱ在红外小目标的检测场景下,检测精度有明显的提高。整体准确率提升1.17%,平均准确率达到83.21%。文中设计的YOLO-Ⅱ网络应用于车载红外摄像机或是交通监测使用的摄像头,能高效地检测夜间来往的行人,提高了夜间驾驶车辆的安全性。
