基于K 近邻分类算法的敏感信息过滤方法研究
2020-09-23路士兵
路士兵
(武警海警学院,浙江 宁波315801)
信息化时代飞速发展背景下,新闻、网络文学等信息,在各类社交平台上快速传播,给每个人提供最新的资讯,但网络技术发展背景下,一些人采取非法手段,在网络中发布传销内容、非法广告以及反动言论等不和谐的信息,污染整个网络环境,给海量文字信息的分享与传播,带来了较为恶劣的影响[1]。因此传统方法参考文献[2],通过构建决策树,对敏感信息进行过滤[2]。但随着网络信息体量的不断增加,传统过滤方法出现了一些弊端,因此提出一个基于K 近邻分类算法的敏感信息过滤方法[3]。此次提出的敏感信息过滤方法,以传统方法为研究基础,在K近邻分类算法的应用下,重新创建决策树,为网络信息的使用安全,提供更严谨的技术支持。
1 基于K 近邻分类算法的敏感信息过滤方法
1.1 划分敏感词汇内容和等级
过滤敏感信息要有一个过滤标准,因此需要划分敏感词内容和等级。构建一个敏感词数据库,用于存储需要被禁止使用的敏感词,还有赌博类的非法广告。按照不同类型的敏感词汇,将敏感词划分为n 个类别,并对每一类别信息,设置3 个敏感等级。
将敏感信息分成三个类别,分别是政治类、色情类以及广告信息类。其中,反动类敏感词汇包括:政治主张、军事主张以及恐怖信息等,此类信息涉及到国家发展、社会稳定、人民团结,因此此类型信息的敏感等级较高。色情类与广告类信息,会给社会风气带来不良影响,给人的精神方面、财产方面,带来了极大的隐患,因此此类信息的级别,稍低于反动类敏感词汇。
针对上述划分的三个敏感级别,将每一级别中所有的敏感词汇作为过滤标准,构建敏感信息决策树,并利用K 近邻分类算法,设置敏感信息过滤逻辑。
1.2 基于K 近邻分类算法创建敏感信息决策树
首先要从敏感信息数据库中,提取敏感词汇,并将这些敏感关键词,添加到决策树的基本结构中,按照敏感词第一个关键字的拼音首字母,对敏感关键词进行排序,构建决策树的根目录子树。
每一个子树中的敏感信息,要按照第一个关键字的第二、或第三个拼音字母,或第二个关键字的首字母进行排序。需要注意,构建敏感信息决策树的子树信息时,还要将敏感词汇的拼音包含进去,防止类似敏感词汇,在过滤时被遗漏。
当敏感信息决策树中存在孩子节点时,且该节点包含的信息,不是敏感信息的最后一个关键字,那么将此类节点作为非叶子节点;当敏感信息决策树中,不存在孩子节点时,且包含的信息,是敏感词的最后一个关键字,那么将此节点作为叶子节点;当敏感信息决策树有孩子节点、且包含的信息,为敏感词的最后一个关键字时,那么将此类节点作为伪叶子节点。令isLeaf表示敏感词结束,则各个节点的表现形式,如下列公式所示:

公式中:a 表示非叶子节点的对应值;b 表示叶子节点的对应值;c 表示伪叶子节点的对应值。根据上述内容,将敏感词数据库,建成了一个敏感信息决策树,在进行敏感信息过滤时,大大减少了过滤匹配范围。
例如检测网络文章中,是否存在敏感关键词时,只需要对决策树中敏感词汇所带字的子树进行检测。若敏感词数据库更新,只需要在决策树的相应位置上,直接添加新的敏感关键词即可。
将K 近邻分类算法,与创建的决策树相结合,对网络中的敏感信息,进行集中一次过滤。
具体步骤如下:
首先将待分类的敏感词数据库中的敏感关键词,看做一个整体,假设该整体为集合W,对其进行向量化处理;假设集合W中共包含i×j 个文本,注意i>j,计算矩阵Wi,j的协方差矩阵Vj,j;根据所得结果计算其特征向量,分别用x1,x2,…,xn、y1,y2,…,yn来表示;计算所有个特征值,对协方差矩阵的权重和累计权重,计算结果如下列公式所示:
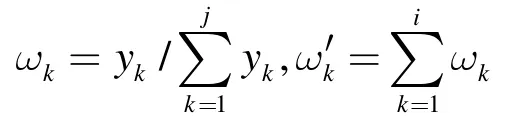
公式中:k∈n,表示k 个特征向量。根据权重大小确定降维后的矩阵维数,再按照从大到小的顺序,将特征值对应的特征向量,作为投影矩阵。按照上述步骤设置决策树的过滤逻辑,实现基于K 近邻分类算法的敏感信息过滤。
2 测试与分析
将此次研究的过滤方法,作为实验组测试对象;将传统过滤方法,作为对照组测试对象,分析不同方法应用下,两个测试组的敏感信息过滤效果。
设定三个敏感词汇A、B、C,分别从政治、经济、体育三个方面进行敏感词搜索,下图1 是设定的3 个敏感信息,在网络中的占比情况。

图1 敏感信息在网络信息中的占比
分别利用两种敏感信息过滤方法,检测并过滤其中的敏感信息,实验共进行5 次。下表1、表2、表3,是两个测试组的敏感信息过滤准确率统计结果。
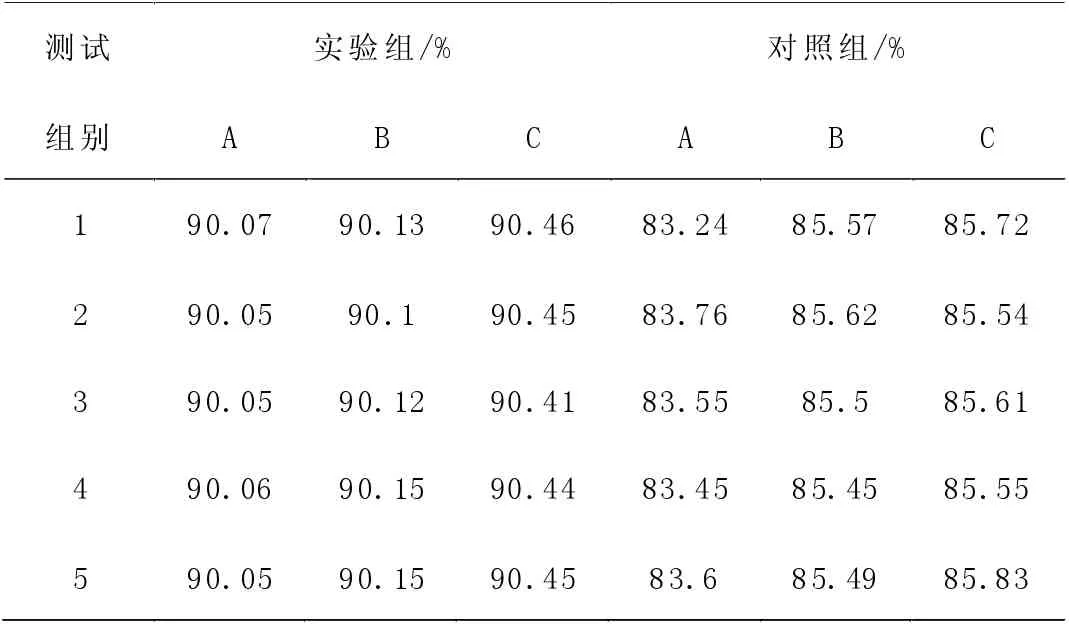
表1 政治领域敏感信息过滤准确率统计结果

表2 经济领域敏感信息过滤准确率统计结果

表3 体育事业敏感信息过滤准确率统计结果
根据表中的测试结果可知,在三个领域中,实验组政治领域的敏感词过滤准确率平均值为90.05%;对经济领域的敏感词过滤准确率平均值为90.13%;对体育领域的敏感词过滤准确率平均值为90.39%。而对照组对政治领域的敏感词过滤准确率平均值为83.53%;对经济领域的敏感词过滤准确率平均值为85.58%,对体育领域的敏感词过滤准确率平均值为85.58%。综合上述分析可知,此次研究的过滤方法,在K 近邻分类算法的控制下,过滤出的敏感信息准确率,总体提升了5.29%。可见提出的敏感信息过滤方法满足研究要求。
3 结论
互联网时代,我们利用海量的网络信息解决生活和工作任务,而此次研究的过滤方法,帮助净化网络信息,维护网络安全与社会稳定。但根据K 近邻分类算法的基本特点可知,该算法还可以与其他算法结合使用,因此可对K 近邻分类算法进行改进,进一步优化敏感信息过滤结果,通过更加详细的信息分类与相似度计算,得到更为完整的网络敏感信息。
