基于多模态神经网络生成图像中文描述①
2020-09-22陈兴
陈 兴
(河海大学 计算机与信息学院,南京 211100)
生成图像描述是自然语言处理和计算机视觉的热点研究问题,其任务主要为理解图像中物体和场景等语义信息并采用近似于人类语言的描述形式表达出来,生成符合一定语法规则的文本信息.图片描述作为解决图像信息到文本信息的跨模态转换的重要方法,可广泛应用在人机交互、视觉辅助、图像标注等领域.
Vinyals 等[1]提出了GoogleNIC 模型,借鉴机器翻译中常用的编码解码方式,分别采用InceptionV3[2]预训练模型作为编码器提取图像特征信息,长短时记忆网络(LSTM)[3]作为解码器生成图像描述.Xu 等[4]在解码过程中加入注意力机制,更加关注图像的局部特征.邓珍荣等[5]也应用了注意力机制和卷积神经网络提取图像特征,与Xu 不同的是采用了循环门单元网络(GRU)[6]取代LSTM 网络以此生成图像的描述.
随着生成对抗网络的发展流行,生成对抗机制[7]也逐渐被应用到图像描述生成任务中.例如Dai 等[8]通过控制条件对抗网络[9]中噪音Z 来生成图像的描述,并通过实验证明加入对抗机制生成的描述在该任务上优于其他方法,生成的图像描述在自然性和多样性两方面都有所提高.Shetty 等[10]同样采用生成对抗网络结构,通过对抗机制提高语句多样性.其中生成器利用CNN 提取图像特征,在解码过程引入了目标检测模型,额外的加入RCNN[11]检测图像中具体目标图像,通过加入图像的先验知识来提高生成描述中包含图像目标的概率.文献[12]也通过加入先验知识来改进模型生成质量,提出了基于主题模型的图像描述生成模型,不同于文献[10]加入目标检测,而是通过预测图像的主题词的概率分布来实现先验知识的获取.这种加入先验知识的方法虽然可以获得较好的生成效果,但是增加了生成的计算和时间成本,而且过度依赖于先验知识,一旦接收了错误的先验知识,生成的描述也会受到影响.
以上工作都是基于英文领域的图像描述生成方法.因为中文词汇和语句表达的特殊性,在理解中文语义信息往往需要断句和分词,且中文语法表达极为灵活,句式更加多变,因此相比较英文的图像描述难度更大.Li 等[13]在Flickr8K 数据集基础上通过机器翻译和人工标注两种方式提出构建首个中文图片描述的Flickr8K-CN 数据集.Wu 等[14]构建首个大规模的图像中文描述数据集AIC-ICC,包含30 万张图片和150 万句的中文描述.刘泽宇等[15]基于编码解码结构构建了针对图像中文描述的生成模型,并在Flickr8K-CN 数据集上验证了该模型的有效性.
比较以上,本文提出了多模态神经网络生成图像中文描述模型,不同于现有的图像中文描述方法,(1)本文采用FastText[16]预训练模型对词汇进行词嵌入表示.相较于常用的one-hot 编码,一个词汇的表示往往需要词库大小的维度,这个问题在中文词汇上尤其严重.词嵌入表示形式维度相较于one-hot 编码维度更小,可以更准确的保留词汇之间的语义和用法的相关性;(2)相较于利用注意力机制放大图像的局部特征,本文更加关注图像的整体特征,通过融合编码器设计,将卷积神经网络中提取到的图片全局特征与图片对应的中文描述的词向量表示融合编码;(3)损失函数由两部分组成,一部分衡量生成的词向量矩阵与真实词向量特征矩阵的余弦距离,另一部分衡量生成描述单一词汇与目标之间的复现比例.
本文在数据集AIC-ICC、Flickr8K-CN 都进行了实验,并通过双语评估研究(BLEU)[17]值的客观指标进行评估,与现有的模型进行对比发现BLEU 值有不同程度上的提高.
1 图像中文描述网络结构
本文实现图像的中文描述同样采用encoder-decoder结构,其中encoder 模型包含FastText 词嵌入模型和卷积网络,前者生成语句的词向量矩阵,后者提取图像的全局特征,encoder 将成对的语句、图像〈S,I〉进行编码,最终融合为既包含中文描述又包含图像信息的多模态特征矩阵.Decoder 采用多层LSTM 模型对多模态特征矩阵进行解码,通过计算余弦相似度得到解码结果.
1.1 FastText
词汇如果通过常用的one-hot 编码方式进行表示,例如在表示词汇“运动员”时,需要在“运动员”对应的维度上设置为1,其他维度上设置为0,这就意味着每一个词都需要独占一维空间.那么,一个词汇的维度等于词表长度,该词向量中绝大多数的维度都没有被利用到.同时,词汇one-hot 编码形式无法反映出词汇之间的相关性.本文采用的FastText 预训练模型对词汇进行词嵌入表示可以大大减少one-hot 编码带来的冗余和稀疏问题.一个包含104量级大小的词表,在FastText中只需要102量级就可以表征,通过余弦距离的计算也可以反映词汇之间的相关程度.
FastText[16]一种高效快速的文本分类模型.该模型首先将文本词汇通过n-gram[18]格式分解,然后和原单词相加,得到的文本序列(x1,x2,···,xn-1,xn)作为网络的输入,通过单层隐藏层学习,最终输出该文本的分类类别.FastText 采用分层Softmax[19]根据类别频率构造霍夫曼树,相较于标准的Softmax层计算的时间复杂度从O(kh)下降到O(h(log2k)),其中k为类别数量,h为文本特征维数,训练和分类效率都得到了较大的提升.FastText 模型如图1所示.

图1 FastText 模型结构
本文中利用FastText 模型对图像描述中的每个词汇转换为词向量形式,计算两个词向量的余弦相似度,其计算公式为式(1).计算实例见表1.

若余弦值越大,则两个词汇在高维空间的表征形式越相近,说明两个词汇有着相近的语义或强相关的用法,所以FastText 模型在词向量表征学习具有良好的性能.

表1 余弦相似度实例
图2为将若干个词向量通过PCA 降成两维后的可视化表示.可以看出,“教师”与“授课”、“学校”、“老师”等词汇相关度较高,在图中距离也较近.以“教师”、“运动员”、“甜点”、“商品”为关键词的词汇在图中形成4 个词汇区域,可见FastText 在表征词汇上可以很好地保留其语义信息,词汇的相关性也得以体现.
1.2 卷积网络提取图像特征
卷积神经网络是一种有效的图像特征提取方法,广泛应用在图像识别、图像检测等相关任务上,并且表现出相当好的性能.卷积网络通过局部区域感受野和权值共享的设计,大大减少了模型的复杂度,使得模型更加易于训练.卷积网络的网络结构也随着问题的逐渐复杂而逐渐加深[20-22].

图2 部分词向量的可视化表示
本文中使用了类似于VGG-16 的卷积神经网络提取图像特征,如表2所示,输入图像首先经过裁剪和随机翻转增加图像的多样性,最终变形为224×224 的三通道RGB 图像,经过第一个卷积模块,包含两次64 个3×3 的卷积层,每层卷积层使用ReLU 激活函数,最终采用最大池化层向下采样,输出128 个112×112 的特征图;第二个卷积模块与第一个卷积模块一致,输出256 个56×56 的特征图;第三、第四、第五卷积模块包含3 个卷积层,经ReLU 激活函数后采用平均池化层降采样,进一步压缩和编码图像,输出512 个7×7 的图像特征图;最后经过两个全连接层,大小分别为4096、300,最终输出1×300 的图像全局特征向量,该特征向量的特征维数与FastText 所编码的文本词向量特征维度一致.

表2 卷积神经网络结构
1.3 图像中文描述生成模型
如图3所示,图像中文描述模型由两部分构成,融合编码器和LSTM 解码器.
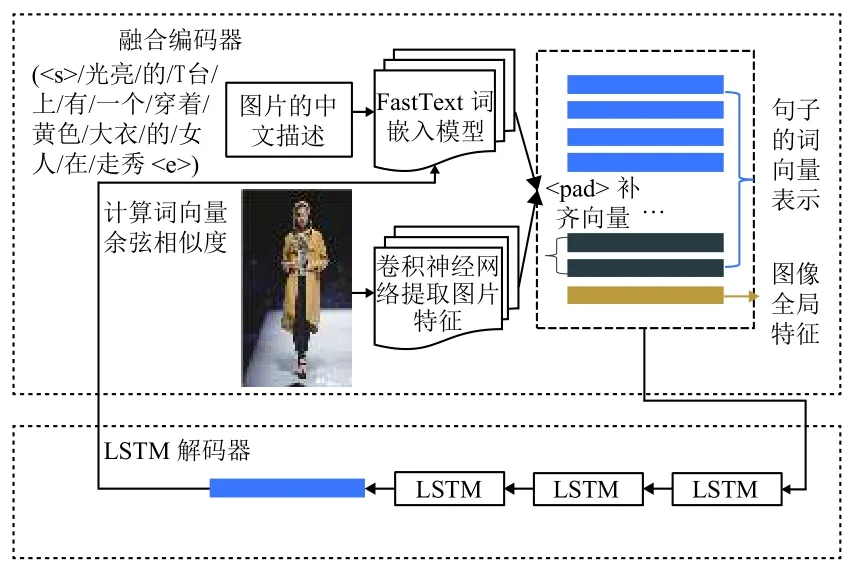
图3 图像中文描述生成模型
融合编码器对成对的语句和图像〈S,I〉进行编码.图像的中文描述在编码之前首先需要分词,将原始的中文描述S 转换为多个词汇的序列结构{w1,w2,···,wn-1,wn},其中wi,i∈(1,n)表示一个中文词汇,词汇结构通过FastText词嵌入模型进一步转换为(n×300)的词向量矩阵.与描述文本对应的图像送入表2所示的卷积神经网络提取图像的全局特征,生成的图像特征,最终对两个编码模型的生成结果以拼接的形式整合为((n+1)×300)的多模态融合特征矩阵.
融合编码器所编码后形成的多模态特征矩阵依赖于LSTM 网络作为解码器进行解码,LSTM 网络为三层,最终解码生成的(1×300)词向量在FastText 词嵌入模型中计算余弦相似度,寻找与该词向量最相似的词汇,作为本次解码的结果.
图4进一步说明了多模态特征矩阵的解码过程,首先图像I 经过如表2所述的卷积神经网络中得到图像的全局特征向量 {s},{s}与<start>开始标记对应的词向量{v0}融 合为多模态特征矩阵在t1时刻输入到LSTM网络中(事实上,为了训练方便固定了多模态特征的大小,其中长度不足的用<pad>标记进行补齐),经过三层LSTM 网络对输入多模态特征矩阵{v0,s}进行解码得到词向量 {v1},{v1}通过FastText 词嵌入模型计算余弦相似度可以得到该词向量所代表的具体词汇{y1}.在t2时刻将t1时刻的输入{v0,s}与 词向量{v1}融合为新的多模态特征矩阵{v0,v1,s}作为此时LSTM 网络的输入,直到生成的词向量{vm}代表的词汇{ym}为结束标记<end>为止.其中序列{v0,v1,···,vm,s}为最终解码得到的多模态特征矩阵,{y0,y1,···,ym}表示经FastText 模型后生成的词汇序列.其中{y0}代表<start>开始标记.

图4 多模态特征矩阵的解码过程
1.4 损失函数
在one-hot 编码中,词向量每一个维度的值都为0 或1 的离散型数据,可以选择交叉熵函数作为损失函数,最小化损失函数减少生成词向量和目标词向量的距离.本文为了降低one-hot 编码形式带了冗余,采用FastText 模型得到每个词汇的词向量,也就是说,在产生最终词汇序列{y0,y1,···,ym}之前,必然会有与之相对应的多模态特征矩阵{v0,v1,···,vm,s}.
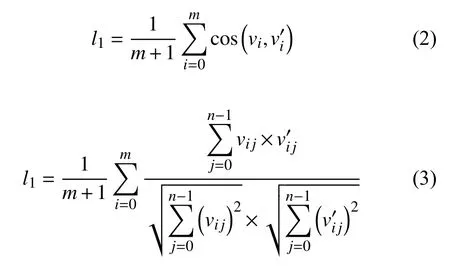
设{w0,w1,···,wm}为图像I 的生成语句目标.词汇序列{w0,w1,···,wm}经FastText 模型可进一步得到该序列在词空间上的表示那么衡量生成的词向量矩阵与真实词向量特征矩阵平均余弦相似度为:
其中,m+1表示词向量的个数,n为词向量的维度大小.
l1值越大表明生成的词向量矩阵和目标矩阵越相似.l1值严格限制了词向量的序列,即词向量vi仅和计算相似度,如果vi与(i≠j)相似但在l1中无法得到奖励,于是需要进一步量化生成描述中单一词汇与目标之间的复现比例,即:

最终的损失函数可以表示为:

其中,λ为平衡两种量化指标的因子,在实验中设置为0.1.最小化损失函数l即意味着最大化词向量矩阵{v0,v1,···,vm} 与余弦相似度,和最大化词序列{y0,y1,···,ym} 在 目标词序列{w0,w1,···,wm}中的复现比例.
2 实验与结果分析
2.1 数据集
目前公开的图像中文描述数据集有AIC-ICC 以及Flickr8K-CN.其详细信息如表3所示.

表3 图片中文描述数据集(单位:K)
由表3可见,AIC-ICC 数据集共包含30 万张图像和150 万句图片描述,本文主要选择该数据集进行实验,其中AIC-ICC-Train 的21 万张图像作为训练集,AIC-ICC-Valid 的3 万张图像作为验证集.数据样本如图5所示.

图5 AIC-ICC 数据实例
2.2 实验设置
本文采用结巴分词对中文描述进行分词,统计语句经过分词后的句子长度.如图6所示,训练集分词后的最大句子长度为32;除此之外,加入<start>和<end>标记向量作为语句起始和结束标志,通过FastText 产生的语句描述词向量矩阵固定为(34×300),当语句长度不足34 时,使用<pad>标记进行补齐,FastText 中不存在的词向量的词汇用标记<unk>替换.加上CNN 网络提取到的图像特征向量(1×300),所以最终送入LSTM解码器的融合矩阵大小固定为(35×300).

图6 中文分词后的句子长度统计
输入图像大小统一设置为3×224×224,batch_size设置为256,进行5 轮共计约150000 次迭代训练,使用Adam 优化算法,其中学习速率为0.0001,beta1 为0.9,beta2 为0.999.每10000 次迭代完成后保存一次模型,最终在验证集上随机选取测试图片进行测试.
2.3 评价指标
BLEU[17]是2002年提出的衡量生成语句的质量的评价指标.最先应用在对比机器翻译语句和人工翻译的参考语句之间的相似度,衡量机器翻译所生成的质量好坏,现已广泛应用在生成式的自然语言评价上.BLEU 针对一元词汇、二元词汇、三元词汇和元词汇分别又有BLEU-1、BLEU-2、BLEU-3、BLEU-4.其公式为:

其中,BP为机器翻译长度小于参考语句时的惩罚因子,即:
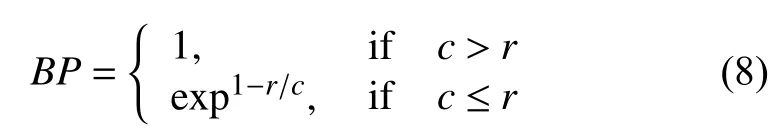
其中,c为机器语句长度,r为参考语句的长度.pn为:

pn直接反映了机器翻译语句在参考译文的在n元组上准确率.BLEU-1 只考虑1 元组的准确率,BLEU-2 同时对1 元组和2 元组加权求和,以此类推.BLEU值越高,说明模型生成的语句与参考语句越相似,生成语句的质量越高.
2.4 结果分析
在AIC-ICC 和Flickr8K-CN 的验证集上测试本文所提的模型,测试结果如图7、图8所示.每幅图片中共有6 句中文描述,其中第1 句为模型的生成结果,后5 句为数据集中的中文描述,由此可见自动生成中的中文图像描述与图像相关,图像中的人物、物体和场景在描述中都可以准确地表达出来,生成结果与图像真实的人工描述相近.

图7 AIC-ICC 验证集上的测试结果

图8 Flickr8K-CN 验证集上的测试结果
本文选取GoogleNIC、Hard-Attention、Soft-Attention、gLSTM、Multimodal-RNN、CNIC-E 等6 种图像描述生成模型进行对比,其中GoogleNIC、Hard-Attention、Soft-Attention、gLSTM、Multimodal-RNN 模型为Flickr8K 上的测试数据,CNIC-E、本文是在Flickr8K-CN 数据集上进行BLEU-1、BLEU-2、BLEU-4、BLEU-4 指标测试.测试结果见表4.

表4 各个模型的BLEU 值对比
由表4所知,本文所提模型的BLEU 值与现有的模型对比,在BLEU 指数上有不同程度的提高.本文所述模型在Flickr8K-CN 数据集上取得了最好的结果,生成的语句更加贴近人工图片描述的参考语句,符合人类自然语言表达.
3 结论与展望
本文提出的图像中文描述生成方法,首先将描述语句和图像<S,I>进行编码,既包含对中文描述语句的分词表示又包含对图像的全局特征提取,最终语句图像对<S,I>融合为一个多模态特征矩阵.使用三层LSTM模型对多模态特征矩阵进行解码,通过计算余弦相似度得到解码的结果.所提模型生成的中文描述可以准确的概括图像的语义信息.在BLEU指标上优于其他模型.
但是,本文模型仍存在一些问题.例如,对较为复杂的场景和多人物的识别不够准确,生成的语句不够细腻等,仍有待提升的空间.该模型较多的考虑图像的全局特征,而忽略了图像的局部特征的提取,从而导致生成语句在图像的细节上体现不足.未来可以加入注意力机制,加强模型对局部细节的把握.
