基于Stacking的钢板表面颜色预测
2020-09-15刘媛媛赵希庆
刘媛媛 赵希庆


摘要:钢板表面颜色是判定钢板表面耐蚀性能的重要指标,提前预测钢板表面颜色可以为控制钢板表面耐蚀性能提供指导。针对单一模型预测精度较低的情况,提出一种基于Stacking的组合模型。该模型采用两层模式,第一层使用支持向量机、随机森林、GBDT等七个个体学习器作为初级学习器,第二层使用XGBoost作为次级学习器。使用该方法对钢板表面颜色进行预测,结果表明,基于Stacking的组合模型与单一模型相比,在多个性能指标上取得了明显的提升。
关键词:钢板表面颜色;分类;集成学习;Stacking方法
中图分类号:TP181 文献标识码:A 文章编号:1006-8228(2020)08-65-04
0 引言
钢板表面颜色是判定钢板表面耐蚀性能一种重要指标,普通热轧钢板最常见的颜色有红褐色和青黑色两种,颜色的不同对钢板耐锈蚀能力有很大影响,红褐色主要是结构疏松的Fe2O3,容易吸收水分和盐分加速锈蚀,而青黑色主要是结构致密的Fe3O4,可以有效延缓钢板的锈蚀,对于钢板下线后的保存、运输、加工和使用等过程比较有利[1-2],因此生产中更希望获得青黑色的表面,避免红褐色的表面。在这种情况下,如果能提前预测钢板颜色,将能够为钢板工艺参数的调整提供指导,达到获得青黑色表面的目的。机器学习为分类预测提供了大量的模型,本文尝试了一系列单一模型后,发现效果并不理想,在此基础上,提出了一种基于Stacking的钢板表面颜色分类算法,以两层堆叠的方式组合多种分类模型,借助多种模型的优势进一步提高预测精度,并使用交叉验证防止过拟合,以达到更好的预测效果[3-5]。
1 stacking算法原理
集成学习通过构建和结合多个学习器来完成学习任务,通常采用一定的策略将多个弱学习器组合到一起,从而获得比单一学习器更好的性能和泛化能力。集成学习的常用算法有bagging,boosting和stacking等。本文在模型的集成算法选择上,选取了stacking算法,这种算法通常用于异质集成。Stacking算法是由Wolpert[6]于1992年提出的,也称之为stacked generalization,是一种用于异质模型的组合策略。Stacking算法通常采用两层结构,本文使用周志华n,在《机器学习》中的叫法,将第一层学习器称为初级学习器,将第二层学习器称为次级学习器。首先,第一层训练出多个不同的初级学习器,然后,将初级学习器的预测结果作为次级学习器的输入特征,并在此基础上进行训练。在这个过程中,为了防止过拟合现象,通常采用K折交叉验证的方法,这里以五折交叉验证为例,介绍stacking的基本步骤[8-10]。
(1)首先将原始样本分为训练集train和测试集test。
(2)假设我们有n个初级学习器,对任一个初级学习器Ci在训练集train上进行训练,训练集采用五折交叉验证,每次选择其中四份进行训练,在第五份上进行预测,并得到预测结果Ai。同时,将训练得到的模型在测试集上进行测试,得到结果E。这一轮n个初级学习器训练完,将得到n个预测结果和n个测试结果。
(3)把n个预测结果合并成新的训练集train2,把n个测试结果合并成新的测试集test2。
(4)在新的训练集train2上训练次级学习器,并将预测结果在测试集test2上进行验证,测试模型的性能。
2 stacking模型构建
2.1数据标准化
本文所选用的数据由于具有不同的量纲和量纲单位,在计算过程中会导致模型精度下降,为了避免数据之间的量纲影响,需要在训练前对自变量做标准化处理。本文选用Z-score标准化方法,其公式如下所示:其中,x*为标准化后的自变量,x.为标准化前的自变量,μ为所有样本数据的均值,σ为所有样本数据的标准差。
2.2 stacking模型构建
本文模型使用stacking的方式,建立两层架构,第一层组合不同的初级学习器,包括逻辑回归(IR)、K近邻(KNN)、支持向量机(SVM)、决策树(DecisionTree)、随机森林(RandomForest)、AdaBoost、GBDT七个基学习器,第二层使用XGBoost作为次级学习器,使用第一层预测的结果作为特征并对最终的结果进行预测,模型构建过程中,为了减少过拟合,使用了五折交叉验证,模型的总体架构如图1所示。
将数据集按照7:3的比例划分为训练集和测试集,按照图1的框架,构建七个不同的初级学习器,对每一个初级学习器使用五折交叉验证,其中四份用于训练,剩余的一份用于预测,五次计算完毕后,根据索引重新聚合预测结果,得到与原训练集相同样本数的新训练集,即为次级学习器的新训练集;而原始数据集的测试集,在每次初级学习器完成训练后都需要在该测试集上进行测试,由于使用五折交叉验证,每个初级学习器完成训练都会进行五次预测,将这五次预测的结果进行平均,就得到了与原测试集相同样本数的新测试集,即为次级学习器的新测试集。完成第一层建模后,第二层使用XGBoost模型,在上一层生成的新训练集上进行训练,并在新测试集上测试,以得到组合模型的性能参数。
3 基于stacking的钢板颜色预测
本文使用数据集为钢厂的真实数据集,该数据集共647条数据,包含了20个与钢板表面颜色相关的工艺参数,如待温厚度比,轧制道次数,在炉时间,二阶段温度,终轧温度,返红温度,轧制方式等,預测的目标颜色为青黑色和红褐色,为典型的分类问题。本文使用python语言进行数据处理、模型搭建及模型评估。
3.1 模型评价指标
本文使用准确率(Accuracy),精确率(Precision)、召回率(RecaI)及Fl值来衡量模型的性能。其中,TP为青黑色样本分类正确的数量,TN为红褐色样本分类正确的数量,FN为青黑色样本分类错误的数量,FP为红褐色样本分类错误的数量。则准确率公式描述为:
3.2 单一模型和stacking组合模型性能比较
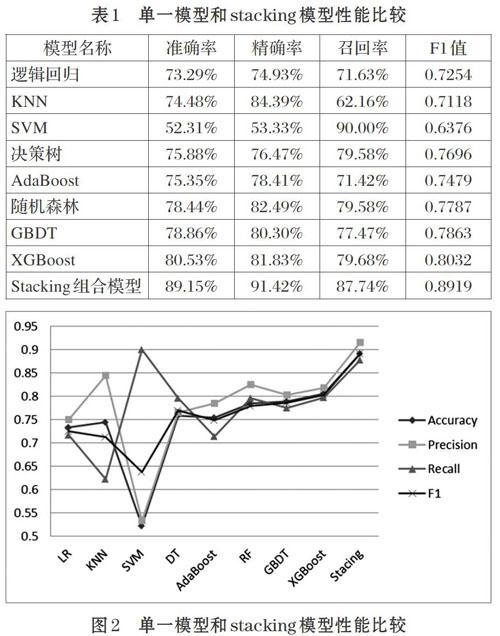
本文的Stacking模型使用了两层的架构,其中,初级学习器使用了lr、KNN、SVM、DecisionTree、Ran-domForest、AdaBoost、GBDT,次級学习器使用了XG-Boost。下面将单一模型和组合模型就准确率、精确率、召回率和Fl值四种指标进行了对比,结果如表l和图2所示。
从表l和图2可以看到,单一模型分类准确率大部分在70%-80%.Fl值也集中在0.7-0.8,模型精度比较低,无法满足模型在实际生产中应用的需求。使用Stacking的方法进行模型集成后,各项指标较单一模型均有了一定程度的提升,主要的判定标准准确率和Fl值分别提高到了89.15%和0.8919,模型精度提高明显。可以看到,对于钢板表面颜色分类模型,基于Stacking的集成模型达到了更好的模型性能,为模型在实际生产中的应用打下了良好的基础。
4 结束语
本文研究了钢板表面颜色预测的问题,针对普通分类模型精度较低的情况,提出了一种基于Stacking的钢板表面颜色分类算法,以两层堆叠的方式组合多种分类模型,借助多种模型的优势进一步提高预测精度,并使用五折交叉验证防止过拟合。使用python进行数据处理及建模分析后,发现stacking组合模型相较于单一分类模型在准确率、Fl值等重要指标上都取得了明显的提升。但由于样本数量偏少,模型的精度还有待提高,后续工作将增加样本及特征数量,进一步优化模型,提高模型的各项性能。
参考文献(References):
[1]刘振宇,于洋,郭晓波,关菊,王国栋.板带热连轧中氧化铁皮的控制技术[J].轧钢,2009.26(1):5-9
[2]王健.热轧钢板表面红色氧化铁皮缺陷成因分析[J].河南冶金,2017.25(4):22-23
[3]卢光跃,闰真光,吕少卿,吴洋.基于混合采样和Stacking集成的电信用户网别预测[J].西安邮电大学学报,2019.24(4):1-5
[4]李强,翟亮.基于Stacking算法的员工离职预测分析与研究[J].重庆工商大学学报:自然科学版,2019.36(1):117-123
[5]梁超.基于Stacking模型融合的工程机械核心部件寿命预测研究[J].毅件工程,2019.22(12):1-4
[6]Wolpert D H. Stacked generaliation[J]. Neural Networks,1992.5(2):241-259
[7]周志华.机器学习[M].清华大学出版社,2016.
[8]罗智青,莫汉培,王汝辉,胡顺东,方绍怀,陈世涛.基于Stacking模型融合的失压故障识别算法[J].能源与环保,2019.41(2):41-45
[9]朴杨鹤然,任俊玲.基于Stacking的恶意网页集成检测方法[J].计算机应用,2019.39:1018-1088
[10]董克源,徐建.基于Stacking的Android恶意检测方法研究[J]计算机与数字工程,2019.47(5):1184-1188
*基金项目:运城学院博士科研启动项目(YQ-2019003)
作者简介:刘媛媛(1985-),女,河北保定人,硕士,工程师/助教,主要研究方向:机器学习。
