基于MOOC的个性化预测和干预研究
2020-09-15蒋翀朱名勋王点
蒋翀 朱名勋 王点
摘要:针对MOOC研究现状,结合MOOC平台多样、规模庞大、种类众多、学习者背景和目的各异等特点,以个性化预测研究为主要对象,分析和对比了作为研究基础的点击流日志、讨论区、课后任务、课程信息和学习者基本属性五类数据源的优劣,归纳了用于预测的基于活动、讨论区、社交和认知的模型。以《大学信息技术二(Python程序设计)》为例,构建和应用了个性化预测和干预模型。
关键词:MOOC:个性化:预测模型:复制框架
中图分类号:G434 文献标识码:A 文章编号:1 006-8228(2020)08-10-04
0引言
自2012年以来,MOOC浪潮以美国为起点迅速席卷全球,吸引了全球不同国籍和教育背景的数以千万计的学习者加入。截止2020年3月,Coursera与来自52个国家207个院校和公司合作,提供4116门课程,学习者超过4500万人[1];edX与全球140多所顶尖机构合作,学习者数量超过2400万,提供2600多门课程。国内知名MOOC平台学堂在线汇集600余所知名院校的近2000门课程,注册用户近3000万[2]。经过近十年的发展,MOOC平台提供给学习者的选择更加多样化,除了免费课程以外,也有一部分付费、学分和学位课程,一些企业也会定向提供付费的培训。
从MOOC诞生之初,高辍课率就是困扰MOOC发展的绊脚石。2014年,哈佛大学的HarvardX研究委员会和MIT的数字化学习办公室合作发布的在线课程研究报告显示:拿到证书的学习者仅占总人数的5.1%[3]。因此,从研究内容来看,大部分MOOC相关的研究工作围绕学生辍课率展开,对学生行为和活动进行分析,预测可能的学习结果(是否能完成课程,测试是否通过)[4],进行个性化干预;也有部分研究获取学习者学习行为、兴趣和结果,在学习过程中开展个性化学习资源推荐,规划学习路径,或者在完成课程后进行相似课程推荐。本文阐述了MOOC个性化预测研究的数据基础和主要类别、归纳了四种类型的模型构建,总结了复制框架在验证已有预测研究结论中的应用,最后提出未来研究可能的重点和方向。
1 基础数据源
在MOOC研究领域,特别是对直接讲授MOOC的教师和团队,可以直接获取大量用于教学研究的原始数据,这在传统的高校教育环境中很难实现。在目前MOOC预测研究中,基础数据有点击流日志、讨论区、测试及课后任务、课程信息和学习者基本属性五类。
1.1 点击流日志
点击流日志又称为服务器日志,是学习者与课程平台交互的记录,由服务器自动记录,是MOOC研究的主要数据来源。记录的学习者行为(事件)包括鼠标点击,页面浏览(当前页码,后退或前进),回答问题,视频播放/浏览/略过,问题提交和讨论区互动等。一般来说,会开展特征工程,从日志中抽取特征,分析属性和操作,以及产生的结果,形成规则[5],例如,如果花费在学习资源上的总时间大于所有学生的平均时间,那么更可能完成课程。在很多情况下,特征工程比统计算法更为重要,研究者会采用新的特征工程算法和标准的分类算法[6],提升预测模型的表现。除了服务器日志外,客户端日志在实时预测中也有使用。Pardos等人在edX平台客户端嵌入JavaScript脚本,获取学习者最近(几秒前)的操作数据,实现实时的学习预测和干预[7]。
1.2 讨论区
在讨论区内,主要有学习者发布的基于主题的讨论,与课程内容相关的讨论和互动,所有学习者都能发表主题和回复,教学团队也会参与其中。但是,只有部分想要完成课程或对课程兴趣较高的学习者会在讨论区发言。与点击流日志相比,这部分数据量相对较小。这部分原始数据都是自然语言构成的文本数据,经过分析处理,可以获取两方面的信息,一方面是对与发帖行为相关的数据,例如发帖次数,回复次数,发布的主题贴是否有更多的回复(相比平均数),点赞和反对的操作次数等,另一方面通过自然语言和词汇复杂度分析,获取语言和词法相关信息,例如是否使用更复杂的词汇和更准确的词语[8],更多的使用二元/三元语法,使用更多种的词汇(与平均使用次数相比)。这些数据可用于获知学习者参与度、掌握和理解学习内容的程度,可用于构建基于课程的社交网络。
1.3 测试、作业和课后任务
与大学实体面授课程相似,MOOC学习过程中,有各种类型的测试、作业和课后任务,包括视频中的QUIZ,课后测试,任务,仿真实验,程序编写和报告论文等。从中抽取的特征主要包括学习者在课后任务中所花费的时间,尝试作业次数、
尝试小测次数和尝试讲座次数等[9]。因为对于大部分课程而言,完成作业的学生较少,数据量和覆盖的学生比例也比较小。同时,不同学科课程的作业形式有一定差异,数据处理的方法各异,为研究带来了一定的困难。
1.4 学习者基本属性和课程信息
课程信息一般與其他信息想结合,进行学习行为和结果的预测,也应用于学习者的持续性和参与度的预测。学习者基本信息一般是通过课前的可选问卷获取,信息量小,获取的内容与真实情况有一定偏差,可用性不高。
1.5 数据获取与应用
在实际研究中,直接使用点击流数据或结合多项数据的情况较多。华中师范大学张浩等人综合运用了用户属性信息(ID,年龄,性别,教育程度和地区)、用户行为数据(浏览、评论、收藏、是否参与课程、交互次数、播放视频次数等)和课程属性信息(ID、名称和分类)进行课程资源的推荐。国防科技大学的王雪宇等人在研究中扩大使用的数据范围,不仅使用学习者学习本课程时产生的数据,而且综合考虑其学习本课程之前在其他课程的行为数据,包括登录次数,学习其他课程数,通过的课程数和平均成绩等,学习本课程期间在其他课程的学习数据,包括同时学习的课程数量,通过的其他课程数和平均成绩等[10]。
在绝大部分的MOOC研究中,数据基本源于研究者或团队所讲授的几门课程。对于其他未讲授MOOC的研究者,可以从MORF和DataStage获取大规模的共享基准数据集,
2 預测模型
预测模型是在根据不同课程源数据提取的特征,构建预测模型,分别进行训练、测试和应用。常见的预测模型主要有基于活动、讨论区、社交和认知的模型。
2.1 基于活动的模型
基于活动的模型使用行为数据,以学习者行为理论为基础,评估行为结果。因为具有大量可靠稳定的数据源(服务器日志)且具有较好的预测表现,基于活动的模型最为常见。具体来说,有基于早期课程行为的模型,针对学习者在第一周内的学习表现进行早期辍课预测,为风险学生提供早期干预[11];也有包括LSTM神经网络的序列模型,将每周的活动特征向量序列作为输入,累积每周的学习数据,逐步提高预测效率[12];另外,SVM、隐马尔科夫和逻辑回归等模型也有不同程度的应用。
2.2 基于讨论区的模型
基于讨论区的模型使用自然语言数据作为基础。这些自然语言数据来自于学习者或使用语言学理论分析得出。对讨论区数据的细节分析包括语言、社交和行为的一些特征,这些只从点击流数据分析无法获取。从讨论区的自然语言中抽取特征是一项十分耗费时间和人力的工作,但带来的效果是其他工作无法替代的。通过比较基于点击流活动特征和自然语言处理特征预测优劣的研究,发现基于点击流活动的特征是课程完成率最有效的推荐指标。基于讨论区模型的局限性主要是数据稀疏性[13],覆盖的学生比例一般不超过完成课程的学生比例。
2.3 社交模型
社交模型使用观测或推导出的社交关系,社交互动的理论作为学生模型的基础。在研究中,以讨论区数据为基础构建社交网络,学生是节点,不同的回复关系构成边。Joksimovi等人评估了评论区社交网络联系与学习表现之间的关系,相比未完成课程的学生,获得认证或者优秀的学生更愿意互动和交流,得出了社交网络中的结构中心与课程完成正相关的结论[14]。与MOOC评论区分析社交网络相比,外部社交网络(Facebook、Twitter、微信和微博等)具有数据丰富和网络关系相对稳定等优点,可作为未来获取更多社交因素,研究社交联系与学生成功之间联系的新方向。
2.4 认知模型
认知模型的基础是认知理论和学习者的认知状态。认知数据的获取主要是通过传感技术进行生物特征追踪和同期问卷调查。Dillon等人关注在MOOC模型中情绪这一认知状态,用自述的情感状态检测情绪与学习活动和辍学之间的关系。研究结果显示,焦虑、困惑、沮丧和希望都与辍学明显相关。虽然MOOC学习本身就是一个认知的过程,学习结果是认知状态的直接反映,但是总体来说,对于认知数据的研究和应用相对较少,这与目前传感设备的普及率不高,认知数据量小有直接关联。
3 个性化预测和干预模型构建
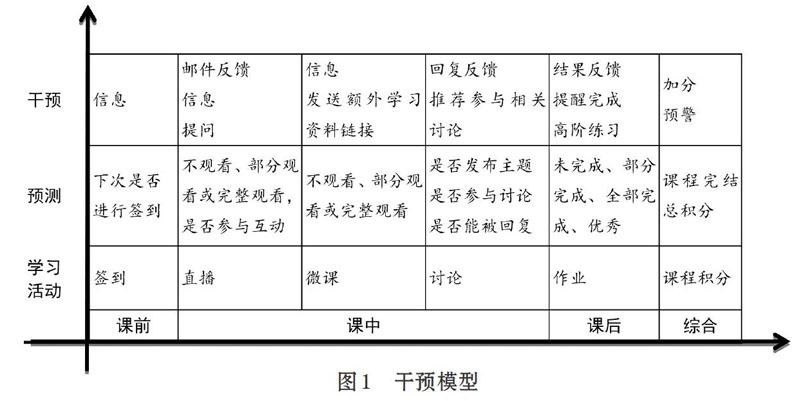
自关注以MOOC为代表的开放在线课程以来,笔者完成了Coursera约翰霍普金斯大学“探索性数据分析”和“R语言程序设计”,学堂在线清华大学“数据挖掘:理论与算法”等课程。在超星学习通先后开设了“数字视频制作”、“数字媒体技术与应用”和“数字媒体技术专业实训”等课程。目前正在讲授“大学信息技术二(Python程序设计)”课程,本文以该课程为例,结合学习和教学经验,构建了个性化预测和干预模型,如图1所示。根据学生学习表现,预测可能的学习行为和状态,通过系统信息和邮件及时地干预。
具体来说,将学习活动划分为课前、课中、课后。课前签到,课中直播、看微课和参与讨论,课后完成作业。综合这三个阶段不需要学生额外参与,系统根据所有学生已参与的课堂活动,给出一个分数评价。下面对每个阶段的学习活动进行详细描述。
(1)签到。根据历史签到情况预测下次课程是否会签到,若结果为不会签到则发送信息提醒学生。
(2)直播。根据以往观看直播视频和是否参与互动的情况,预测学生下次参与直播课程的情况,通过信息进行提醒,邮件反馈历史情况。若预测参与直播的可能性小,则在下次直播课程中重点关注并进行适当提问。
(3)微课。微课相当于布置的录播课任务,要求在规定时间内完成观看,没有实时互动。根据观看微课的历史情况,预测下次将不观看、部分观看或完整观看。对于完整观看的学生,发送额外学习资料的联系,鼓励进行拓展学习。对齐其他学生,发送信息进行反馈和提醒。
(4)讨论。根据学生在讨论区的表现,预测是否会发布主题、参与讨论或主题能被回复,将讨论区动态及时通过信息反馈给学生,并为行为活跃的学生推荐相关性高的主题和讨论。
(5)作业。预测学生完成课后作业的情况,对全部完成作业和优秀的学生推荐部分高阶练习。对其他同学发送提醒信息。
(6)课程积分。课程积分由学习平台自动生成,为学生各学习阶段的表现综合评价。根据现阶段课程积分,来预测课程完结总积分,对积分排名20%的给予不同程度平时成绩加分。对于排名后20%的发送预警信息。
目前,在课程《大学信息技术二(Python程序设计)》的签到、直播、作业和课程积分4项活动中,应用了预测和干预模式,结果表明,学生签到率明显提高,直播互动人数增多,作业完成情况有所提升,课程积分有一定程度提高。
4 结束语
本文对目前MOOC研究中的数据源和预测模型研究进行了梳理,结合自身学习和教学经验提出了个性化预测和干预模型,并将模型应用于所讲授的课程中,教学效果和学生在课程中的参与度都有一定程度的提升。对于以MOOC为代表的在线课程的过程管控、个性化施教和辍课率降低具有重要的参考和指导意义。下一步研究工作的开展主要从以下两个方面入手,一是在微课和讨论2项课程活动中应用预测和干预模式,进一步验证模型效率;二是应用计算机技术和教育学理论,提升预测的准确度,为个性化干预提供更精准的支持。
参考文献(References):
[1]http://www.rcoe.edu.cn/?p=4 269
[2]https://baijiahao.baidu.com/s?id=1647805030394904836&,A,fr=spider&for=pc
[3]Le C V,Pardos Z A,Meyer S D,et al_Communication atScale in a MOOC Using Predictive EngagementAnalytics. Lecture Notes in Computer Science, 2018:239-252
[4] Gardner, J., & Brooks, C. Student success prediction inMOOCs. User Modeling and User-Adapted Interaction,2018.28(2):127-203
[5] Pardos, Z. A., Tang, S., Davis, D., & Le, C. V. EnablingReal-Time Adaptivity in MOOCs with a PersonalizedNext-Step Recommendation Framework. Proceedingsof the Fourth (2017) ACM Conference on Learning @Scale - L@S '17:23-32
[6] Andres, J. M. L., Baker, R. S., Gasevie, D., Siemens, G.,Crossley, S. A., &Joksimovie, S. Studying MOOCcompletion at scale using the MOOC replicationframework. Proceedings of the 8th (2018)lnternationalConference on Learning Analytics and Knowledge-LAK '18:71-78
[7]盧晓航,王胜清,黄俊杰 . -种基于滑动窗口模型的 MOOCs辍学率预测方法 [J].现代图书情报技术 ,2017.4:67-75
[8]王雪宇,邹刚,~骁 .基于 MOOC数据的学习者辍课预测研究[J].现代教育技术,2017.6:95-101
[9] Ho A D, Reich J, Nesterko S O, et aL HarvardX and MITx:The First Year of Open Online Courses, Fall 2012-Summer2013[J]. Social Science Electronic Publishing,2014:1-33
[10] RenZ ,Rangwala H , Johri A . Predicting Performance onMOOC Assessments using Multi-Regression Models,2016.
[11] Xing, W., Chen, X., Stein, J., &Marcinkowski, M.Temporal predication of dropouts in MOOCs:Reaching the low hanging fruit through stackinggeneralization. Computers in Human Behavior,2016.58:119-129
[12] Fei, M., &Yeung, D.-Y. Temporal Models for PredictingStudent Dropout in Massive Open Online Courses.2015 IEEE International Conference on Data MiningWorkshop (ICDMW),2015:256-263
[13] Crossley, S., Paquette, L., Dascalu, M., McNamara, D.S., & Baker, R. S. Combining click-stream datawith NLP tools to better understand MOOC comple-tion. Proceedings of the Sixth (2016)lnternationalConference on Learning Analytics & Knowledge- LAK '16:6-14
[14] Joksimovie, S., Manataki, A., Gasevie, D., Dawson, S.,Kovanovie, V., & de Kereki, I. F. Translatingnetwork position into performance. Proceedings ofthe Sixth(2016) International Conference on LearningAnalytics & Knowledge - LAK '16:314-323
★基金项目:湖南省教育厅科学研究项目“基于移动微课的非结构化教育资源个性化推送算法研究”(16C0804)
作者简介:蒋翀(1980-),女,湖南黔阳人,硕士,讲师/高级工程师,主要研究方向:推荐系统,个性化技术,教育信息化。
