基于GMM模型和LPC-MFCC联合特征的声道谱转换研究
2020-09-15张雄伟苗晓孔
曾 歆,张雄伟,孙 蒙,苗晓孔,姚 琨
(陆军工程大学,江苏南京210007)
0 引 言
语音转换是一种在保留语义信息不变的前提下,修改源说话人的个性特征信息,使之具有目标说话人个性特征的语音处理技术[1]。语音转换要实现这一目的,就要提取表征个性特征信息的声学特征,建立不同说话人对应声学特征的对应关系,即转换规则,然后进行转换合成,得到转换语音。
语音转换是目前信号处理领域比较新的一个分支,该技术的研究兼具理论意义和实际应用价值。在多媒体娱乐方面,可通过语音转换实现特定人物配音;对于语音登入系统,可以利用转换语音攻击说话人认证系统。此外,还可以利用语音转换来消除个人特征差异对语音识别的影响等。由此可见,语音转换技术值得深入研究。
语音的特征信息大致划分为3类:音段信息、超音段信息和语言学信息[2]。相关研究表明,超音段信息中的平均基频和音段信息中的声道谱包络对说话人语音个人特征信息的贡献最为重要[3]。相对于平均基频而言,声道谱包络的建模、转换更为复杂,且是制约语音转换效果提升的瓶颈。因此,本文重点围绕声道谱转换展开研究。
语音转换技术研究可追溯到20世纪80年代。王志卫等[4]采用了基于码书映射的语音转换方法,该方法基于统计得到的直方图信息,通过加权求和的方法实现语音转换。这种“硬聚类”的转换方法虽然效果一般,但开辟了一条从统计学角度解决语音转换的思路。Toda等[5]采用了基于高斯混合模型(Gaussian Mixture Model, GMM)的声道谱转换方法,对说话人的声道谱空间参数进行建模映射。相比基于码本映射的语音转换方法,该方法极大地提升了频谱平滑度,但基于概率的“软聚类”也导致结果中存在参数过平滑问题。Sundermann等[6]采用动态频率规整(Dynamic Frequency Warping, DFW)的方法进行语音转换,即对源说话人声道谱频率进行DFW处理,使其共振峰位置匹配目标说话人频谱共振峰位置。此外,基于隐变量模型的转换方法[7]、基于深度神经网络模型的转换方法[8-9]等也相继被广泛研究和应用。
在语音转换系统中,声道谱参数是反映说话人个性的重要特征参数。在众多关于声道谱包络的建模转换中,GMM 方法的使用较为普遍。相较于近年流行的神经网络方法,GMM 方法依然具有模型体积小、转换耗时少、可本地化计算等优点。因此,本文考虑选用GMM方法进行相应的语音转换研究。
语音信号中包含着丰富的特征参数,不同的特征参数表征着不同的物理和声学意义。特征参数的选择对语音转换系统的转换效果至关重要。目前关于语音转换的研究中,大多数转换方法只选择对单一声道特征参数进行转换,而忽略了不同声道特征参数之间可能存在的互补性。本文在现有研究成果的基础上,对不同的声道特征参数进行联合建模和转换。具体来说,从语音信号中提取线性预测系数(Linear Prediction Coefficient, LPC)和梅尔频率倒谱系数(Mel-Frequency Cepstral Coefficient, MFCC),联合二者得到 LPC-MFCC特征参数,并借助转换性能较好的GMM,实现对LPC-MFCC特征参数的转换。LPC是表征声道信息的特征参数,主要反映声道响应;而MFCC是基于人听觉的临界带效应,在梅尔标度频率域提取出来的倒谱特征参数,更贴近人耳的听觉特性。因此,LPC参数和MFCC参数存在一定的互补性。
1 相关知识
1.1 GMM建模
在GMM建模阶段,采用了对源和目标联合建模的方法。联合建模一般选用并行语料,即源与目标训练的语料一致,以此来保证动态时间规整(Dynamic Time Warping, DTW)后的联合矢量源与目标的对齐,为GMM训练做好准备。转换规则的确立一般选用最小二乘法来估计转换函数的相关参数。与矢量量化语音转换方法相比,GMM是对频谱包络特征参数进行软分类,使得特征参数能够以一定的概率属于多个不同的类,在一定程度上克服了矢量量化的不连续性,改善了转换后语音的音质。使用该方法进行语音转换能够得到较为满意的合成语音。
1.2 基于LPC特征参数的GMM声道谱转换方法
1.2.1 线性预测系数
语音线性预测的基本原理是:由于语音信号样点之间存在相关性,因此一个语音的采样值可以用过去若干语音采样值的线性组合来逼近。通过使实际语音信号抽样值和线性预测抽样值之间的误差在均方准则下达到最小值来求解预测系数,而预测系数就反映了语音信号的特征,故可以用这组语音特征参数进行语音转换或语音合成等。
设n时刻的语音采样值s(n)可由其前面p个语音采样值的线性加权表示,则s(n)可以表示为

其中,ai表示权值,p个LPC参数可通过全极点模型进行求解。
线性预测最主要的优势在于可以较为精确地估计语音声道参数,能够较好地反映语音信号的声道特性。
1.2.2 基于LPC参数和GMM模型的语音转换
在训练阶段,首先分别提取源说话人和目标说话人的LPC参数;然后使用DTW算法对源和目标说话人的LPC参数进行时间对齐;最后运用GMM训练网络,建立映射转换规则。
在转换阶段,首先提取源说话人的LPC参数;然后根据训练阶段建立的映射转换规则,对源说话人的 LPC参数进行转换;最后利用转换所得到的LPC参数合成转换语音。
2 本文方法
2.1 基于LPC-MFCC联合特征参数的语音转换
本文在基于LPC参数的GMM声道谱转换方法的基础上,引入了更贴近于人耳听觉特性的MFCC参数,构建了联合特征参数 LPC-MFCC并用于语音转换。其语音转换框图如图1所示,转换步骤如下:
在训练阶段:(1) 分别提取源说话人和目标说话人的LPC参数和MFCC参数;(2) 联合LPC参数和MFCC参数,得到新的特征参数LPC-MFCC;(3) 使用 DTW 算法对源和目标说话人的LPC-MFCC特征参数进行时间对齐;(4) 使用GMM模型训练网络,建立映射转换规则。
在转换阶段:(1) 提取源说话人的LPC参数和MFCC参数;(2) 联合LPC参数和MFCC参数,得到LPC-MFCC联合特征参数;(3) 根据训练阶段建立的映射转换规则,对源说话人的 LPC-MFCC特征参数进行转换,转换所得 LPC-MFCC特征参数中包含LPC参数对应转换的生成部分和MFCC参数对应转换的生成部分;(4) 考虑到基于LPC参数的语音转换方法的效果优于基于 MFCC参数的语音转换方法,因此选取LPC参数对应转换生成部分进行语音合成,得到转换语音。
2.2 方法步骤
2.2.1 语音信号预处理
为了得到适合转换处理的语音帧,首先对语音进行加窗分帧、端点检测、预加重等前端预处理。其中,预加重的目的是为了对语音的高频部分进行加重,去除口唇辐射的影响,增加语音的高频分辨率。本文设置的预加重系数为0.9。
2.2.2 MFCC参数与LPC参数的提取
本步骤的目的是基于预处理后的语音帧,提取出反映信号特征的关键特征参数以便于后续处理。考虑到GMM模型更适用于低维度特征的建模,本文选取低维度的MFCC参数与LPC参数进行联合。MFCC参数的提取过程如图2所示[10]。
基于LPC特征参数的语音转换在1.2节已经详细介绍,此处不再赘述。
2.2.3 LPC参数与MFCC参数的联合
为了便于LPC参数和MFCC参数进行联合,在LPC参数和MFCC参数提取之前,对语音信号做同样的加窗分帧等预处理操作。本文实验设定滤波器阶数为12。
为了便于阐述参数的联合过程,假设矩阵Alpc表示根据某一句语音提取得到的LPC参数,阶数为M×N,其中M表示帧数,N表示特征维度。矩阵Amfcc表示根据同一语音提取得到的MFCC参数,阶数为M×N。对两个矩阵按列拼接得到联合矩阵,即LPC-MFCC特征参数对应的矩阵,阶数大小为M×2N。这一步对LPC参数的维度进行了扩充,使原本N维度的转换问题变成 2N维度的转换问题,同时也将LPC参数和MFCC参数之间可能存在的互补性纳入考虑范围。
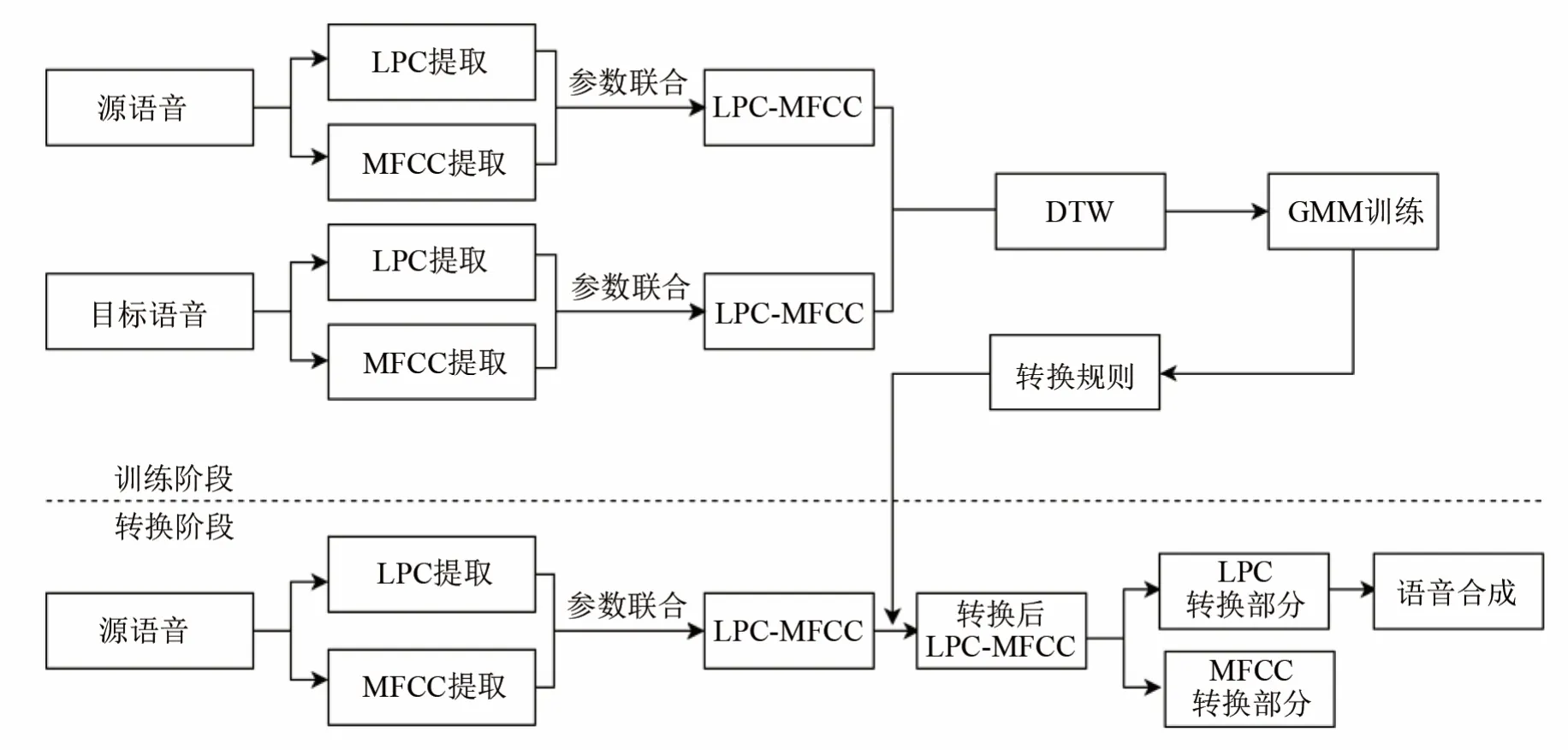
图1 基于GMM模型和LPC-MFCC联合特征的转换框图Fig.1 Block diagram of voice conversion based on GMM model with LPC-MFCC

图2 MFCC特征提取流程Fig.2 The procedure of extracting MFCC features
2.2.4 时间对齐
在建立源特征参数和目标特征参数映射关系之前,需要先将源和目标语音的特征参数进行时间对齐,确保转换的是描述同一音节的特征参数。使用 DTW 算法对源说话人和目标说话人的LPC-MFCC特征参数进行对齐,产生一对相等长度的源和目标的特征序列。
2.2.5 模型训练及参数转换
将源语音参数矢量X与目标语音参数矢量Y构成一个联合矢量Z,Z= [XY]T,利用联合概率P(X, Y)来训练高斯混合模型。假设用p个单高斯分布的加权求和来表征Z的概率分布,则GMM的概率分布函数表示为[11]
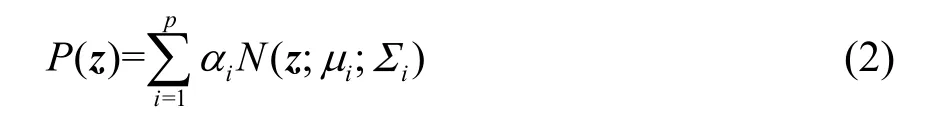

约束条件为

GMM的3个模型参数(αi,µi,Σi),可以通过期望最大(Expectation-Maximization, EM)算法进行迭代求取[11]。
首先找到输入语音特征参数相对于源说话人GMM 模型对应的分量,然后找到输入语音特征参数相对于目标说话人GMM模型对应的分量,然后在这两个分量之间建立转换规则,这样就可以将源语音的参数映射成目标语音的参数,从而实现对输入语音特征的转换。
运用上述的 GMM训练 LPC-MFCC特征参数,建立映射转换规则。在转换阶段,同样对源目标语音提取LPC-MFCC特征参数,根据训练好的网络模型进行转换。在合成阶段,只需取出LPC参数对应的转换部分,进行语音合成,从而得到转换语音。
3 实验结果及分析
为了更好地对比语音转换方法的性能,需要进行仿真实验测试。本文采用主观和客观相结合的测试方法来对两种方法的转换性能进行综合评价。
3.1 测试方法
3.1.1 客观测试
语音信号之间的差异一般采用语音信号频谱上的距离测度来描述。理论上可以使用各种类型频谱差测量来计算转换语音和目标语音之间的差异。转换后的频谱和目标频谱之间的距离越小,说明二者越接近,也即转换效果越好。语音转换相关文献中使用最多的客观测试衡量指标是梅尔倒谱失真(Mel Cepstral Distance, MCD),单位dB,其计算方法为
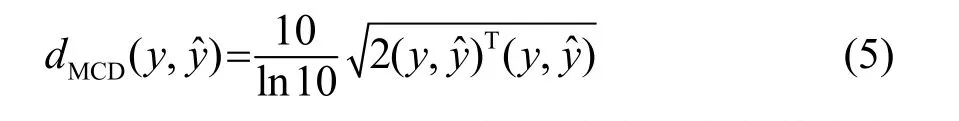
其中,y和分别是目标语音和转换语音的梅尔倒谱特征向量。
3.1.2 主观测试
主观测试也是对转换语音进行评价的一个很重要的方式。它根据一定的评价标准、靠人的主观听觉来对转换后的语音进行判断或打分,进而对语音转换方法的性能进行评估。语音转换相关文献中使用最多的主观测试衡量指标是平均意见得分(Mean Opinion Score, MOS)测试。MOS测试的主要原理是让测评人根据5个等级划分对测试语音的主观感受进行打分。它既可以用于对语音自然度进行主观评价,也可以用于对说话人特征相似度的评价。测试要求测评人具有正常的听觉感知能力,并多年从事语音技术研究。
3.2 测试结果
本文使用由中国科学院自动化所(Institute of Automation, Chinese Academy of Sciences, CASIA)发布的 CASIA汉语情感语料库进行了多组转换实验,包括:男声到男声(M-M)、男声到女声(M-F)、女声到男声(F-M)、女声到女声(F-F)的转换。客观测试结果如表1所示。其中优化比率表示联合特征参数方法相对于LPC参数方法的MCD的下降率。
结合表1分析可知,相比于基于GMM和LPC参数的语音转换方法,基于 GMM 和 LPC-MFCC联合特征参数的语音转换方法,在男声到男声、男声到女声转换时,客观指标MCD值有较明显的下降;但是当源目标语音是女声,目标语音是女声或者男声时,两种语音转换方法的MCD测试结果相差不大。可能的原因是女声音调高,将其作为待转换语音会影响转换效果。今后将会对其具体原因进行更深入的研究。
总体来说,基于联合特征参数的转换方法相比于基于LPC特征参数的转换方法,MCD值明显降低,降低比率为11%,客观测试结果更佳。

表1 客观测试的MCD结果比较Table 1 Comparison of MCD results in objective test
在主观测试方面,依据转换语音和目标语音相似度的主观测试结果如表2所示。其中优化比率表示联合特征参数方法相对于 LPC特征参数方法的MOS分提升率。

表2 主观测试的MOS结果比较Table 2 Comparison of MOS results in subjective test
结合表2分析可知,相比于基于LPC参数的转换方法,基于 LPC-MFCC联合特征参数的转换方法,在男声到男声、女声到女声两组实验中的相似度显著提高;在男声到女声、女声到男声两组实验中略有提高。
总体来说,基于联合特征参数的转换方法,相比于基于LPC特征参数的转换方法,转换语音和目标语音更相似,相似度提升达到25%,转换性能更佳。
4 结 论
本文在基于GMM模型和LPC参数语音转换方法的基础上,引入了更贴近人耳听觉特性的MFCC参数,将LPC和MFCC参数之间可能存在的互补性纳入考虑范围,在此基础上提出了一种基于GMM模型和LPC-MFCC联合特征参数的语音转换方法。主观和客观实验表明,相比于基于GMM模型和LPC参数的语音转换方法,基于GMM模型和LPC-MFCC联合特征参数的语音转换方法相似度更高,转换效果更佳。但MFCC参数的引入同时也会对LPC的合成阶段产生干扰,导致合成语音存在些许噪声。如何解决这一问题将是下一步工作的重点。此外,本文语音转换系统的输入和输出都是LPC-MFCC,且合成阶段只选用LPC对应的转换部分进行语音合成。下一步拟继续研究以LPC-MFCC为输入,LPC或MFCC为输出的语音转换方法,并且在语音合成阶段拟将MFCC纳入考虑范围,继续探究LPC和MFCC参数之间的互补性,以进一步提高转换语音的自然度和相似度。
