基于多特征分层的视频摘要提取算法
2020-09-15周巨罗兵
周巨,罗兵
(五邑大学 智能制造学部,广东 江门 529020)
手机、网络等视频相关设备和技术的进步使得视频数据快速增加,大量的视频数据也对视频摘要提取产生了更大的需求.视频摘要是从原始视频数据中提取出的能反映原视频主要信息内容的单帧或一组少量视频帧,用于视频预览、视频分类、视频识别等应用.
现有的视频摘要生成算法分为基于特征提取和基于视频镜头分割两类[1].其中基于特征的方法为了有效利用多帧图像的多特征信息,无法预先去除冗余帧,每一帧都需要计算多特征值,再进行多次聚类,计算量大,且每种特征权重难以进行有效设定[2-3].而基于镜头分割的视频摘要提取方法利用局部特征将视频根据内容分割成不同的视频片段,来获取整个视频的结构信息,但由于局部特征的时空局限性,出现多场景、多镜头的复杂视频内容变化时,易缺失重要帧或生成冗余帧,提取生成的视频摘要不能有效表示原视频的主要内容,性能难以满足实际需要[4-5].
本文设计了一种基于多特征分层的视频摘要提取生成算法,分层采取先快后慢的策略,每层使用不同的特征进行镜头分割、片段聚类,最后得到保留时序信息的视频镜头准确分割及各段关键帧.再对关键帧进行局部特征聚类相似度比较,得到候选视频摘要.根据实际应用需要,再结合全局特征,从候选视频摘要中得到最终视频摘要.
本文设计的分层多特征视频摘要生成算法的特点是:
1)分层提取多特征进行视频镜头分割,先用简单特征分割,再对分割点采用复杂特征聚类,大大减少了计算量;
2)结合了像素、颜色、特征点信息进行分层视频镜头分割,更全面地依据视频内容变化情况完整地分割镜头,具有旋转不变性、错误率低、鲁棒性好的优点,降低了视频摘要冗余度;
3)结合全局特征提取方式,保留了全局结构信息,弥补了局部特征方法的不足与结构信息出现偏差的缺点,能够全面准确地表达视频内容;
4)在生成视频摘要的同时,完成了基于视频内容的视频镜头分割.
本文提出的视频摘要生成算法主要分为两个阶段:视频镜头分割与视频摘要生成.
1 基于多特征的视频镜头分割
视频摘要提取前一般对原始视频先进行预处理,去除空帧、错误帧.镜头分割阶段首先从像素特征、颜色特征和关键点匹配三个方向进行特征选择.使用多个特征,能够更好地依据视频内容变化完成视频镜头分割,保证视频镜头分割的结构完整.选取速度相对快且效果好的三种算法提取不同特征:差异值哈希算法、HSV 改进算法和特征点匹配及描述算法(Oriented FAST and Rotated BRIEF,ORB).根据三种算法的计算复杂度和性能特点,将最快速简单的差异值哈希算法放在第一层,初步对所有视频帧进行相似度比对,得到初步分割好的视频片段;再用各片段间的首尾帧依次采用HSV 改进算法进行聚类,粘合视频镜头得到第二层分割的视频片段.此时片段间需要计算的帧图像逐层减少,此时引入ORB 特征点匹配算法,其聚类效果更好,同时避免了人为指定聚类中心带来的干扰.
图像差异值哈希算法多用于相似图搜索和图像相似度计算[6].图像在计算机中以像素点的形式保存,像素值的差异是图像最直观的差异.基于哈希算法的视频镜头分割算法直接利用像素差异进行等比例缩放后进行比对而分割视频,速度极快,虽然存在准确率低、效果差的缺陷,但是可以用于初步分割,将内容基本一致的视频帧按照时间顺序分割为小片段,为后续性能更好但速度较慢的特征提取算法减少冗余帧.
解码得到的最初视频RGB 图像不能直观地表示色彩明暗、色调及鲜艳度等颜色信息,因而转化为HSV 表示.由于目前较多视频是由手持设备拍摄,各种轻微的抖动都会导致拍摄角度变化而造成颜色明度的变化,实际上视频内容并没有太大变化,这样易将相同内容的帧的进行错误的分割.在HSV 颜色空间中,色度H 及饱和度S 分量直接与人眼接受彩色信息紧密相连,而亮度V 分量与图像的颜色信息没有直接关系,对视频分割作用较小,因此本文只对H 和S 分量做16 级量化,并按照式(1)合成为一维特征向量.
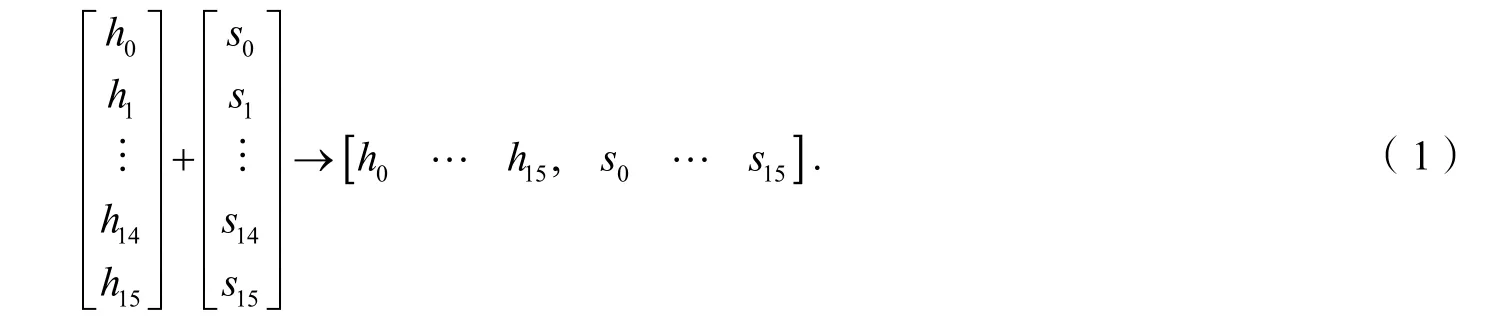
在相似度判别上,本文使用欧氏距离来计算两帧图像之间的相似度.设Sim(R,I) 为R、I 两帧图像的欧氏距离,Sim(R,I) 越小则越相似.设两帧图像按式(1)计算得到的一维特征向量归一化后的结果分别为,则他们的欧氏距离可由式(2)计算得到.

通过HSV 特征的欧氏距离聚类视频,仍然会受颜色特征干扰而影响分割.常常是帧间出现了某些颜色特征变化,但视频内容并未发生大的变化.因此进一步采用ORB 算法,通过两幅图像之间匹配到的ORB 特征点数目与两幅图像平均的特征点数目的比值来判定聚类,通过相似度匹配将视频片段再次聚类.
ORB 算法包括ORB 特征点匹配和特征点描述两部分.相对于其他特征点匹配算法,传统的ORB算法速度快、效果好,但不具备旋转不变性.为了解决此问题,本文使用oFAST(FAST Keypoint Orientation)算法进行特征点提取.oFAST 算法在FAST(Features from Accelerated Test)算法提取出特征点之后,给其定义一个特征点方向,得到二进制串描述符,以此实现ORB 特征点的旋转不变性.在描述子方面,本文使用rBRIEF 算法选择点对进行特征点描述,同时,采用汉明(Hamming)距离进行相似度计算.ORB 特征点匹配算法视频帧间的颜色特征变化不敏感更集中于实际内容的变化.通过相邻帧之间匹配到的特征点数量与相邻帧平均的特征点数量的比值来作为相似度判别.
通过三层多特征相似度判断,得到了三次聚类后的视频分割片段.
2 视频摘要的生成
2.1 基于局部特征的关键帧选取算法
下一步在已分割好的各视频片段中提取关键帧来作为候选的视频摘要.首先将视频分割聚类中第三次ORB 特征点匹配聚类时,已计算了ORB 特征值的各视频片段边界帧构成集合Oj,其中j 为最终视频分割后的视频片段数目.这样集合Oj中的图像数目为最终分割得到的视频片段数目 hj的两倍,即2 hj.
然后以ORB 特征匹配点的数量来衡量视频内容发生突变的情况.设定斜率阈值α,Km为视频片段m 最终将提取出的候选关键帧数目,m=1,2,3,…,j.由视频片段m 中两个边界帧与集合Oj中的其他图像的ORB 特征匹配点数量 ORBnum来确定Km.Km初值为1,视频片段m 中边界帧图像与集合Oj中其他图像的索引序号差为dist,若则 Km+ 1.计算边界帧与集合Oj中所有其他图像的比值后得到各视频片段的候选关键帧数目Km.
对于每个视频片段,根据片段中每帧图像的特征向量xi来计算相邻图像间的帧间距离D (xjm,xjn).将帧间距最近的两类合为一类,并计算各类的聚类中心:

其中Cnum为各类最新聚类中心,num 为聚类的类编号,lnum为该类帧图像数目.反复聚类,直到聚类到Km个类结束,然后将每个类中与该类聚类中心帧间距离最小的帧图像作为候选视频摘要提出.最终候选视频摘要的数目K 为 K1+K2+…+ Kj.
2.2 基于全局特征生成最终视频摘要
通过2.1 节得到候选视频摘要,都是基于视频镜头分割的视频摘要,最大限度地保证完整反映了原视频内容.此时直接输出候选视频摘要,将得到较好的召回率,但精确率相对低,可以适用于召回率要求高的应用,本文称之为方法一.
由于方法一中相似视频片段会有冗余的视频摘要,为了进一步得到既保留了时序信息又能准确描述视频内容的视频摘要,使用欧氏距离对候选视频摘要提取全局特征进行聚类,将相似的候选视频摘要再次聚类为一类,然后在同类中选出最具代表性的帧作为静态视频摘要进行输出,如图1 所示,本文将这种方法称之为方法二,将得到更高的精确率.
具体算法为:
1)计算候选 视频摘要关键帧集合 E={e1,e2,…,eK}中两两候选 视频摘要 ei、ej的欧氏距离

图1 对候选视频摘要根据全局特征再次聚类
2)设定阈值φ,若Sim(ei,ej)<φ,将其归为一类;
3)聚类后关键帧的选择:根据每一类中原关键帧的数目n,当n=1时,直接输出当前帧;当n=2时,将时序靠前的帧作为摘要输出;当n≥3时,输出每一类中离平均值最近的关键帧作为摘要.
3 实验及结果分析
3.1 评估方法与数据集
本文使用OpenCV 与Python3.6 作为开发软件,运行系统为Ubuntu16.0 64 位操作系统,硬件配置为Inter Core i5-4590 处理器和12GB 内存.
实验结果的评估方法采用F-measure 统计量对本文的实验结果进行评估,将使用精确率(Precision)、召回率(Recall)和F-score 3 个指标,分别按式(4)~(6)计算[7].

其中,Nc为提取得到的正确的视频摘要数目,Nf指提取出的错误的视频摘要数目,Nm指未提取出而丢失的视频摘要数目.
实验选择公共视频数据集VSUMM 数据集进行视频摘要提取,该数据集自带手动创建的用户视频摘要作为评价视频摘要的标准[2].但是该数据集与目前实际应用中的视频数据相比存在分辨率不够高、帧图像质量较差的问题,因此本文也将在本课题组建的WY-316 数据集进行相关实验,以此验证对目前网络视频数据的效果.WY-316 数据集为MP4 格式的随机爬取于商业视频网站的视频,帧率以及分辨率均不固定,根据内容分为51 类.WY-316 数据集随机抽取每类视频共计102 个,每个视频均附有由5 位用户人工选取的用户摘要.这些视频数据均未经过再处理,更符合实际应用中视频数据由于视频拍摄工具的多样化导致的帧率分辨率多样化实际情形,更能验证算法的鲁棒性.
3.2 实验结果评估与分析
表1 是用两种不同的特征选择分别在VSUMM 数据集和WY-316 数据集上生成视频摘要的性能比较,两种方法除图像分量数采用不同外,其余参数均相同.
在VSUMM 数据集上,本文提出的H、S 两分量方法相比H、S、V 三分量方法的精确率、召回率均有所提高,在WY-316 数据集上,召回率提高更明显.在时间消耗上,两分量方法比三分量方法减少了7.7%.由此可见,本文对HSV 颜色特征的改进方法优于传统方法.在WY-316 数据集上的实验结果显示,该方法对新的网络视频数据效果更好,使用H、S 分量颜色直方图进行聚类比使用H、S、V 三分量更能避免因人为因素造成的抖动干扰的影响,显示了更好的鲁棒性.
按本文2.2 节提出的方法一、方法二与现有传统视频摘要算法分别在VSUMM 数据集进行视频摘要提取得到的实验数据比较如表2 所示,数据为该数据集所有实验的平均值.

表1 使用不同通道的特征提取方法在VSUMM 数据集和WY-316 数据集上的比较
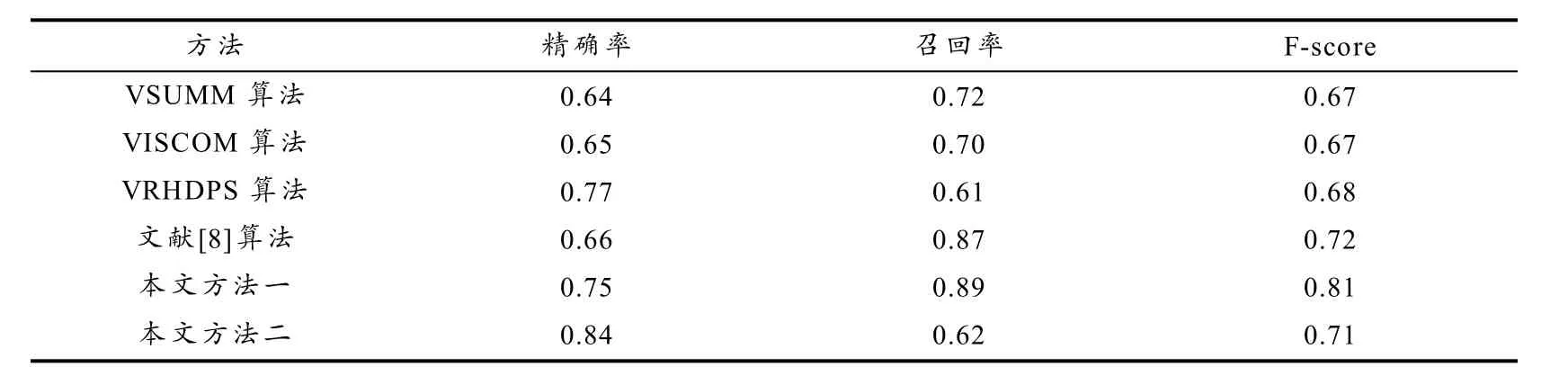
表2 本文算法与其他传统算法在VSUMM 数据集上的实验结果
由表2 可以看到,在VSUMM 数据集上,方法二的精确率远高于VSUMM 算法、VISCOM 算法、VRHDPS 算法以及文献[8]算法.本文方法二在提出候选视频摘要后,再次考虑全局特征,减少相似候选视频摘要,能最大限度保证视频摘要准确描述视频内容;方法一在召回率上优于其他算法,精确率优于VSUMM 算法、VISCOM 算法和文献[8]算法,方法一从切割好的视频镜头中选出视频摘要,能最大限度地保留时序信息,完整地表达了原视频内容.方法一的F-score 远高于其他算法,方法二的F-score 略低于文献[8]算法而高于其他算法,本文提出的算法整体性能更好.
为了更加直观显示本文所提出算法的实际效果,对网络视频WY-316 数据集用不同方法提取的视频摘要对比如图2 所示.可以看出,VSUMM 算法生成的摘要在光影变化较大的情况下易产生冗余,VISCOM 和VRHDPS 算法虽然冗余较少,但是摘要长度短,未能完整表达视频内容,文献[8]算法虽然较为完整地表达了视频内容,但仍有明显的冗余.本文方法二虽然没有完整表达视频内容,但是没有冗余,精确率最高,方法一与用户摘要基本匹配,展示的摘要更加完整和丰富.
用本文提出的两种方法对VSUMM 数据集提取视频摘要与用户摘要的对比如图3 所示.用户1~5 为VSUMM 数据集V14 视频自带的5 个用户摘要,将其与本文算法生成的视频摘要对比可以看出,方法二视频摘要长度为9 张,小于用户摘要平均长度15.4 张;方法一视频摘要长度为16 张,接近用户摘要平均长度.总体来看,本文提出的两种方法能够适应不同用户的需求,也能够适应不同应用的实际需要.

图2 对于网络视频数据不同算法生成的视频摘要

图3 本文提取的视频摘要与数据集用户摘要对比
4 结论
本文设计了基于多特征分层的视频摘要提取算法,对原始视频数据首先按照视频特征计算复杂度分别使用像素特征差异、颜色特征差异和特征点匹配差异进行多特征视频镜头分割,然后根据视频内容突变情况,自适应确定聚类数目,并得到候选视频摘要;在最终视频生成阶段,引入全局特征,保留结构信息,并采取了两种不同的方法,用以满足侧重精确率和召回率的不同应用需求.在公共数据集上的实验结果显示,本文算法由于其分层结构和多特征信息利用,在加快了处理速度的同时,提高了视频摘要质量;每层单独处理,避免了多特征权值分配问题;改进的HSV 颜色特征提取算法,比传统使用HSV 颜色特征的提取算法在速度和性能上都得以提高.通过多特征相似度对视频帧在时序顺序上进行相邻帧聚类,保留了时序信息;结合全局特征提取方式,弥补了局部特征方法的不足.如何结合时序信息和视频分割的视频片段生成动态视频摘要、如何引入更有效的特征相似度计算方法来提高视频摘要质量和加快提取速度,将是需要进一步研究的重点.
