基于DDNPE算法的间歇过程故障诊断
2020-09-15赵小强姚红娟
赵小强, 姚红娟
(1. 兰州理工大学 电气工程与信息工程学院, 甘肃 兰州 730050; 2. 兰州理工大学 甘肃省工业过程先进控制重点实验室, 甘肃 兰州 730050; 3. 兰州理工大学 国家级电气与控制工程实验教学中心, 甘肃 兰州 730050)
间歇化工过程在现代工业中占有相当大的比重,尤其是医药和食品行业.近年来,随着市场对多规格、高质量产品需求的增加,间歇生产过程正向高效、大型和集成化方向发展,从而对间歇生产过程的安全性和可靠性要求越来越高.与连续生产过程相比,间歇生产过程由于频繁的变化产品和工艺操作条件以及经常处于不稳定状态而具有较强的非线性、多模态、非高斯等特征.为保障间歇生产过程的生产安全和产品质量,需要对间歇过程建立故障检测模型,从而降低故障的发生率,减少不合格产品,达到保障安全性和产品质量的目的[1].
一方面,由于间歇过程固有的多变量、多工序、变量时变性等原因,间歇过程很难建立精确可靠的机理模型;另一方面,随着计算机和数据挖掘技术的飞速发展,现代工业过程可以在线获得大量反映生产过程实时运行状态的过程数据,通过对其适当的信息提取,可以用于工业过程的建模与监控.从而基于数据的多元统计过程监控方法便应用于工业生产过程故障检测中,典型的方法有主元分析(principal component analysis,PCA)[2]、偏最小二乘(partial least squares,PLS)[3]和独立主元分析(independent component analysis,ICA)[4],此类方法首先提取原始数据特征,进行纬度约简,接着利用降维后的数据建立模型,在化工过程故障检测中取得了一定的效果.
对原始数据进行特征提取时,保持其局部结构不变可以保留有用信息,从而提高特征提取能力.研究表明,高维数据存在嵌入在其中的低维流形结构,低维流形结构表征了高维数据的本质特征.近年来,基于流行学习的维度约简算法引起了广大的关注和研究,Roweis[5]于2002年提出了局部线性嵌入(locally linear embedding,LLE)算法,同年,Tenenbaum等[6]提出了等距映(isometric feature mapping,ISOMAP)算法,Belkin和Niyogi[7]提出了基于谱图理论(spectral graph theory)的拉普拉斯特征映射(Laplacian eigenmaps,LE)算法.在上述算法的基础上,产生了很多扩展的流行学习算法,如最大方差展开(maximum variance unfolding,MVU)算法[8]、随机邻居嵌入(stochastic neighbor embedding,SNE)算法[9]以及He等[10]于2005年提出的基于LLE的线性扩展算法即邻域保持嵌入(neighborhood preserving embedding,NPE)算法等.NPE算法一经提出就受到人们的极大重视,并将其成功应用于生物医学[11]、人脸识别[12]等领域,而且近几年来基于NPE的改进算法被引入到间歇过程的故障诊断领域.赵小强等[13]将统计量模式分析与MKNPE算法结合的方法应用于间歇过程的故障诊断中,一定程度上解决了间歇过程的非线性问题.梁秀霞等[14]将邻域正交保持嵌入(ONPE)算法与及时学习相结合的方法应用于处理间歇故障诊断中的多时段问题,取得了一定的效果.虽然NPE算法能够通过线性重构样本点提取高维数据的低维特征结构,但是间歇过程具有多模态特性,数据分布复杂,采用欧式距离寻找近邻很难获得样本间全面的相似特性,这直接影响特征提取的有效性,从而降低故障检测率,进而降低故障诊断的准确性.
针对NPE算法只通过欧氏距离挑选近邻带来的特征提取不充分问题,本文提出了一种基于扩散距离邻域保持嵌入(NPE based on diffusion distance,DDNPE)算法的故障诊断新方法.DDNPE算法有效利用了样本的局部结构信息,更加准确地描述了样本点与近邻点之间的相似性,可以对原始数据进行更好的学习和特征提取.首先,DDNPE算法充分提取间歇过程数据的局部结构,进行线性降维;然后,构造T2和SPE统计量并确定其控制限,通过判断统计量是否超过控制限来完成故障的检测,检测到故障后,利用变量贡献图法诊断出故障变量;最后,通过青霉素发酵过程仿真结果验证本文提出方法的有效性.
1 邻域保持嵌入算法(NPE)
NPE算法在局部线性的假设下,通过求解特征映射矩阵Α(a1,a2,…,ad),将高维数据Χ(x1,x2,…,xn)∈Rm映射到低维特征空间Y(y1,y2,…,yn)∈Rd(d≤m)中,满足Y=ΑΤΧ.
NPE首先通过k近邻法为每个样本xi选取离其欧式距离最近的k个样本作为其近邻点,然后通过近邻点线性重构样本点,重构系数矩阵W可以通过求解下式定义的重构误差最小化公式得到:
(1)
NPE的思想是降维后的特征空间与原始高维空间具有相似的局部结构,即在高维空间重构样本点xi的权重系数wij,可以在低维空间中重构对应的yi,特征映射Α可以转化为求解下式的最优解问题:
(2)
其中:Μ=(I-W)Τ(I-W);约束条件为yΤy=aΤΧΧΤaΤ=1.式(2)的最优化问题最终转换为如下的广义特征值求解问题:
ΧΜΧΤa=λΧΧΤa
(3)
求解上式广义特征值问题,其最小的d个特征值(λ1≤λ2≤…≤λd)对应的特征向量组成特征映射矩阵Α(a1,a2,…,ad).
2 扩散距离
扩散距离(diffusion distance,DD)是源于扩散映射的概念,扩散映射使用一系列的扩散核进行数据降维,避免了高维矩阵特征分解时的不稳定性和不可行性,其主要思想是在样本集上构造一个扩散图,用扩散距离描述样本间的相似程度[15-17].扩散距离的关键在于其是基于扩散图上的多条路径,它反映的是来自扩散过程中样本点之间相关性的内在几何特征,考虑了样本点间距离贡献权重.因此,与欧式距离相比,扩散距离能够更加准确地衡量数据点间的相似性.
首先,引入高斯核定义样本x1与x2的权重为
w(x1,x2)=exp(-‖x1-x2‖2/2σ2)
(4)
w(x1,x2)表征了样本x1和x2之间的关联强度,其值越大,关联性越强.
在样本训练集X∈Rn×m上定义马尔科夫随机游走,定义一步转移概率:
由式(5,6)可以得到一个n×n的一步转移概率矩阵:
P(1)=[p1(xi,xj)]∈Rn×n(i,j=1,2,…,n)
p1(xi,xj)表征了样本集X中样本点一阶近邻分布,其值越大,说明样本点xi和xj越密集,关联性越强.P(t)=[pt(xi,xj)]∈Rn×n,i,j=1,2,…,n是一步转移概率P(1)的t次迭代,pt(xi,xj)为样本点xi到样本点xj的t步转移概率,随着t的适当增加,样本点间近邻的关联影响可以由pt(xi,xj)精确表达,即P(t)反映了带有关联权重信息的样本点间的本质结构,其中2步转移概率可以较为精确地反映样本间的关联性,且计算量适中.
最后,扩散距离定义为
其中:i,j,l=1,2,…,n;1/Φ0(x)是样本点密度不同区域相应的惩罚差异因子.
3 基于DDNPE算法的故障诊断
本文将提出的DDNPE算法应用于间歇过程故障诊断,将原始空间划分为主元空间和残差空间,利用T2和SPE统计量分别反映主元空间和残差空间的工况波动情况,通过判断统计量是否超过控制限来检测故障.检测到故障后,通过贡献图法确定故障变量.
3.1 DDNPE算法
NPE算法可以在纬度约简的同时保持数据的局部结构特征.相比于PCA算法,NPE可以挖掘隐藏于高维数据中更多的本质信息.NPE算法将样本点间欧氏距离的大小作为挑选邻域的标准,假设样本点服从同一分布,每个样本点均可以被看作概率分布的中心,欧式距离可以用来衡量样本点与其近邻点之间的相似性,然而间歇过程具有多模态特性,过程数据往往来自多个模态,不再服从单一的高斯或者非高斯分布.如果不考虑数据的复杂分布,继续将样本点与其近邻点之间的相似性用欧式距离来衡量是不准确的,会直接影响故障检测的效果.
为了克服NPE算法只利用欧氏距离为样本挑选近邻带来的特征提取不充分问题,本文将扩散距离与NPE算法相结合,提出了DDNPE算法.该算法充分利用了数据的局部特性,将间歇过程的多模态特性以及数据的复杂分布考虑在内,可以更加准确地学习和提取高维数据的局部特征.
DDNPE算法首先将三维数据X(I×J×K)(I代表批次,J代表变量,K代表采样点)按批次方向展开成二维数据X(I×KJ),对其按列进行标准化处理使得在同一个水平上衡量变量,再将已经标准化处理的矩阵按变量方向排列,构成二维矩阵X(IK×J),接着计算样本点xi与其他训练样本间的欧式距离并从小到大排序,取欧式距离最小的k个样本点作为样本xi的近邻点,然后按照式(7)计算样本点xi与其k个近邻点之间的扩散距离,并更新距离.由于样本点xi到训练集中其他样本点的转移概率和样本点xj到训练集中其他样本点的转移概率相应分布较近,则训练集X中样本点xi和xj较接近.其反映的是来自扩散过程中样本点之间相关性的内在几何特征,样本点间的随机游走步伐越大,样本点间有更大的转移概率,扩散距离就越小.一般来讲,属于同一模态的样本点之间随机游走的步伐更大,从而具有更大的转移概率,进而扩散距离越小,利用扩散距离为样本点找到的近邻点与样本点属于同一模态,因此与样本点之间具有更大的相似性,从而能够更加准确地重构样本点.
将样本xi与其k个近邻点之间的距离更新完后,从小到大排序,选择距样本点最近的k/2个近邻点重构样本点.采用下式计算重构系数:

(j=1,2,…,k/2)
(9)
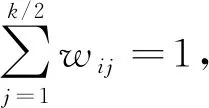
最后,利用得到的重构权重矩阵计算特征映射矩阵A,进而得到训练数据集X的低维表示Y.
3.2 基于降维数据的故障诊断
假设标准化后的训练数据表示为Χ(x1,x2,…,xn)∈Rm,令Y(y1,y2,…,yn)∈Rd为训练数据X在低维空间的投影,通过DDNPE算法计算得到特征映射矩阵A,进而得到测试样本xtest的低维表示为ytest=ΑΤxtest,则T2统计量可通过下式计算:
(10)
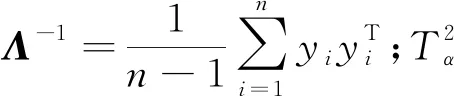
监控残差空间的SPE统计量为
(11)
当测试数据的T2和SPE统计量超过控制限时,可判断过程发生了异常,发生异常后,就需要找到引起故障的原因,利用统计量贡献率确定故障变量的方法中贡献率如下计算.
计第i个过程变量为xi,则第i个变量对T2统计量的贡献率通过下式计算:
(12)
其中:λj为特征向量A的第j个特征值.
而第i个变量对SPE统计量的贡献率通过下式计算:
(13)
3.3 算法步骤
DDNPE算法用于间歇过程故障诊断有离线建模和在线监控两个过程,流程图如图1所示.
1) 离线建模
步骤1:在无故障工况下获取若干批次过程数据X(I×J×K),将其展开并进行标准化处理;
步骤2:利用DDNPE算法提取数据局部结构特征,得到投影矩阵A,计算得到训练数据X在低维空间的投影Y(y1,y2,…,yn)∈Rd;
步骤3:将原始变量空间划分为特征空间和残差空间,计算训练样本的T2和SPE统计量以及控制限.
2) 在线监控
步骤1:在线获取新的测试数据Χtest,将其按批次方向展开并用离线建模时的均值和方差进行标准化处理,进一步按变量方向展开;
步骤2:利用离线建模步骤2获取的特征映射A对每一个测试数据xtest线性降维,得到其低维表示xtest;
步骤3:计算测试数据的T2和SPE统计量,判断其是否超出控制限;
步骤4:若统计量超出控制限,用贡献图法找到故障变量;若没有超限,说明没有故障,继续采集测量数据,并对其进行故障检测.
4 仿真实验
本文通过Pensim2.0[19]青霉素发酵过程标准仿真平台产生间歇过程数据,该平台可以产生不同初始条件、不同工况下各过程变量在每一采样时刻的数据.本文设定每一批次反应时间为400 h,采样时间为2 h,通过设置不同但都在正常范围内的初始条件和参数产生30个批次正常工况下的数据,从产生的18个变量中选择10个变量作为监控变量,构成三维数据X(30×10×200) 用于模型建立.为了更符合实际情况,所有测量变量均加入了测量噪声.这10个监控变量为:通风速率(L/h),底物进料速率(L/h),搅拌功率(W),底物浓度(g/L),补料温度(K),溶解氧浓度(mmol/L),反应器体积(L),排气二氧化碳浓度(mmol/L),发酵罐温度(K),pH值.
Pensim2.0除了可以产生无故障的训练数据外,还可以产生三类故障工况下的数据,本文引入故障类型2,即搅拌功率故障,在采样时间100~200 h(采样点50~100)加入20%的阶跃信号作为故障信号,产生的数据作为故障样本用以故障检测.分别用PCA算法、NPE算法和本文提出的DDNPE算法对故障样本进行监控,监控结果如图2~7所示.
从图2和图3可以看出,PCA的两种统计量虽都能检测到故障的发生与消失,但两图中均存在多处超限现象,尤其在样本点1~20产生多处误报.这是因为,样本点1~20即为采样时间的1~40 h,在这段时间,青霉素发酵过程要经历从菌种的培养到开始补料进行发酵的过程切换,此时生产不稳定,由于PCA只能保持数据的全局结构而不能保持数据的局部结构,以致无法提取原始数据更多隐含的数据特征,造成误报.
从图4可知,NPE算法的T2监控图完全没有检测到故障,这是因为NPE算法虽保持了数据的局部特征,但其在寻找近邻时,用欧氏距离衡量样本间的相似特性,没有考虑间歇过程的多模态特性以及数据的复杂分布,因此NPE算法的特征提取能力受限,从而降低了故障检测率.从图5可知,NPE算法的SPE统计量可以检测到故障,且除过菌种的培养阶段出现的三处误报,其他时间均未出现任何误报和漏报现象,由此可见,NPE算法保持原始数据局部结构在故障诊断过程具有一定的优越性.
从图6可知,DDNPE算法的T2统计量除在样本点1~18出现少数几处误报外,均能正确检测出故障的发生与消失,且其在故障时段的统计量值远离控制限,可知DDNPE可以明显检测出故障的存在.从图7可知,DDNPE算法的SPE统计量监控没有出现任何误报和漏报现象,由此可以看出DDNPE算法具有更加有效的故障检测能力.
三种方法故障检测结果的对比数据见表1.从故障检测率的对比数据可以看出,三种方法对间歇过程的故障检测都是有效的,从误报率来看,PCA和NPE存在较大的误报,PCA的SPE统计量误报率达到0.36,NPE的T2统计量误报率高达0.58,这将对生产过程的正常运行造成巨大的影响.总体而言,对比三种方法的故障检测效果,本文提出的DDNPE方法表现出了较大的优势.

表1 三种方法检测结果统计
检测到故障发生后,用变量贡献图法找到故障变量,三种方法的T2和SPE贡献率如图8~13所示.
从图8可知,贡献率最大的是变量2,符合实际真实故障,但变量3和9也有较大的贡献率,易对故障产生误报.从图9也可以看出,除过贡献率最高的变量2,其他变量的贡献率也较高,不利于故障的诊断.
图10中,贡献最大的是变量3,而实际故障变量是变量2,可知NPE算法的T2贡献图出现误诊.图11中,变量2的SPE贡献率最高,符合实际故障情况.
从图12和图13可以看出,DDNPE方法的T2和SPE贡献图中都是变量2的贡献率明显大于其他变量,其他变量具有很小的贡献率,这就很容易诊断出真实的故障变量.
由以上分析可知,本文提出的DDNPE算法能够更好地挖掘间歇过程数据的特征信息,降低间歇过程故障诊断误报率,提高间歇过程故障检测率.
5 结论
间歇过程具有比连续过程更为复杂的过程特性,对间歇过程的数据进行准确有效的特征提取是利用多元统计方法进行故障诊断的关键.本文针对间歇过程数据的多模态特性和数据的复杂分布导致的特征信息提取不全面的问题,提出了一种基于扩散距离的邻域保持嵌入(DDNPE)算法,通过用带有距离贡献权重的扩散距离为样本挑选近邻点,将样本近邻点的局部特性考虑在内,能够对原始数据集进行更好的学习和特征提取.通过青霉素发酵过程仿真结果表明,与PCA算法和NPE算法相比,DDNPE算法具有较低的故障误报率,能够更加准确地检测到故障,验证了本文方法的有效性.
