嵌入注意力机制的多模型融合冠脉CTA分割算法
2020-09-13方志军高永彬
沈 烨,方志军,高永彬
上海工程技术大学电子电气工程学院,上海 201600
1 引言
我国一直是心血管疾病的高发国之一,随着生活水平的日益提高,心血管疾病不断开始蔓延,而且发病年龄日趋年轻化,严重威胁着人类的健康。冠状动脉性心脏病(coronary heart disease,CHD),又称为冠心病。作为一种常见的心脏疾病,其病因是由于冠状动脉壁的沉积物导致血管狭窄,致使心肌缺血从而导致其功能障碍与器质性病变。因此又称为缺血性心脏病(ischemic heart disease,IHD)[1]。冠心病绝大多数的原因是由冠状动脉的粥样硬化导致的,故习惯上称冠状动脉性心脏病为冠状动脉粥样硬化性心脏病。在冠心病患者中存在处于临界状态的情况,即狭窄50%~70%。这种情况根据冠脉的结构和患者心肌功能的损伤情况判断是否需要置入支架。针对同一类型的病变,不同的医生根据冠状动脉造影结果会给出不同的治疗策略,但部分患者的冠状狭窄程度超过50%,患者的心肌并没有明显缺血,有些反之。由此可见,根据患者的冠状动脉造影指导具有主观性。因此通过计算机辅助诊断技术对冠状动脉进行准确分割的这项工作,对于及早发现冠心病以及冠心病的治疗具有重要的临床意义。
本文主要提出了一种基于深度学习多模型融合的冠脉CTA的血管分割方法,主要贡献如下:
(1)采用3D FCN(three-dimensional fully convolutional network)网络处理三维冠状动脉CTA影像,使网络可以充分学习三维空间特征。
(2)将AG(attention gate)模型嵌入3D FCN网络中去抑制不相关区域中的特征激活来提升网络预测精度。
(3)提出了一种多模型融合的方法,通过把原始网络和两种改进网络的结果用多数投票算法进行融合,有效地减少只使用单个网络模型进行血管分割容易造成假阴性和假阳性的情况。
2 相关工作
分割是医学图像分析中高度相关的任务,图像分割是基于图像中像素的一些特征将图像划分为更小分区的过程。在医学成像方面,图像的分区可以是某些组织、器官或其他相关结构的区域[2]。分割任务大多用于定量分析和诊断,医学图像分割中的金标准是由临床专家的手动分割来完成的。这是一项十分耗时的任务,因为现代医学成像模态(例如计算机断层扫描(computed tomography,CT)和磁共振成像(magnetic resonance imaging,MRI))能够以3D图像体积的形式产生大量数据,并且手动分割也存在偏差和人为错误。在临床诊断中已经使用了一些半自动方法来加速分割过程,但仍然需要临床专家来初始化或指导分割。全自动分割方法的重要性也随着患者可用数据量的增加而增加。
近年来,基于水平集的分割算法已被广泛使用,并成为医学图像分割的优选算法[3-4]。水平集方法通过整合不同类型的正则化(平滑项)和先验,基于能量最小化的问题来进行分割[5]。它们可以提供具有改变拓扑属性趋势的分割函数,缺点在于它们需要适当的轮廓初始化以获得有效的分割结果。近阶段,基于深度学习方法的卷积神经网络(convolutional neural network,CNN)已成功应用于医学图像的分析中,特别是用于分割和检测任务中[6-7]。与基于水平集的方法不同的地方在于,深度学习可以从大量训练数据中自动学习外观模型,提取复杂结构和模式的特征,并把这些训练的特征用于预测。
另外,医学图像的分割比自然图像的分割更具挑战性。首先,患者数据极具多样化。换句话说,相同病理的模式因患者而异。其次,小而不完整的医疗数据集使CNN训练更容易产生过拟合的情况。尽管如此,最近提出的CNN架构比其他基于机器学习的医学图像分割算法表现出更好的性能[8]。随后,全卷积网络(fully convolutional network,FCN)被加州大学伯克利分校的Long等人提出,扩充了原有的CNN结构,在不带有全连接层的情况下能进行像素级预测[9]。Ronneberger等人则在FCN网络的基础上提出了U-net神经网络,实现了对生物细胞图像的自动分割,与传统FCN网络不同的是,U-net网络使用跳连结构将下采样层和上采样层相连,这使得像素定位更加准确。U-net网络在医学图像分割领域表现非常优秀,很多学者将U-net网络作为基础框架[10]。但是,诸如MRI或CT的医学图像通常是3D体积形式,而现有分割网络大都是2D性质的。这些二维分割网络按顺序逐层应用,从而会忽略第三维中的空间信息[11]。由于计算复杂性和内存需求,不鼓励使用3D CNN进行模型训练。通过考虑上述问题,最近提出了3D FCN来对MRI或CT图像进行分割和检测,其中整个体积数据作为输入直接在单个前向传播中获得3D体积输出作为3D预测结果,从而降低计算复杂度[12]。与其他基于二维分割网络的方法不同,它们使用3D卷积核,可以在三个维度上共享空间信息。
尽管3D FCN具有很好处理3D医疗体积数据的能力,但是当不同患者间的目标器官在形状和大小方面存在较大差异时,有一部分做法会过度依赖于多级级联CNN。级联框架先提取感兴趣区域(region of interest,ROI)并对该特定ROI进行密集预测,应用领域主要包括心脏[13]、腹部分割[14]、肺结节检测等[15]。然而,这种方法导致计算资源的浪费和模型参数的复杂化。例如,类似的低级特征被级联中的所有模型重复提取。为了解决这个问题,最近提出了一种简单而有效的解决方案,即注意力门控模型[16-17]。具有AG的CNN模型不会影响模型训练的标准方式,并且AG能够自动学习专注于目标结构的特征而无需额外的监督。在测试时,这些门会动态地隐式生成候选区域,并突出显示对特定任务有用的显著特征。此外,它们不会造成很高的计算成本,并且不需要像多模型框架那样学习大量模型参数。优势在于所提出的AG可以通过抑制不相关区域中的特征激活来提高密集标签预测的模型灵敏度和准确度。以这种方式,可以在保持较高预测精度的同时消除使用外部器官定位模型的必要性。
3 基于深度学习多模型融合的冠脉CTA的血管分割方法
本次研究的整体工作流程如图1所示,该框架包括:(1)原始3D FCN网络;(2)在原始3D FCN中嵌入一个注意力门控模型的网络(3D FCN-AG1);(3)在原始网络中嵌入两个注意力门控模型的网络(3D FCN-AG2)。在训练阶段,通过训练这三种不同的网络来得到训练的权重信息,并在测试阶段中,分别使用三种网络训练好的权重对同一测试数据进行预测,并把三种网络预测的结果采用多数投票算法进行融合,得到网络预测的最终结果。最后,对网络预测的最终结果运用水平集函数迭代优化,得到最终的分割结果。
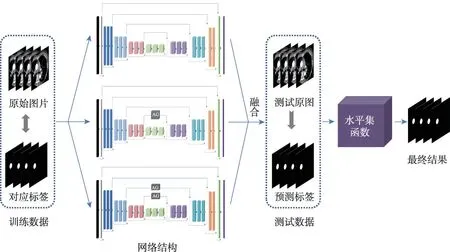
Fig.1 Overall flow chart图1 总体流程图
3.1 三维全卷积网络模型
实验采用的三维全卷积网络的结构如图2所示。此网络结构与现在比较主流的3D U-net[18]以及V-net[19]网络结构较为相似。通过运用三维卷积,目的在于从三维CTA影像数据中提取特征,并在每个阶段结束时通过使用适当的步长来调整其分辨率。网络的左侧部分由编码路径组成,而右侧部分通过解码路径将数据恢复到其原始大小。

Fig.2 3D FCN network structure图2 3D FCN网络结构图
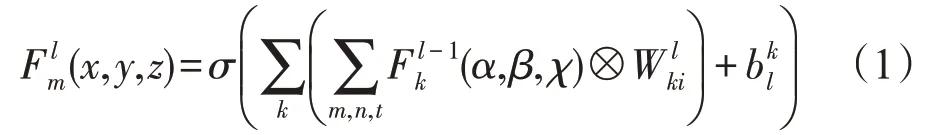
其中,α=x-m,β=y-n,χ=z-t,表示内核大小为m×n×t的3D滤波器,在每个前一层的特征体积上逐元卷积;⊗代表3D卷积运算;表示偏差,σ(·)代表非线性激活函数。这里,新引入的非线性激活函数,即参数整流线性单元(parametric rectified linear unit,PReLU)[20],来代替整流线性单元。PReLU函数给出为:

其中,Fi表示输入,σ(Fi)表示输出,αi表示学习控制Fi的负数部分所需的训练参数,而αi在ReLU中几乎为零。因此,PReLU可以根据输入情况调整整流器,从而提高网络的准确性,几乎不增加计算成本,并降低过拟合风险。
网络的左侧分为不同的阶段,以不同的分辨率运行。每个阶段包含一到三个卷积层,并且在每个阶段中,通过把每个阶段的输入在卷积层中进行非线性处理,并且将该层添加到该级的最后一个卷积层的输出中,以便能够学习残差函数[21]。在网络结构中融入残差函数学习的优点就在于可以使网络在训练过程中能够短时间内达到收敛的状态。
在每个阶段中执行的卷积使用的是卷积核尺寸为5×5×5,步长为1的卷积。随着数据沿编码路径前进不同阶段,其分辨率逐渐降低,这是通过卷积核尺寸为2×2×2,步长为2的卷积来实现的。由于第二个操作仅使用非重叠的2×2×2卷积核来提取特征,因此所得特征图的大小减半,这种采用卷积操作来减半特征图的方法也是代替了以往CNN中常用的池化操作[22]。此外,特征通道的数量也会在该网络中编码路径的每个阶段加倍,并且由于模型是由残差网络形成,通过这些卷积操作使特征映射的数量加倍,但其分辨率会随之降低。
在整个网络中应用了PReLU非线性激活函数,并且在非线性激活函数前也采用了批标准化[23],通过一定的规范化手段,把每层神经网络任意神经元输入值的分布强行拉回到均值为0、方差为1的标准正态分布,这样可以使梯度变大,避免梯度消失,加速网络收敛。使用卷积的方法进行编码操作也会导致网络在训练期间占用更小的内存。网络编码路径中通过下采样部分来减小输入的大小,并增加在后续网络层中计算的特征的接收域,而网络解码路径主要进行提取特征并扩展较低分辨率的特征图,以便收集和组合必要的信息,并且每个阶段计算出的特征数量是前一层的两倍。
最后一个卷积层采用卷积核尺寸为1×1×1来产生一个与输入体积大小相同的特征映射,并通过应用sigmoid激活函数将它转换为前景和背景区域的概率。在该网络解码路径的每个阶段之后,采用反卷积运算以增加输入的大小,随后是一到三个卷积层,涉及前一层中采用的5×5×5卷积核的数量的一半。与网络的编码路径相类似,该部分也会在卷积阶段学习残差函数来加速网络模型的收敛。
这项工作中采用了一个基于Dice系数的目标函数,它的值介于0和1之间,目标是最大化Dice系数的值。两个二元体积之间的Dice系数D可写为:

其中,总和在N个体素上运行,预测的二值分割体积pi∈P和Ground Truth二值体积gi∈G。
3.2 注意力门控模型
CTA的血管形状和大小因冠状动脉的切片而异,血管增强对于消除CTA切片中的杂质区域非常重要。在标准的CNN网络模型中,一般采取对特征图网格逐渐下采样来捕获足够大的感知场,从而能够更好地捕获语义上下文信息。通过这种方式,可以让网络模型学习到粗糙空间网格水平模型的位置和全局范围内组织之间的关系。然而,仅通过下采样的方式仍然难以减少对于显示大的形状可变性的小物体的假阳性预测。为了提高准确性,当前的分割框架大多依赖于将任务简化为单独的定位和后续分割步骤[24]。在这一任务中,通过把AG融入到标准CNN模型中可以实现相同的目标。与多级CNN中的定位模型相反,它不需要训练多个模型和大量额外的模型参数,并且AG的最大特点在于它可以逐渐抑制在不相关的背景区域中的特征响应,而不需要通过级联网络来裁剪ROI。
在标准注意力门控模型中,AG的输出是输入特征图和注意系数的逐元素乘法,公式如下:

式中存在注意系数αi∈[0,1],识别显著图像区域和修剪特征响应来保留与特定任务相关的激活。一般情况下,针对每个像素矢量计算单个标量注意值,其中Fl对应于层l中的特征图的数量。
通过学习多维注意系数来针对多个语义类情况。因此,每个AG都学会专注于目标结构的子集,其中包含门控矢量用于每个像素i以确定聚焦区域。门控向量包含上下文信息以修剪下层特征响应[25]。通过对比乘法注意[26]和加性注意[27]的性能,最终使用加性注意来获得门控系数。虽然这在计算上更昂贵,但实验证明它可以获得比乘法注意更高的准确度。加性注意力如下:
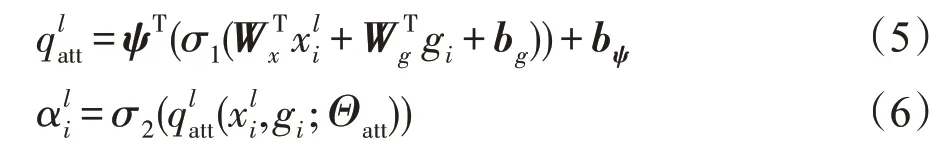
其中,AG的特征在于一组参数Θatt包含线性变换和偏置项bψ∈R,。采用基于向量级联的注意方法,对于输入张量,使用卷积核为1×1×1卷积计算线性变换,其中级联特征xl和g被线性地映射到维度中。注意系数(σ1)采用PReLU非线性激活函数,因为PReLU激活函数相比于广泛使用的ReLU激活函数可以根据输入情况调整整流器来提升精度;由于顺序使用softmax函数会在输出端产生较稀疏的激活,因此注意系数(σ2)采用sigmoid激活函数,从而让AG的参数在训练过程中更好地收敛,AG的整体流程如图3所示。

Fig.3 Workflow of attention gate图3 注意力门控模型工作流程
在工作中,通过把AG嵌入到3D FCN的网络架构中,以突出通过跳跃连接传递的显著特征,结构如图4所示。

Fig.4 3D FCN integrating attention gate图4 嵌入注意力门控模型的3D FCN结构图
该结构可以把网络粗略提取的信息通过门控来消除跳跃连接中的不相关和噪声区域。另外,AG在正向传播以及反向传播期间过滤神经元激活,源自背景区域的梯度在反向传播期间向下加权,这允许较浅层中的模型参数主要基于与给定任务相关的空间区域来更新。在每个子AG中,提取并融合补充信息以定义跳跃连接的输出。为了减少可训练参数和AG的计算复杂度,采用卷积核为1×1×1的卷积来执行线性变换,并且输入特征映射被下采样到门控信号的分辨率,类似于非局部块[28]。相应的线性变换将特征图解耦并将其映射到用于门控操作的较低维空间。其次在门控功能中不使用低级特征图,因为它们不表示高维空间中的输入数据。因此使用了两种嵌入AG的3D FCN网络模型,一种是将AG嵌入到网络结构中最后一层跳跃连接上(图4(a)所示),另一种则是将AG嵌入到最后两层跳跃连接上(图4(b)所示),从而加强整个网络对相关特征的学习。
3.3 模型融合及后处理方法
鉴于在工作中如果使用单个模型很容易造成预测结果的假阴性和假阳性情况,因此在下阶段采用了一种模型融合的方法,对于三种网络模型(3D FCN、3D FCN-AG1以及3D FCN-AG2)的预测结果,用多数投票法进行分类,投票多者确定为最终的分类。具体来说,针对测试数据的每一个像素点,通过三个网络模型会预测出三个结果,如果结果中有两个或两个以上预测结果是血管,该像素点的最终预测结果即为血管,反之亦然。
通过上述方法得到最终网络预测的分割结果,据观察发现,在分割出的血管上存在边缘比较粗糙的问题,为了解决这一问题,在后处理阶段仍需采用水平集方法对血管边缘轮廓进行迭代优化。
水平集方法[29]的基本思想是将平面闭合曲线隐含地表达为二维曲面函数的水平集,即具有相同函数值的点集,通过水平集函数曲面的进化隐含地求解曲线的运动。水平集函数的演化满足如下的基本方程:

其中,φ为水平集函数,其零水平集表示目标轮廓曲线,即Γ(t)={x|φ(x,t)=0},表示水平集函数的梯度范数;F为曲面法线方向上的速度函数,控制曲线的运动。
4 实验
实验所采用的冠脉CTA影像数据一共包括70组病人数据,每组病人的切片数都在250~350之间,由于冠脉CTA影像数据的完整性导致在整个病人切片序列中前一部分切片和后一部分切片中存在无用切片序列(切片中只存在主动脉或者血管消失的情况)。如图5所示,图5(a)中是实验所需要的图片,图片中包含主动脉以及冠脉血管(位置关系如箭头指向所示),图5(b)中只存在主动脉,冠脉血管还没有出现,图5(c)中血管已经全部消失。并且通过统计发现每组病人从冠脉出现到冠脉完全消失的整个过程都在150帧切片以内,因此通过人工筛选的方式以每组病人数据中冠脉出现的那一帧切片作为参考项取前10帧切片作为起始帧,选出160张切片作为每组病人的实验数据,共约11 200张CTA影像图片,每组病人的CTA影像数据尺寸为512×512×160,将50组病人数据作为训练集,将其余20组病人数据作为测试集。

Fig.5 Data sample of various slices图5 数据样本切片
实验采用Keras库来实现模型[30]。利用Adam的优化算法来优化网络模型[31]。学习率最初设定为10-5,在单个NVIDIA GPU(Nvidia GTX 1080Ti)上训练整个模型500个epochs。训练过程大约需要10 h。由于运行内存的限制,模型每一次的输入尺寸为128×128×160,因此将原始CTA数据缩小为网络输入所需尺寸。
通过计算各自血管分割之间的JI(Jaccard index)和DSC(Dice similarity coefficient)分数[32]来比较分割精度的好坏。JI分数可理解为预测正确面积占两者面积并集的比值,DSC分数可理解为两倍的预测正确结果面积占两者面积相加的比值,两个数值的范围都在0~1之间,数值越高,证明分割的精度越好。JI和DSC的计算公式如下:

其中,Y代表GT,Yp代表预测值。
实验中不同算法分割精度如表1所示,首先在20组病人数据集上测试了原始3D FCN网络在冠脉血管上的分割精度,JI和DSC均值能到达0.796 2和0.884 3,主动脉能准确分割出来但是冠脉的部分小血管存在一定的丢失。其次,又分别测试了在原始网络的一层跳跃连接和两层跳跃连接中分别嵌入注意力门控模型,发现两种改进后的网络模型分割结果的JI和DSC均值明显超越了原始网络,分别达到0.815 4、0.896 6以及0.811 9、0.893 6。特别在一些亮度不是特别明显的冠脉血管的分割上有较好的效果,如图6阶段(1)所示,通过原始网络的分割容易导致冠脉小血管的丢失(图中黄色箭头所示为未分割出血管部位),但是采用嵌入注意力门控模型的网络就能很好地弥补原始网络经常出现的这种问题,提升整体分割精度。然后,在可视化实验结果的过程中发现,虽然嵌入注意力门控模型在整体的效果上有所提升,却仍然会出现一些分割上的问题,如图6阶段(2)所示,原始网络的分割表现很好,但是在嵌入注意力门控模型的网络却出现错误判断血管的情况,误将杂质分割成了血管(图中黄色箭头所示为血管分割错误部位),造成部分效果甚至不如原始网络。针对这种问题,使用了一种多模型融合的方法,通过把原始网络,以及两个嵌入注意力门控模型的改进网络的预测结果通过多数投票算法来得到最新预测结果。实验结果证明,这种方法得出的分割结果的JI和DSC均值为0.821 4和0.900 5,优于以上三种模型中最好的结果。最后,从上述实验中发现如果只用深度学习的方法去分割血管,虽然能够把血管的骨架分割得很好,但是在一些细节处理上,特别是分割的轮廓上都会显示得比较粗糙,并不是很光滑,因此在最后还加入了后处理部分,采用水平集算法对已经分割好的血管边缘轮廓进一步迭代优化,如图6阶段(3)所示。并且,为了便于分析测试数据中每组病人数据的分割结果,还通过箱线图的形式对各组结果进行统计,如图7所示。图7中原始的3D FCN的每个病例结果以及均值都不高,在嵌入了AG的两个网络结果中均值相较于原始3D FCN的结果都呈现出较大提升,再进行三个模型融合后的结果不管在每个病例结果还是均值上都有明显提升,最终分割结果也是通过水平集方法在模型融合结果的基础上得到进一步优化。

Table 1 Comparison of segmentation accuracy for various algorithms表1 不同算法分割精度的比较

Fig.6 Segmentation results of different methods for three stages of coronary CTA data图6 不同方法对三期冠状动脉CTA数据的分割效果
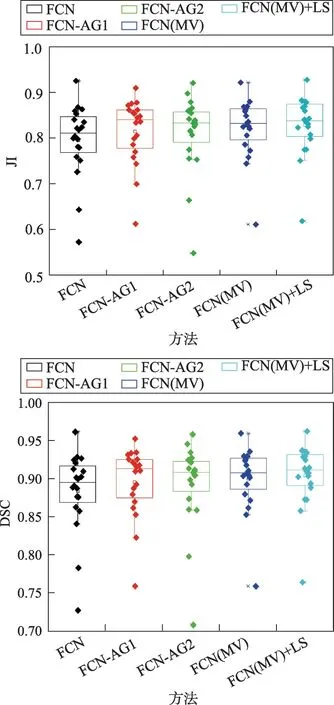
Fig.7 Boxplots of experimental data results图7 实验数据结果的箱线图
5 结论
本文提出了一种基于深度学习多模型融合的方法来进行冠脉CTA血管的分割,该方法包括三个网络模型:一个原始3D FCN来处理三维体积数据,训练一个端到端的网络来对三维冠脉CTA进行预测,以及两个在原始3D FCN中嵌入AG模型的网络。使模型在训练过程中可以抑制不相关区域中的特征激活来提高密集标签预测的模型灵敏度和准确度,然后把三种网络的预测结果采用多数投票算法进行融合来减少分割中易造成的假阴性以及假阳性情况,得到网络预测的最终结果。同时把网络预测结果送入水平集函数进行边缘轮廓的迭代优化,得到最终的分割结果。与原始网络的分割效果相比,本文提出的方法在冠脉血管分割上提供了更好的分割精度与效果。
