融合自注意力机制的跨模态食谱检索方法*
2020-09-13王亚沙毛维嘉赵俊峰
林 阳,初 旭,王亚沙,毛维嘉,赵俊峰
1.高可信软件技术教育部重点实验室,北京 100871
2.北京大学计算机科学技术系,北京 100871
3.北京大学软件工程国家工程研究中心,北京 100871
1 引言
人们日常的饮食习惯对于人们的身体健康有着极为重要的影响。随着生活水平的不断提升,人们对饮食健康的关注程度越来越高。而日常饮食摄入的记录,作为饮食管理的关键环节,更是越来越受到人们的重视[1-2]。而对某些慢性病患者(如慢性肾病患者)而言,由于其疾病治疗的需要,对营养摄入的监控更是至关重要[3-4]。
传统的饮食摄入记录工具的基本流程是,通过用户拍摄的食物图片,对食物类别和原材料种类进行预测,并进一步估计其中的营养成分含量[5-7]。然而,由于人们自制的食物的风格、外观多变,实际上得到的结果不足以支持从食物图片中进行营养含量的推定[8]。
随着互联网的发展,越来越多的人们开始将食物图片和食谱上传至社交网络和公开的食谱网站。这使得大规模的收集食物图片及其对应的食谱成为可能,也为解决饮食摄入记录问题提供了新的思路。
在大规模的食谱数据的支持下,一个新的研究方向开始兴起:食谱检索,即通过一张食物的图片在大规模的食谱中检索其对应的食谱[9-11]。被检索到的食谱中包含着食物的类别、原材料种类及用量等信息,在其基础上可以进一步进行原材料识别、营养含量估计等其他相关工作,达到饮食摄入记录的目的。除了在传统预测方法使用到的标签信息之外,食谱中还包含着食物制作的操作步骤信息,其中蕴含了比类别标签更丰富的语义信息,可以帮助模型更好地理解食物图片中所包含的语义,取得更高的准确率[10]。
食谱检索问题是一个典型的跨模态(crossmodal)检索问题[12],即通过一个模态(如图片)的数据在另一个模态(如文本)的数据库中寻找对应的样本。比如图片与其简单文字描述之间的相互检索,就是跨模态检索领域常见的问题。
与一般的跨模态检索问题相比,食谱检索问题的难点主要在于食谱中文字与食物图片联系的复杂性。食谱描述了从原材料到最终成品的一系列变化过程,而不是直接描述了成品食物图片中可见的特征。这些变化过程之间的叠加和相互作用是十分复杂的,相同的原材料经过多重操作后外观可能完全不同,而相似的成品外观反而可能出自经历了不同处理的不同原材料。因此,通过图片特征检索食谱,需要模型深入理解图片中出现的原材料在食谱中的处理过程,换言之,需要充分捕捉对同一种原材料进行加工处理的多个步骤之间的依赖关系。
然而,在食谱中,同一原材料的多个处理步骤的文本并不总是紧靠在一起的。食谱中的加工步骤,根据其时序依赖关系一般可以表示为一个树形结构[13],对不同原材料的加工步骤分属不同的没有时序依赖关系的分支流程,最终不同原材料的多条处理流程汇总到一起。然而,大多数的食谱其格式要求把原本树形结构的流程记录成一个线性结构,对不同原材料加工处理的流程相互交织在一起,因此对某种原材料加工的两个相邻步骤之间文本可能相隔较远。如图1中食谱所示,步骤1与步骤4斜体文本都是关于同一种原材料(土豆)的加工步骤,它们之间的依赖关系明显高于其相邻步骤。
当前食谱检索方向的工作,均采用了传统的文本处理模型(RNN(recurrent neural network)或其变体LSTM(long short-term memory)、GRU(gate recurrent unit)等)对食谱文字进行处理。这些模型采用线性的方式处理文本数据,捕捉远距离依赖关系的能力较差,使其难以充分理解图片中出现的原材料在食谱中的处理过程。

Fig.1 Distant dependency in recipe图1 食谱中的远距离依赖
也有研究工作尝试使用注意力机制来捕捉食谱中的依赖关系[10],但是其在注意力机制中为所有的食谱选取了相同的环境向量(context vector),没有考虑到食谱之间的差异性和独特性,导致其准确率较差。
针对上述问题,本文结合最新的食谱检索工作,并在其基础上提出了一种新的食谱检索模型。本文采用Transformer模型[14]来对食谱文字进行编码,借助Transformer模型中的自注意力(self-attention)机制,来捕捉食谱文字中远距离的依赖关系。同时,本文还对文献[10]中使用的注意力机制进行了改进,选取食谱的标题这一人工从食谱中提取的抽象信息作为环境向量,并将改进后的注意力机制结合到本文的模型中,进一步提升了模型的效果。
为了使训练得到的模型更加符合国内群众的饮食习惯,本文从国内热门的食谱网站上获取数据,构建了一个新的大规模中文食谱数据集(large-scale Chinese recipe dataset,LCR)。LCR数据集包含超过17万个中餐食谱,每个食谱包含标题、使用的原材料、操作步骤,同时数据集中还包括该食谱对应的最终成品图片。
本文的贡献在于:面向用食物图片检索文本食谱的跨模态检索任务,提出了一个新的基于自注意力机制的跨模态食谱检索方法框架;本文提出了基于Transformer网络的食谱文本编码器,并改进了传统方法注意力机制的环境向量选取方式,综上两点提升了模型理解食谱复杂文本的能力。在LCR数据集上验证了本文跨模态食谱检索方法框架的有效性,检索准确率(Recall@1)对比跨模态食谱检索领域的现有先进基线方法提升22%。
2 相关工作
2.1 跨模态检索
跨模态检索是指在不同模态的数据中检索与提供的查询样本相关的结果。常见的跨模态检索问题有通过图片检索其相关描述,或者通过关键词检索图片等。跨模态检索问题的主要困难在于如何度量不同模态的数据之间的相似度。较为普遍的一种做法是将不同模态的元素映射到一个共享的隐空间(latent space)中,在其中将相互匹配的元素对齐,使在该隐空间中不同模态的数据之间可以进行比较。跨模态检索领域的一种经典方法是典型关联分析(canonical correlation analysis,CCA)。随后CCA又发展出了诸多变种如核CCA(kernel CCA)[15]等。后来随着深度神经网络的发展,很多工作也开始采用深度神经网络进行隐空间映射[16-19]。
相比于常见的跨模态检索问题,如使用图片检索描述性文字或是相反[18],食谱检索中并不是所有文本信息都直接体现在图片上,文本与图片之间存在着复杂的关联关系。
2.2 食谱检索
食物相关的研究一直受到研究人员的关注和重视。常见的研究方向有食物识别[20]、原材料识别[8]、营养成分估计[21]等。
最初的食谱检索工作可以看作是上述研究的一个延伸,关注于通过食物图片预测食物属性,如食物类别、原材料等,进一步根据这些属性在候选集中寻找对应的食谱,如图2(a)所示。Chen等人[8]提出通过多任务学习的方法同时预测食物类别和原材料,并通过条件随机场(conditional random field,CRF)调整预测的结果。之后,Chen等人[22]认为可以加入更加丰富的食物属性,在类别和原材料之外又考虑了处理步骤这一属性。上述工作提出的模型,其训练要基于食物图片对应的标签。而考虑越多的属性,所需标签就越复杂,对数据的要求越高,如文献[22]就要求图片需要有细粒度的料理步骤标签,而这通常是很难获得的。
Salvador等人[9]率先将跨模态检索的经典的隐空间对齐思想引入食谱检索,其模型框架如图2(b)所示。这样的结构使得检索可以不受固定的食物属性的限制,训练时对人工提取的标签的需求也较低。Chen等人[10]在上述模型的基础上引入了注意力机制,使模型关注食谱中对食物外观影响更大的部分,并且捕捉其中隐含的因果关系。同时针对检索问题引入了排序损失(rankloss),加快了训练速度。Carvalho等人[11]在排序损失的基础上,提出了一个双三元组(double-triplet)损失函数,更好地利用了食谱中不同层次的语义信息。同时其还提出了一种新的梯度下降和反向传播的方法,以提升训练效果。
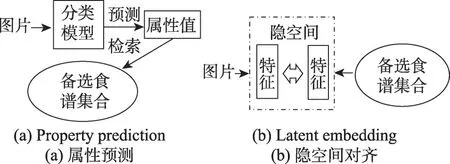
Fig.2 Two frameworks in recipe retrieval图2 食谱检索的两种框架
然而,这些方法仍存在一些不足之处。但在上述方法中,均使用了循环神经网络(RNN)或其变形(LSTM、GRU)等线性处理文字的模型来编码非线性的食谱文本。本文提出了一种基于自注意力机制的食谱文本编码器,可以更好地处理食谱中长距离的步骤间依赖关系。
3 模型设计
3.1 模型框架概览
本文模型框架如图3所示,共由三部分组成,分别为食谱文字编码模块(text encoding module)、图片编码模块(image encoding module)以及联合嵌入模块(joint embedding module)。
文字和图片两种模态的数据分别经过各自的编码模块得到对应的特征表示。其中食谱文字被分为标题、原材料、操作步骤三部分,分别由三个不同参数的文本编码器进行编码,并最终通过拼接得到食谱文字的特征表示;而食物图片则通过深度卷积神经网络进行编码。接着两个模态的特征向量进入联合嵌入模块,学习在一个共享的隐空间中的嵌入表示,使得匹配的文字与图片之间的相似度尽量高。整个模型为端到端(end-to-end)训练。接下来将分别介绍模型中的不同模块。
3.2 文字编码模块
3.2.1 Transformer模型
Transformer模型是Google于2017年提出的一种模型[14],其原本的目的是代替循环神经网络解决自然语言处理中seq2seq的任务。与循环神经网络相比,Transformer解决了两个问题:一个是摆脱了串行的计算顺序,提升了其并行能力;另一个是解决了循环神经网络在处理长文本时,由于文本过长出现“遗忘”现象,导致难以处理远距离依赖的问题。
Transformer模型之所以能够处理远距离依赖问题,主要依赖于其采用的自注意力(self-attention)机制。不同于循环神经网络(RNN)只能通过上一个时间片传递的隐含层信息了解之前的信息,借助自注意力机制,Transformer模型可以“全局浏览”输入的数据,并找到与其相关性更高的部分。举例而言,如图4,在处理食谱中“翻炒土豆丝”一步时,循环神经网络(图4(a))只能接收前一步传递的信息,而自注意力机制(图4(b))可以在全局范围内寻找与该步相关性较高的步骤(如“土豆切丝”这一步)。
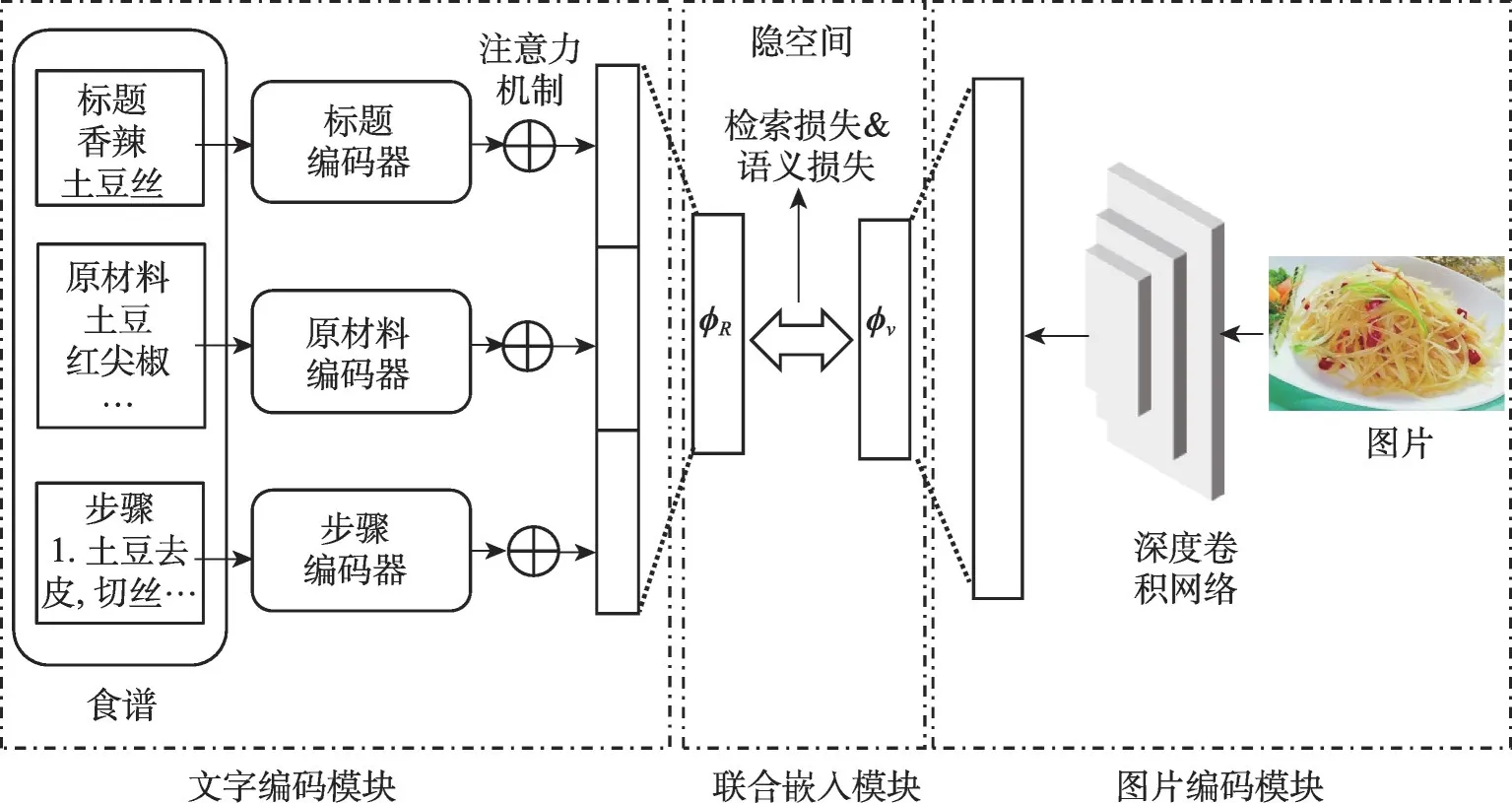
Fig.3 Model framework图3 模型框架

Fig.4 Comparison between RNN and self-attention mechanism图4 循环神经网络与自注意力机制对比
本文采用Transformer模型的encoder网络作为文本编码器,encoder网络的结果如图5所示。
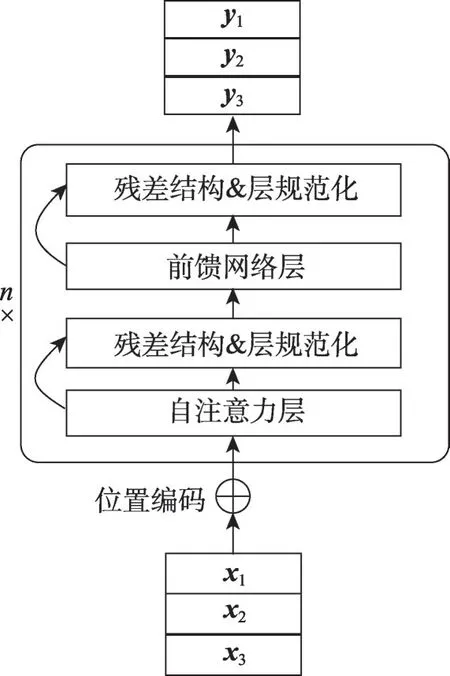
Fig.5 Encoder in Transformer model图5 Transformer模型中的encoder网络
在本文剩余的部分中,将该网络记为:

其中,x为输入的词向量;y为词向量经模型编码后的隐含层向量。
3.2.2 标题编码
每个食谱均包含一个标题。食谱的标题通常是对食谱的一个高度总结,一般会包括食谱中使用的主要原材料和主要烹饪方式(如西红柿炒鸡蛋),有的也会包括风味或菜系(如香辣土豆丝、川味排骨等)。
给定一个食谱的标题,其中包含T个词wt,t∈[1,T]。首先通过word2vec算法将其转换为n维词向量,之后将这T个词向量输入一个文本编码器中,每一个向量均可以得到一个n维的隐含层表示ht:
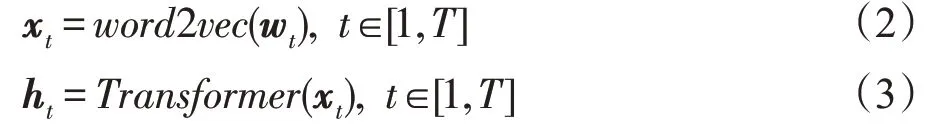
接着本文采用注意力机制,来计算整个标题的编码。注意力机制的原理就是为不同隐含层表示计算权重,并通过加权求和的方式得到最终的特征表示,以此来体现文本中不同部分的重要程度。在本文中,注意力机制是通过一个单层的多层感知机(multi-layer perceptron,MLP)和一个SoftMax层来实现的:
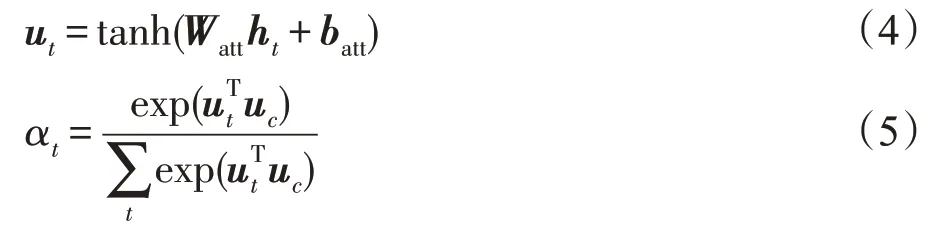
其中,Watt和batt为感知机层的参数,可以通过反向传播进行训练。
注意力机制最终得到的权重αt是通过ut与uc之间的相似度来衡量的。uc被称为环境向量(context vector),用于表示对隐含层向量的选择倾向。环境向量的选取方式详见3.2.5小节。
最终,标题的编码embtitle(64维)由标题中的每个词的隐含层表示加权平均获得:

3.2.3 原材料编码
食谱中通常会有一个部分列出其中使用的各种原材料,其中包括可见的材料(如西红柿、土豆等)与不可见的材料(如盐、糖等)。
原材料编码embingr的获得的方式与标题编码的方式基本相同。首先通过式(2)、式(3)得到隐含层表示,接着通过式(4)、式(5)计算权重,并最终通过式(6)得到最终的编码embingr(64维)。
3.2.4 步骤编码
操作步骤详细描述了食物的制作过程,是食谱中语义信息最丰富的部分,也是最复杂的部分。通常该部分是由多个长句子组成的。操作步骤部分的描述通常与成品的外观没有直接的对应关系,比如,“放入锅中翻炒”这个步骤,并没有直接描述处理之后原材料颜色和形状的变化,而需要模型自己去理解。
在对步骤信息进行编码时,本文没有选择类似[10]的层次编码的方法,即:先通过一个编码模型,将词向量转换为句子级别的编码,再通过第二个编码模型,得到所有句子的整体编码。本文没有采用层次编码方法,而是仍采用了单个Transformer模型,从词向量直接得到最终的整体表示。这样做的原因在于以下几点:首先使用层次Transformer模型对计算资源的消耗是巨大的;其次,Transformer模型本身多个子层的堆叠已经起到了一定程度的抽象作用(本文在实际测试时也发现两种方法准确率基本相同)。综上所述,在编码步骤信息时,将其视为一个较长的文档,仍采用式(2)到式(6)得到最终的步骤编码embinst(256维)。
3.2.5 环境向量的选择
文献[10]中使用了与本文类似的注意力机制。本文对文献[10]中注意力机制的uc(环境向量)选择方式进行了改进。文献[10]中uc采用随机初始化,在训练的过程中不断调整,并在所有食谱之间共享。这种方式并不是选取环境向量的最优方式,随机初始化并且共享的uc难以反映不同食谱的独特性。本文选择使用标题的所有隐含层向量的最大池化作为uc,原因是食谱的标题可以看作是食谱的撰写人提供的对食谱的整体总结,从中可以得到一个食谱更好的综合表示,从而帮助注意力机制将更高的权重赋予该食谱更加重要的部分。实验部分也证实本文采用的方式确实可以得到较高的准确率。
3.2.6 文字整体编码
食谱文字整体的编码由三部分的编码拼接得到:
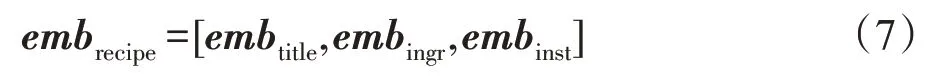
3.3 图片编码模块
在处理图片时,本文采用了当前图像处理领域广泛采用且效果较好的深度卷积网络——深度残差网络(deep residual network,ResNet)[23]。
本文采用50层的残差网络版本ResNet50作为图片编码模块,并采用该网络在ImageNet数据集上预训练的参数对网络参数进行初始化。在将图片输入残差神经网络后,本文选取网络的倒数第二层(即除去最后一层SoftMax分类层)作为图片数据的编码embimage,维度为2 048维。
3.4 联合嵌入模块
本文将文字与图片中对应的信息分别通过一层全连接神经网络编码映射到同一个隐空间,分别表示为ϕR与ϕv。隐空间维度为1 024维。全连接网络使用tanh激活函数,原因是希望在该隐空间中使用余弦相似度来度量样本表示之间的相似度:
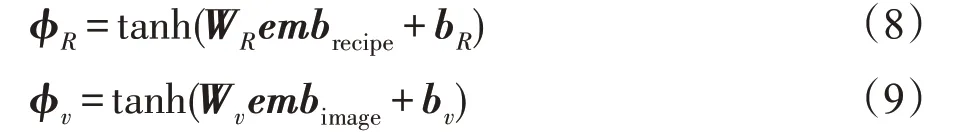
3.5 损失函数
本文中采用与文献[11]相同的损失函数,其中包括两部分:检索损失Lretr与语义损失Lsem。总的损失函数为:

其中,λ为控制检索损失与语义损失相对大小的超参数。
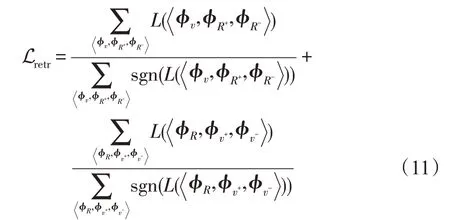
检索损失的目标是,使得锚样本与正例之间的相似度至少高于其与负例之间相似度一个正数α。
语义损失的计算方式与检索损失基本一致,不同之处在于三元组构建时,正例和负例分别选取另一个模态中与锚样本类别相同和不同的样本的表示,记为
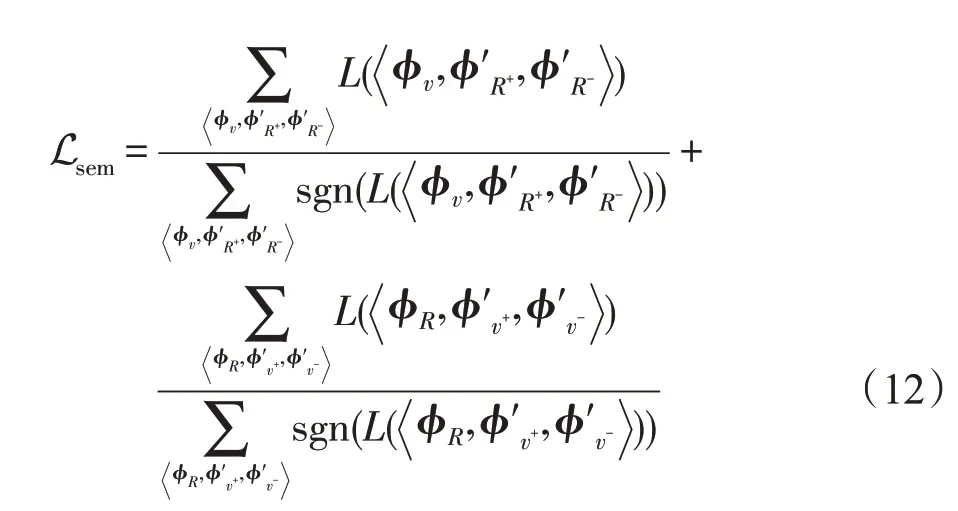
语义损失的目标,是希望尽量提高不同模态间同一类别样本之间的相似度,降低不同类别样本之间的相似度。
3.6 模型训练
由于整体模型较大,参数较多,同时学习文字和图片两个编码模块的参数可能会造成训练结果的震荡。因此,本文借鉴跨模态领域训练模型时常用的思路[24],对模型进行分阶段训练。训练过程共分为三个阶段:
第一阶段,固定图片编码器模块的参数,反向传播时,只更新文字编码模块及联合表示学习模块的参数,直到在验证集上准确率收敛。
第二阶段,固定文字编码模块和联合表示学习模块的参数,反向传播时,只更新图片编码模块的参数,直到在验证集上准确率收敛。
第三阶段,同时更新所有模块的参数。经过前两阶段的训练后,所有模块的参数均已基本训练完成,该阶段仅对模型参数进行进一步的微调。
算法1对模型的训练过程进行了总结。
算法1模型训练过程
参数:食谱编码模块参数θR,图片编码模块参数θv,联合嵌入模块参数θJ,批尺寸N,超参数α、λ。
输入:食谱集合R,图片集合V。
输出:网络参数θR、θv、θJ,食谱与图片在隐空间内的嵌入ϕR、ϕv。


4 实验验证
4.1 数据集
为了使模型更符合国内的饮食习惯,本文从国内热门的公开食谱网站中下载数据,构建了一个大规模的中餐食谱数据集——LCR数据集。
LCR数据集中共包括177 048个食谱及该食谱对应的成品图片,在实验时,本文随机从中抽取15 000个作为验证集(validation set),15 000个作为测试集(test set),剩余147 048个作为训练集(training set)。
LCR数据集中的每个食谱均包括标题、原材料、操作步骤三部分。经统计,每个食谱的平均标题长度为6.83个字,每个食谱中平均包含6.89种原材料与7.34个操作步骤。
同时,本文参考文献[9]的方法,通过二/三元组匹配的方法,将LCR数据集中的食谱分为了1 026类,其中第0类为背景类,表示类别无法确定的食谱。在全部食谱中,属于背景类的食谱约占52%。
4.2 实验设置
4.2.1 实现细节
本文代码使用Pytorch框架实现。模型使用Adam优化器进行训练,学习率为10-4,间隔α为0.3,λ为0.1,批尺寸(batch size)为50。以上超参数均在验证集上进行选择。
在计算损失函数时,选择在每个批(batch)中为锚样本选择正例和负例。具体而言,将一个批中所有的样本均视为锚样本,对每个锚样本,在该批中寻找所有符合条件的正负例构建三元组,以进行检索损失和语义损失的计算。
4.2.2 评价指标
本文实验选取了使用图片检索食谱(im2recipe)及使用食谱检索图片(recipe2im)两个任务来衡量模型的准确率,并分别在1 000/5 000/10 000三种大小的备选集合上进行测试。
本文实验采用中位序数(median rank,MedR)以及topK召回率(recall rate at topK,R@K)作为准确率评价指标。中位序数指所有检索样本对应的被检索样本在检索结果中的序数的中位数,其值越低,代表模型的准确率越高;topK召回率,举例而言如im2recipe任务中的top 5召回率,指使用图片检索食谱时,图片对应的食谱出现在检索结果前5位的比率,其值越高,代表模型准确率越高。
上述所有评价指标均在每种大小的候选集上独立地计算30次后汇报平均值。
4.3 结果比较
本文选择了三种食谱检索领域近年提出的模型作为基准算法,与本文提出的算法进行准确率比较,分别为:(1)JNE(joint neural embedding)[9];(2)ATTEN[10];(3)Adamine[11]。实验结果如表1所示。
由表1看出本文模型的准确率在不同的任务、不同的备选集合大小下均显著优于三种基准算法。其中,在10 000备选集上im2recipe任务的top 1召回率相比最好的基准算法提高了22%。三种基准算法在文本编码模块上均使用了循环神经网络模型线性处理文本,而本文模型通过:(1)自注意力机制更好地捕捉食谱中远距离的依赖关系;(2)改进的环境变量更好地捕捉食谱的独特性,提高了模型的语义理解能力,取得了更高的检索准确率。
4.4 对照实验
在比较准确率的同时,本文还进行了一些对照实验,通过改变或删除一部分模型中的模块并进行准确率的比较,验证本文模型中各模块的有效性。
4.4.1 注意力机制
本文采用了与文献[10]不同的机制来选取注意力机制中的环境向量(详见3.2.5小节)。本文对两种选取方式进行了比较,详细结果见表2,其中Uc_glob为文献[10]环境向量选取方式,Uc_title为本文模型中的选取方式。文献[10]中对所有的食谱均使用同一组端到端学习的参数向量作为环境向量,而本文则选取各食谱标题编码向量的最大池化作为环境向量,更好地捕捉了不同食谱之间的差异性和独特性,在绝大多数情况下得到的结果要优于文献[10]中的选取方式。
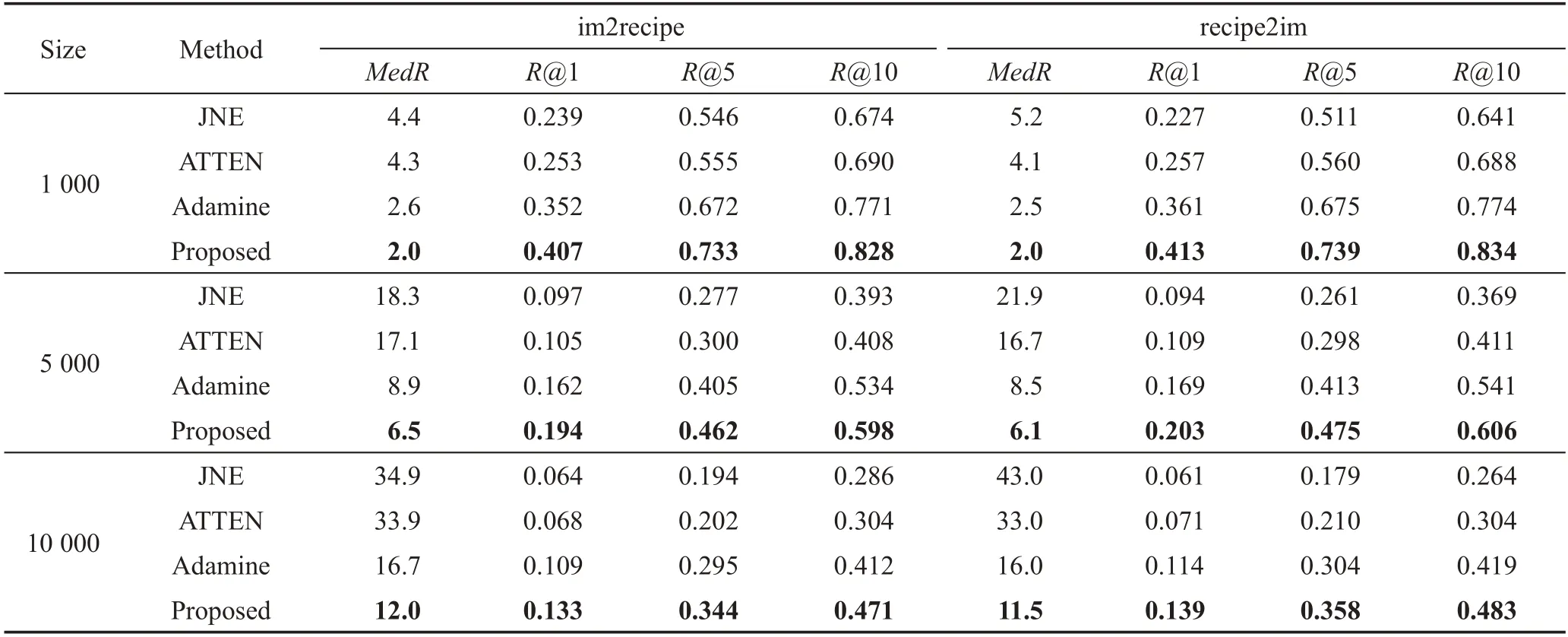
Table 1 Comparison between proposed model and baselines表1 本文模型与基线方法对比
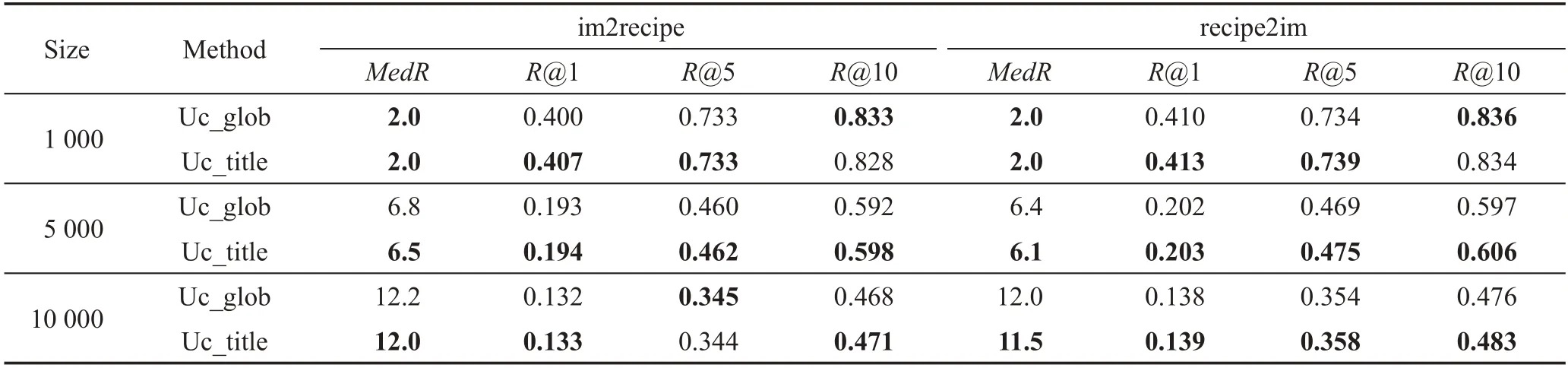
Table 2 Comparison between two attention methods表2 两种注意力方法对比
4.4.2 消融研究
图6展示了采用食谱的各个部分及其组合的数据对模型进行训练的结果(仅汇报在10 000大小的备选集im2recipe任务的准确率),该结果可以反映食谱中的各个部分的重要程度。
可以看到,单独使用食谱的某一部分进行训练时,在三部分中,使用“操作步骤”这一数据进行训练得到的准确率最高,这反映了操作步骤在食谱中的重要性。同时,这也说明了模型在理解输入的食谱时,除了标题和原材料部分包含的部分可见的特征之外,模型确实从复杂的操作步骤信息中学习到了更为丰富的隐式的语义信息,用于检索最终的成品图片。
同时,根据实验结果可以看到,单独使用标题或者原材料这两部分数据训练模型得到的结果不佳,但当两部分组合使用时,准确率甚至要略优于单独使用操作步骤数据。这说明这两部分数据中与食谱检索任务相关的信息是互补的。
4.4.3 参数灵敏度实验
本文还对模型中使用到的两个超参数λ和α进行了参数灵敏度测试,其中λ为控制语义损失与检索损失相对大小的超参数,α为损失函数中的间隔(margin),表示本文对正样本对和负样本对相似度差异的期望值。详细结果见图7(10 000备选集上im2recipe任务的R@10准确率)。
从图7中可以看出,λ过大过小均会影响模型准确率。λ过小时,模型可能无法充分利用语义损失中包含的高层语义信息;λ过大时,模型可能过于关注抽象的类别信息而不能准确地进行匹配。同样,α过大过小也会对准确率造成不良影响。α过小时,正例和负例与锚样本之间相似度的差距不明显,容易混淆;α过大时,会使模型在训练后期关注过多的三元组,其中很多可能并不需要进一步优化,导致真正需要进一步优化的三元组的训练信号被掩盖。
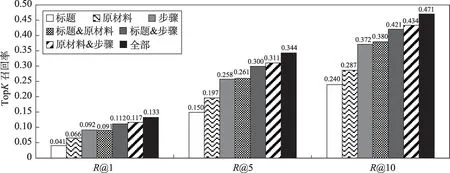
Fig.6 Experiments results of using different recipe parts and their combinations图6 使用食谱不同部分及组合的实验结果
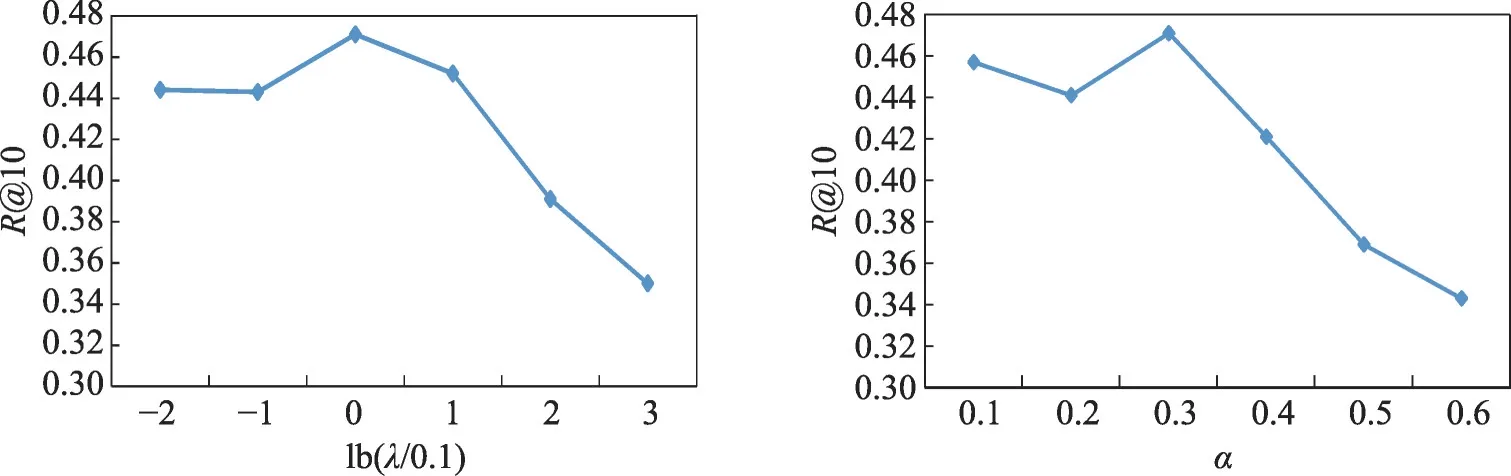
Fig.7 Experiment results of parameter sensitivity图7 参数灵敏度实验结果
5 总结与期望
针对当前人们对便捷的饮食摄入记录工具的需求,本文提出了一种基于自注意力机制的跨模态食谱检索模型,可以根据输入的食物图片自动检索与其对应的食谱,进而达到记录饮食摄入的目的。
本文模型借助Transformer模型的自注意力机制,更好地捕捉食谱中出现的远距离依赖关系,提升了模型的语义理解能力。同时,本文还对传统食谱检索模型中使用的注意力机制进行了改进,更好地捕捉了不同食谱之间的独特性,进一步提升了模型准确率。
尽管本文模型相对传统模型已经有了明显进步,但还没有达到尽善尽美的地步。当前方法仅在食谱文字编码模块中进行了有针对性的考虑,而在图片编码模块部分则采用了较为常用的图片处理模型。将来会对图片编码模块进行针对食谱检索问题的调整和优化。
