结合注意力机制和本体的远程监督关系抽取*
2020-09-13李艳娟臧明哲刘晓燕郭茂祖
李艳娟,臧明哲,刘晓燕,刘 扬,郭茂祖
1.东北林业大学信息与计算机工程学院,哈尔滨 150000
2.哈尔滨工业大学计算机科学与技术学院,哈尔滨 150001
3.北京建筑大学电气与信息工程学院,北京 100044
1 引言
伴随着互联网的发展,非结构化的文本呈指数级增长,关系抽取是从非结构化的文本中抽取两个实体之间的关联关系。关系抽取对知识图谱构建具有重要意义,可有效地降低学者阅读文献的时间成本,因此一直以来都是专家学者研究的热点。
传统关系抽取包括基于模式匹配的方法和基于监督学习的方法。其中,基于模式匹配的方法通过提取动词和特定领域术语的文本集合,计算该集合与已知关系间的联系得到关系模板,再从文本中抽取关系[1-3]。随着关系种类的增加,数据源从标准数据集扩展到网络中多源复杂冗余的文本,基于模式匹配的方法无法完全适应关系的多种表现形式。基于监督学习的方法在带标记的文本语料库上进行训练,再对测试语料进行关系预测。监督学习的方法主要基于两大方法体系,特征向量[4]和核函数[5],精准率较高,但对上下文的信息利用不足,且需要大量人工标注数据。基于远程监督的关系抽取方法不需要大量人工标注数据,且能够适应关系表达形式的多样性,因此成为目前研究热点。
远程监督由Craven等人[6]提出,基本思想是获取包含已知知识库中实体对的文本,对其运用统计文本分类的方法,找出文本当中蛋白质与其他医学概念之间的关系。Mintz等人[7]提出“如果一个句子中含有一组关系涉及到的实体对,那么这个句子就是在描述这个关系”,基于此假设,用已知知识库中的关系实例对齐纯文本,从而获得大量训练实例,大幅减少了人工标注的工作。Pan等人[8]利用远程监督的思想,在中文在线资源中采用基于SVM(support vector machine)和LP(label propagation)算法进行了任务关系的抽取。Xue等人[9]将模式匹配和远程监督思想结合,提取了人物实体之间的关系。然而,根据该假设获取的标注数据包含大量错误标签,这些噪声影响了模型学习的准确性。为了降低噪声对模型的影响,提高关系抽取的准确性,大量学者进行了研究。Socher等人[10]提出了基于RNN(recurrent neural network)的模型,该方法在处理单元之间既有内部反馈链接又有前馈链接,抽取关系时不受句子长度的制约,解决了单词向量空间模型无法提取长短语特征的问题。但是RNN在训练时容易出现梯度消失或梯度爆炸的问题,且训练时间较长。因此Zeng等人[11-12]使用了结构较简单的卷积神经网络对句子建模提取特征,然后进行分类,但这种方法在每个数据包中只选取一条概率最大的语句信息,无法利用数据袋中全部句子的监督信息。Lin等人[13-14]在卷积神经网络的基础上引入了注意力机制,按照实体对分为不同训练集,再对每个训练集中的实例权重进行动态调整。为了加强对目标关系的注意力,Ji等人[15]在注意力机制中加入了每一句中的实体对描述信息,车金立等人[16]又将字符级注意力机制与实例级注意力机制结合,进一步优化了模型。
上述基于远程监督的关系抽取方法,主要借助Mintz的假设,对海量网络文本进行数据标注,获取大量的训练语料,再使用各种方法对其去除噪声。对于一些特定领域的关系抽取存在如下问题:(1)对于一个含有多级复杂层级结构实体的领域,知识库中提出的关系实例较少且多数基于上层实体,十分抽象,用这些关系做出的远程监督的假设会引入更多的噪声数据。(2)对于一个间隔较近实体所在句子,使用已有模型对关系描述词的特征提取不足,无法准确地判断该句是否为噪声。
因此,本文在现有模型的基础上,引入了领域本体,针对以上问题进行了改进。在构造训练数据时先使用已有的模式匹配的方法在小部分文献中提取关系,这增大了对底层实体关系的覆盖量,增加了训练数据的多样性,减少了远程监督假设的噪音。对于描述关系单词较少的句子实例,本文将这些单词的特征向量引入到注意力机制中,提高了注意力机制的效果。对于抽取出的关系,加入了本体的实体层级约束,使提出的关系严格符合领域常识。最后本文使用训练好的模型在多个数据集上进行了关系抽取,在测试集SemMed数据库中的F1值为86.08%,在验证集GoldStandard数据集中的F1值为61.06%,抽取结果均比已有模型效果好。
2 关系抽取流程
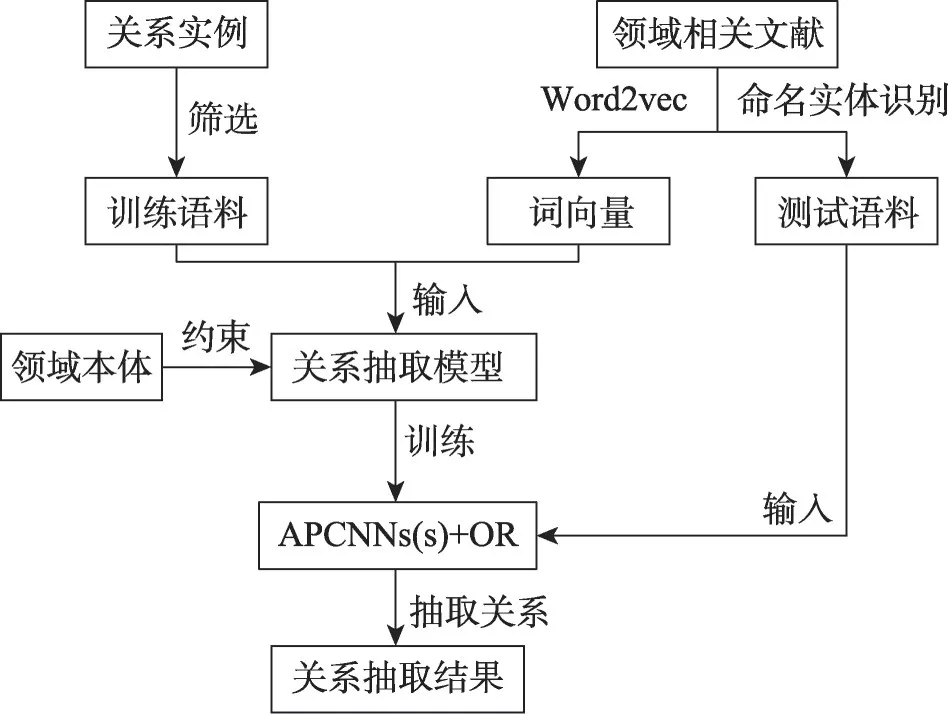
Fig.1 Workflow of relation extraction图1 关系抽取工作流程
基于注意力机制和本体的远程监督关系抽取工作总流程如图1所示。首先在已知的关系中筛选出关系实例作为训练语料,再找到与已知本体相关领域的语料库,通过预处理得到词向量,并筛选出用于测试的语料,对测试语料进行命名实体抽取得到实体对。然后使用训练语料和词向量训练关系抽取模型,使用本体中的知识约束过滤,最后用训练好的关系抽取模型对验证语料加以验证。
由于远程监督思想的假设比较宽泛,从训练文本中获取的本体关系实例存在很大的噪声,影响了关系抽取的效果。因此本文在句子级注意力模型APCNNs(attention piecewise convolutional neural networks)[15]的基础上加入了本体的关系约束,提出了关系抽取模型APCNNs(s)+OR(attention piecewise convolutional neural networks with ontology restriction)模型。该模型由三个模块组成:特征工程提取模块、分类器模块、本体关系约束模块。如图2所示。特征工程提取模块包括词向量表示层、卷积层和分片最大池化层;分类器模块包括注意力层、Softmax分类器。本章将详细介绍这部分内容。
2.1 特征工程提取模块
2.1.1 词向量
本文使用词嵌入和位置嵌入[17]构建词向量。词嵌入是将文本中提到的每个词映射到低维向量的表示方法。本文通过pubmed检索接口获取了截至2019年6月的所有文献的摘要作为训练样本,采用了Mikolov等人[18]提出的word2vec中的skip-gram模型训练单词的语义向量。
关系抽取最后得到的结果通常形式化描述为三元组<头实体,关系,尾实体>,且头尾实体通常不同,因此本文只考虑句子中两个或多个实体的情况,忽略没有实体或只有一个实体的情况。
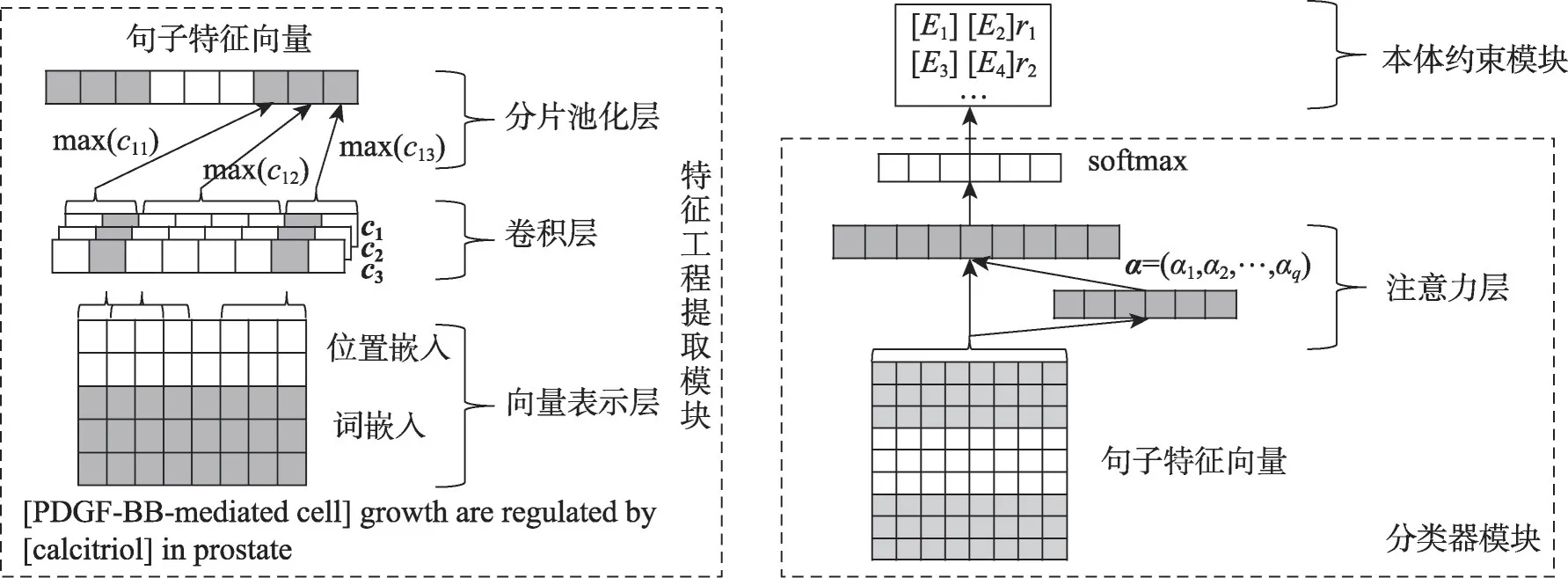
Fig.2 APCNNs+OR model图2 APCNNs+OR模型
当一个句子含两个实体时,令s作为一个输入句子,可以把句子分为5个部分s=(ql,e1,qm,e2,qr),其中e1代表头实体,e2代表尾实体,ql代表e1左边的子句,qm代表e1、e2中间的子句,qr代表e2右边的子句,本文主要针对(e1,qm,e2)中的单词进行位置嵌入。当一个句子含3个实体时,可以把句子分为7个部分s=(q1,e1,q2,e2,q3,e3,q4),本文将实体两两组合成实体对,进行关系抽取。本例中先将e1和e3作为头尾实体,则(q2,e2,q3)为qm,使用其他实体对时同理。实体对为4个或以上时以此类推。
位置特征指的是从当前单词到实体e1和实体e2的相对距离的组合,每个单词都有两个相对距离,图3展示了相对距离的示例,从“regulated”到头实体和尾实体的相对距离分别是3和-2。先随机化初始两个位置矩阵PFi(i=1,2),分别代表每个单词相对于e1和e2的距离,再把相对距离转换为向量放入矩阵中。
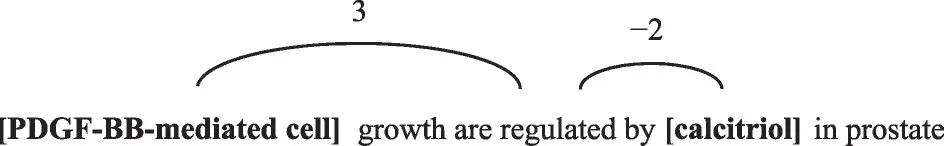
Fig.3 Position embedding example图3 位置嵌入示例
本文将语义向量和位置向量串接起来作为网络的输入。假设词嵌入向量的大小是kw,位置向量的大小是kd,则最终的单词向量k的大小是k=kw+2kd。
2.1.2 卷积层
本文将输入句子设为S={s1,s2,…,sn},sn为该句中第n个单词的词向量,文本句子矩阵S∈Rn×k作为卷积神经网络的输入,其中k是词向量维数大小。使用si:j代表句子中第i个单词到第j个单词的序列。这样的输入无需复杂的预训练处理,降低了预处理可能导致的错误。
将矩阵S进行卷积操作,提取文本的局部特征,其中卷积核矩阵为W∈Rw×k,利用该卷积核滑动窗口在句子S上提取局部特征,得到另一个向量c∈Rn-w+1,为了得到更多种类的局部特征,实验使用了多通道的过滤器,最终得到结果向量C=[c1,c2,…,cn-w+1]T。
2.1.3 分片最大池化层
在神经网络训练中,通常使用最大池化的运算来提取特征矩阵中最明显的值。但是这种方法提取到的关系抽取特征粒度过大,并且无法有效地获得头尾实体及中间关系词的结构信息,因此本文采用了分片最大池化的方法。
分片最大池化就是将一个句子示例根据头尾实体的位置分成三个部分ci={ci,1,ci,2,ci,3},对每一个卷积核得到的向量进行最大池化得到pi={pi,1,pi,2,pi,3},再将所有的向量串接得到输出向量p。
2.2 分类器模块
2.2.1 注意力机制改进
关系抽取任务是一个多实例学习任务,含有标注实体对的句子可能不是在描述训练标签中的关系,这是远程监督假设带来的噪声,因此在含有相同实体对的句子中要做好区分,在实际描述标注关系的句子中进行学习。
注意力机制是为了在学习中给予合理的关系实例较大的权重,可以减少噪声数据对模型的影响。首先将包含相同实体对的句子分为一个数据袋B,每个数据袋中包含q个句子。Liu等人[19]提出在基于数据特征融合的模型中,如果特征向量的维数相同,则可以将这些特征直接拼接。本文引入了Luong-Attention注意力机制公式[20]计算权重:
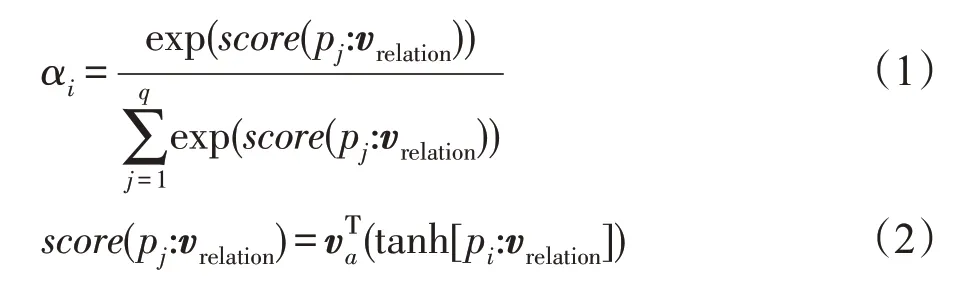
其中,[x1:x2]代表x1和x2的串接,p是分片池化后得到的特征向量,vrelation是注意力机制中当前句子的隐藏状态,也是该句的关系向量,1 ≤i≤q,va是中间矩阵,α=[α1,α2,…,αq]是一个数据袋中所有实例句子的权重,整个数据袋的特征可以用如下公式计算:

现有方法计算vrelation借鉴了词向量的运算思想,如v("king")-v("queen")=v("man")-v("woman")。选择句子中头尾实体的向量差vrelation=v(e1)-v(e2)(APCNNs)。该算法在实体间隔较长的句子中效果较好,但在一些间隔较短的句子中,词向量运算产生的误差会比使用描述关系部分的向量运算大。
为了更好地使用关系词来描述实体间隔较短句子的vrelation隐藏状态,本文提出一种新的计算方法——关系词向量加和(attention piecewise convolutional neural networks sum,APCNNs(s)),vrelation=∑v(qm),其中qm为e1、e2之间的单词。该计算方法认为句子中关系总是出现在两实体之间,因此使用了实体间词语向量的加和获得vrelation的向量,在词语较少的句子中可以更好地使用每一个关系相关单词的特征,如“IS_A”关系在句子通常表达为“is a”或“is the”,而v(is)+v(a)和v(is)+v(the)的向量相似度较高,因此可以使这样的特征获得更高的权重值,从而更准确地区分一个数据袋中真正描述关系的语句。
2.2.2 softmax层
本文加入softmax分类器计算每个合理关系的信任值:

式中,o是输出,W是偏移值,令θ=(E,PF1,PF2,Wα,Ws)代表上述所有的参数,B代表一个数据袋,则该袋实体对是第i个本体关系的条件概率为:

本文利用了Dropout[21]的方法,在每次计算中随机忽略隐藏层中一定比例的神经元,这样可以避免隐藏层中各个神经元之间的相互作用,降低过拟合现象,提高模型的泛化能力。
2.3 本体约束层
本体提供了丰富的领域知识,包括实体的分层,以及最顶层实体间存在的关系。而现有模型没有利用这一部分信息,造成了抽取到的一些关系不符合常识。因此为提高模型最终抽取关系的精准率,使最终抽取的关系均符合该领域的基本知识,本文提出了本体约束层。
本文利用了本体提供的层级及各层级之间的关系,将其视为一个约束R:令T=(E1,E2,…,En),T为本体中的概念树,En为概念集合,如式(6)所示:

如果被抽取语句中的实体e1、e2满足e1∈E1,e2∈E2,代表实体集E1、E2的关系集合,若,则在softmax层后保留该关系,否则将其信任度置0。
下面通过一个具体实例说明本体在远程监督关系抽取模型中的作用。以GoldStandard数据集为例,当识别句子“CONCLUSIONS:Human EPCs express functional PAR-1.”时,头尾实体为“Stem cells#Receptor,PAR-1(干细胞#受体PAR-1)”,关系抽取模型得到的候选关系中,“PRODUCES”和“CAUSES”分数较高,二者含义也较为相近,但本体给出了实体层级“[stem cells]IS_A [Cell]”“[Receptor]”“[Receptor,PAR-1]IS_A[Receptor]”,在实体对“Cell#Receptor”中存在关系“PRODUCES”而不存在“CAUSES”,因此模型在最后预测时应当排除候选项“CAUSES”。
2.4 模型损失函数
APCNNs(s)+OR模型采用交叉熵函数作为损失函数,假设每个实体对标注的关系为ri,模型抽取得到的关系为Bi,实体对总数为N,损失函数如式(7)所示:

其中,θ为模型参数。训练阶段采用随机梯度下降的方法,每次迭代随机选择一小批数据集进行训练,选择Adam优化算法最小化损失函数。
3 实验结果与分析
3.1 实验数据与评价标准
关系抽取的训练语料应包含文本原句,头实体和尾实体的类型及在文中出现的位置,句中包含的关系名,本文选择了SemMed[22]中的数据作为训练语料库。SemMed数据库是从所有pubmed文献中提取的语义关系数据库,该数据库以“主语-谓语-宾语”的三元组形式存储数据,符合训练集的要求。本文选用的数据库版本为semmedVER31_R(文献收录截止到2019年6月30日),为保证方法的时效性,选择了数据库最后122 167个实例作为训练语料,68 011个实例作为测试语料。其中关系来源于UMLS关系语义网络,包含54种关系头尾实体,其来源于UMLS Metathesaurus[23]。
为了测试模型对句子中最主要关系的抽取结果,本文还选取了SemRep GoldStandard[24]数据集作为测试语料,该数据集的构建目的是为了验证SemRep方法抽取实体和关系的准确性。GoldStandard是一个金标准的注释研究,它包含从MEDLINE摘要中随机选择的500个句子,并从中人工提取了1 371个主要的关系预测,其实体和关系也遵循UMLs的索引。
本文采用精准率(precision,P)、召回率(recall,R)、F值来评价模型性能,三者的计算公式为:

3.2 参数设置
本文检索了PubMed中截至2019年6月的全部生物医学文献的摘要,使用python中gensim库的word2vec包训练词向量,后进行归一化,设置训练参数如表1所示,其余数值为默认。
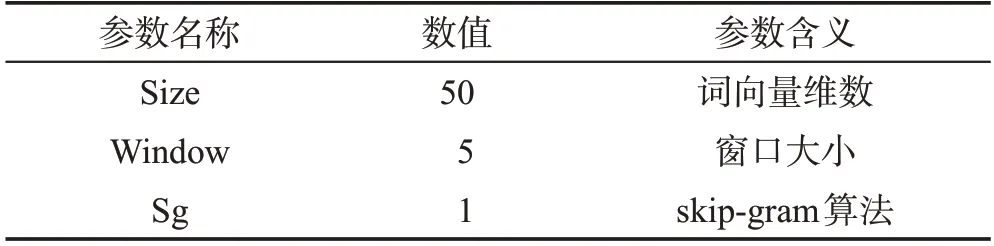
Table 1 Word embedding vector training parameters表1 词嵌入向量训练参数
训练APCNNs模型的超参数如表2所示,其中词嵌入向量维数为50,位置嵌入向量维数为5,词向量总位数k=kw+2kd=60。

Table 2 APCNNs parameters表2 APCNNs参数
3.3 实验结果
3.3.1 比较系统
本文提出的模型如下:
(1)APCNNs(s):使用卷积神经网络和分片最大池化提取特征向量,加入本文改进的注意力机制,使用关系词加和作为注意力机制隐藏层。
(2)APCNNs+OR(attention piecewise convolutional neural networks with ontology restriction):使用卷积神经网络和分片最大池化提取特征向量,加入句子级注意力机制,加入了实体信息,最后加入本文提出的本体约束层。
(3)APCNNs(s)+OR:使用卷积神经网络和分片最大池化提取特征向量,加入本文改进的注意力机制和本文提出的本体约束层。
为了验证本文提出的关系抽取模型APCNNs(s)+OR的性能,与以下现有关系抽取模型进行比较:
(1)PCNN(piecewise convolutional neural network)[12]:分片最大池化的卷积神经网络,引入了多示例学习,但会浪费数据袋中的句子信息。
(2)APCNNs[13]:在PCNN基础上引入句子级注意力机制的方法,加入了实体的信息,但注意力机制中关系隐藏状态向量计算不准确。
(3)RNN+Attention[10]:循环神经网络引入注意力机制的方法,该方法有效地利用了顺序信息,但没有考虑句子中后面单词对前面单词的影响。
(4)biRNN+Attention[10],即双向循环神经网络引入注意力机制的方法,利用了句子双向的顺序信息,但易出现梯度消失和梯度爆炸的问题。
3.3.2 SemMed数据库实验
将本文方法和现有方法在SemMed数据库进行实验,绘制出的PR曲线如图4所示。可以看出:
(1)在P为0.80的前提下,本文提出的APCNNs(s)+OR的R可达0.85,高于APCNNs的0.81,证明本文方法可以增强实体关系抽取的覆盖率。
(2)在R相同的情况下,本文方法APCNNs(s)、APCNNs+OR、APCNNs(s)+OR获得的P也均高于现有的方法APCNNs、PCNN、RNN+Attention、biRNN+Attention,说明本文方法提高了关系抽取的准确性。
(3)由APCNNs和其他引入注意力机制的模型RNN+Attention、biRNN+Attention对比可知,分片最大池化卷积神经网络在该任务上具有更好的特征提取效果。
(4)由APCNNs(s)和APCNNs实验对比可知,使用关系词向量加和作为注意力隐藏层的方法可以获得数据袋中每个句子中更多的监督信息。
(5)由APCNNs+OR和没有加入本体约束层模型APCNNs的对比实验可知,本体约束层可以有效约束抽取出关系的类型,提高模型抽取的准确性。
(6)将关系词向量加和作为注意力隐藏层,和本体约束层同时引入,构成的模型APCNNs(s)+OR具有最好的抽取效果。
图4各条曲线的最大F值点对应的P和R值如表3所示。从表3中可以看出,APCNNs(s)+OR具有最高的F值86.08%,高于APCNNs的82.23%,同时在最高F值的情况下,R值达到84.20%,P值达到88.06%,均高于其他模型。综上所述,APCNNs(s)+OR在SemMed数据库抽取关系实验中具有最好的抽取效果。
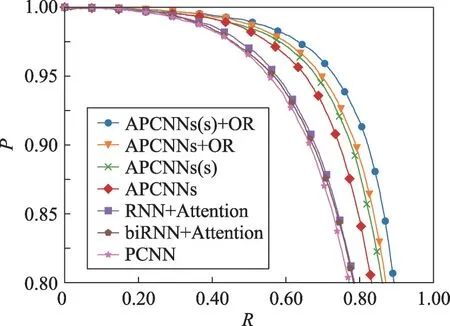
Fig.4 PR curves of each model on SemMed dataset图4 各模型在SemMed数据集的PR曲线
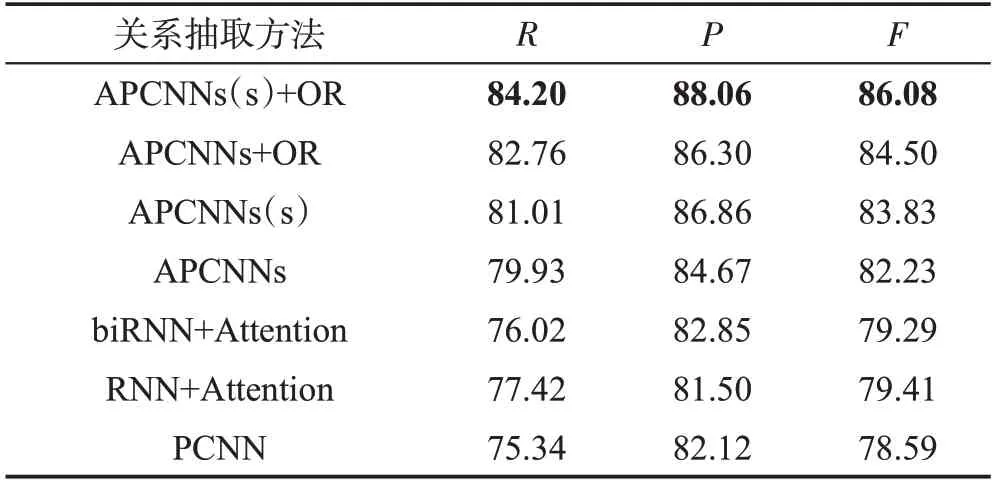
Table 3 Results of each model on SemMed dataset表3 各模型在SemMed数据集的结果 %
3.3.3 GoldStandard数据集实验
GoldStandard数据集中出现的关系如下所示:在句子“The effect of mitomycin C was also evident in the normal size alleles in two cell lines with alleles of 13/13 and 12/69 repeats,where treated cultures showed new longer alleles.”中,人工标注的实体对为“mitomycin#alleles”,关系为“affect”,该关系即为句子的主要关系;而提出的实体对“alleles#cell”,关系“location_of”即为次要关系。
在实验中,本文首先使用了SemRep工具进行了命名实体识别,标注了句子中出现的所有实体。接着对这些实体抽取了关系,最后把结果与GoldStandard中人工标注的数据进行比对,PR曲线如图5所示。
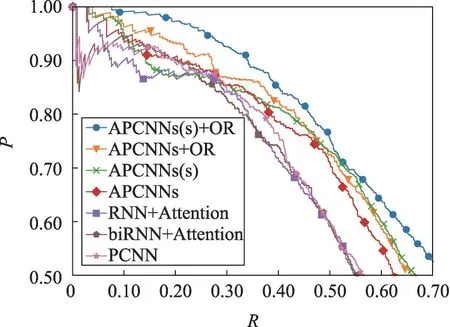
Fig.5 PR curve of each model on GoldStandard dataset图5 各模型在GoldStandard数据集的PR曲线
由实验可知:
(1)本文方法获得的R高于现有方法,在P为0.60的前提下,APCNN(s)+OR的R可达0.63,高于APCNNs的0.57。这说明APCNN(s)+OR可以覆盖到句子中更多的主要关系。
(2)在R相同的情况下,本文方法APCNNs(s)、APCNNs+OR、APCNNs(s)+OR获得的P也均高于现有的方法APCNNs、PCNN、RNN+Attention、biRNN+Attention,说明本文方法提高了句子主要关系抽取的准确性。
(3)由APCNNs+OR和APCNNs模型的对比中可以看出,因为人工标注的实体关系严格符合本体中的关系约束,所以加入了本体约束层可以有效提高模型的准确率。
(4)由APCNNs和其他引入注意力机制的模型RNN+Attention、biRNN+Attention对比可知,分片最大池化卷积神经网络在抽取句子主要关系的任务上也具有更好的特征提取效果。
(5)由APCNNs(s)和包含注意力机制的模型APCNNs对比可知,使用关系词向量加和的注意力机制可以抽取更多的主要关系,这是因为该方法获得了更多句子中主要关系的监督信息,从而有效增加模型的准确率和召回率。
(6)将关系词向量加和注意力隐藏层和本体约束层同时引入模型APCNNs(s)+OR,可以加强对句子中主要关系的抽取效果。
图5的各条曲线的最大F值点对应的P和R值如表4所示。从表4中可以看出,APCNNs(s)+OR具有最高的F值62.07%,高于APCNNs的59.02%。综上所述,APCNNs(s)+OR在GoldStandard数据库抽取句子主要关系的实验中具有最好的抽取效果。
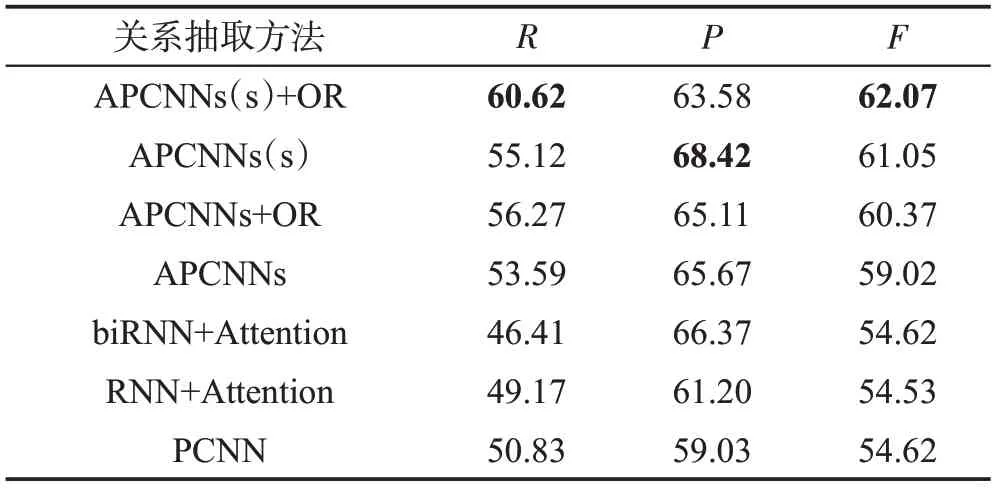
Table 4 Results of each model on GoldStandard dataset表4 各模型在GoldStandard数据集的结果 %
4 结束语
本文针对本体关系抽取现阶段存在的问题,提出了基于注意力机制的远程监督本体关系抽取模型APCNNs(s)+OR,该模型加强了对句子中实体间关系词的学习,并充分利用了本体对关系实体间关系约束的信息,有效地降低了远程监督假设引入的噪声干扰,提升了模型性能。为了验证模型性能,本文基于UMLS医学本体构建了实验数据,使用GoldStandard数据作为验证数据。实验结果表明,相较于其他方法,该方法可以有效降低远程监督假设引入的噪声干扰,以及句子中两实体间的词语信息干扰,抽取关系的性能更好。
