基于Python的爬虫系统设计与实现
2020-09-10吕定辉
摘要:随着互联网技术发展,网络所承载的数据逐渐体现其价值,且网络数据体量日益倍增,对网络数据的利用越来越受到各行各业的重视。该网络爬虫系统以基于Python语言的Scrapy网络爬虫框架技术为基础,综合考虑对反爬机制的应对措施及相关系统优化,满足一定的爬取效率要求,便于数据挖掘等数据研究利用。系统主要实现了实体管道模块、爬虫业务模块、中间件模块、Cookies池模块。过程中涉及到的关键技术主要包括Cookies池服务、反爬虫策略、页面解析、Selenium+ChromeDriver实现模拟访问、MongoDB实现数据持久化存储等。
关键词:爬虫;Scrapy框架;Selenium+ChromeDriver;MongoDB
1.项目研究的背景及意义
随着大数据发展战略的逐步推进,打破信息孤岛,合理整合利用数据信息成为信息融合技术的关键要素[1]。而及时掌握各种消息并对其进行分析和处理具有重大社会意义。随着国家持续推进全国网络安全和信息化建设,互联网信息技术不断创新发展,经济数字化转型已成大势所趋[2]。随着网络效应的不断增强,微博等用户群体的不断扩大,其中某些平台每天都会有过亿的博文发送量及转发量,在网络数据产生和消费中占到很大比例。
网络爬虫技术作为对网络数据提取的基本技术在近些年随网络信息技术发展也不断推陈出新,既是作为搜索引擎的基础结构推动着互联网网页浏览访问的基本进程,又为新时代数据技术提供着多样化的功能性应用场景[3]。Python语言作为当今流行语言之一,以广泛的开源库支持和语言特性与爬虫系统开发有着很高的契合度[4]。
信息数据利用价值越来越重视,诸多门户网站开始并逐步加强对可能的数据访问行为进行判断和分析,对其中的非法访问采取很多有效防范措施,因此在合法的应用范围内相关网络爬虫需要遵循相应的数据访问方式,本文基于Scrapy网络爬虫框架、Python语言等相关技术,并结合目前主流社交平台研究、设计并开发了网络爬虫系统,实现数据的爬取。
2.爬虫的种类及爬取策略
根据所构建的爬虫系统所应用的场景,常将爬虫技术分为三类:通用爬虫、聚焦爬虫、增量式爬虫。通用爬虫通常应用在搜索引擎系统中,聚焦爬虫通常应用于对特定人群提供主题信息服务的系统中,增量式爬虫主要应用于特定网站的数据持续获取系统中。
主要的爬行策略有深度优先爬行策略、广度优先爬行策略、大站优先策略、反链策略、其他爬行策略等。除了以上这些策略,还有一些特定场景下比较适用的爬虫策略如OPIC策略、PartialPageRank策略等[5]。
反爬机制指的是相关门户网站为了防止网站重要数据的泄露或网站异常访问造成不利影响,在网站设计时运用一些策略或技术手段限制用户访问,通过对敏感行为的分析和控制来防止爬虫工具对网站的异常访问。
在爬取过程中需要充分考虑目标网站的反爬机制,做到合理合法的获取数据。
3.系统使用到的关键技术
URL去重可以以下集中策略来实现(1)数据库去重,(2)集合去重,(3)基于集合的Hash优化去重,(4)布隆过滤器。
网页解析分为静态页面解析和动态页面解析。
数据库采用MongoDB。数据存储采用BSON格式来进行以获取更快的速度和更高的安全性。
网站登录机制采用模拟登录方法来进行。
4.需求分析及系统实现
系统总体来看有如下几点需求:(1)克服反爬机制,(2)实现爬虫逻辑,(3)数据存储。系统对硬件资源的需求主要取决于爬虫系统的执行效率要求,依据已有的相关爬虫项目建设情况来看,实现单日万级、十万级、百万级、千万级爬取量所要求硬件条件逐渐提升。开发上充分考虑所需要的时间周期,为在有效期限内完成项目的有效成品,本系统采用增量式开发,在项目初期完成基本业务逻辑实现系统基本功能,而后通过扩展接口不断提高系统执行效率和扩展功能。
本系统的非功能性需求主要体现在运行使用的稳定性和扩展性等方面。例如:执行效率、可靠性、可扩展性等。
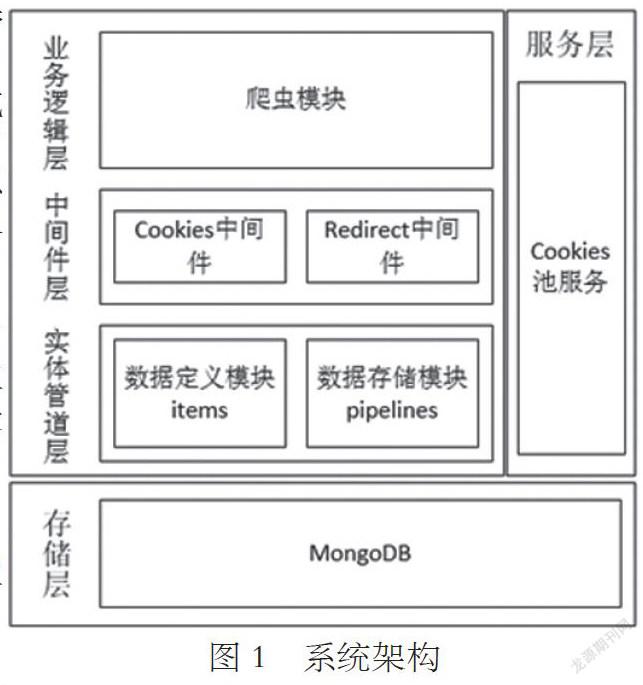
作为单机应用系统开发,项目采用分层架构,结合Scrapy框架技术在具体系统分层上有五个层次,系统架构如图1所示。
在软件程序设计方面所要实现的具体的功能模块主要在中间件层、业务逻辑层与管道层。
对于本系统所爬取的数据,常常是半结构型数据,用传统的关系型数据库存储一方面会对系统执行效率有较大影响,另一方面也不利于数据的后续使用,因此本系统采用基于NoSQL查询语句的MongoDB数据库。
5.总结与展望
本系统以基于Python语言的Scrapy网络爬虫框架为基础,利用Selenium + Chrome模拟登陆、页面解析技术、UA伪装、MongoDB等技术,具体实现了实体管道、爬虫、中间件、服务池等模块,完成了对用户信息、用户关系、用户发表信息等数据的爬取和持久化存储。
系统不足之处:在实现上系统采用了单机架构,数据爬取效率在一定程度上受到了限制。
参考文献:
[1]KEVIN.网络爬虫技术原理[J].计算机与网络,2018,44(10).
[2]高宇,杨小兵.基于聚焦型网络爬虫的影评获取技术[J].中国计量大学学报,2018,29(3).
[3][美]瑞安·米切尔(RyanMitchell).Python网络爬虫权威指南第2版.人民郵电出版社,2019.
[4]杨建.分布式网络爬虫技术及对其安全防御研究[J].网络安全技术与用,2018(04):6-7
[5]汪兵.基于Scrapy框架的分布式爬虫系统设计与实现[D].合肥工业大学,2019.
基金项目:2017年度河南省高等学校青年骨干教师培养计划项目“基于XSLT和STACS的高校云智慧校园建设研究”(项目编号:2017GGJS292)。
作者简介:吕定辉(1980-),男,硕士研究生/讲师,研究方向:计算机网络技术。
