基于判决辅助的异步CDMA信号多伪码序列盲估计算法
2020-09-08邱钊洋李天昀陈香名
邱钊洋,李天昀,陈香名
(信息工程大学信息系统工程学院,河南 郑州 450001)
1 引言
多径异步码分多址(CDMA,code division multiple access)信号是一类直接序列扩频(DSSS,direct sequence spread spectrum)信号,发送端采用不同的伪随机码对发送符号进行调制以实现频谱扩展和信道复用。接收端采用约定的地址码对信号进行匹配接收,从而实现相关解扩和解调。由于伪随机码具有类高斯白噪声特性,同时扩频调制带来的扩频增益有利于发射端实现功率压缩,因此这种通信体制具有天然的抗截获、抗干扰能力,一直以来被视为一种安全可靠的通信机制,并广泛应用于许多重要的保密通信场合[1-4]。近年来,由于伪码序列自相关特性带来的天然的抗多径能力,该类信号也逐渐被应用于多径衰落严重的水下通信场景[5-6]。对此类信号展开非合作条件下盲处理技术的研究,在无线电监测、通信对抗、频谱侦察等领域都具有十分重要的意义。伪码序列估计是扩频信号盲分析技术的核心。对于非合作接收方,由于没有训练序列、信道等先验信息,对接收的多用户混合信号直接进行伪码序列恢复十分困难。多径衰落、低信噪比、各用户可能出现的功率不对称、时延差异等客观条件使这一问题变得更加复杂,更具挑战性。
诸多学者对这一问题展开了深入的研究,许多行之有效的方法被提出以解决DSSS 信号的伪码估计问题。特征值分解方法是一类经典的方法,其通过提取分段自相关矩阵的主特征向量重构伪码波形,在单用户DSSS 信号伪码序列估计中展示出优异的性能[7-8]。基于Hebbian 准则或恒模算法的神经网络方法也是一种获取伪码序列的有效手段,单层BP(back propagation)神经网络收敛后的网络权值对应伪码波形,相比特征值分解方法,复杂度大大降低[9-10]。诸如聚类的方法以及最大似然的方法均得到了一定程度上的关注,但这些方法仅能应对单用户DSSS 信号,难以解决多用户CDMA 信号伪码序列估计问题。同时这些方法在应对多径信道时,往往需要结合m序列自身的特性(如三阶相关特性等),以恢复原始序列,对其他类型的扩频序列则不适用,应用十分受限[11-12]。
Koivisto 等[13]和Nzoza 等[14]尝试将矩阵分解的方法引入多用户伪码序列估计问题,当用户数量较少且功率差异较大时,这种方法可以获得相对较好的性能。但是,当用户数量增多且功率相近时,特征向量将表现为各用户伪码序列的线性组合,交叠的子空间难以分离导致算法失效。盲源分离(BSS,blind source separation)的思想被引入用来分离线性组合的伪码,在信噪比高且用户数量不多时,可实现伪码的有效分离,但当用户数量增加时,难以保持稳定的分离性能[15]。期望最大化(EM,expectation maximum)算法利用了通信信号的有限元(FA,finite element)特性,通过遍历发送符号,选取后验概率较大者作为信息比特的估计,从而迭代实现伪码序列的估计[16]。该方法性能较好,但复杂度较高,当用户数量较大时,难以实时处理,且只能应用于同步CDMA信号。迭代最小二乘投影(ILSP,iterative least square with projection)算法基于最小二乘估计,提供了与EM 算法近乎相同的性能,但复杂度大大降低。然而以上算法均面向同步CDMA 信号模型,不能直接用于异步CDMA 信号伪码估计问题。针对异步CDMA信号,Avitzour[17]采用二倍增广矩阵对信号进行建模,将ILSP 算法进行了拓展,实现了异步体制CDMA信号多伪码迭代估计,是目前较主流的方法。多通道接收下的CDMA 信号伪码估计问题也得到了一定程度的研究[18],其思想主要是采用多天线进行接收,构建张量模型,但这些方法对于单天线接收条件下的CDMA 信号(单通道CDMA)并不适用。此外,以上方法均考虑理想的接收环境,未考虑实际中可能存在的多径信道,因此其在多径环境下的性能有待进一步评估。
总体来说,目前涉及单通道异步CDMA 信号伪码序列盲估计的研究十分单一且缺少一个可对比的性能界。误码率指标虽在一定程度上可用于评估伪码估计精度,但对于盲估计问题存在局限性和下界的不准确性,故研究异步CDMA 信号的伪码序列估计方法及其性能界是十分必要的。本文主要针对多径条件下异步CDMA 信号多伪码估计问题,提出了一种基于判决辅助的多伪码盲估计算法,该算法基于最大似然理论,通过对异步信号进行建模,构造了迭代优化模型并分析了模型中的收敛性和可能存在的局部极值点,给出了避免局部收敛的应对方法,实现了良好的估计性能。将算法推广至多径信道,实现了多径条件下的伪码恢复。同时,本文研究了异步CDMA信号伪码估计问题的Crammer-Rao界(CRB,Crammer-Rao bound),并对比评估了理论界的合理性,从而给出了算法性能的一般参考。最后通过蒙特卡洛仿真实验验证了本文算法的有效性。
2 算法设计
2.1 信号建模
信号模型的优劣直接决定了参数估计的效果。由于异步CDMA 体制中不同用户具有不同时延,其分段信号建模相对复杂。文献[17]采用同相码和反相码同时对信号进行建模并建立对发送序列矩阵的约束,将异步信号转化为同步信号处理。该建模方法通过将信号转化为同步CDMA 信号模型,从而使用ILSP 算法进行估计。本文经过对异步信号进行分析,提出一种新的异步信号建模算法。
假设信号已完成下变频及载波同步且各用户时延已预先准确估计,基带异步CDMA 信号可表示为
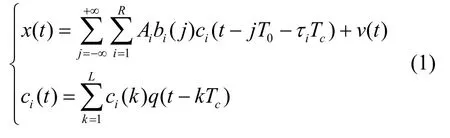
其中,T0和Tc分别为扩频波形周期和码片周期;A i、bi(j)、ci(t)、τiT c分别为第i个用户的信号幅度、第j个符号周期的发送比特(bi(j) ∈{± 1})及该用户的扩频伪码波形和时延;q(t)为信道滤波器,实际通信场景下多为升余弦滚降滤波器;v(t)为高斯白噪声;L为伪码序列周期(T0=LTc);R为用户个数。
对信号进行定时抽样后,长度为M个伪码周期的异步CDMA 信号可表示为
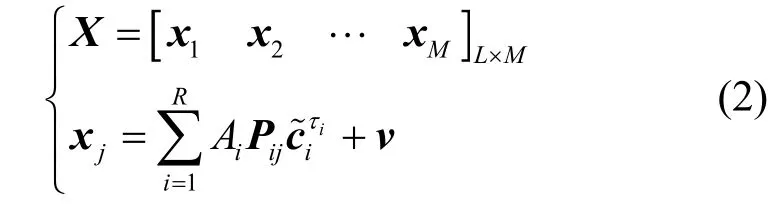
其中,X为以伪码周期长度分段后的观测矩阵;x j为其第j个分段;为第i个用户的伪码序列ci向右循环移位τi后对应的伪码序列向量;P ij为对角矩阵,对应第i个用户在第j个分段时间窗内的信息波形,可表示为
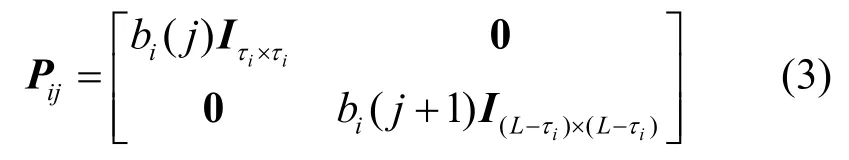
其中,Iτi×τi表示维度为τ i×τi的单位阵。
本文研究的主要问题可以概括为仅已知观测信号矩阵X,在各用户信号幅度Ai、发送序列bi(j)均未知的条件下估计伪码序列ci。
2.2 基于判决辅助的多伪码序列估计方法
最大似然估计(MLE,maximum likelihood estimation)理论在解决高斯模型下参数估计问题中具有十分重要的意义。MLE 一般给出参数的最小方差无偏估计,估计性能在均方误差的意义上接近理论界,所以被广泛应用于信号检测与估计问题。在此,给出观测矩阵的似然函数为
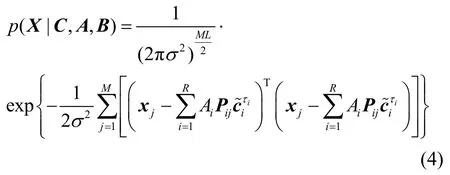
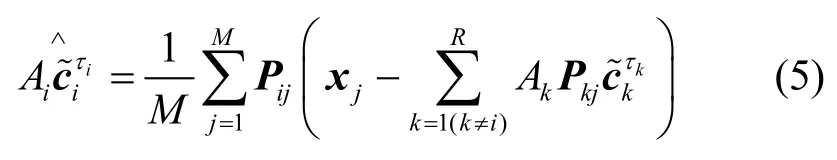

当各用户发送序列被确定以后,再次根据式(5)进行伪码序列估计,依此循环进行,从而实现发送序列与伪码的迭代估计结构。为观测优化模型的收敛性,可计算如式(9)所示的代价函数。
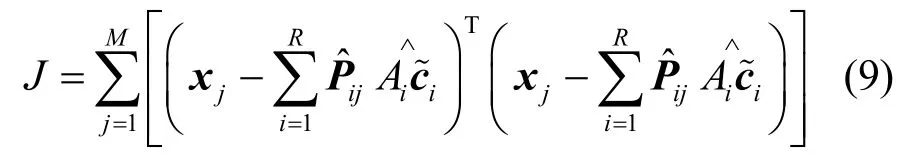
2.3 收敛性分析
随机初始化条件下,多参数优化模型具有数量较多的局部极值点。求导过程虽保证了模型的收敛性,然而,局部极值的存在将严重影响算法性能。实际应用中,为避免局部收敛,可以通过多次随机初始化进而选择代价函数最小的迭代结果作为最终估计。在计算资源允许的条件下,随机初始化的次数越多,全局极值越容易取得,估计的效果也就越好。实际操作中,随机初始化次数的设定一般为经验值,随着待估参数量的增加(如用户数量、伪码序列长度),一般需要增大该值。
在该盲估计问题中,由于各用户发送序列和伪码序列均未知,可以得出模型参数是不可唯一辨识的,具有相位不确定性。当用户时延相近时,又将产生顺序的不确定性。这种现象在随机初始化规模不够大时,表现尤其突出。局部收敛后伪码估计结果如图1(a)所示,可能产生的顺序误差将导致在时延区间内伪码估计值不准确(趋于零),而此时的收敛曲线将表现为图1(b)所示的局部收敛。
图1 所示的局部收敛现象产生的原因可以用图2(a)来描述。根据初始化数值的不同,模型具有不同的收敛路径。不考虑相位因素时,模型参数具有R! 条不同概率的收敛路径(即对应伪码在不同顺序排列下的可能数量)。当时延接近时,收敛结果中将具有较大概率的伪码顺序互换,相应地有较大概率的局部收敛性。为了避免这种局部收敛在伪码时延点附近带来的估计误差,可采用收敛后遍历调整顺序的方式,将局部收敛调整为全局收敛。经过遍历顺序调整,当估计所得伪码序列的顺序调整至与预设顺序相同时,将迭代产生最优的伪码序列估计与发送序列估计,同时对应于最小的代价函数取值。一般而言,由于MAI 的存在,CDMA 系统用户规模有限,因此交换次序寻优的复杂度完全可以承受。图2(b)展示了遍历调整后收敛曲线变化情况,可见,遍历调整可有效将优化结果调整至最优收敛点,实现更精确的伪码估计。
2.4 多径信道下信道与伪码序列联合估计
前文考虑了理想的信道情况,实际通信环境中,由于建筑物的遮挡反射等,电磁波的传播可能存在多径效应。多径条件下伪码周期分段信号可建模为
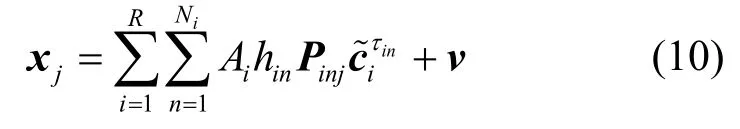
其中,Ni为第i个用户的多径条数,hin为第i个用户第n条径的信道抽头系数,Pinj为第i个用户第n条径下第j各伪码周期内传输的信息矩阵。依第i个用户主径同步分段的形式可由式(11)给出。
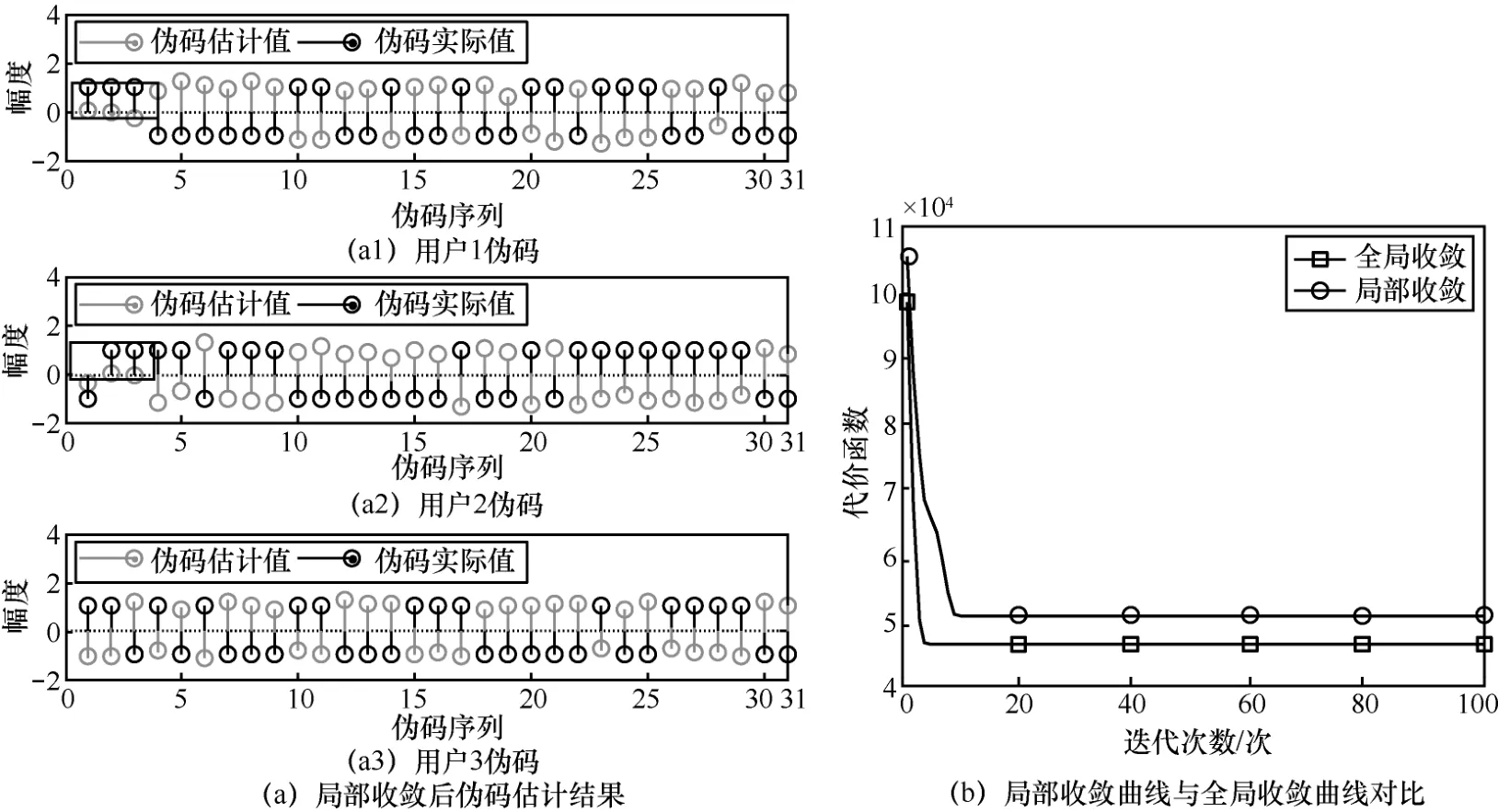
图1 算法局部收敛示意
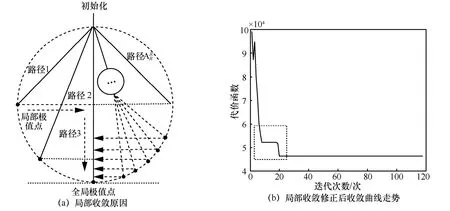
图2 局部收敛修正原理及结果示意
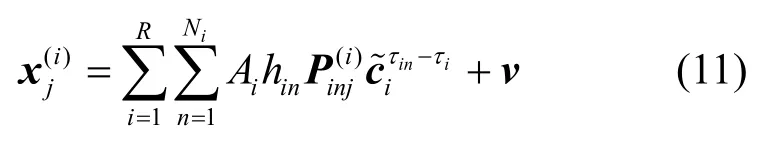
假设主径时延已获得准确估计,模型收敛情况下,考虑式(5)及同步迭代与异步迭代的等价性,估计所得伪码波形具有如下形式
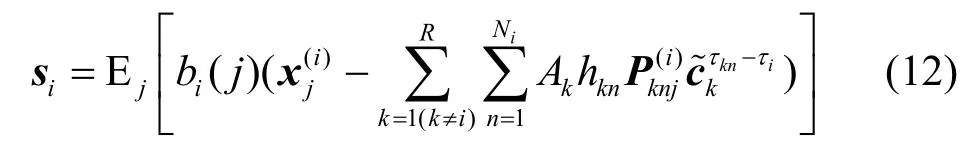
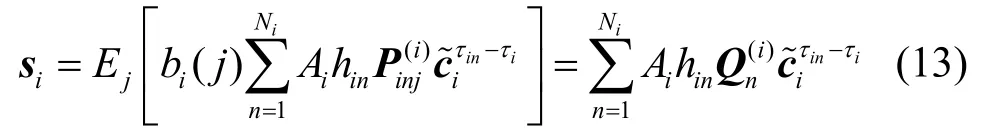
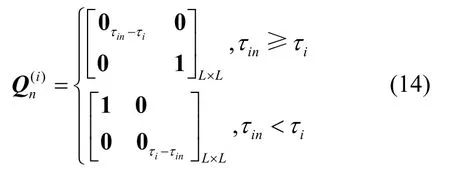
其中,0τin−τi表示维度为(τin−τi) ×(τin−τi)的对角方阵,其对角线元素为0。式(13)表明,收敛后的伪码波形向量对应于当前用户伪码序列的移位叠加,其可表示为一个截断的卷积模型,等价于式(15)所示的矩阵形式
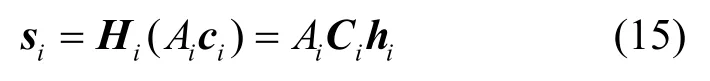
其中,hi为第i用户传播中的信道系数向量,其中间抽头对应主径时延,即τi,hi长度为Ni。不失一般性,假设信道长度Ni为奇数(若实际中为偶数,则在hi中按照主径所在位置将对称时延位置系数补0),N i<L且有。式(15)中的信道矩阵与伪码矩阵可表示为


多径信道的存在将严重影响伪码的估计结果,在信道未知的条件下,式(15)转化为一个多径条件下的信号检测问题,可采用盲信道估计或盲均衡的思路加以解决。由于伪码序列同样具有FA 特性(序列元素取值为 ±1),因此迭代思想同样适合于此问题以实现伪码恢复。类似于2.2 节中的伪码估计思想,此处的多径伪码模型可采用式(18)~式(20)对伪码和信道进行迭代联合估计
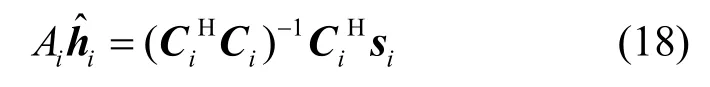
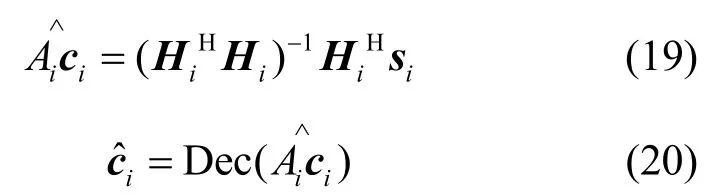
其中,Dec(⋅)表示硬判决,可观测式(21)所示的代价函数的收敛过程
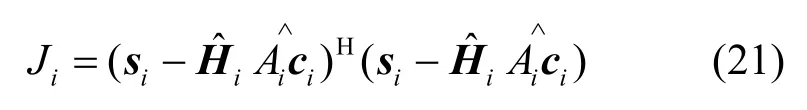
同样地,作为多参数优化模型,局部极值难以避免,可采用大量随机初始化(包含原始si)以增加全局收敛概率。实际上,为加速收敛过程并减少局部极值,可采用si直接判决作为的初始化值,在多径不十分严重的情况下,一般仅需极少的迭代次数即可实现全局收敛。
以上讨论了多源CDMA 盲接收情况,即各用户分量来自不同的发射源,对应不同的传输信道,如小站或用户端发送的信号。而实际通信过程中还存在着大量单源的CDMA 系统,这种信号由单一发射源发射,各用户分量经历相同的传输信道,如通信主站发射的信号。作为第三方接收,各用户分量经历相同的传输信道,此时,理论上可对信道做出更精确的估计,相应地也可实现更好的伪码估计。单源CDMA系统经过判决辅助伪码波形估计流程后,其收敛的伪码波形与信道具有如式(22)所示关系。

结合式(19)、式(20)、式(24)和式(25),即可实现伪码与信道抽头的联合估计。
2.5 算法流程
本文算法流程如图3 所示。具体步骤介绍如下。
步骤1估计接收信号的载波、码片间隔Tc、伪码周期T0和各用户时延等参数。
步骤2对接收信号进行定时同步抽取和载波同步,并将同步后信号按周期分段排列为XL×M。
步骤 3随机初始化N个伪码矩阵Ci(i=1,2,…,N)作为种子矩阵,根据式(7)并行估计各初始化种子对应的发送信息序列bi(j)(i=1,2,…,R,j=1,2,…,M+1)。
步骤4根据式(5)更新,计算代价函数,重复估计发送序列bi(j)(i=1,2,…,R,j=1,2,…,M+1)直至收敛。选择最小代价函数对应的估计结果,其代价函数、信息矩阵和伪码矩阵分别记为Jc、Bc和CAc。
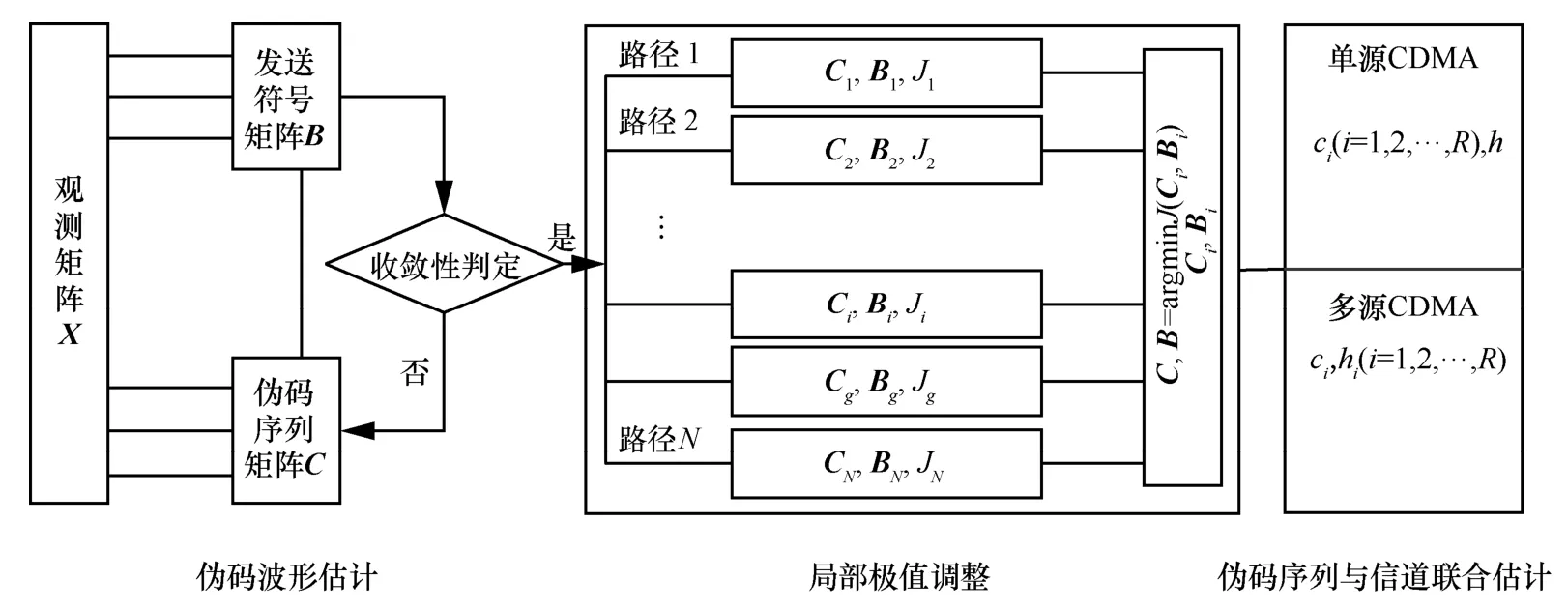
图3 基于判决辅助的异步CDMA 多伪码序列估计流程
步骤5交换CAc中向量顺序,遍历R! 种排序,重复步骤4 直至收敛。
步骤6选取最小代价函数对应的信息码估计值和伪码波形估计值作为最终估计,伪码序列估计结果可由进行功率归一化得到。
步骤7将估计所得的伪码波形进行反向(向左)循环移位τi后得到多径伪码波形sk,根据信号来源选取对应的信道与伪码联合估计方法。若信号为多源发射CDMA 信号,采用式(18)~式(20)迭代估计各用户分量信道与伪码序列;若信号为单源CDMA 信号,采用式(19)、式(20)、式(24)和式(25)进行信道与伪码迭代联合估计,即得各用户伪码序列。
3 伪码序列盲估计理论界
为评价本文算法性能,下文将继续讨论非合作接收条件下异步CDMA 信号多伪码盲估计的性能界。CRB 在参数估计问题中具有重要的意义,其可以给出一个非随机参数向量的无偏估计在均方误差意义上的理论下界,常被用于评估参数估计器的性能优劣。本节将对异步CDMA 模型下伪码估计CRB 展开研究。
确定性参数模型中,盲估计问题实质上是伪码序列与信息码的联合估计。为简化推导过程,将幅度参数与发送序列联合考虑,即B A=AB。待估计参数向量表示为,其中表示循环移位后的伪码序列矩阵,vector(·) 表示将矩阵按列展开为向量。在常见的参数估计模型下,Fisher 信息矩阵(FIM,Fisher information matrix)的逆矩阵将给出参数估计的CRB,其内部元素由似然函数对参数向量的二阶偏导构成。在异步CDMA 信号模型中,由发送序列和伪码序列的时序特性可得,其FIM 应具有如图4所示的分块形式。
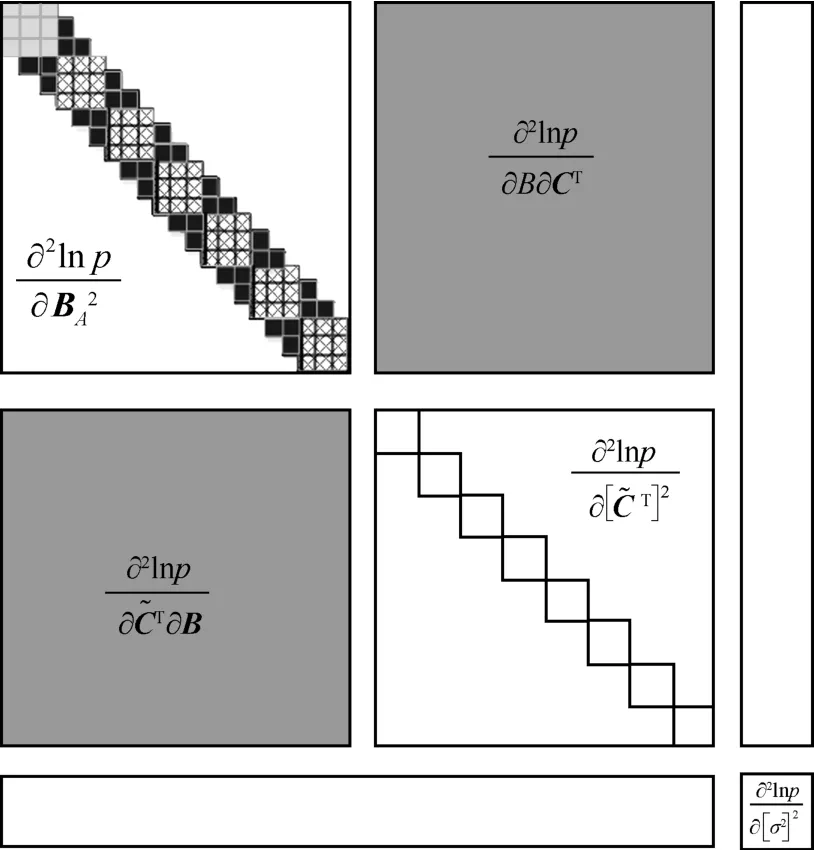
图4 异步CDMA 伪码盲估计问题FIM 形式(以R=3 为例)
图4 中,空白区域对应0 值,各分块表示的数学表达式如图所示。首先考虑,其中对应R个用户的第1 发送比特二阶偏导的子FIM 可以通过式(26)计算。
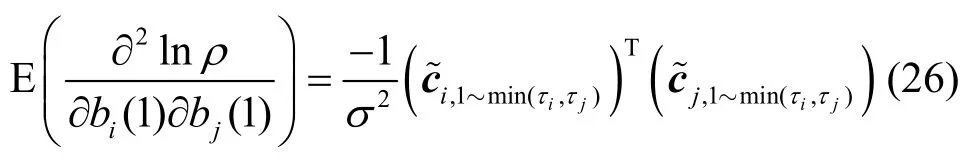

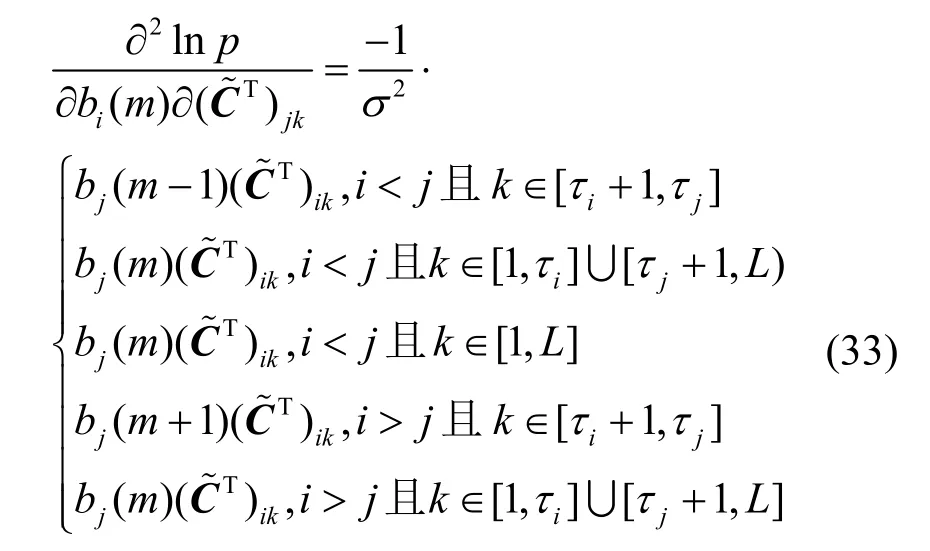
至此,FIM 矩阵被唯一确定。然而,经过上文分析,伪码盲估计问题中由于未知的幅度、相位等因素,实质上不满足可辨识条件。与信道盲估计问题相似,此时的FIM 矩阵将表现为奇异阵。其CRB不能由FIM 矩阵简单求逆得出。文献[20]就信道盲估计问题讨论了约束条件下CRB 的求解。当FIM奇异时,需要提炼约束条件,通过对约束条件求导获得梯度矩阵,并求解梯度矩阵的零空间,从而消除FIM 的奇异性。针对本问题中的伪码,其需要满足的条件包括子序列互相关取值、相位约束等,可由的求解过程得出。令,分别表示子FIM 矩阵JB中浅灰色、黑色、灰色区域的某一元素。则对伪码的约束可以表示为
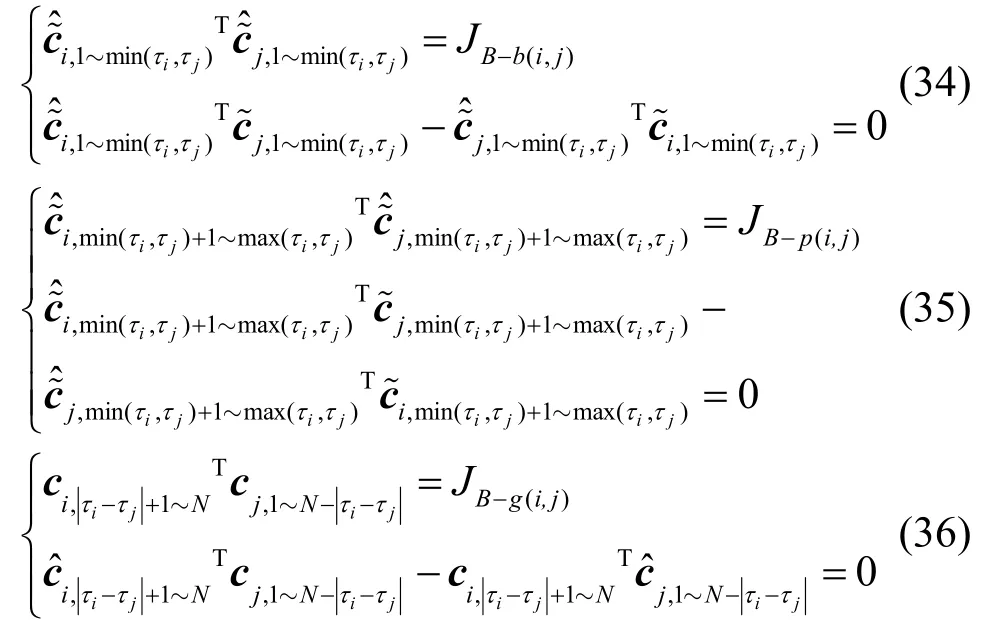
其中,ci,j~k表示序列ci的第j到第k比特子序列。将以上约束条件对θ求导,可以得到梯度矩阵F,H为F的零空间。此处用归一化的均方误差(NMSE,normalized mean square error)来表示估计误差,所求的CRB 可表示为
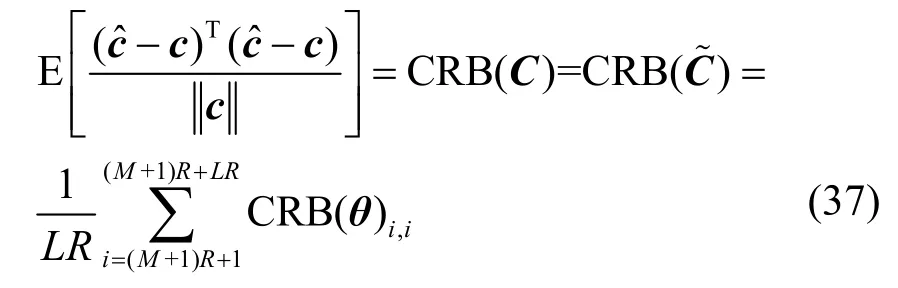
4 仿真实验
4.1 CRB 理论界仿真分析
由第3 节推导过程可知,与伪码盲估计CRB有关的因素主要包括伪码序列长度、正交度、用户功率、信噪比、数据量等,在此首先分析正交度和用户功率对CRB 的影响,信噪比和数据量的影响将在4.2 节中予以讨论。需要指出的是,本文定义信噪比均为所有信号分量之和的功率与噪声功率的比值。
为观测方便,选取2 用户CDMA 系统,数据量为50 个伪码周期,信噪比区间为[−10,10]dB。分别考察伪码长度、相关度及各用户功率比对CRB 的影响。其中,考察不同伪码相关度下CRB随信噪比变化情况时,固定了不同用户功率比为1:1,扩频伪码序列长度为31,结果如图5(a)所示。考察不同用户功率比下CRB 随信噪比变化情况时,固定伪码相关系数为0.16,扩频伪码序列长度为31,结果如图5(b)所示。考察CRB 随伪码长度的变化情况时,固定信噪比为−5 dB,伪码相关系数为0.16,不同用户功率比为1:1,结果如图5(c)所示。
由图5(a)可以看出,与正向多用户检测性能受伪码相关度影响较大的结论不同,伪码盲估计CRB与伪码之间的相关度无关,说明无论CDMA 系统采用何种序列,均不影响非合作方估计伪码所能达到的精度。图5(b)说明用户功率比是影响伪码估计的一个显著因素,当用户功率比接近1,即用户等功率时,可达到的估计精度最高,随着功率差异逐渐的增大,精度将加速恶化。图5(c)说明伪码长度也是影响估计方差的一个客观因素,当伪码长度增加时,估计CRB 会逐渐上升,这主要是伪码序列的范数约束导致。当序列较短时,范数约束的影响较大,可提高NMSE 性能;反之,则范数约束对估计序列的影响减弱,对NMSE 性能提升的贡献降低,因此CRB 上升。
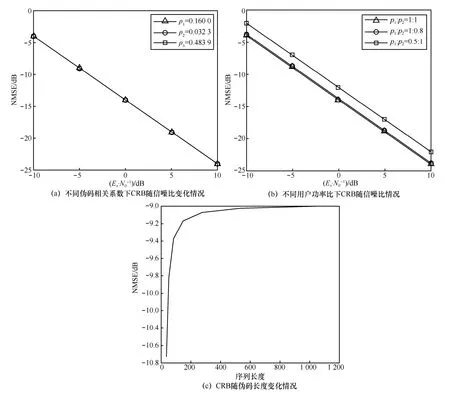
图5 异步CDMA 系统伪码盲估计CRB 影响因素分析
4.2 基于判决辅助的多径异步CDMA 信号多伪码盲估计算法性能
4.2.1 多径信道、信噪比和数据量对算法性能的影响
为了验证算法性能,选取了单源3 用户异步CDMA 系统,信号参数如表1 所示,其中伪码序列为截断m序列,长度为31,每次实验中各用户时延随机产生,进行了有、无多径信道2 种情况下的对照测试,其中仿真选取的多径信道抽头系数为h=[0.2 1 −0.3],算法中初始化种子数量N取10。选取文献[17]所提ILSP 算法及CRB 进行对比。同时给出了与ILSP 算法及合作解调下的误码率对比,共进行10 000 次蒙特卡洛仿真实验,结果如图6和图7 所示。
从图6(a)可以看出,本文算法可大幅改善估计性能,在理想无多径信道下,相比ILSP 算法,具有约5 dB 的性能提升,在−2 dB 信噪比以上性能基本接近理论限,证明了本文算法的有效性,在实验采用的多径信道下,本文算法性能将发生一定退化。图6(b)展示了算法的误码率性能,本文算法相比ILSP 算法有明显优势。值得指出的是,在多径信道下,本文算法的信息码无符号性能退化较小,这是由于本文算法在多径信道下对最佳的相关伪码波形估计性能较好。
如图7(a)所示,在无多径、信噪比为0 的条件下,本文算法性能随着数据量的增加持续提升,在20个伪码周期时就接近CRB且显著优于对比算法,说明本文算法对数据量不敏感,具有较好的符号稳健性。在多径信道下,本文算法性能发生一定退化,但仍然优于无多径的ILSP 算法,说明了本文算法的优势。图7(b)展示了与图6(b)相似的结果,在数据量大于或等于50 个伪码周期时,多径信道对本文算法的信息码误码率影响较小。以上结论说明,影响本文算法伪码估计性能的主要因素在于盲信道估计(盲均衡)环节。一般而言,影响盲信道估计性能的包络信号长度与信噪比等因素,在本文采用的短伪码长度下(L=31),如何有效恢复序列和信道,这依然是该领域面临的难点问题之一。

表1 实验信号参数
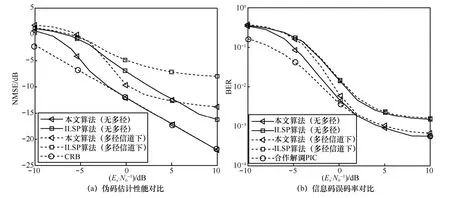
图6 算法性能与信噪比的关系(M=50)
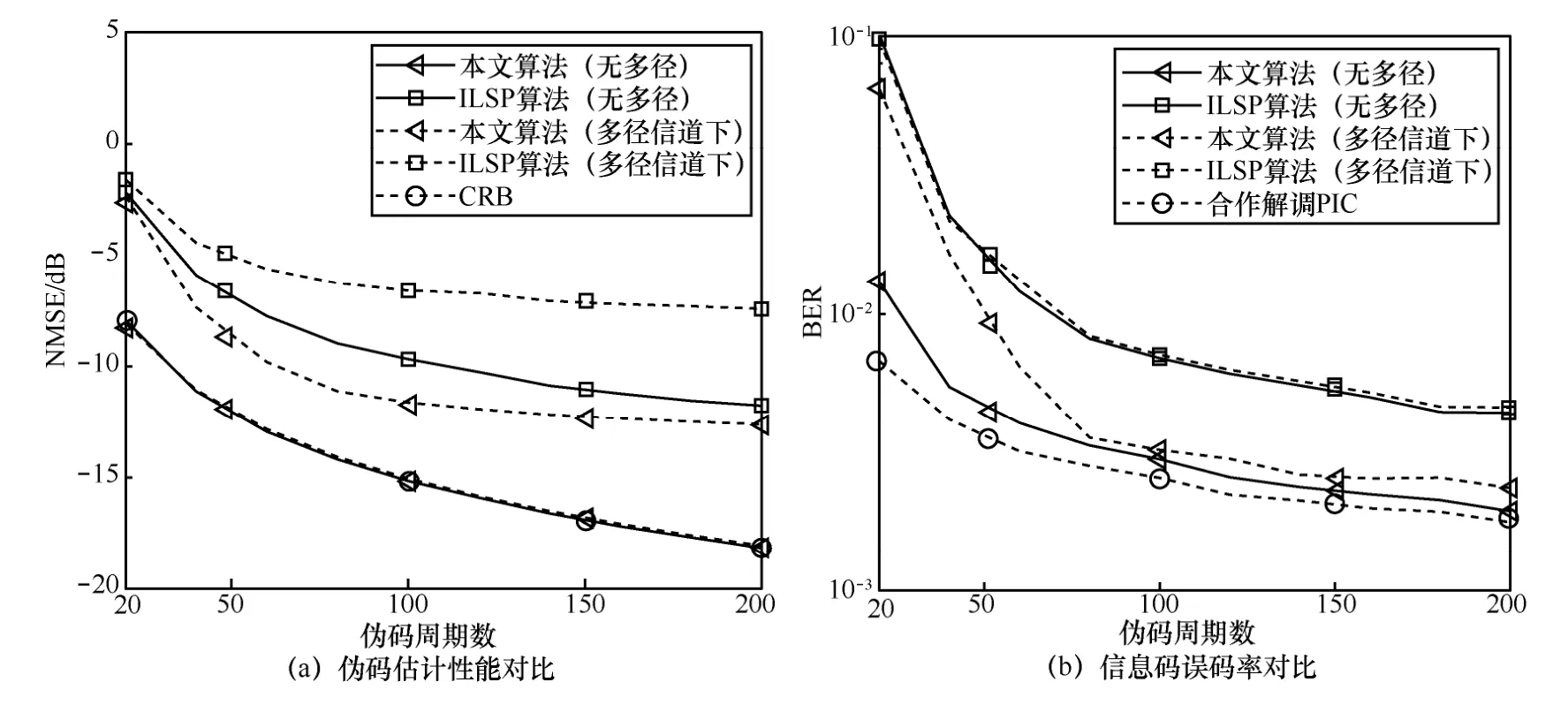
图7 算法性能与数据量的关系((Es⋅N0−1)=0)
4.2.2 伪码正交度对算法性能的影响
本文采用的判决辅助思想在多用户检测步骤中可能引入MAI,因此需要考察伪码正交度对算法性能的影响。实验选取2 用户系统,伪码序列长度为31,正交度采用两伪码相关系数衡量指标(相关系数越小,正交度越好),对比了本文算法在2 种较极端情况下的伪码估计性能及误码率,共进行10 000 次蒙特卡洛仿真实验,结果如图8 所示。
从图8 中可以看出,伪码正交度对本文算法性能的影响十分有限。这主要是由于异步系统中随机的时延使各用户发送符号错位,从而降低了伪码之间整体相关性对单一符号的影响。对于伪码估计,由于基于判决辅助思想,因此异步系统的这种优势相应地体现在本文伪码恢复方法中。因此,本文算法对伪码序列之间的正交性具有较高的容忍度。
4.2.3 不同用户数量对算法性能的影响
为衡量本文算法在用户数量增加时的有效性,设计了2 用户和5 用户情况下性能对比实验,数据量为50 个伪码周期,每次实验中实验信号各用户具有相等功率和随机时延,共进行10 000 次蒙特卡洛仿真实验。图9 展示了用户数量对算法性能的影响。
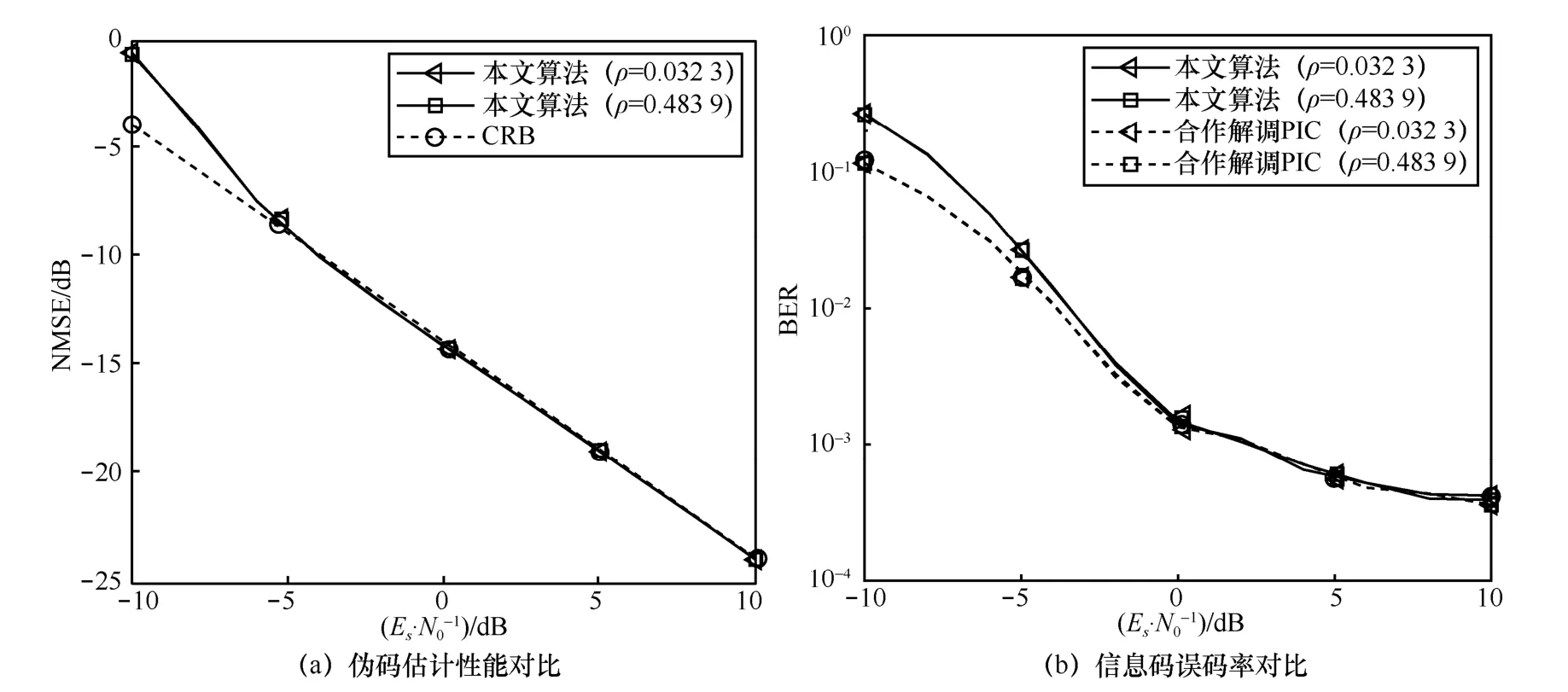
图8 伪码正交度对算法性能的影响(M=50)
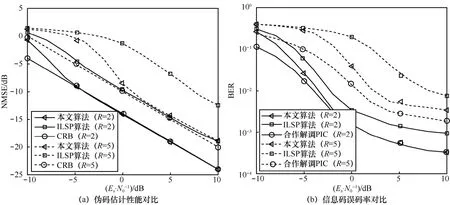
图9 用户数量对算法性能的影响(M=50)
从图9(a)中可以看出,当用户数量增多时,本文算法在较高信噪比下依然能保持稳定良好的性能,接近于理论限。但信噪比较低时,伪码估计性能下降。这与本文信噪比的定义有关,如前文所述,本文信噪比定义为多用户分量功率之和与噪声功率的比值,相同信噪比下,当用户数量增加时,各用户分量平均信噪比将相应降低。以实验采用的2 用户和5 用户系统为例,相同信噪比条件下,平均意义上5 用户系统的各用户分量信噪比将比2 用户系统低左右,因此,从这一意义上而言,实验中5 用户系统在低信噪比下的性能下降是合理的。相比而言,本文算法在相等条件下对比目前常用的ILSP 算法仍然具有较大优势,尤其是较高信噪比条件下估计性能较好,说明了系统负载较大时本文算法的有效性。图9(b)中5 用户情况下本文算法误码率略高于合作解调误码率,优于对比算法,也验证了本文算法的优势。
4.3 复杂度分析
本文算法中单次迭代的计算复杂度主要由判决辅助部分和伪码估计部分构成,算法的平均复杂度可以表示为O(R2ML2+R2M L2),而ILSP 算法单次迭代的复杂度主要由两次矩阵求逆构成,可以表示为。经过简单推导可证得(2RL)3+(2RM)3≥R2ML2+R2M L2,当且仅当R=1且M=L时等号成立。可见,在多用户伪码估计问题中,本文算法的计算复杂度低于ILSP 算法,且为多项式复杂度,可实现实时估计。
5 结束语
本文针对非合作接收条件下异步CDMA 信号多伪码序列盲估计问题,通过对异步信号进行建模,结合最大似然估计理论,提出了一种基于判决辅助的多伪码盲估计算法,实现了低复杂度、高精度的伪码盲估计,并且给出了多径信道下信号伪码估计算法,扩展了算法的适用性。同时,推导了该盲估计问题的理论界,并分析了可能影响估计性能的因素。仿真实验表明,本文算法优于现有算法,接近理论界,说明了算法的有效性和实用性。该算法对其他体制CDMA 信号伪码估计问题也有一定参考意义。
