面向SDN的流规则拆分分配算法
2020-09-07闫祎程王兴伟
闫祎程,易 波,王兴伟,黄 敏
1(东北大学 软件学院,沈阳 110169)
2(东北大学 计算机科学与工程学院,沈阳 110169)
3(东北大学 信息科学与工程学院,沈阳 110819)E-mail:wangxw@mail.neu.edu.cn
1 引 言
随着互联网的发展,传统网络这种全分布式的结构开始展露出许多弊端.为了表达所需的高级网络策略,网络运营商通常需要使用低级别且特定的命令来配置每个单独的网络设备[1].为解决传统网络中管理复杂、强耦合等弊端,国内外学者提出了软件定义网络(Software Defined Networking,SDN),并对SDN进行了广泛的研究[2,3].SDN不仅使网络在灵活性和可控性上得到了很大的提升,而且已经成为信息中心网络等新型网络架构的基石[4].OpenFlow作为目前SDN中被最广泛应用的协议,为操作员提供了简单接口,简化了网络管理并提高了鲁棒性[5].OpenFlow协议需要在有限容量的三态内容寻址寄存器(Ternary Content Addressable Memory,TCAM)中安装流规则,但TCAM容量有限的问题,限制了大规模流规则的存储[6].
在网络中实现高级策略(如防火墙策略等)所产生的流规则数量对于TCAM空间来说往往是巨大的.因流规则放置不当而没有完全实现高级策略,导致本该被拒绝的数据包进入网络,有可能造成网络安全问题.因此,如何在SDN交换机上合理利用流规则空间实现高级策略至关重要.
本文在给定的拓扑上放置访问控制列表(Access Control List,ACL)规则以实现防火墙策略,并针对ACL规则拆分分配问题,设计了两种不同的拆分分配算法.流规则拆分分配的关键挑战在于如何将原始规则集拆分为多个语义上等效的子集,以及如何将这些子集分配给TCAM空间有限的SDN交换机[7].本文的主要贡献如下:
1)设计了基于矩形拆分分配算法,在路径上仅放置与之相关的高级策略规则集.
2)设计了基于平均拆分分配算法,在路径上放置全部高级策略规则集.
3)仿真结果表明,与基准机制相比,本文所提出的算法可以明显降低拆分后流规则的数量.
2 相关工作
由于单个交换机没有足够的TCAM空间来存储所有规则,因此,针对如何高效地利用TCAM空间来放置流规则的解决方案主要分为两种[8].一种是流表压缩机制.文献[9]提出了使用通配符规则的流表压缩机制,对流规则按照源地址、目的地址和默认流规则进行压缩.文献[10]中对流条目进行周期性的压缩,并基于匹配频率和匹配概率的隐马尔可夫模型决定保留在流表中的流条目.文献[11]首先根据流表匹配域之间的关系将流表分割为流表子集,然后对每个流表子集进行压缩,从而实现流表的高效存储.虽然流表压缩机制可以提高TCAM的利用率,但流表压缩降低了流规则的可见性.
另一种是流规则拆分分配机制.文献[12]中将规则转化为有向依赖图,将规则拆分后缓存在存储桶中.虽然将规则存储在额外存储设备上可以缓解TCAM空间紧缺的问题,但是额外存储设备使得网络的管理变得复杂.文献[13]提出了一种线性规则拆分方法和两种基于启发式的规则分配方法.但该方法会导致计算成本较高.文献[14]将流条目划分为通用规则和本地规则,并且针对不同类型的流条目执行不同的拆分和分配算法.这意味着拆分分配可能导致拆分后流规则数目较多.
考虑到流规则压缩存在一定的弊端,并且流规则拆分分配机制还有很大的改进空间.因此本文根据按需安装的原则,对高级策略(即ACL)提出了基于拆分分配的流规则放置算法.
3 网络模型
3.1 网络拓扑模型
网络拓扑可以抽象为一个有向连接图G=(V,E),由基础设备和链路组成,顶点集合V=(H,S)由主机集合H和交换机集合S组成.边集合E由Esh和Ess组成,其中Ess表示交换机之间的通信链路,Esh表示交换机与主机之间的通信链路.
3.2 节点模型
交换机节点模型为S={id,Tcapi,Ptabi,Ftabi,linkset}.其中id表示交换机的唯一标识,Tcapi表示为交换机Si上TCAM的存储空间.每个流表由策略规则表Ptabi={rp1,rp2,…,rpn}和转发规则表Ftabi={rf1,rf2,…,rfn}组成,linkset表示该节点到下个节点的集合.
为了防止交换机中的规则空间被全部占用,基于式(1)对策略规则表进行空间分配.
Pcapi=Tcapi×THRTCAM×portion
(1)
式(1)中Pcapi表示为策略规则表的大小,Tcapi为TCAM存储空间,THRTCAM为交换机规则空间的最大利用率,portion表示交换机流规则空间可以分配给高级策略规则的比例.
3.3 数据流模型
本文将数据流描述为Flow={cookie,ips,ipd,ports,portd,rate,time,path,edgeset}.其中,cookie用以标识一个数据流,ips和ipd分别代表数据流的源IP和目的IP地址,ports和portd分别代表数据流的源和目的端口地址,rate为数据流的速率,time为当前时间戳,path为数据流经过的一系列交换机节点的有序序列,edgeset为数据流经过的有向边的集合.
3.4 流规则模型
本文的流规则模型表示为ri={pre,act,tim,pri},其中pre为流规则的匹配域,act为流规则的动作域,本文ACL的动作域为act={Permit,Drop},其中Permit表示允许转发数据分组,Drop表示丢弃数据分组.tim为流规则的超时值,对于所有的ACL规则设置统一的固定超时值.pri为流规则的优先级.
4 算法设计
4.1 设计目标

(2)
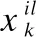
(3)
4.2 基于矩形拆分分配的PNS算法
设计了基于矩形拆分(Rectangle Based Split,RBS)算法在路径上放置与之相关的高级策略规则子集(Partial Related Policy and Not Share Rule Mechanism,PNS),路径之间不共享流规则.网络中的数据分组可能仅与高级策略规则集中的部分规则相匹配,所以只需在数据分组的转发路径上放置与之匹配的高级策略规则集即可.因此PNS算法可以保证规则拆分分配前后网络操作的一致性.下面分别从交换机空间资源分配和基于矩形拆分分配算法进行介绍.
4.2.1 交换机空间资源分配

(4)

(5)
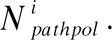
(6)
(7)
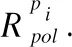
(8)
交换机资源分配算法如算法1所示,其中1-7行是交换机为每条路径分配相应的空间,其中8-16行是为每条路径筛选与路径相关的策略规则.
算法1.交换机流规则空间分配算法
输入:路径匹配结果{p1,{IPh1,IPh2,…,IPhm}},…,{pn,{IPhl,IPhl+1,…,IPhn}},高级策略规则Rpol.
输出:交换机为不同路径分配的空间.
BEGIN:
1.FORi∈S
3. 按式(5)为每个路径平均分配交换机空间;
4.ENDFOR
5.FORpi∈{p1,p2,…,pn}
6. 根据式(7)确保路径pi所分配到足够的规则空间;
7.ENDFOR
8.FORpi∈{p1,p2,…,pn}

11.IF估计值>分配值
12. 重新执行交换机规则空间分配模块;
13.ELSEIF估计值≤分配值
14. 执行规则集拆分分配模块;
15.ENDIF
16.ENDFOR
17.END
4.2.2 矩形拆分分配算法
本文使用几何方法来表示规则,提出基于矩形的拆分算法RBS,假设由源地址和目的地址生成一条规则,可以用一个矩形网络来表示规则,如图1所示,横坐标F1表示源地址的范围,纵坐标F2表示目的地址的范围.将按优先级排列的ACL映射到矩阵中.由于规则中使用通配符,所以规则之间有重叠部分,其中高优先级的规则矩形位于低优先级矩形的上部.

图1 ACL规则集的几何表示

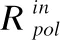
(9)

(10)
(11)
(12)
基于矩形的切块算法如算法2所示.3-9行是选择合适的矩形切块q,并根据矩形切块对规则进行拆分.10-17行是将规则安装在相应交换机上.
算法2.基于矩形拆分分配算法
输入:路径匹配结果{p1,{IPh1,IPh2,…,IPhm}},…,{pn,{IPhl,IPhl+1,…,IPhn}},高级策略规则Rpol.
输出:在交换机上放置的规则.
BEGIN:
1.初始化参数di←Pcapi,xj,i←交换机si为路径pj分配的交换机空间;
2.q←满足条件最大的矩形切块,需要满足q≤di;
3.FORpi∈{p1,p2,…,pn}
4.FORsi∈pi
5.WHILE交换机si有可用的流规则空间
6. 根据式(10)选择矩形q;
8. 选择矩形q′
9.ENDIF
10. 在当前交换机上安装与矩形切块q包含的规则集

11. 更新路径相关策略规则;
14.ENDWHILE
15.IF到路径pi的最后一个交换机,仍有规则未安装
16. 重新执行拆分模块;
17.ENDIF
18.ENDFOR
19.ENDFOR
20.END
4.3 基于平均拆分分配的AVS算法
当网络拓扑中节点度较大时,每个节点均被多条路径所共用.为了更高效的利用流表空间,可以使路径之间共享交换机空间,因此本文提出了基于平均拆分(Average Based Split,ABS)算法在路径上放置全部规则集机制(All Policy Split Average and Share Rule Mechanism,AVS).
4.3.1 计算最值
AVS机制是将高级策略规则集均匀拆分后放置到路径上.在网络中不同数据分组的转发路径长度有可能不同,若最短路径pshort上可以放置全部高级策略规则子集,那么其他路径也都可以成功放置拆分后的规则块.因此均匀拆分的份数取决于最短路径的长度lshort.
4.3.2 平均拆分分配算法
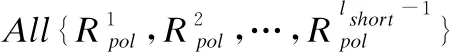
(13)
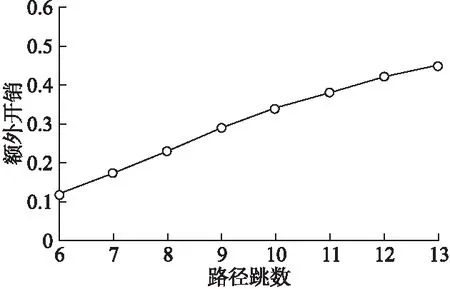
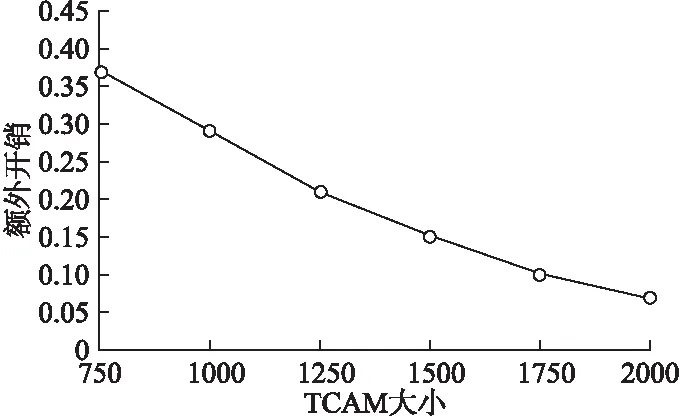
NAVS (14) (15) AVS算法对流规则进行拆分放置时,不一定按顺序放到路径上的交换机中,可能存在优先级高的规则被放置到路径的下游.因此为了保证网络全局操作的一致性,需要在放置了低优先级策略的交换机上放置与之相同匹配域的高优先级策略. 基于平均拆分分配的算法如算法3所示.首先计算最短路径,并将规则等分.然后在最短路径上安装相应的规则,在其他路径上安装未安装的规则. 算法3.基于平均拆分分配算法. 输入:路径匹配结果{p1,{IPh1,IPh2,…,IPhm}},…,{pn,{IPhl,IPhl+1,…,IPhn}},高级策略规则Rpol. 输出:在交换机上放置的规则. BEGIN: 1.将路径p1,p2,…,pn按长度从小到大排序; 2.记最短路径为pshort,最短路径长度为lshort; 3.按照式(13)计算每份规则块包含的规则数NAVS; 5.FORpi∈{p1,p2,…,pn} 6. 在其他路径上安装剩余规则,如式(15); 7.WHEN安装低优先级规则时 8.IF数据分组同时匹配高优先级规则 9. 在安装了低优先级规则的交换机上安装相应的高优先级 规则; 10.ENDIF 11.ENDWHEN 12.ENDFOR 13.END 本节对设计的SDN流规则拆分分配算法进行仿真实现与性能评价.基于Mininet网络仿真器和Floodlight控制器构建仿真实验平台,以此为基础,分别从拆分后规则总数、运行时间和额外开销三个方面对比设计的PNS、AVS流规则放置机制与基准机制.仿真环境详细信息如表1所示. 表1 仿真环境 本文从拓扑园中选择了Darkstrand拓扑和ATT North America拓扑作为实验拓扑.Darkstrand拓扑结构如图2(a)所示,具有28个节点,31条边,最大节点度Maxndeg为3,平均节点度Avgndeg为2.2,其中节点的度为连接该节点的边数.ATT North America拓扑结构如图2(b)所示,具有25个节点,57条边,其中最大节点度Maxndeg为10,平均节点度Avgndeg为4.2. 图2 网络拓扑结构 采用基于枢轴位拆分(Pivot Bit Decomposition,PBD)算法[15]作为对比机制,该算法在路径上放置全部高级策略规则集(All Policy Split Based on Pivot Bit and Share Rule Mechanism,APS).基于枢轴位拆分算法是目前比较具有代表性的算法之一,因此采用该算法作为对比机制.枢轴位指的是规则位上是通配符的位点,如果一个规则具有P个轴点,则可以分解成为2p个新规则. 本文使用ClassBench[16]生成10000条高级策略规则集,分别在实验拓扑上将本文提出的PNS和AVS机制与对比机制APS在拆分后生成的流规则总数、运行时间这两个方面进行对比实验,以及对本文提出的机制所产生的额外开销进行实验. 5.3.1 拆分后生成的流规则总数 流规则总数为将ACL规则进行拆分分配后,网络中的流规则数量.流规则增加率为拆分分配后的流规则总数与ACL原规则数相比增加的比例.规定每个交换机的TCAM可存储2000条规则,当网络中的总规则数超过总容量时,将无法放置规则. 在节点度较小的Darkstrand拓扑中,对三种算法拆分后产生的总规则数进行比较.如图3(a)所示.从图中可以看出,随着ACL原规则数的不断增大,流规则总数也不断增大.由于AVS和APS两个算法拆分和分配的情况比较接近,因此这两种算法所呈现出的增长趋势比较相似.PNS机制明显优于AVS和APS.这是因为AVS和APS算法在路径上放置全部高级策略规则,而PNS机制只拆分与路径相关的规则集,因此PNS机制中每条路径拆分基数小,总规则数也相应的少.在Darkstrand拓扑中,最短路径长度为9跳,最短路径上可存储的流规则数为路径长度与该路径上交换机存储空间的乘积,即18000条.所以当ACL原规则数超过18000时,则不能使用AVS和APS机制.在相同ACL原规则数下,PNS机制算法流规则平均增加率约为34.1%,AVS和APS的流规则平均增加率分别为113.27%和144.85%. 图3 不同拓扑上拆分后流规则总数对比 在节点度较大的ATT North America拓扑中,比较三种算法拆分后产生的总规则数,如图3(b)所示,APS机制的增长速度明显大于其他机制.从图3(b)中可以看出,PNS机制产生的规则数与AVS机制产生的规则数相差不多.结合图3(a)中PNS的表现,说明PNS机制具有较好的适用性.同样,在该拓扑下,最短路径跳数为6,AVS和APS可以放置的最大规则数为12000条.所以当规则总数大于12000时,将不能使用这两个机制.在相同ACL原规则数下,AVS和PNS机制的流规则平均增加率约为55.5%和67.06%,APS的流规则平均增加率为186.96%. 5.3.2 运行时间 将三种算法分别在路径为16的Darkstrand拓扑和路径数为28的ATT North America拓扑下运行,比较其运行时间.如图4所示,随着路径的增加,时间也不断增加.三种机制都以路径为基本计算单位.AVS使用线性时间拆分,所以运行时间最短,APS需要递归寻找枢轴位,运行时间次之.PNS机制虽然在两种拓扑上产生的规则总数最低,但是由于其需要为每条路径上的每个交换机都递归的寻找拆分切块,因此运行时间也最长. 图4 不同拓扑上算法运行时间对比 5.3.3 额外开销 额外开销指的是流规则放置机制使用拆分分配算法生成的额外规则与原高级策略规则总数的比值,可以体现流规则放置机制的性能.在对额外开销进行测试时,需要测试算法在不同跳数路径下的额外开销,由于Darkstrand拓扑结构相对简单,因此在ATT North America拓扑下,对算法进行测试. 在交换机TCAM大小为750,ACL规则总数为3000的情况下,对PNS机制在不同跳数路径下产生的额外开销进行测试.如图5所示,随着路径跳数的增加,PNS算法的额外开销也不断增加.这是因为当路径的跳数增加,交换机可能被更多条路径共用,因此交换机为每条路径分配的流规则空间也随之降低.PNS算法需要寻找更小的切块来拆分原规则集,从而使不同交换机中安装重复规则,因此导致了额外开销的增加. 图5 不同跳数的路径上产生的额外开销 在路径跳数为10,ACL规则数为5000条的情况下,测试PNS机制在不同TCAM大小下产生的额外开销.如图6所示,交换机TCAM大小从500增加至2000.随着TCAM大小的增加,额外开销逐渐降低.这是由于TCAM的存储空间变大,PNS中切块的选择也可以相应的增大,因此与切块相交的规则按一定比例减少,额外开销也随之降低. 图6 不同TCAM大小的额外开销 本文在现有的TCAM大小下,思考如何将流规则更高效的放置在交换机上.本文提出了面向SDN的流规则拆分分配算法,选择ACL作为高级策略,分别设计了基于矩形切块拆分算法在路径上放置与之相关的高级策略规则子集的PNS算法和基于平均拆分算法在路径上放置全部规则集策略的AVS算法. 本文设计的流规则放置算法,取得了一定的研究成果.但在流规则拆分过程中,可能会导致网络状态不稳定,因此如何评估和降低拆分对网络状态的影响将作为下一步工作.当拓扑或者高级策略发生变化时,如何提高鲁棒性和容错能力同样是下一步工作的重点.
5 性能评价
5.1 拓扑用例

5.2 对比机制
5.3 性能评价


6 结束语
