深度强化学习在室内无人机目标搜索中的应用
2020-09-04赖俊,饶瑞
赖 俊,饶 瑞
陆军工程大学 指挥控制工程学院,南京 210007
1 引言
随着飞行控制和新型材料等技术的突飞猛进,无人机得到越来越广泛的发展和应用。无人机已成功应用到不同领域,如环境监测、灾后救援、道路交通安全、制造浪漫等[1-2]。无人机体积小,在室内封闭环境下执行目标搜索等任务时更方便,但室内环境、空间结构和障碍物的复杂性和未知性等,要求无人机对环境有较高的感知能力和响应能力[3-4]。强化学习具有自学习和在线学习的特点,能很好地适应未知复杂环境,研究以其为基础的室内无人机目标搜索具有重要的理论意义和实际应用价值[5-6]。
文献[7]提出了一种基于改进遗传算法的无人机航路规划方法,文中通过改进交叉和变异算子,更快更稳更准地搜索到每一次的最优航线。在该文中起始地到目标间的威胁和障碍事先知道,搜索区域的信息已知。文献[8]结合动态搜索模式和固定搜索模式,先划分搜索区域,再对重点子区域进行固定模式搜索覆盖,并动态搜索其余区域。两种模式的结合,加快了无人机对任务区域的搜索,并在短时间内能发现更多目标。文献[9]提出了一种未知环境下基于Q 学习的无人机目标搜索算法,并与基于D-S 证据理论的方法进行对比,仿真结果表明基于Q学习的搜索算法能适应未知环境,较快速率地发现目标。文献[10]提出基于内在好奇心的目标搜索算法,先利用神经网络从原始输入空间中生成特征空间,再在该空间中采样进行目标搜索,并模拟了机器人手臂与物体相互作用的实验,结果表明该搜索方法可应用到工程。
目前,传统用于目标搜索的方法,搜索效率不高,且随机搜索需对环境有一定的先验知识[7]。因此引入强化学习来训练无人机进行目标搜索。强化学习模型由环境(Environment)和智能体(Agent)两部分组成[11]。Agent凭借“试错”的方法在与环境的不断交互中进行学习[12-14]。Agent在当前时刻的状态下,采取某动作后,转移到下一时刻状态;环境接收到该动作后,不会告诉Agent 正确选择(这点不同于监督式学习),只会给Agent 提供反馈,Agent 根据反馈信息改变自身动作以适应环境。当收到正反馈信息时,Agent 就强化该行为策略,反之,该行为策略执行的概率会降低。在强化学习中,Agent 利用与环境交互得到的奖赏来指导行为,以获得最大奖励。但当无人机在室内进行随机目标搜索时,存在奖励函数设计难,训练周期长,并容易陷入局部区域等问题。文中针对强化学习在室内无人机目标搜索中存在的问题,依据好奇心驱动思想,提出了基于空间位置标注的好奇心驱动方法,以此提升无人机学习过程中的内部奖励,缩小训练周期,从而尽快完成训练。并使用Unity 3D 中 的 ML-Agents(Unity Machine Learning Agents)学习插件进行仿真,实验结果表明了该方法的有效性和可用性。
2 仿真环境和任务介绍
基于Unity 3D平台对一个太空密闭方舱进行三维仿真,并使用其中的开源插件ML-Agents在模拟环境中训练无人机[15-16]。ML-Agents包含三个高级组件(如图1):(1)Learning Environment,包含Unity 场景和所有游戏角色;(2)Python API,包含用于训练的所有机器学习算法;(3)External Communicator,将 Unity 环境与 Python API连接起来,位于Unity环境中。

图1 ML-Agent结构图
图1 中的Brain 保存了每个Agent 的策略,并返回Agent在每个状态下应采取的动作。Agent有4个逻辑模块:(1)CollectObservations(如图2 和图3),收集Agents的观察输入数据和自身velocity;(2)AgentAction,获取VisualObservation的输入值;(3)AgentReset,Agent重置;(4)对Agent进行奖励设置。

图2 CollectObservations结构图

图3 CollectObservations动作示意图
太空舱三维仿真图如图4,二维平面图如图5。仿真环境中共包含12个舱室和3种类型的通道,分别为L型、T字型和十字型。

图4 太空舱三维环境仿真示意图

图5 太空舱平面示意图
12个舱室见图中五角星和字母A到K的位置,每个舱室的内部环境和装饰基本一致,可提升无人机的泛化能力。在通道中设置了两处高度不一样的障碍物,分别位于太空舱底部和顶部(见图5阴影长方形),障碍物可提高无人机的避障能力。
无人机(Agent)在该模拟环境下飞行时,每次从标有五角星的位置开始进行目标搜索,搜索目标每轮随机出现在位置A到K上。在飞行过程中,当撞到太空舱内壁和设置的两处障碍物,或长期停留在某块区域内时,此轮任务失败,需重新开始新一轮训练;无人机凭借自身的雷达探测装置,寻找目标完成任务,得到奖励。
在模拟的太空舱环境下,单架无人机从固定位置开始搜索单目标,目标每次在11 个位置随机出现。舱内狭长“胡同”较多,无人机易陷入该类局部区域,因此要求无人机在走到“胡同”底部时,接受最少的惩罚跳出该区域并继续探索;设置的两处高低障碍物,无人机很容易将它们误认为是“死胡同”,从而停止对前方的探索。无人机通过自身雷达感知收集观察数据,探测过程中应尽量保持机身平稳,避免陡升陡降,减少数据误差,传感器的性能在一定程度上影响搜索效果。
3 基于深度强化学习的室内无人机目标搜索
3.1 PPO算法
深度强化学习算法很多,文中采用的是近端策略优化(Proximal Policy Optimization,PPO)算法,该算法结合了Q-Learning 和深度学习的优势[9],是一种基于策略梯度(Policy Gradient)的异策略(off-policy)学习算法。与TRPO(Trust Region Policy Optimization)算法相比,TRPO算法新增了一个约束条件,让新策略和旧策略的差异性(用KL 散度衡量)小于δ,但该带约束的TRPO算法求解复杂。PPO 算法将约束作为目标函数的正则化项,降低了算法求解难度。PPO 算法采用截断(clip)机制,目标函数如下[17]:

其中,rt(θ)= pθ(at|st)pθ_old(at|st),为新旧策略的概率比,上式说明新策略不会因远离旧策略而获益[17]。当̂>0时,若rt(θ)>1+ε,则Lclip(θ)取到上限值 (1+ε)̂;当̂<0 时,若rt(θ)<1-ε,则Lclip(θ)取到下限值 (1-ε)̂。
3.2 好奇心驱动模型
由于无人机是在室内封闭空间下进行飞行训练,容易发生碰壁或长时间困在一个局部小区域内无法飞出,从而不能完成任务。此时,引入好奇心,可以打破这种僵局,好奇心可以让Agent勇敢进入陌生环境去寻找目标。因此,Agent 在搜索目标的同时,还要对环境进行探索。
好奇心激励函数,是在给定状态st和动作at,Agent对状态st+1的预测差,即:

函数φ是针对状态的编码函数。可由另一前向网络产生,即:

和φ(st+1)相差越大,Agent的好奇心越强。
在一个复杂环境中,存在很多无关特征,Agent需要找到特征空间。自监督预测包括前向编码和逆动力学模型两个模块[18],前者将状态st编码成φ(st),后者用连续时刻的φ(st)和φ(st+1)来预测时刻t的动作at,而常规操作是用st和at预测st+1。该模型可有效提取有影响特征,过滤无用特征,因而能极大减少学习时间,提升学习效率。提取特征空间,表达为:


深度强化学习的目标是找到使得奖励期望达到最大化的策略[20-21],即:

综合好奇心激励函数和特征空间的选择,得到最终的优化目标:

为满足好奇心,要最大化预测差Lp_s,即实现下一状态的现实和预测脱节,但对动作的预测要尽量和实际采取的动作一致,因此要最小化Lp_a,目标函数中的后两项也可看作是正则化项。
3.3 基于空间位置标注的好奇心驱动方法
无人机在室内飞行探索时,由好奇心激励其进入未知区域,但无人机不能区分某区域是否被探索过。此时,对周围环境进行标注和存储不失为一种好方法。
Savinov N 提出了基于情景记忆的好奇心模型[22]。在该模型中,Agent存储对环境的观察结果,并奖励那些存储记忆中不存在的观察结果,使得Agent拥有进入新环境的动力,有效防止其在原地停留或兜圈。
采用正六边形对探索空间进行划分,下面描述基于空间位置标注的好奇心驱动方法:
S(h)表示用正六边形对高度为h的二维空间进行区域划分,S(h,k)表示第k块区域,Ts(h,k)为无人机进入第k块区域的次数,γ1、γ2和γ3分别表示无人机首次和非首次进入某一区域的奖励和惩罚因子以及找到目标的奖励因子。文中γ1=0.000 1,γ2=0.01,γ3=4,算法如下:


4 仿真实例
4.1 Agent状态空间及奖励规则设置
用无人机不同的位置坐标描述其状态空间,无人机的动机集合有9 个,分别为前进、后退、左移、右移、左转、右转、上升、下降和无动作。动机和动作间映射关系见表1。

表1 无人机动机动作映射表
使用基于空间位置标注的好奇心驱动方法,在二维平面环境下用正六边形对空间进行划分,如图6。

图6 平面环境下的区域标注示意图
无人机在搜索过程中,奖励规则如下:如果无人机进入某一标注区域,该标注区域访问次数加1,若该区域访问次数等于1,则无人机获得奖励0.000 1 分,若该区域访问次数大于1,则得到惩罚0.01分,无人机两次在同一区域,视为无动作,该区域访问次数依旧加1,并接受惩罚;无人机撞墙或是撞到障碍物,都接受惩罚;为了最快到达搜索目标,无人机每走一步也接受惩罚。无人机奖励规则见表2。

表2 无人机奖励规则
4.2 实验结果及分析
在训练Agen(t无人机)时,ML-Agents 的参数设置见表3。
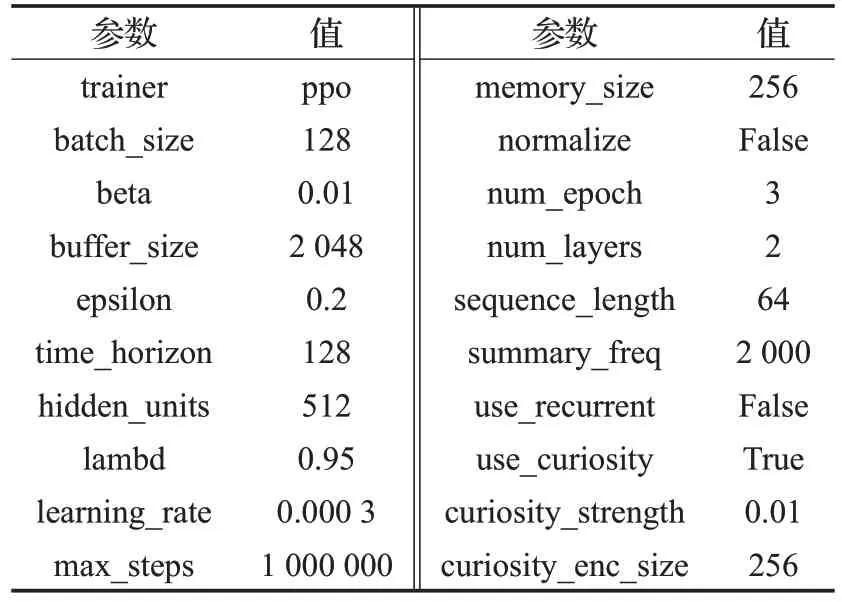
表3 ML-Agents训练参数表
基于TensorFlow 实现训练工作,训练完成后,得到的策略(policy)是一个TensorFlow 的模型文件。使用2层且每层隐单元个数为512的神经网络训练无人机,优化器使用PPO算法,算法中的截断系数ε=0.2,memory_size为256,batch_size为128,learning_rate为0.000 3,存储空间标注信息的buffer_size为2 048,use_curiosity为True,max_steps为1 000 000,Agent 的奖励由两部分组成,一个是外部奖励,完成目标时环境给予4分,另一个是由好奇心决定的内部奖励,通过为每一个动作提供子奖励来促使Agent快速完成任务。
调用TensorBoard,可看到Agent的训练结果,如图7和图8。

图7 平均累积奖励和内在奖励
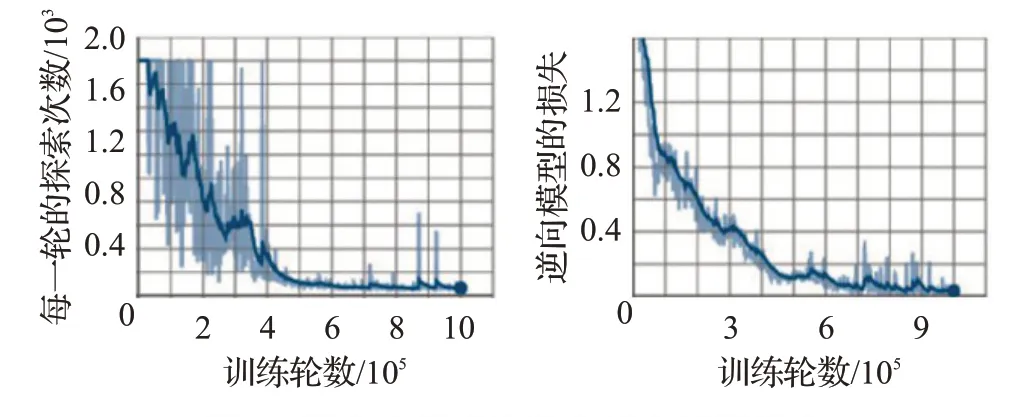
图8 回合内探索次数和逆向模型损失
由图7 可知,在训练期间,每一轮的平均累积奖励逐渐增加,并最终无限接近于外在奖励4 分,说明经训练后,Agent能迅速找到目标,完成任务,获得外在奖励;而内在奖励随着训练的推进,呈逐渐下降的趋势,并趋于零。因为在训练初期,Agent通过好奇心的内在奖励,不断探索环境,内在奖励发挥较大的作用;Agent在训练后期已能快速搜索到目标,拿到外部奖励,内部奖励的作用随着训练次数的增加逐渐减弱并趋零。
由图8可知,每个回合内的探索次数随着训练逐渐减少,说明Agent 逐步学习到了最优的搜索策略,并学习到躲避障碍物,搜索次数越来越少,搜索效率不断提升,训练效果好,训练后能较快较准地找到随机出现的目标。逆向模型的损失呈逐渐下降的走势,说明Agent在通过各种类型的通道时,能做出观测和合理的动作,如在通过十字形通道时,能够检查两侧是否存在目标,避免了飞入无目标舱室后进行多余的检查。
5 结束语
文中使用U3D这样一个通用游戏引擎搭建了一个复杂的室内无人机飞行环境,使用ML-Agents 实现了TensorFlow 与Agents 的对接,采用PPO+基于空间位置标注好奇心探索的算法展现了一个3D环境下的一个小型无人机如何进行深度强化学习。通过这种可视化的深度强化学习,Agents 学会了在陌生地域搜索随机目标、避障和调整飞行高度等技能。仿真环境及实验结果表明,U3D的ML-Agents是一个出色自由的深度强化学习开发平台,通过学习训练,无人机在飞行时的平稳保持性、对障碍物判断的精准性、探索的高效性、执行动作的合理性等各项性能得到显著提升;相较于传统的搜索方式,基于空间位置标注的好奇心驱动方法,克服了无人机陷入局部区域的缺陷,有效缩短训练周期,提升搜索到随机目标的准确率,编码量更少,智能水平更高。
