流形极限学习机自编码特征表示
2020-09-04陈晓云
陈 媛,陈晓云
福州大学 数学与计算机科学学院,福州 350116
1 引言
近年来,因深度学习(Deep Learning,DL)在许多困难的学习任务(例如语音识别[1-2]、目标检测[3-4]和图像分类[5-6])上都表现出色,因此受到各领域研究人员的广泛关注。典型的深度学习架构包括深度置信网络(Deep Belief Network,DBN)[7]、堆叠式自动编码器(Stacked Autoencoder,SAE)[8]和卷积神经网络(Convolutional Neural Network,CNN)[9-10]可用于特征提取任务,训练多层神经网络或深层网络。深度网络的性能优于传统的多层神经网络,单层前馈神经网络和支持向量机(Support Vector Machines,SVM),但存在学习速度慢的问题。极限学习机(Extreme Learning Machine,ELM)[11]是一种单隐层前馈神经网络,同传统的前馈神经网络学习算法相比,它不仅学习速度快,还能找到全局最优解。就学习效率而言,ELM 不仅是具有最小人为干扰的网络模型,还具有精度高和学习速度快等优点。鉴于ELM 的高效率,一些研究人员致力于研究如何将ELM集成到通用深度学习框架中。Kasun 等人[12]应用ELM进行自编码,提出了极限学习机自动编码器(Extreme Learning Machine Autoencoder,ELM-AE)特征表示方法,对ELM-AE 的隐层输出进行聚类。Ding 等人[13]将ELM-AE 应用到 US-ELM 中提出 US-EF-ELM 算法,把ELM-AE 得到的特征作为US-ELM 的隐层输出,再利用US-ELM 进行降维。受到多层感知机(Multilayer Perceptron,MLP)理论的启发,Tang 等人[14]通过使用ELM-AE 进行特征表示和提取,将ELM 扩展到了多层ELM(ML-ELM)。Li 等人[15]将稀疏性和邻域理论整合到ELM-AE中逐层提取数据的深层特征,提出了一种基于稀疏和邻域保留的深度极限学习机(SNP-DELM)。Wei 等人[16]基于深度置信网络和极限学习机,提出一种新的入侵检测方法,有效提高入侵检测识别率和运行效率。Kong等人[17]将深度卷积神经网络和极限学习机组合成DCELM模型,很好地融合了DCNN更好的特征提取能力和更快的ELM训练速度。
为了提高现有机器学习模型的性能,具有局部数据一致性的学习受到了研究人员的广泛关注。PCA[16]是最经典的线性降维方法,以最大化投影散度为目标,但未考虑样本间的近邻结构关系。局部保持投影(Locality Preserving Projections,LPP)[18]、近邻保持嵌入(Neighborhood Preserving Embedding,NPE)[19]、拉普拉斯特征映射(Laplacian Eigenmaps,LE)[20]是几种常用的技术,能够使得降维后的数据保持原数据的近邻结构,然而可能会导致信息的丢失。而ELM-AE 以全局特征为主可以避免信息丢失但未考虑数据的固有流形结构(即在原始空间中较近的数据点在新空间中应尽可能靠近)。为了更好地刻画局部特征,本文在ELM-AE上增加流形正则项,并用近邻表示来学习样本之间相似性,提出了一种基于流形的极限学习机自动编码器(Manifold-based Extreme Learning Machine autoencoder,M-ELM),通过这种方式保持数据的近邻结构并使模型学习得到的样本相似度更具有数据自适应性。
2 相关工作
本文将对极限学习机自动编码器(ELM-AE)进行扩展,为了便于理解所提出的算法,本章简要对ELM-AE的基本思想和功能及流形正则化的思想进行介绍。
2.1 ELM-AE
极限学习机自动编码器(ELM-AE)[12]是基于ELM的一种无监督学习算法,且ELM-AE 的输出等于ELMAE 的输入,其分为两个阶段。ELM-AE 的结构框架如图1所示。在第一个阶段,对于无标签的原始样本数据集X=[x1,x2,…,xn]T∈Rn×m,隐层神经元将X映射到nh维特征空间。根据样本维数m和隐含层神经元数nh的大小,ELM-AE可以使用三种不同的结构表示提取的特征:(1)当m >nh时,即输入神经元的数量大于隐含层中神经元的数量,此时为压缩结构,在这种情况下ELMAE从比输入数据空间维数低的隐含层特征空间中捕获特征;(2)当m <nh时,即输入神经元的数量小于隐含层中神经元的数量,此时为稀疏结构,在这种情况下ELMAE从比输入数据空间维数高的隐含层特征空间中捕获特征;(3)当m=nh时,即输入神经元的数量等于隐含层中神经元的数量,此时为等维结构,输入数据空间的维数与隐含层特征空间的维数相同。ELM-AE 隐含层的输出即:

其中g为激励函数,常用的激励函数如Sigmoid 函数。则网络的输出为:

在第二阶段,ELM-AE需要通过预测误差的平方损失更新输出权重β,ELM-AE的目标函数为:
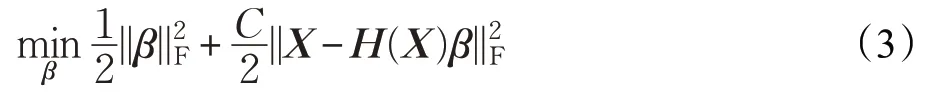
其中第一项是控制模型复杂度的正则项,C是误差的惩罚系数,β∈Rnh×m为隐节点到输出节点的权重矩阵,H(X)为以下矩阵:
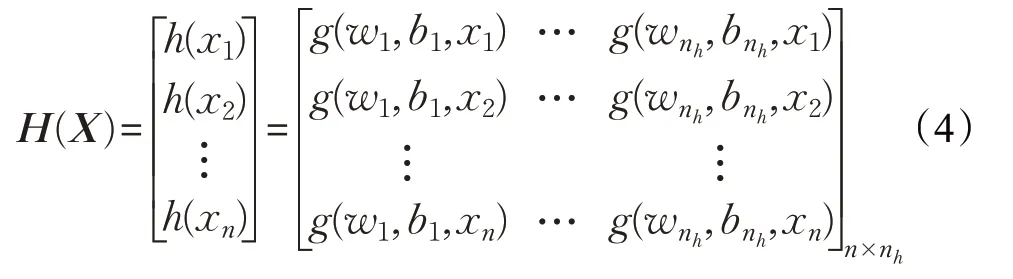
目标函数左右两边对β求导,令导数等于0,即得到问题的解。上述问题的解分为两种情况,当样本数大于隐含层神经元数时,解得:
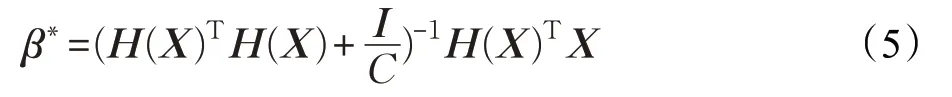
当样本数小于隐含层神经元数时,H的列数将多于行数,直接解式(1)~(3)不仅需要更多的内存开销,而且会出现矩阵不可逆的情况。为了解决这个问题,根据文献[21]的方法,令β=H(X)Tα(α∈Rn×m),解得:
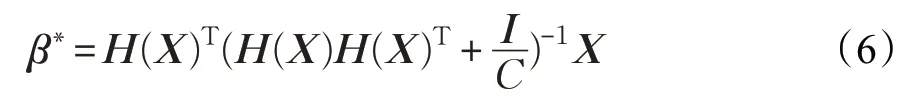
β负责学习从特征空间到输入数据的转换。给定输入数据X,在nh维空间中获得Xnew=XβT的表示形式。随后,可以使用Xnew替换聚类和嵌入任务中的原始数据,使用k-means算法对获得的新数据Xnew进行聚类。
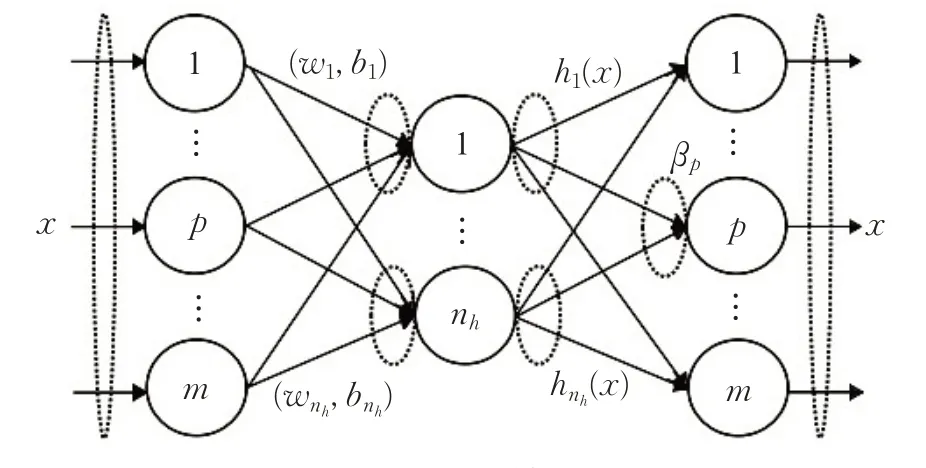
图1 ELM-AE的结构示意图
2.2 流形正则化
流形正则化的思想是在将隐含层投影到输出层时对原始样本点相距较近的近邻点施加较大的惩罚,使得投影后的样本点保持近邻关系。通过最小化目标函数:

即可使数据的近邻结构得以保持。wij为样本xi和xj的相似度,定义为:

其中,Nk(xi)表示xi的k近邻。最小化目标函数可化为矩阵形式:
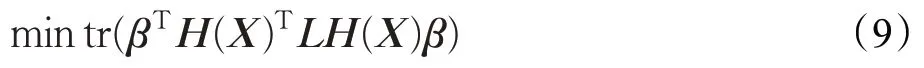
其中,tr(⋅)表示矩阵的迹,L=D-W为拉普拉斯矩阵,D是对角阵,。
3 基于流形的极限学习机自编码
3.1 相似度学习
流形正则化利用高斯函数计算样本之间的相似度,高斯函数用到距离测度,难以避免地也存在高维空间中测度“集中现象”,可能造成样本点间高斯相似性度量的类区分性随着维数增加而减弱,进而影响算法性能。为了更好地刻画样本的相似性,使其具有数据自适应性,根据文献[22],将每个数据点xi表示为其近邻样本的线性组合,即:

其中Z为表示系数矩阵且当xj∉Nk(xi)时Zji=0,并使用(|Zij|+|Zji|)/2 来度量样本xi和xj之间的相似度。文献[23]已经证明在假设子空间是独立的情况下,通过最小化Z的某些范数,可以保证Z具有块对角结构,在数学上被形式化为以下优化问题:

为了确保相似度越高的样本投影后距离越近,将流形正则化中的样本相似度矩阵W用Z进行学习,将式(7)与式(11)结合得到:
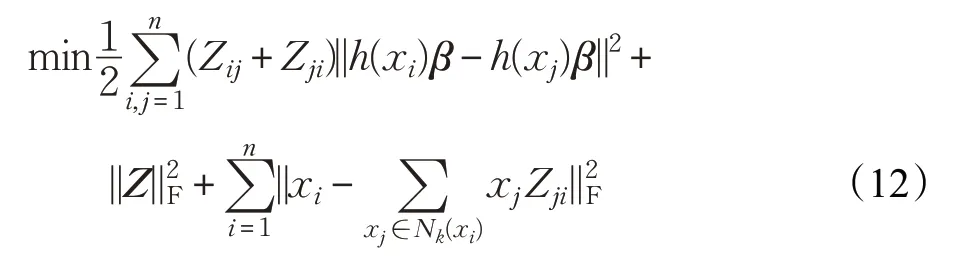
其中第二项和第三项用于自适应的学习原空间中样本的相似度。通过上式,使得样本之间的相似度学习具有数据自适应性。
3.2 基于流形的极限学习机自编码算法
ELM-AE 不仅学习速度快,还能找到全局最优解,但未考虑数据的固有流形结构,因此本文对ELM-AE进行改进。为了更好地刻画样本的局部特征且使样本的相似度矩阵具有数据自适应性,在ELM-AE目标函数中增加流形正则项,并用相似度学习自适应地学习原空间中样本的相似度,将模型(3)与模型(12)进行结合,且为避免平凡解,引入约束(H(X)β)TH(X)β=I,得到M-ELM的目标函数为:

其中,κ,λ,ρ和θ为参数,第一项是控制模型复杂度的正则项,第二项为误差损失项,第三项为流形正则项,第四项和第五项用于自适应地学习原空间中样本的相似度。
3.3 模型求解
上述目标函数有两个变量β和Z,为求解模型,采用ALS 算法进行解决。首先固定β,更新Z,目标函数为:

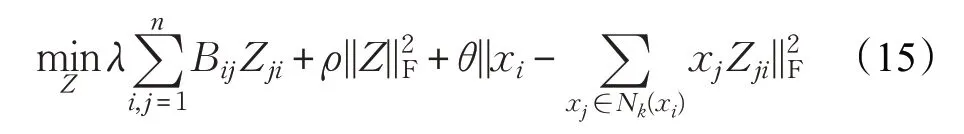
又每个xi相互独立,则:

其中当xj∈Nk(xi)时,A(xi):j=xj;否则A(xi):j=0。令上述目标函数一阶导数为0,得到:

其次固定Z,更新β,目标函数为:
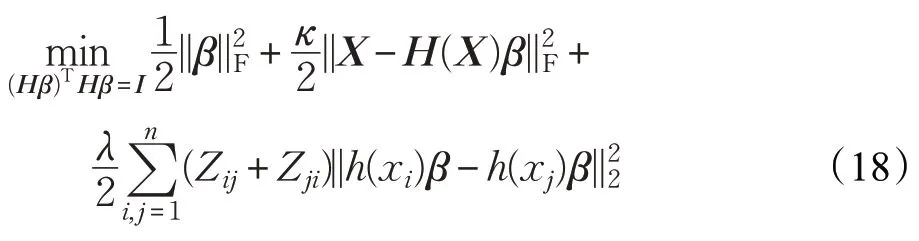
令W=(Z+ZT)/2,则目标函数可化为矩阵形式:
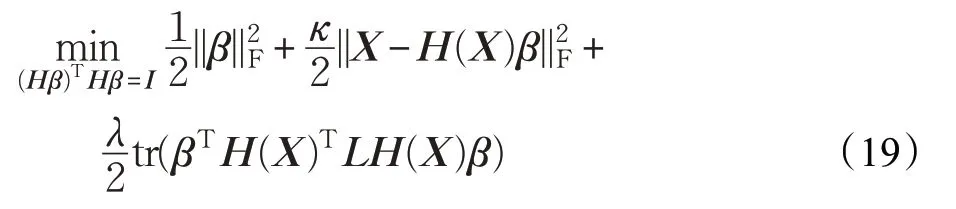
其中,tr(⋅)表示矩阵的迹,L=D-W为拉普拉斯矩阵,D是对角阵,。
类似于ELM-AE,上述问题有两种情况的解。当样本数大于隐含层神经元数时,解得:
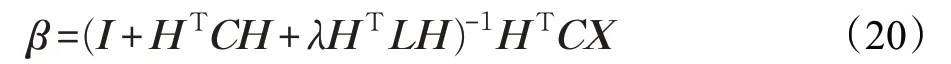
当样本数小于隐含层神经元数时,令β=H(X)Tα,解得:

其中[C]ii=κ,i=1,2,…,n。
β负责从特征空间到输入数据的转换,给定输入数据X,在nh维空间中获得Xnew=XβT的表示形式。随后,可以使用Xnew替换聚类和嵌入任务中的原始数据,最后将得到的新的样本矩阵通过k-means 算法聚成K类。具体算法如下:
算法M-ELM Algorithm for clustering


4 实验结果与分析
本章将研究M-ELM 的特征提取能力,并与PCA、LPP、NPE、LE 和ELM-AE 五种方法进行比较。实验选用 6 个公开数据集:UCI 数据集 IRIS、BCI 竞赛 II 数据集 IIb 中的 Session 10 和 Session 11、BCI 竞赛 III 数据集II 中的Subject A 训练集、基因表达数据集DLBCL、Prostate0 和Colon。其中BCI 数据集需要进行预处理:研究表明,C3、Cz、C4、Fz、P3、Pz、P4、PO7、PO8 和Oz 电极对实验中的BCI 数据集的特征提取和分类效果较好[24],因此对 BCI 竞赛 II 数据集,选取该 10 个电极通道每轮行或列刺激后600 ms的脑电数据作为实验数据并进行0.5~30 Hz的巴特沃斯滤波;对BCI竞赛III数据集,选取相同10个电极通道每轮行或列刺激后1 s的脑电数据作为实验数据并进行0.1~20 Hz的巴特沃斯滤波。数据集的描述如表1所示。
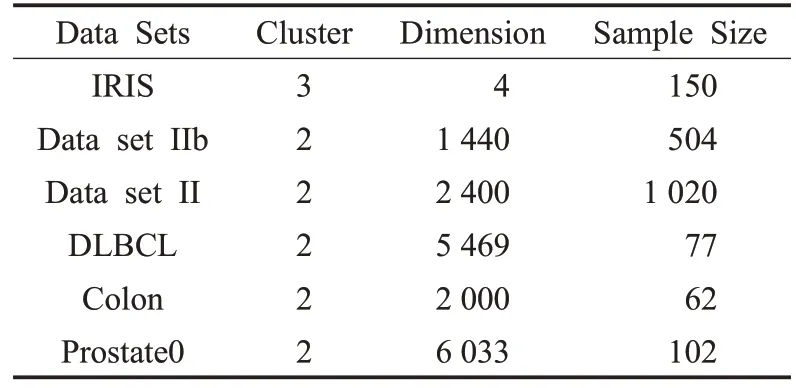
表1 用于聚类的数据集
为了评估每种算法的特征表示能力,本文在实验中采用聚类准确率(Accuracy,ACC)作为聚类评价指标。ACC计算公式表示为:

其中,n为样本数,si和ri为真实标签和预测标签。δ(si,map(ri)) 表示当si=map(ri) 时,δ=1 ,否则δ=0 。map(ri)将聚类得到的类标签映射成与样本数据自带的类标签等价的类标签。
实验采用PCA、LPP、NPE、LE、ELM-AE五种方法与本文方法进行比较,所有方法均用MATLAB 2018b 编程实现。实验中,每个数据集超参数λ、ρ、θ和κ均选自指数序列{10-3,10-1,…,103},激励函数均采用Sigmoid函数。LPP、NPE和LE使用相同的相似度矩阵,近邻数均设为5。每种算法独立选择嵌入空间的维数,将数据分别投影到21,22,…,n维。该实验以特征提取后样本的k-means聚类准确率作为衡量标准。为减少k-means选取初始中心的随机性,实验取10 次聚类准确率的平均值作为各自方法的最终准确率,并选取最优结果进行展示,结果如表2所示。
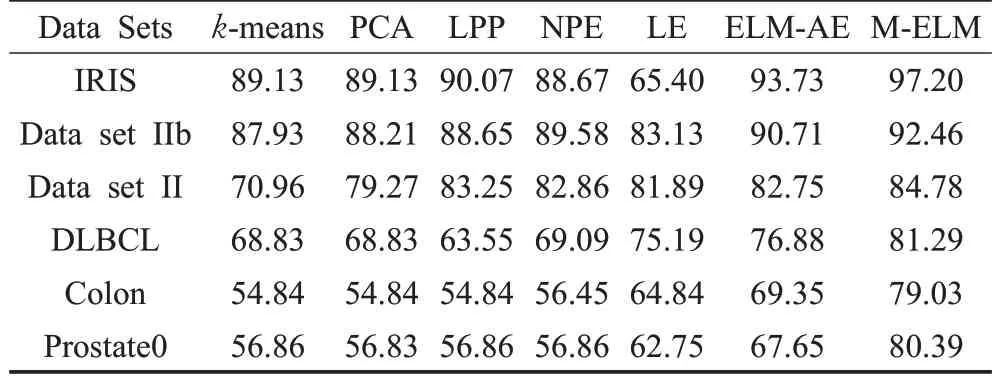
表2 聚类准确率 %
由表2 可以看出相较于 ELM-AE 算法,M-ELM 算法的聚类准确率更高,这说明M-ELM 引入流形正则项保证了彼此接近的原始数据在输出空间中将更接近,并利用近邻线性表示学习相似度矩阵能更好地表示原始数据的结构特征。M-ELM算法对比LE算法,不仅保持了样本的局部信息,还获得了原始样本的主要特征,考虑了样本的全局信息,聚类准确率更高。M-ELM 算法在6 个数据集上的表现优于PCA、LPP 和NPE 算法,因相较于这些线性降维方法,M-ELM 采用了非线性激活函数。对于基因表达数据集,非线性特征提取方法总体要优于线性特征提取方法,而在非平稳脑电数据集上,线性和非线性特征提取方法各有千秋。相较于所有对比方法,M-ELM既是非线性映射,又考虑了局部信息和原始样本的全局信息,且在进行特征提取的同时对相似度矩阵进行了学习,具有数据自适应性,能够提取更合适的特征,聚类效果更优。
UCI 数据IRIS 用于直观地显示M-ELM 的低维投影,将属于同一簇的数据聚在一起。IRIS数据集由四个维度和三个类别组成,分别代表名为sentosa、versicolor和verginica的鸢尾花物种。为了展示M-ELM算法的性能,分别用PCA、LPP、NPE、LE、ELM-AE和M-ELM这6种方法将IRIS数据集投影到2维空间,不同方法投影的每个簇的分布可视化结果如图2所示。
由图2可以看出用PCA、LPP、NPE和ELM-AE方法能够将IRIS数据第一类样本较好地分离,少部分第二类和第三类样本重叠。而LE方法虽能将第一类样本较好地分离,但第二类和第三类样本完全重叠。与这几种方法相比,本文方法的可分性最好,其能够使IRIS数据不同类样本的重叠程度最低,且投影后每一簇的分布宽度要小于其他方法,使投影后同类样本更集中,聚集程度最高。
5 结束语
目前,ELM模型主要用于有监督分类或回归问题,本文对ELM模型推广到无监督特征提取问题上进行了进一步研究,提出基于流形的极限学习机自编码特征表示算法M-ELM。它将ELM-AE 与流形的思想相结合,同时考虑数据的局部信息和全局信息,并进行了相似度矩阵的学习提高数据自适应性,与PCA、LPP、NPE、LE和ELM-AE 相比,M-ELM 具有更强的特征提取能力。数据可视化实验和在6 个数据集上的聚类实验结果表明,M-ELM具有比其他对比方法更好的性能,但如何有效地选择参数是本文之后需要继续探究的方向。
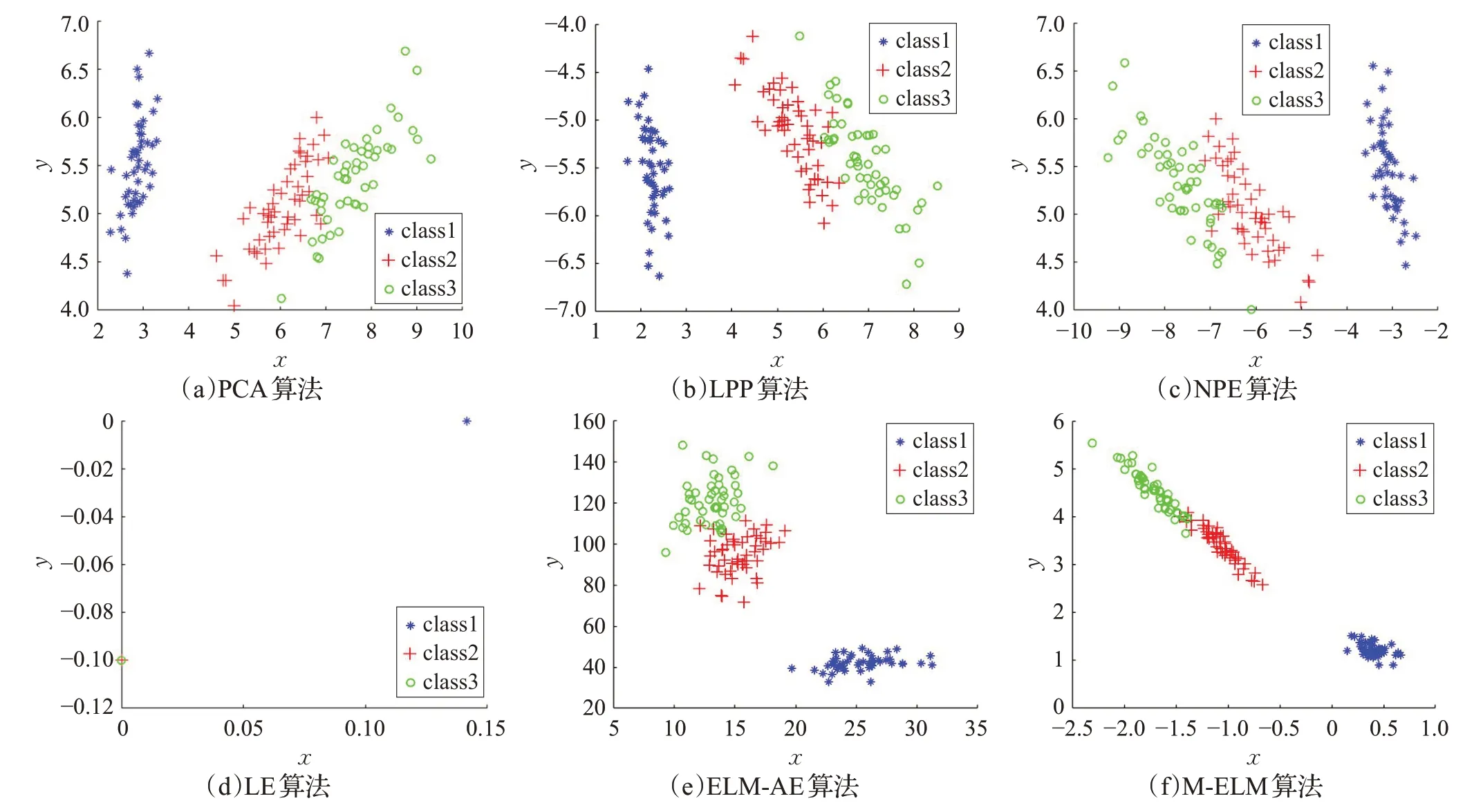
图2 不同算法下IRIS数据集二维可视化
