基于多分辨率网格的异常检测方法
2020-09-04刘文芬穆晓东黄月华
刘文芬,穆晓东 ,黄月华,2
1.桂林电子科技大学 广西密码学与信息安全重点实验室,广西 桂林 541004
2.桂林航天工业学院 计算机科学与工程学院,广西 桂林 541004
1 引言
异常检测是一种重要的数据挖掘手段,它的目标在于发掘与大部分对象不同的对象,而这个异常的对象被称之为离群点或异常点。异常检测技术在欺诈检测、入侵检测、公共卫生、工业异常检测等领域有着重要的应用价值。早在1980 年,霍金斯就对离群点下了准确的定义,即:“离群点是一个观测值,它同其他观测值的差别如此之大,以至于怀疑它是由不同机制产生的[1]”。由该定义可知,离群点更深层次的意义在于其产生机制不同。
针对异常产生本质的不同理解,异常检测的方法大致可以分为基于统计、基于距离、基于密度、基于聚类、基于机器学习等类型。网格划分大多用于聚类,这类聚类算法首先将数据空间划分成有限数量的单元,从而形成一种网格结构,然后再在这种网格结构上进行聚类。经典的基于网格的聚类算法有STING[2]、WaveCluster[3]、CLIQUE[4]。由于聚类在网格上进行,而不是数据点,这类算法最大的优势是速度快。但是基于网格划分的算法需要解决两个问题,一个是网格的划分尺度问题,另一个是高维度的适用性问题。网格划分太密时,不仅计算量增大,而且每个网格内的点都几乎相等,无法区分离群点和非离群点,网格划分太稀疏时,同一个网格可能不光包含大量的非离群点,也包含离群点,无法达到良好的区分,在疏密交界处的网格这种现象尤为明显。同时,随着空间维度的增长,当维度较高时,即使是密度较大的区域,也会被(d-1)维的超平面分割而变得稀疏,导致算法无法区分疏密。
二分网格聚类的方法[5]从某种程度上克服了这两个问题,该方法每次对一个维度进行二分,循环划分,直到所有网格密度小于预先设置的密度阈值,再通过数据点从开始到停止划分所需要的划分次数来区分疏密(所需要的划分次数越多,数据点所处区域越密集,反之越稀疏)最终达到聚类的目的。该算法解决了网格划分尺度问题和高维度不适用的问题,但是该算法每次只划分一个维度,维度之间的相关性考虑较少,且该算法中的密度阈值参数仍然需要提前设定。参数自适应的网格密度聚类算法[6]针对网格尺寸和密度阈值的选取问题,提出了从噪声曲线中获取最优密度阈值的思路,可以自动设定密度阈值,但仍然需要人工从噪声曲线中识别最佳阈值。针对高维度数据,基于网格划分的算法一般在子空间上进行聚类。这类算法首先用传统的特征选取算法确定相关维度,然后在对应的子空间上聚类,不同的簇可能对应不同的子空间,每个子空间维度也可能不同,因此时间效率较低,经典的算法有PROCLUS[7]等。
网格划分技术应用于异常检测时,常作为辅助工具出现,传统的基于网格的异常检测算法通常与其他算法结合使用。GDLOF[8]、OMAGT[9]、FOMAUC[10]、ODAVG[11]以及最近的NLOF[12]等算法,大多将网格技术作为数据筛选工具,或将密集区域去除,或将稀疏区域取出,以提高算法的时间效率,再结合LOF等传统的异常检测算法在剩余网格或者剩余数据点上提取异常点。这类算法有很好的时间效率,但是这些算法对于异常的衡量是一次性的,只考虑了一种网格尺度下的异常值,与基于网格的聚类算法一样,它们无法回避网格尺度和密度阈值选取的问题,算法需要较为苛刻的选取密度阈值以适应不同的数据。为应对高维数据,与子空间聚类方法类似,子空间异常检测算法[13]通过在低维投影中查询异常区域来发现异常数据,这种方法可以很好地应对高维数据,但仍需要大量的算力来发现合适的子空间。RRGOD[14]结合粗糙集理论,通过一个属性重要度阈值,淘汰部分维度,再在降维后的数据上进行自适应的网格划分,淘汰高密度网格后用LOF 算法进行异常检测,该方法可以在保证精度的同时,显著降低LOF 的时间和空间复杂度,但仍需要人工设置属性重要度阈值和密度阈值参数。
本文提出的方法将多分辨率的网格技术引入异常检测,通过从稀疏到稠密的多分辨率的自适应网格划分避免了网格尺度参数的引入,同时提出一种局部异常值的计算方式,综合衡量了不同分辨率网格下,数据点的异常程度,并将所有尺度下数据点的局部异常值之和作为该点的全局异常值,在保证检测精度的前提下避免了网格尺度划分参数和密度阈值参数的引入。为了能够适应高维度数据,本文引入了一个子空间划分参数,将高维度切割成多个低维数据集处理,多分辨率网格划分在低维的子空间上进行。这样的子空间划分策略,既可以保证多分辨网格划分的高维度适用性,也避免了子空间查询花费大量的算力,使算法在较低的时间复杂度下完成异常检测。
2 算法介绍
2.1 传统网格划分方法
设A=D1×D2×…×Dm是一个m维的数据空间,算法的输入是n个m维的数据点,设为vi=(vi,1,vi,2,…,vi,j,…,vi,m),i=1,2,…,n,vi,j∈Dj,j=1,2,…,m。传统的网格划分算法需要输入一个网格尺度划分参数ε,将空间A每一维划分成相同的ε个区间,从而将整个空间分成εm个互不相交的矩形单元格,矩形单元格可以描述为u1×u2×…×um,其中uj=[lj,hj),j=1,2,…,m,均为一个前闭后开的区间。一个数据点vi=(vi,1,vi,2,…,vi,j,…,vi,m)落入一个单元格u1×u2×…×um中,当且仅当lj≤vi,j<hj成立,其中j=1,2,…,m。
这样的网格划分策略有以下两点不足:(1)整个空间分成εm个互不相交的矩形单元格,当数据维度高时,m偏大,网格单元数呈指数增长,导致时间效率降低;(2)参数ε需要人工选取,该参数鲁棒性差,太大或太小都会导致检测性能下降。
针对传统网格划分策略存在的不足,本文提出了基于多分辨率网格划分的异常检测方法,主要包含三个步骤:(1)子空间划分;(2)对每个子空间进行多分辨率网格划分;(3)计算每个数据点的全局异常值并输出异常值排序。
2.2 子空间划分方法
为了解决异常检测中数据的高维度问题,通常有两种解决方法,降维或划分子空间。降维技术将原始数据集的高维空间映射至低维空间,再在低维空间中使用传统算法进行异常检测,以保证异常检测算法的效率[15-16]。子空间技术将原始数据集划分成多个低维的子空间,每个子空间包含一个或多个维度,再在子空间上进行异常检测。基于子空间的异常点挖掘最重要的是选择包含异常点的子空间,然而在一个m维的数据集里,新维度的组合有2m种可能,子空间的个数随数据维度增加呈指数增长,这就需要有效的算法来寻找合适的子空间,典型的算法有Aggarwal 使用遗传算法寻找最优子空间[17],最近的算法有Gao Zhipeng的SRS[18]等。
为了保证算法的时间效率,以及对高维数据的适用性,本文引入了一个子矩阵划分参数d,一般d取值在10以内。将n×m大小的原始数据矩阵,划分成多个n×d大小的子矩阵,其中d≤m,最后一个子矩阵不足d的取余,即最后一个子矩阵大小为n×d',d'=mmodd,其余子矩阵大小为n×d。为表示方便,子矩阵的两种大小统一表示为n×d。
经过子矩阵划分的数据集,保留了原始数据的所有维度,不需要额外的算力来确定子空间的大小,高效地保证了该算法对高维数据的适用性。
2.3 多分辨率网格划分
为了解决网格划分参数和密度阈值需要人工选取的问题,本文提出的算法引入多分辨率网格划分自动适应数据。STING 聚类算法是经典的多分辨率网格聚类算法,它将空间区域根据不同的分辨率,划分成多个级别的网格单元,这些单元形成一个层次结构:高层的每个单元被划分为多个低一层的单元,递归划分,直到形成多个层次的网格结构。通过预先计算和存储每个网格单元的统计信息,包括总数、均值、最大值、最小值等,来预处理数据,然后依据这些信息自下向上的通过一个阈值来确定相关网格,最终达到聚类的目的。
如图1所示,多分辨率网格划分技术是一种空间划分技术,它将空间区域(以二维为例)分层递归的进行划分,形成多层矩形单元,每层矩形单元对应不同的分辨率,并构成了一个层次结构,每个高层网格在下一层被划分成4 个网格(2d个,d为维度),依次递归,直到达成某种终止条件才停止划分。此时的多分辨层次网格,从上到下,是一系列从稀疏到密集的网格单元,每层网格都对数据进行了一次划分,因此,数据被多个分辨率的网格单元划分。统计数据点在多种分辨率情况下的局部密度,即可在不需要设定网格参数的前提下得到数据点更为精确的全局密度。

图1 多分辨率网格划分过程
多分辨率网格的优势在于高层次网格划分所带来的误差,可以由低层次网格继续划分进行弥补,直到划分得足够细致。本文算法将多分辨率网格划分引入异常检测,以网格数近似等于数据点个数为终止条件,实现了网格的自适应划分。具体过程如下:
原始数据集大小记为n×m,被划分后的子矩阵大小为n×d,即n行d列的矩阵。首先对子矩阵所有维度进行二分,形成2d个网格,记为第一层,i=1。再在这2d个网格的基础上对所有维度进行二分,形成22×d个网格,记为第二层,i=2。依次递归,则第i次划分后的网格个数为2i×d个。为保证网格个数不超过数据点个数,令:

求得:


图2 网格划分过程
2.4 计算全局异常值
在进行网格划分后,需要计算每个数据点的异常值以确定最终的异常值排序。通常的方法是以单元格内数据点的个数近似表示数据的局部密度,将局部密度的倒数直接作为局部异常值,没有进行标准化处理,容易受数据量n的影响。CLIQUE算法用单元格中的点数除以总的点数作为局部密度,解决了这一问题。但CLIQUE算法只划分一次网格,局部异常值的计算方法不能直接用于多分辨率网格划分算法。为了适应多分辨率网格划分算法,本文提出的算法重新定义了局部密度,具体过程如下:
子矩阵编号记为k,子矩阵大小记为n×d,网格划分次数记为i(即第i层),某个网格的在某一层中的编号记为j。子矩阵k的第i层第j个网格内数据点的个数记为ck,i,j。本文提出的算法定义网格的局部密度为:

该公式用每个网格内的相对数据点个数,近似表示了该网格内数据点的密度。由于网格内数据点越少,表明该网格内数据点越稀疏,越有可能是异常点,所以数据点密度与异常值成反比,本文算法定义数据点p的局部异常值为:

任意数据点p的全局异常值是它在所有子矩阵内划分的每一层下所处网格的局部异常值之和,即:

接下来以500 个2 维数据点来解释这一过程,由于维度较低,直接令m=d=2,此时只有一个子矩阵,即数据集本身,因此k=1。
如图3 所示,只取典型的第二次和第三次划分为例。由第二次划分(即i=2)可知,数据集被均匀地分成16 个网格,在这16 个网格中,中间红色方框内的4个网格内数据点个数明显多于周围的8 个网格(例如6号网格的数据点个数明显大于2 号网格)。根据局部异常值的定义可知,网格内数据点越多,局部异常值越小,因此周围网格内数据点的局部异常值就会明显高于中间4 个网格的局部异常值。这样该算法就在16 网格的分辨率尺度上实现了一次异常检测。然而这样的检测比较粗略,以6 号网格为例,该网格左上角的数据密度明显小于右下角,但由于在同一网格内,因此并没有得到很好的区分。又因为i <I,I=5,不满足多分辨率网格划分的终止条件,所以网格还会进一步划分,这个问题会在64 网格的分辨率尺度(第三次划分)上得到解决。
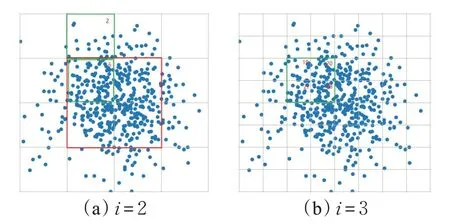
图3 异常值计算过程
如图3所示,i=3 时数据被均匀地划分在64个网格内,此时上一次没有得到精确划分的6号网格被划分为4 个区域,分别是19,20,27,28 号网格。在64 网格的分辨率尺度下,计算这4 个网格的局部异常值,根据局部异常值的定义可知19 号网格的数据点少于其他3 个网格,因此19 号网格的局部异常值会大于其他3 个网格。这样该算法就在64网格的分辨率尺度上又实现一次异常检测,与上一次的异常值叠加,就可以更细致地区分数据点的疏密区域(例如6号网格左上角的19号网格内数据点的异常值会大于6 号网格内的其他3 个网格,而小于红色区域外的8个网格)。依次迭代,直至i=I,累加得到的全局异常值会综合考虑多个分辨率的情况下的局部异常程度,可以很好地区分各个区域数据的疏密,以达到较高的异常检测精度。
2.5 算法步骤和伪代码
算法实现过程中用到的重要变量及符号定义如表1。

表1 变量及符号定义
2.5.1 算法步骤
输入:所有数据点组成的矩阵X=[x1,x2,…,xn]T,每个数据点x都是m维数据,X为n×m大小的矩阵;子矩阵尺度划分参数d,d≤m;异常点比例R%。
输出:算法判定所有异常点的编号。
步骤1子矩阵划分。将输入数据矩阵X划分成n×d大小的 ■nd■ 个子矩阵。
步骤2取一个子矩阵进行多分辨率网格划分。
步骤3按照公式(4)计算每个数据点的局部异常值,累加到该点的全局异常值。
步骤4判断是否所有子矩阵都已计算异常值,若全部计算完毕则继续下一步,若没有则转至步骤2执行。
步骤5对所有数据点按照全局异常值大小进行降序排列,并输出前R%的编号组成的异常数据集。
2.5.2 算法伪代码
算法本文算法
输入:原始数据集X,子矩阵尺度划分参数d,异常点比例R%。


2.6 算法时间复杂度
对于n×m大小的数据集,算法需要划分成■m d■个子矩阵。记每个子矩阵大小为n×d,d≤m,每个子矩阵进行次网格划分。每次网格划分遍历一次数据集(n个数据)。所以该算法的时间复杂度为:
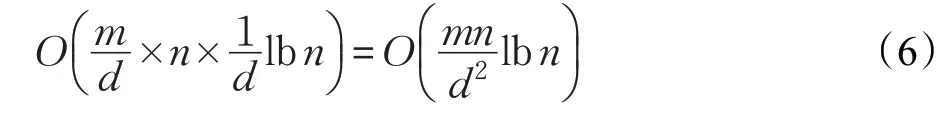
3 实验
实验基于Python3.7、VSCode 平台,计算机硬件配置为:Windows10操作系统、Intel Core i5-3230M CPU、2.6 GHz、4 GB RAM。
3.1 人造数据集上有效性验证
实验首先用人造数据集来验证算法的有效性,为了方便观察,本文用sklearn 库的datasets 工具创建了四组二维数据集(dataset 1,dataset 2,dataset 3,dataset 4)。四组数据集都是由1 700 个正常点和300 个异常点组成。dataset 1数据集的正常点部分是方差为0.5的二维高斯分布,dataset 2数据集的正常点部分是两个方差分别为1.5和0.3的高斯分布,dataset 3数据集的正常点部分是一对月牙形分布,dataset 4数据集的正常点部分是一对环形分布。实验结果如图4,橘色为算法输出的正常值,蓝色为算法输出的异常值。由图可知,算法可以很好地区分稠密与稀疏区域,并且可以对非凸数据集进行检验,从而达到了预期效果,验证了算法的有效性。
3.2 公开数据集上有效性验证
本文选用8个公开数据集验证算法的适用性,它们均来自ODDS网站,具体数据集信息如表2。
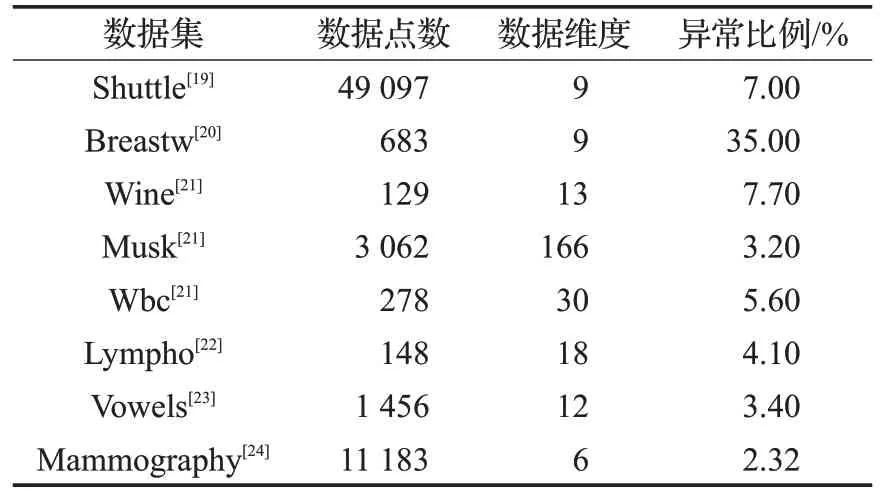
表2 数据集信息表
新算法在8 个公开数据集上实验的ROC[25]曲线如图5。

图5 新算法在不同数据集上的ROC曲线
由图5可知,算法在一些数据集上可以保证较高的真正率和较低的假正率,具有较好的异常检测效果,有一定的应用价值。
为了定量地分析算法的性能,本文对比分析了三种常用的异常检测算法,基于网格的Isolation Forest[26]算法、基于统计的Robust Covariance[27]算法和基于密度的LOF[28]算法,分别记为IF、RC、LOF,本文算法记为NA。其中IF 算法是最常用的基于网格划分的异常检测算法,RC 是经典的基于统计的算法且不需要预设参数,LOF 是经典的基于密度的异常检测算法。与经典的网格划分算法IF比较的目的是为了考察本文所设计算法和同类算法的性能对比,与三种不同类型的经典算法对比,是为了进一步考察算法的性能和算法的普适性。
各算法参数设置如表3。

表3 参数设置信息
主要性能指标为AUC 值(ROC 曲线所围的面积)、检测率TPR、误报率FPR和运行时间T(单位:s)。对于二分类问题,可以将真实类别和算法检测的类别组合划分为四种情况,如表4所示。

表4 混淆矩阵
FP是标记为正常但被检测为异常的点(False Positive),TN是标记为正常也被检测为正常的点(True Negative),FN是标记为异常但被检测为正常的点(False Negative),TP是标记为异常也被检测为异常的点(True Positive)。
检测率和误报率分别定义为:

从上述计算公式可以看出,检测率代表的是被正确检测出的异常点占所有真实异常点的比例,误报率代表的是被错误检测的正常点占所有真实正常点的比例。一个性能较优的异常检测算法有较高的AUC值和TPR,较低的FPR。由于异常检测数据集是典型的不平衡数据集,单纯的准确率不能很好地描述算法的性能,利用检测率和误报率两个指标来衡量,可以解决异常检测算法在不平衡数据上的度量问题,在不同异常检测算法对比时,可以有效地衡量算法的性能。
实验结果如表5。

表5 不同算法实验结果对比
由对比实验表5可以看出,本文提出的异常检测算法在Mammography、Shuttle、Wbc 三个数据集上具有比其他三种常用算法更好的检测效果,该算法在这三个数据集上有更高的AUC值和TPR,更低的FPR。该算法在其他五个数据集虽然检测效果不是最好的,但与最高值十分接近,例如数据集Wine,效果最好的LOF算法AUC 值为 0.999,而该算法 AUC 值为 0.989。上述实验还表明该算法可以有效地应对高维度的数据集,例如在166维的Musk数据集上,该算法表现良好。
由运行时间的对比实验可以看出,该算法在时间效率优于基于统计的Robust Covariance 算法。在高维度或大数据量的情况下(例如Mammography、Shuttle、Musk三个数据集)时间效率略优于LOF算法,低于Isolation Forest。在低维度小数据集上,时间效率略优于Isolation Forest,低于LOF算法。整体上,本文提出的算法在两个数据集上(Mammography、Vowels)时间效率优于其他三种传统算法,在其他六个数据集上仅次于一种算法,与对比算法相比,有一定的优势。
该算法需要预先设置子矩阵划分参数d,为了验证不同的子矩阵划分参数d对算法性能的影响,本文对比了不同d取值下,该算法在各数据集上AUC值的变化,实验结果如图6。
由图6 实验结果可知,即使d取值不同,该算法在多个数据集上AUC值依旧可以稳定保持在较高水平,说明d参数的选取对最终实验结果影响有限,该参数鲁棒性较好。
4 结语
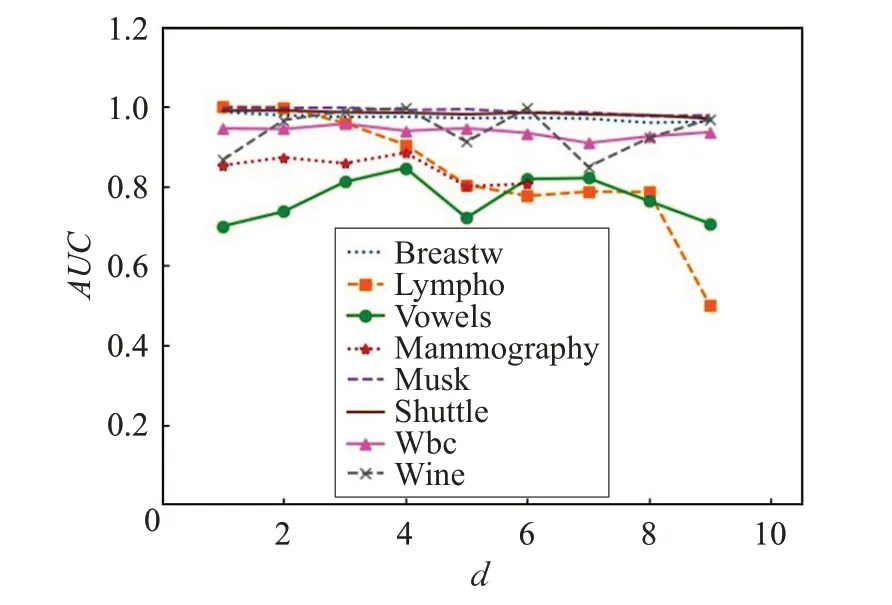
图6 算法在各数据集上不同d 取值时的AUC 值
为了避免传统的基于网格的异常检测算法网格划分尺度和密度阈值两个参数的选取,本文将多分辨率网格的概念引入异常检测,并相应地提出了一种局部异常值的计算方法,衡量了数据点在不同分辨率网格下的局部异常值,在较低的时间复杂度下,既保证了检测的精度,又避免了两个参数的引入。为了能够适应高维度数据,本文引入了一个数据尺度划分参数,将高维数据切割成多个低维数据集处理,实验表明,该参数具有良好的鲁棒性。为验证算法的检测效果,本文通过人造数据集上的实验证明了该算法的有效性,实验结果还表明该算法可以有效地检验多种形状的数据。多个公开数据集上的对比实验表明该算法具有良好的检测性能,能在多个应用场景下接近或超过现有的常用异常检测算法,有一定的适应性和应用价值。
