基于多层注意力机制的中文文本蕴涵识别方法
2020-09-04刘茂福胡慧君
严 明,刘茂福,胡慧君+
(1.武汉科技大学 计算机科学与技术学院,湖北 武汉 430065;2.武汉科技大学 智能信息处理与实时工业系统湖北省重点实验室,湖北 武汉 430065)
0 引 言
文本蕴涵通常是来判断两个文本之间的关系,在给定前提文本P(promise)和假设文本H(hypothesis)条件下,如果根据文本P可以推理出文本H是正确的,那么就认为这两个文本之间就存在蕴涵关系,如果推理出文本H是错误的,那么它们就是矛盾关系,如果相互之间没有关联,那么就是独立关系[1]。文本蕴涵识别对文本摘要、问答系统、语义检索等多项自然语言处理任务都非常重要[2,3]。文本摘要任务中可以使用文本蕴涵方法来精简文本内容,问答系统中可以利用文本蕴涵方法来判断问题和答案之间的因果关系。
目前文本蕴涵识别的方法主要分为3大类,第一类主要是采用传统机器学习的方法[4-6],例如计算词语相似度[7]的文本蕴涵识别、基于特征抽取的分类方法等;第二类采用句子编码的深度学习方法[8-10]来解决文本蕴涵问题,Bowman使用长短时记忆神经网络(long-short-term memory,LSTM)对句子进行编码,在数据集(Stanford natural language inference,SNLI)上可以达到77.6%的准确率,验证了深度学习在文本蕴涵识别任务的有效性;第三类为基于注意力机制[11-14]的方法,通过对假设句中的每个词与前提句中的词分别进行关系处理,来得到编码向量,这种方法可以捕捉到词语和短语级别的蕴涵关系,但是这类方法缺点在于都没有同时考虑到句子间词语与短语以及句子之间的交互匹配信息。
针对传统注意力机制无法捕捉句间交互信息和句子全局信息的问题,本文提出一种基于多层注意力机制的文本蕴涵识别方法,多层注意力的结合能提升句子在复杂语义上的表示,弥补单注意力的不足。采用双向长短时记忆神经网络(bidirectional long short-term memory,Bi-LSTM)对句子进行编码,这样可以自动提取文本的相关特征,避免了人工选择特征以及使用NLP工具造成的错误累计问题,使用自注意力[15](self-attention)得到句子的全局信息,更深层次的捕捉对句子语义有重要作用的词和短语,并且使用协同注意力(co-attention)得到句子间词语与短语交互匹配信息。然后采用最大池化和平均池化得到深度学习特征,最后再经过全连接层和SoftMax进行分类得到识别结果。
1 多层注意力模型
1.1 系统框架
本文利用较少NLP工具对文本进行预处理,然后利用神经网络自动提取文本特征,结合多层注意力机制得到文本的重要信息和文本之间的交互信息,最后经过全连接层和SoftMax分类器得到最终识别结果。系统框架如图1所示。
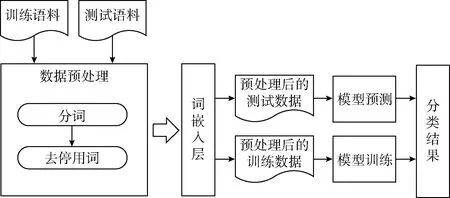
图1 模型框架
在数据预处理部分主要包含文本分词和去停用词两个模块。在文本分词这一模块使用了jieba分词对数据进行了分词处理,停用词会给文本的有效信息产生噪声干扰,而且停用词没有什么特殊的含义,比如“的”、“啊”、“哦”等词,这些词在语料中出现的频率较高并且很少能表达出语句的相关信息。为了减少停用词对语句造成的噪声干扰和不必要的运算量,文本在进行提取特征之前进行去除停用词处理。每个句子经过词嵌入层得到句子的句向量矩阵,然后在训练集上训练多层注意力模型,并选用SoftMax作为模型的分类器,最后利用训练好的模型预测测试集,得到测试集的分类结果。
1.2 网络结构
多层注意力机制的网络结构如图2所示。输入的文本首先经过词嵌入层被转化为向量形式,然后经过Bi-LSTM层提取文本特征,利用自注意力层获取文本的全局信息,接着采用协同注意力层得到文本间的交互信息,最后是融合层与池化层的融合与池化。自注意力层和协同注意力层相互作用来获取文本对的推理信息,经过拼接层、全连接层和SoftMax来得到文本之间的蕴涵关系。下面来详细介绍网络结构。
独热编码(one-hot)的方式词语与词语之间没有任何相关联系,难以捕捉到词语的句法和语义信息,并且当词库非常大时,浪费了大量的存储资源。不同于独热编码,词嵌入层是将预处理后得到的词语映射到向量空间中,并且将意思相近的词语分组映射到向量空间中的不同部分,让词语与词语之间能产生相应的关联,得到词语之间的内在关系。前提文本p=(wp1,…,wpi,…,wpm)和假设文本h=(wh1,…,whj,…,whn),经过词嵌入层转化为向量形式分别为ep=(ep1,…,epi,…,epm)和eh=(eh1,…,ehj,…,ehn),其中ep∈Rm×d,m表示前提文本的句子长度,d表示词向量的维度。
LSTM[16]是RNN(recurrent neural network)的一种变体,因为RNN在文本过长导致前面的文本信息几乎消失,不能很好解决文本信息的长期依赖问题,而且RNN在神经网络反向传播时容易造成梯度消失或者梯度爆炸等问题,所以许多研究人员都用LSTM神经网络代替RNN神经网络。与RNN神经网络不同,LSTM通过设置输入门、遗忘门、输出门来解决文本的长期依赖问题和RNN的损失函数关于时刻隐藏层变量的梯度比较容易出现消失或爆炸的问题。所谓的“门”,就是通过sigmoid激活函数输出一个0到1之间的数值,这样来表示信息得到通过的程度,1表示全部保留,0表示全部舍弃。
在文本蕴涵识别中,文本包含的语义不仅和之前的状态有关,也和之后的状态有关。LSTM只能记住文本的上文,但是触及不到文本的下文,这样对机器来说,不能很好判断整个的文本的含义,所以在LSTM的基础上提出了Bi-LSTM[17]。Bi-LSTM能够同时保留文本的“过去”和“未来”的信息,是真正利用了文本的上下文语义信息,使神经网络能更好提取文本特征。Bi-LSTM的神经网络结构如图3所示。

图2 网络结构

图3 Bi-LSTM神经网络结构
从图3中可以看出,X为输入序列,h为前向层的隐藏层节点,h′为后向层的隐藏层节点,Y为输出序列,Bi-LSTM模型是由两个LSTM模型上下反向叠加在一起组成的,总共分为4层,分别是输入层、前向层、后向层和输出层。其中,输入层和传统的神经网络结构一样,对应着文本数据的输入序列。前向层是一个由前向后传播的LSTM结构,后向层是一个由后向前传播的LSTM层,这两层的节点连接的都是输入层的节点和各层次中上一时刻的历史状态。输出层则是对应于输出序列的节点,由这两个LSTM模型的状态共同决定,将前向的LSTM的隐藏层和后向的LSTM隐藏层拼接在一起,作为这一时态的输出。当向输入层输入一个子句时,模型会分别从前向和后向两个方向进行运算,从而得到最后的输出序列。
本文将经过词嵌入层得到的句子向量形式经过Bi-LSTM可以表示为
hpi=Bi-LSTM(epi,hpi-1,hpi+1)
(1)
hhj=Bi-LSTM(ehj,hhj-1,hhj+1)
(2)
其中,epi表示当前词,hpi-1表示为文本的“过去”信息,hpi+1表示文本的“未来”信息,这样可以得到所有的隐藏层信息Hp=(hp1,…,hpi,…,hpm),同样的也能得到Hh=(hh1,…,hhj,…,hhn),并对所有隐藏层进行对齐处理。
注意力机制来源于人类的视觉研究,由于信息处理的瓶颈,人们总是选择性的关注信息中最在意的一部分,同时忽略掉其它不关心的信息,把有限的计算资源给最重要的部分。自注意力(self-attention)在自然语言处理领域已经成功的应用在机器翻译,它通过对Bi-LSTM的输出进行选择性的学习并且与输出序列进行关联,这样能突出文本中的重要信息,忽略文本中的冗余信息,从而能更好表征文本信息,进而得到文本的全局信息。具体计算公式如下所示
upi=tanh(Wwhpi+bw)
(3)
(4)
Vp=∑iαpihpi
(5)
式中:Ww与bw为注意力模型的可调节权重和偏置项,tanh为激活函数,hpi是Bi-LSTM层的输出,uw也是权重值,计算的结果αpi表示句子中每个词的重要度信息;Vp即为前提文本经过注意力模型计算后的输出向量。同理也可以计算出假设文本经过注意力模型计算后的输出向量Vh。
本文采用协同注意力(co-attention)来得到两个句子之间的交互信息,并且在两个句子相互时考虑到了单词顺序和句子的上下文信息,这样能够将两个句子看成一个句子来进行语义蕴涵分析,而不是把每个句子都独立的编码成一个语义向量,这种方式可以捕捉到成对单词和短语之间的蕴涵关系。具体计算公式如下所示
(6)
(7)
(8)
(9)
(10)


(11)
(12)
(13)
(14)
其中,[;]表示把各个隐藏层拼接在一起,表示对应元素相乘,所以fp=(fp1,…,fpi,…,fpm)。同样的方法可以得到fh。
池化能很好减少特征提取过程中的误差,常见的池化有最大池化和均值池化,最大池化能减少隐藏层参数的估计值均值偏移,而均值池化能减少隐藏层的估计值方差增大。本文采用最大池化和均值池化的方法来得到句子最有用的特征信息
(15)
(16)
然后将前面的自注意力层得到Vp和Vh的与池化后的结果进行拼接
V=[fpave;fpmax;Vp;fhave;fhmax;Vh]
(17)
本文使用两层前馈神经网络,第一层前馈神经网络使用非线性激活函数为tanh,第二层前馈神经网络使用的归一化函数SoftMax分类器输出每个类别的预测概率
U=tanh(W1+b1)
(18)
P(y|p,h)=SoftMax(W2U+b2)
(19)
其中,W1和b1为第一层前馈神经网络的权重和偏置项。W2和b2为第二层SoftMax层的权重和偏置项。由于SoftMax的输出结果是一个概率分布,需要衡量和真实标签的差异,就是训练过程的损失,所以训练过程的目标为最小化交叉熵(cross entropy)损失函数,其公式如下所示

(20)

2 实 验
实验环境。本文实验的硬件环境为NVIDIA-GTX1070,CPU为Inter i5-7500,内存为8 G,软件环境操作系统Ubuntu16.04,编程语言为python。
2.1 实验数据与评价指标
本文使用CCL2018中文文本蕴涵测评任务的数据集(chinese natural language inference,CNLI)进行实验,并且还在NTCIR-9 RITE数据集上测试了本文模型泛化性。CNLI数据集用于训练的数据有90 000条,验证数据10 000条,测试数据10 000条,3种类别的数据比较平衡,数据具体分析统计见表1。

表1 CNLI数据集分析
NTCIR-9 RITE数据有1221条,其中包括正向蕴涵关系、逆向蕴涵关系、双向蕴涵关系、矛盾关系、独立关系,经过处理后,将类别标签处理为蕴涵、矛盾、独立3种关系。
评价指标选取准确率(Accuracy)来判断模型的识别效果的好坏
(21)
其中,accNumber表示预测正确的数量,N表示是测试集中文本对的总数量。
2.2 参数设置
本文采用预训练好的300维glove中文词向量,学习率设置为0.0003,dropout设置为0.2,batch size设置为32,Bi-LSTM和自注意力的隐藏层个数都设置为300维。优化方法采用的Adam。主要超参数见表2。

表2 参数设置
2.3 实验结果分析
为了验证本文设计的模型对中文文本蕴涵识别任务的有效性,还实现了Siamese模型[18]、ESIM模型[19]。各模型的在CNLI数据集准确率对比见表3。

表3 CNLI数据集上的模型比较/%
(1)Siamese模型:通过两个Bi-LSTM共享权重来比较两个句子的文本相似度方法。
(2)ESIM模型:通过句子间的注意力机制来实现局部推断,再利用局部推断得到全局推断。
(3)多层注意力模型:本文提出的模型。
从表3中的实验结果可以看出,对比Siamese模型,这个模型通过共享两个句子神经网络参数来得到两个文本的相似性,没有考虑到短语之间的匹配,在测试集上的准确率为68.48%,ESIM模型在SNLI上有很好的表现,用对齐注意力匹配字与字以及短语之间的匹配,在测试集上的准确率为72.22%,比Siamese模型提高了3.84%,但是ESIM模型没有考虑到句子的全局信息的整体匹配。
多层注意力模型利用自注意力来获取句子的全局信息,并采用协同注意力来得到句子间的局部信息和推理结果,在测试集上的准确率为73.88%,比Siamese模型提高了4.90%,比ESIM模型提高了1.66%。
表4中列为预测类别,行为真实类别,从各模型的混淆矩阵可以看出,蕴涵(entailment)类别的识别效果最好,其次是矛盾(contradiction)类别,独立(neutral)类别识别较差。
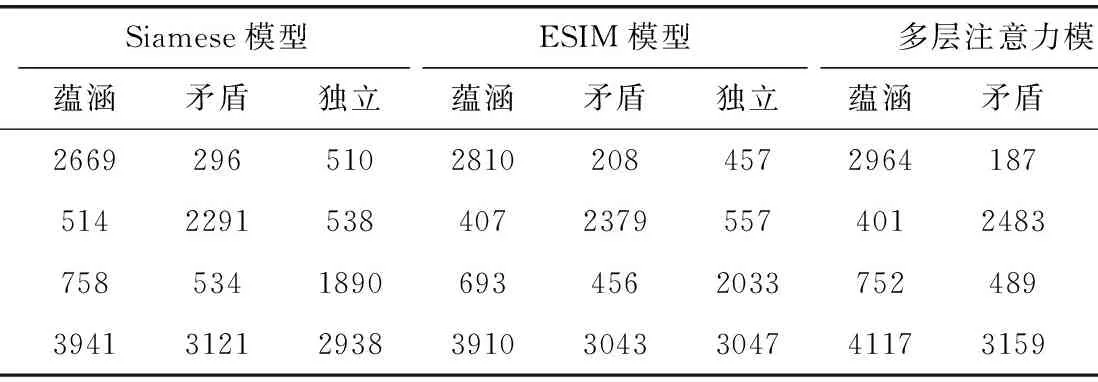
表4 各模型在CNLI数据集上的混淆矩阵
例1:
前提:两名男子正在谈论一顿饭。
假设:两名男子在晚餐时谈论政治。
类别:独立。
从例1可以看出两个文本相似之处比较多, “两名男子”、“谈论”都出现在前提文本和假设文本中,并且出现位置也是一样的,这样会使模型认为蕴涵的概率大一点,而前提文本的谈论“一顿饭”和假设文本的谈论“政治”更像是矛盾的,“正在”和“在晚餐时”将前提文本和假设文本从时间和空间上相互独立,所以抛开相似文本和矛盾文本的干扰,所以此类别为独立。这类文本的深层语义信息难以捕捉,从而导致各模型错误的识别。
例2:
前提:一只大白狗和一只小黑狗坐在雪地里。
假设:地面上有积雪。
类别:蕴涵。
在例2中,Siamese模型和ESIM模型均错误的识别成了独立,而多层注意力模型正确的识别出了两个文本之间的蕴涵关系。由于两个文本从词与词的相似度匹配,无法得到准确的识别结果,所以错误判断成了独立,而多层注意力模型不仅从词与词的角度进行匹配,并且借助全局匹配信息能正确的判断出两个文本之间的蕴涵关系。该结果也表明多层注意力在中文文本蕴涵识别上的有效性。
使用CNLI数据集上训练出来的模型,针对NTCIR-9 RITE数据集,本文将训练集、验证集和测试集合并,一共1221条数据全部作为测试集。该模型在NTCIR-9 RITE数据集上的准确率为67.63%,而SVM模型则选择976条数据作为训练集,245条数据作为测试集,最后SVM模型在245条数据上的准确率为62.44%。见表5。表6为多层注意力模型在NTCIR-9 RITE数据集的混淆矩阵。其中列为预测类别,行为真实类别。从表6可以看出,用CNLI上训练好的模型可以很好识别出NTCIR-9 RITE数据集上的蕴涵关系,而矛盾关系和独立关系识别效果不太好。这也说明该模型在其它中文文本蕴涵数据集上也是有效的。

表5 NTCIR-9 RITE数据集上的模型比较/%
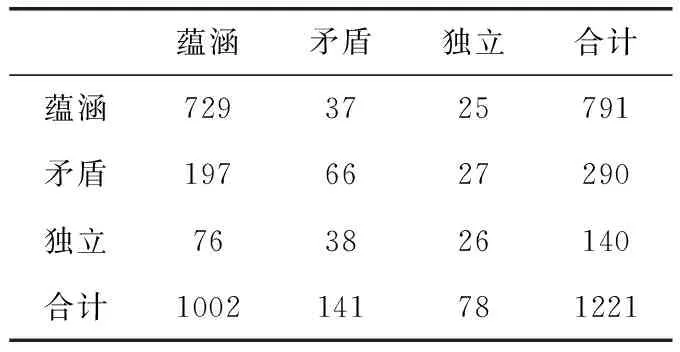
表6 多层注意力模型在NTCIR-9 RITE 数据集上的混淆矩阵
3 结束语
本文提出了一种基于多层注意力的中文文本蕴涵识别方法,首先中文文本对用词向量表示,并通过Bi-LSTM获取子句上下文语义特征,同时该方法中用自注意力提取了每个子句的全局信息特征,并使用协同注意力融合了句子间的局部信息特征,有效地解决了句间交互信息和全局信息的问题,进一步提高了中文文本蕴涵识别方法的准确率。在CCL2018中文文本蕴涵测评任务的数据集CNLI上准确率到达了73.88%,并且在NTCIR-9 RITE数据集上的准确率为67.63%。实验结果也验证了该方法对中文文本蕴涵识别的可行性和有效性。
在未来工作中,可以引入知识图谱和外部语义知识来优化网络,提高文本蕴涵识别的准确率,因为当提取出来的信息特征存在某些关联关系及层次结构时,这是模型识别不到的。
