基于数据筛选的硬盘剩余使用寿命预测方法
2020-09-04马连志
邓 玲,陕 振,马连志
(中国航天科工集团第二研究院 706所,北京 100854)
0 引 言
硬盘故障是存储系统的主要故障之一,影响着存储系统的可靠性。为了获得好的故障预测结果,学者们利用smart数据和人工智能算法进行故障预测,并采用二分类[1,2]、健康度[3,4]和剩余使用寿命[5,6]来度量硬盘健康状态。相比于前两者,剩余使用寿命的预测方法更有助于存储系统的运维管理,本文主要研究预测硬盘剩余使用寿命(remaining useful life,RUL)的方法。
Lima等[5]使用深度RNN、LSTM和CNN网络对硬盘剩余使用寿命进行预测,验证了硬盘剩余使用寿命是可预测的,但精度上不能满足存储系统的实际需求。Anantharaman等[6]分析了LSTM网络和随机森林预测器对硬盘RUL回归预测的效果,发现随机森林的预测更加精确。但本文发现在扩大取样时间窗和增多硬盘数量后,运用随机森林却达不到预测效果。本文针对这一问题,提出了一种基于使用寿命长短划分数据集的方法,将使用寿命大于一定阈值的硬盘作为预测目标,具有更好的预测效果。
同时,存储系统更加关心硬盘在临近失效时的剩余使用寿命变化。有学者为提高模型在硬盘临近失效时的预测精度,采用“Piece-wise”的预测方法[6,7],能在一定程度上提高预测精度,但因分段函数奇点的存在对预测结果会产生较大波动。本文提出一种基于硬盘健康状态相似度算法,根据硬盘状态之间的相似度对训练集进行数据筛选,为待预测盘提供专有的预测器,以此提高预测精度。
1 相关原理
1.1 随机森林
随机森林(RF)[8]是一种基于多个决策树的集成学习方法。它是由多个基于决策树构建的评估器结合而成。随机森林从原始的数据集中采取有放回的抽样,构造子数据集,并用子数据集构建决策树。当在决策树的构造过程中分离一个节点时,未用到所有的待选特征,而是从所有的待选特征中随机选取一定的特征,之后再在随机选取的特征中选取最优的特征。由于这种随机性的原因,随机森林能得到更好的预测正确率以及减轻过拟合现象的发生。随机森林既可用作分类器,也可以用于回归分析。在本文中,随机森林用作硬盘剩余使用寿命的回归预测器。
1.2 MDA算法
硬盘报告的Smart数据是多维的,每一个特征对训练结果的精度影响程度不一,不同特征的重要性不一样。计算特征的重要性算法有多种,本文采用基于随机森林的平均精确度减少(mean decrease accuracy)算法(MDA算法)。
MDA算法主要方法是通过打乱每个特征的特征值顺序,度量顺序变动对模型的精确率的影响,以此计算特征的重要性。对于一棵树,用OOB样本(袋外数据)可以得到精度I1,然后随机改变OOB中的第j列,保持其它列不变,对第j列进行随机的上下置换,得到精度I2。用I1-I2来刻画特征j的重要性。其依据就是,如果一个特征很重要,那么其变动后会非常影响预测精度,如果预测精度没有怎么改变,则说明特征j不重要。VI(variable importance)计算公式[9]如式(1)所示
(1)

1.3 回归预测评价指标
回归模型效果的判断指标有多种,本文选取均方根误差(RMSE)和决定系数(R-square)来描述模型的优劣。RMSE计算如式(2)所示,RMSE能直观描述预测精度,是预测模型在应用时重点关注的,它的值越小表示预测曲线和真实曲线越接近。R-square的数学表达如式(3)所示,分母为原始数据的离散程度,分子为预测数据和原始数据的误差,二者相除可以消除原始数据离散程度的影响。R-square是通过数据的变化来表征一个拟合的好坏,理论上R2取值范围是(-∞,1],正常取值范围为[0,1]。R2越接近1,表明方程的变量对y的解释能力越强,这个模型对数据拟合的也较好;R2越接近0,表明模型拟合的越差
(2)
(3)
1.4 信息增益与信息熵
“信息熵”[10](information entropy)是度量样本集合纯度最常用的一种指标,样本集合D的信息熵计算方法如式(4)所示,Ent(D)的大小代表了集合的无序程度,越大代表集合越无序。在划分数据集前后信息发生的变化称为信息增益,如果用熵度量数据集集合的信息,则信息增益为数据集划分前后其对应集合熵的变化
(4)
其中,pk表示集合D中第k类样本所占的比例。
2 数据集划分
2.1 数据集
Backblaze公司收录了其数据中心从2013年4月至2019年9月30日超过10万块数据硬盘的smart数据[11],该数据集是做硬盘故障预测最常用的开源数据集。每一条结果包含设备的序列号、型号、容量、故障和90个smart属性的信息。根据Backblaze数据中心的报告,如果设备停止工作(不运转或不接收命令),或者如果属性5、187、188、197或198的智能自检失败,则设备将被标记为故障。大多数型号的HDD不报告所有smart属性。在这种情况下,未报告的值留空。此外,不同的制造商和设备型号可能会报告不同的属性。为充分验证模型效果,选取故障盘数量较多的希捷ST4000DM000盘作为实验对象。从2013年至今,共失效3724块,数据集选取了其中2015年1月至2019年6月发生故障的3097块硬盘的smart数据作为训练和验证集。
在实际系统中,训练集和待预测数据是相互独立的,因此对训练集和验证集进行划分时需要以盘为最小单元,才能真正验证出模型的可用性。本文对发生故障的3097块硬盘,按8∶2的比例分给训练集和验证集。
2.2 随机森林模型预测缺陷
组件或系统的剩余使用寿命(RUL)定义为从当前时间到使用寿命结束的时间[12],因此参与训练和验证的样本必须是已经发生故障的硬盘报告的smart信息。对于已经发生故障的硬盘,其剩余使用寿命变化趋势是一条随着使用时间增大而减小的直线,并在硬盘失效时减小到0。
Anantharaman等[6]在2016年10月到2017年12月期间失效的100块硬盘的数据集上进行实验,但根据Backblaze公司的统计数据[13], 在该段时间内型号为ST4000DM000共有1274块硬盘发生故障,不能明确Anantharaman等的数据集。将该段时间发生失效的1274块硬盘按8∶2划分给训练集和验证集,即是训练集1020块硬盘、验证集254块硬盘。利用随机森林对训练集进行学习,发现通过调参后预测器产生的预测结果的均方根误差(RMSE)为155.45,并且随着训练集的逐步增大,预测器对同一个验证集的RMSE逐步增大。如表1所示,训练集train0、train1、train2是随着采样时间窗口扩大和硬盘数量增多逐渐增大的,它们构建的预测器出现欠拟合现象,并且随着训练集增大,欠拟合现象越来越严重。训练集采样时间窗口大小严重影响预测器的预测效果,这说明了Anantharaman等简单的运用随机森林对硬盘剩余使用寿命进行预测是不可取的。

表1 不同预测器对验证集的预测结果
2.3 使用寿命与预测精度
预测器出现欠拟合的直接原因是训练集中新加了数据,特征的取值有所不同,利用MDA对训练集trian0进行特征重要性分析,结果如图1所示。smart_9_raw记录了硬盘累计通电时间,该数值直接累计了设备通电的时长。图1表明特征smart_9_raw的重要性高于90%,对预测结果有决定性的作用。而从表1看,训练集最大的不同是采集的时间跨度,硬盘失效越晚,使用寿命就越长,smart_9_raw的取值范围越大。因此考虑训练集中硬盘寿命长短对训练结果的影响,在大型存储系统中,硬盘从上机到发生故障期间不轻易断电,因此设备通电时长和使用时长几乎相等,如果定义硬盘最大通电时间为硬盘失效时的通电时间,则硬盘的使用寿命为最大通电时间。图2是表1中各个训练集中硬盘使用寿命分布情况,可以看出随着采集时间跨度的增大,使用寿命分布的轴心不断右移,由于这种变化导致预测器的预测效果越来越差。

图1 特征重要性

图2 不同数据集中硬盘使用寿命分布
2.4 熵与数据集划分
2.2节证明了数据集增大会降低预测器的预测精度,但同时也表示了如果通过某种方式对数据集进行划分,在小的数据集上,预测器会有好的表现。为了验证硬盘使用寿命分布对预测结果的影响,找到一种数据集分割方式,借鉴决策树构建构过程中的数据集划分策略[10],找到最优特征划分数据集。数据集的无序程度可以用熵来度量,选择最优特征对数据集进行分割,目的是将无序的数据变得更加有序,在按特征划分数据集时,划分前后熵减小最多的特征就是最好的选择。将硬盘使用寿命life作为特征加入到数据集中,为配合算法,使得结果更加明显,对数据集数据进行二值化,得到的结果见表2,表中特征栏由特征ID表示,从表中可以看出数据集划分过程中只有特征9(smart_9_raw)、241(smart_241_raw)、242(smart_242_raw)、life有信息增益,特征life是最优分割的特征,按照硬盘使用寿命长短进行数据集划分能提高数据集的有序程度。
2.5 预测目标的选取
在实际系统中,硬盘设计的使用寿命在3年以上,存储系统出现大规模硬盘失效一定是在运行了一定年限后,新盘出现故障的概率非常小。Backblaze数据中心在2019年6月30日,共19 569块正常运转的硬盘通电时长分布如图3所示。从图中可以看出,99.9%硬盘的通电时长大于900天,这表明在这些硬盘中,至少99.9%的硬盘的使用寿命大于900天。2015年1月至2019年6月发生故障的3097块希捷STM4000DM000硬盘,其使用寿命分布规律如图4所示。Backblaze数据中心的希捷STM4000DM000硬盘年统计数量见表3[14],由表3知,在2015年至2019年间,硬盘年平均数为27 712块,因为硬盘数量变动较大,用年平均数代表硬盘总数。而由图4知2015年至2019年间发生故障的盘使用寿命低于900天硬盘的数量为1659块,约占硬盘总数的5.99%,符合实际系统中硬盘失效情况。
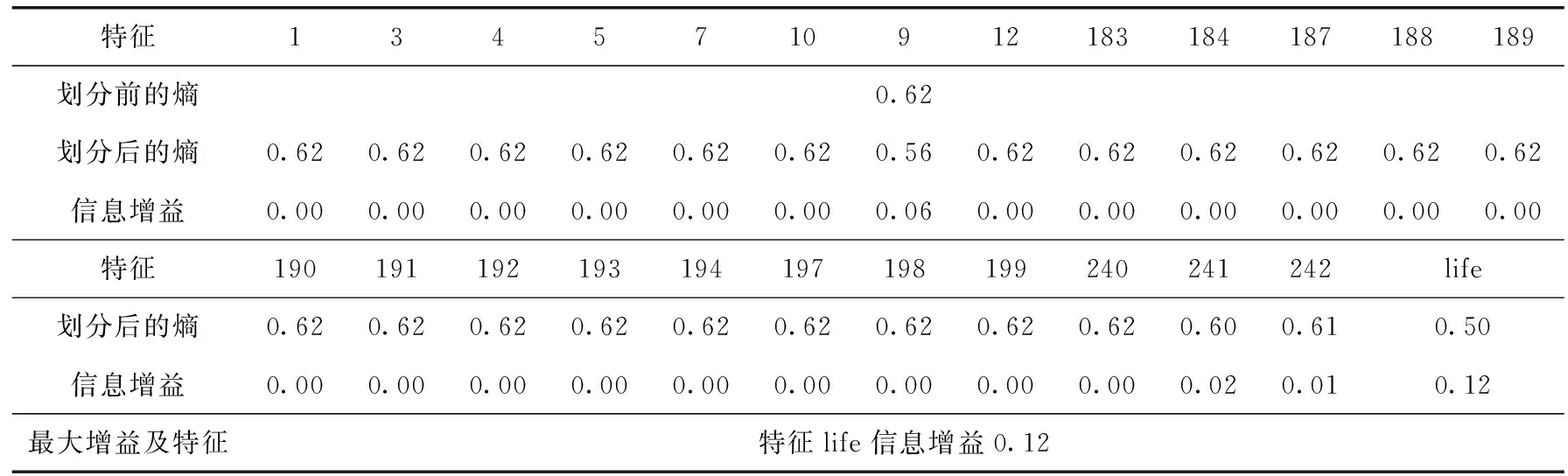
表2 按特征划分数据集集合前后熵的变化
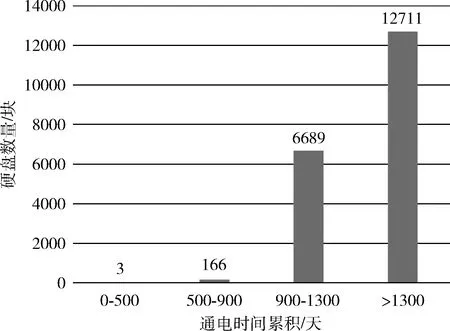
图3 2019年6月30日硬盘累计通电时长统计

图4 数据集硬盘使用寿命统计

表3 年硬盘数量统计
按使用寿命的长短对数据集进行划分后,信息增益表明,划分出的子数据集构建的预测器只对寿命在同一区间的硬盘有较好的预测效果。而对于一块待预测剩余使用寿命的硬盘,其使用寿命是未知的,这就造成了不知道用哪个子数据集构建的预测器对该硬盘进行预测。因此需要选择一个合适的划分点,使得预测目标占主要地位,而硬盘使用寿命大于900天的硬盘数占总硬盘数的94.01%,将预测目标选为使用寿命大于900天的硬盘满足实际需求。
3 临近失效预测优化
3.1 算法描述
在实际应用中,人们更加关心在硬盘临近失效时预测模型的预测精度,准确的预测才能对存储系统的运维有帮助。在临近失效状态下,存储系统对剩余使用寿命更加敏感,若实际剩余使用寿命(RUL)为50天,而预测值大于实际值50天,则预测结果表明硬盘还很健康,预测模型起不到作用;若实际RUL为100天,而预测值小于实际值90天,则存储系统会进行故障处理,造成资源的浪费。因此需要提高剩余使用寿命较小时的预测精度,最简单、有效的提高预测精度的方法是减少训练集里的噪声。通用的预测器已经得到了硬盘大致的剩余使用寿命,在硬盘的RUL低于一定阈值时,就可以进行训练集去噪,本文提出一种硬盘健康状态相似度的计算方法,通过按相似度大小筛选数据,减少训练集里的噪声。
3.2 改进的MDA算法
硬盘按一天一次的频率报告smart数据,相邻一天或几天的数据相差较小。利用MDA算法时,随机森林构建树的过程中随机选取数据集中的样本,剩下的袋外数据(OOB)都能在被选取的数据中找到与其接近的样本,同一硬盘的数据被打散了,因此在利用MDA算法求特征的重要性时,并不能体现硬盘是一个整体这一特性,对于一些特征的重要性计算和实际有所差别。基于硬盘报告的smart序列是以硬盘为基本单元的这一思想,将袋外数据改换为验证集数据,并对式(1)作了修改,特征重要性VI计算方法如式(5)所示。根据式(5),重新计算特征的重要性如图5所示,对比图1和图5,特征的重要性变化很大,但重要的特征基本未变
(5)
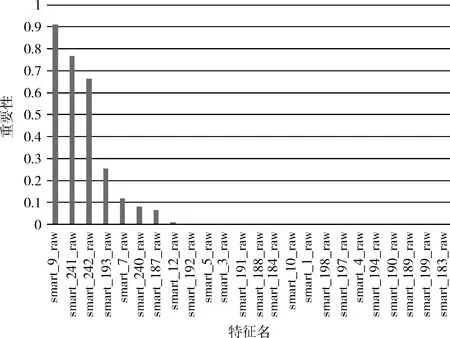
图5 修正的特征重要性
3.3 健康状态相似度
硬盘健康状态由好变坏是一个过程,剩余使用寿命接近的硬盘健康状态更为相似。硬盘的smart数据是时间序列,采集数据的时间跨度、硬盘的使用寿命不一样,得到的序列长度也不一样。利用硬盘通电时间累计统一时间轴,基于欧式距离给出在t时刻两硬盘状态的相似度如式(6)所示。当硬盘的剩余使用寿命小于设定阈值时,硬盘的剩余使用时间也即将告罄,利用硬盘状态相似度针对性的为预测目标匹配出相应的训练集并训练出预测模型,以便更精准预测
(6)

4 实验与分析
4.1 数据处理
希捷ST4000DM000硬盘的smart特征经过数据清洗后有23个特征可参与训练,由于随机森林预测器具有不需要进行特征选择的优点,将23个特征全部用于训练。这些特征值域范围很广,采用式(7)的归一化方法,将特征值值域归一化到区间[0,1]上,以便提高模型的收敛速度和预测精度
(7)

4.2 训练集分割与预测效果
在2.5节中,明确了预测目标是使用寿命大于900天的硬盘,而不同训练集的划分方法影响预测精度。由图4知,硬盘的使用寿命分布在各个时间区间里,取值范围为[0,+∞), +∞代表了未知大小。预测目标的使用寿命取值范围为[900,+∞),研究寿命小于900天硬盘的数据对预测寿命大于900天硬盘剩余使用寿命的影响,则训练集取值范围为[x,+∞)。调节训练集分割起始点x的值将得到不同的训练集,不同训练集构建的预测器有不同的精度,表4给出了数据分割策略。
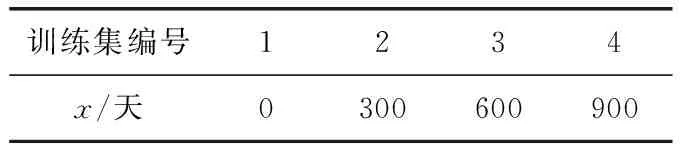
表4 训练集分割策略
按表4进行训练集分割,验证集包含了287块硬盘的历史smart数据,其预测结果的RMSE见表5,决定系数变化如图6所示。由表5知,分割点不同的训练集,生成预测器的预测结果精度差距大,分割得到的数据集中硬盘的使用寿命分布和验证集越接近,预测精度越高,这和利用信息增益的验证方法得到的结果一致。当分割点取到0时,预测结果的RMSE达到了293.98,这表明不进行数据集分割的预测效果是很差的,简单的利用随机森林预测硬盘剩余使用寿命的方法是不可行的。图6也表明了模型的决定系数(R2)随着分割点靠近900天而增加。图7是在分割点为900天,RMSE为104.97天时,随机森林预测器对硬盘序列号为S300XRSS的预测结果,图中横坐标是使用时间,纵坐标是硬盘剩余使用寿命(RUL),可以看出预测曲线和真实曲线十分接近。

表5 训练集不同分割点对应的RMSE

图6 决定系数随分割点变化趋势

图7 S300XRSS的RUL预测曲线和实际曲线对比
4.3 临近失效状态优化
在硬盘临近失效时,通常有两种处理方法。第一种方法是不对数据集做任何处理,公平对待数据集里的样本。第二种方法是采用“Piece-wise”算法,即是预测的目标函数是一个分段函数,剩余使用寿命在阈值之上为常数,在阈值之下为线性函数,目标函数会有奇点存在。与前两种处理算法不同,本文采用筛选训练集的方式提高硬盘临近失效时预测模型的精度。
若设降噪开始的阈值为200天,当某一硬盘的剩余使用寿命(RUL)低于200天时,计算该硬盘和训练集包含的硬盘之间健康状态相似度,按从大到小排列,选取前50%(可根据硬盘数量调整比例)对应的硬盘数据组成新的训练集,新训练集生成的预测器是该硬盘独享的。表6是统计了50块硬盘,对比普通预测、分段预测和进行训练集筛选3种方式在硬盘临近失效时预测结果,由表6知,训练集筛选能较大提高模型在硬盘临近失效时的预测精度。

表6 训练集筛选前后预测对比
仍旧对S300XRSS硬盘RUL进行预测,其预测曲线和真实曲线如图8所示。图8中画圈的地方是RUL小于200天后,进行训练集降噪得到的结果。和图7相比,图8的预测结果更接近真实值,达到提高精度的目的。
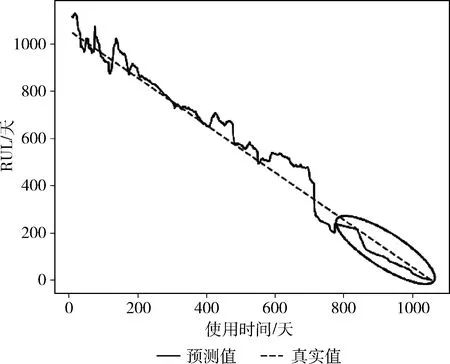
图8 S300XRSS的RUL预测优化结果
5 结束语
实际存储系统中,硬盘在长时间使用后,故障开始增多,准确的故障预测有利于存储系统的运维。本文明确了预测目标,与其它无差别预测不同,本文只考虑使用寿命大于900天硬盘,即运行900天不失效的硬盘的剩余使用寿命预测。针对这一类盘,着重研究了使用寿命在不同范围的训练数据对随机森林预测器预测效果的影响,发现当训练集为与其寿命相近的盘的数据时,预测效果最佳,这说明使用寿命接近的硬盘健康状态变化更加相似。在此基础上,针对剩余使用寿命较小即硬盘临近失效时,提出训练集降噪的方法,有效提升了预测精度。
