基于蒙特卡洛树搜索的符号回归算法
2020-09-04鲁强,张洋
鲁 强,张 洋
(1.中国石油大学(北京) 石油数据挖掘北京市重点实验室,北京 102249;2.中国石油大学(北京) 地球物理与信息工程学院,北京 102249)
0 引 言
符号回归[1]问题是“在符号空间中寻找合适的公式,以使得它能够描述指定的数据集”。目前解决符号回归问题的常用算法是基于进化思想Genetic Programming-GP算法[2]。它将种群中每个个体表示为一个公式,通过个体之间的交叉、变异和选择等操作,在符号空间内寻找适应度最优的公式。由于这些操作仅是根据初始概率来随机改变种群个体,因此GP算法存在以下的问题:①不能利用数据集的特征(例如周期性,对称性等)来构建和搜索合适的个体,从而导致搜索过程过长,搜索效率较低;②不能保存和利用已搜索空间的信息,从而导致容易陷入局部最优。
针对上述问题,文献[3]使用深度学习指导GP算法种群个体的初始函数选择,减少GP算法的搜索范围;文献[4]使用强化学习动态优化进化算法参数,使得算法更易跳出局部最优;文献[5]优化了GP算法种群的初始化方法,减小了陷入局部最优的可能。但是以上改进还是基于演化计算本身的改进,不能从根本上克服上述的两个问题。
为了更好解决GP算法存在的上述问题,本文提出了一种基于深度学习[6]的蒙特卡洛树搜索[7]符号回归算法(MCTS-SR)。MCTS-SR算法首先将待搜索的符号空间划分为两个不同层次的子空间:模型空间和系数空间。本文使用模型空间树表示模型空间,树中添加的节点为已经搜索过的公式模型。由于系数空间巨大,本文并没有单独对系数空间进行保存和划分,仅是在每个公式模型下保存了其最优的系数。
然后,根据数据集特征,将在模型空间中搜索(生成)公式模型的过程看作一个强化学习过程。将数据集和模型空间树中的节点作为生成公式模型的当前环境,利用强化学习中的策略函数π来选择合适的基本符号(+、-和*等)以生成下一个公式模型。为生成此策略函数π,本文提出一种基于卷积神经网络(convolutional neural network-CNN)和循环神经网络(recurrent neural network-RNN)的深度策略网络。该网络使用CNN来获取数据集的空间特征;使用RNN来获取公式模型的序列特征;使用全连接层将上述两类特征进行融合,并与基本符号建立映射。通过使用该网络来指导并生成下一个公式模型。
最后,将蒙特卡洛树搜索过程看作模型空间的探索与利用问题。根据上述深度策略网络的输出和当前节点的搜索次数,使用上置信算法[8](upper confidence bound-UCB1)来指导对模型空间的搜索。同时在生成一个新公式模型(新节点)后,使用粒子群算法[9](particle swarm optimization-PSO)在该公式模型的系数空间内寻找最佳系数,以得到最能描述数据集的公式。
1 背景知识
1.1 特征提取
蒙特卡洛树搜索[10](Monte Carlo tree search-MCTS)是在决策空间中通过随机取样寻找最优决策并建立搜索树的方法。本文使用MCTS算法来解决模型空间搜索问题。MCTS算法可以在只有基本规则的情况下对搜索空间巨大的问题进行有效搜索,而不需要领域内的经验辅助。MCTS算法主要流程分为4步:
第一步,选择:在选择阶段需要根据当前蒙特卡洛树状态依次选择当前最适合拓展的节点,直到达到树的终结节点;第二步,拓展:把第一步选中的尚未添加到蒙特卡洛树中的节点添加到蒙特卡洛树中;第三步,模拟:根据每一个节点的适应度函数得到一个该节点的评分,适应度函数越小则该节点评分越高;第四步,反向传播:在模拟过程结束之后,更新此次搜索过程中节点的状态。
因为MCTS算法的搜索次数有限,不能搜索到树中的每一个节点,所以存在空间探索与利用冲突的问题,其中探索是指搜索新的区域以获得更多回报信息;利用是指使用已有的回报信息,在选择节点之后使可能获得的“回报”最大。为了平衡空间探索与利用问题,在MCTS算法中引入了UCB1,核心公式如下
(1)
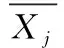
1.2 强化学习
强化学习[11]是指智能系统从环境到行为映射的学习,以使得整个环境的累计奖励值最大。强化学习通常使用马尔科夫决策过程描述[12]:机器处于环境E中,状态s是对当前环境的描述,其集合构成状态空间S。动作a可以使状态si跳转到下一状态si+1, 其集合构成动作空间A。每次状态转移之后可以获得一个奖励值r,体现本次转移效果的测度。由此,强化学习要找到一条最优“状态-动作”序列,使得整体奖励值最大。每一个状态s总能根据策略函数π找到一个最优动作a,使整体的累计奖励值最大,其中策略函数π如式(2)所示
a=π(s)
(2)
2 问题和相关概念定义
将用于生成公式的基本函数称为基本符号。例如,二元函数+,-、一元函数sin、自变量x等。这些基本符号组成的公式称为公式模型。一个公式由公式模型和对应的系数组成。将所有公式模型的可选择系数范围称为系数空间。将由所有公式所形成的集合称为符号空间,其包括模型空间和系数空间。例如符号空间中的公式 “0.3*cos(x)+0.5*x” 和 “0.4*x”, 其中 “cos(x)+x” 和“x”是模型空间中的公式模型,“0.3、1、0.5”和“0.4”是它们系数空间中对应的系数。
本文使用模型空间树来表示模型空间,其数据结构如图1所示。

图1 模型空间树
其中,此树中的节点表示公式模型,每个公式模型使用二叉树结构进行表示和存储;边表示父节点公式模型到子节点公式模型的变化操作。此操作表示为
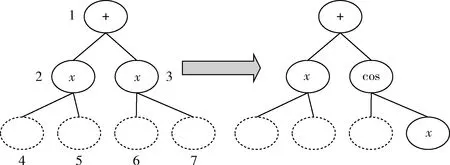
图2 公式模型生成
构建此模型空间树的过程就是对模型空间的探索过程。因此,添加子节点的位置次序直接关系到在符号空间中搜索答案的速度。例如,图1中加粗路径是公式模型 “cos(x)-sin(x)” 的生成过程。但若是在公式模型生成时先搜索节点 “x+x”, 则必须搜索更多的子节点才可以探索到正确的公式模型,使得搜索效率降低。为得到合理的子节点位置次序,将此树的构建看作一个强化学习过程。将节点作为状态,边作为动作,则从根节点到叶子节点的一条路径作为强化学习中“状态-动作”序列。在已知这些序列的基础上,通过强化学习获得符合数据集特征的生成节点次序,以得到最大“累计奖励值”。
每创建一个节点,就对此节点表示的公式模型使用PSO算法进行系数空间搜索,以得到较优的系数,并将此系数进行保存。例如,如果公式模型为 “x+sin(x)”, 经过PSO算法生成系数后的具体公式为 “0.3*x+0.2*sin(0.5*x)”。 在PSO算法进行系数空间搜索时,使用适应度函数(式(3))来衡量系数的“好坏”
(3)
式中:yn为测试数据集的结果,y′n是当前公式使用测试数据集计算的结果。式(3)表示绝对值误差和,也就是测试数据集中每个结果和公式预测的每个结果的差的绝对值累积和。
根据上面的描述,本文将符号回归问题转换为模型空间树的搜索过程。首先,利用数据集特征和已搜索空间信息,使用MCTS算法完成模型空间的搜索。再使用PSO算法完成系数空间的搜索。在搜索过程中,当找到适应度低于设定阈值的公式或者到达指定搜索路径次数时,搜索停止。
3 算 法
MCTS-SR算法由3部分组成:深度策略网络模块、模型空间探索模块和系数空间探索模块。①深度策略网络模块:其为预训练模块,根据大量的训练数据获得公式模型生成信息(当前状态的所有可能的下一步动作选择概率),以指导MCTS算法;②模型空间探索模块:其通过MCTS算法来选择或生成树节点(即公式模型),在搜索过程中,使用UCB1整合以下两个方面的信息:深度策略网络模块提供的公式生成信息和蒙特卡洛树自身包含的模型空间探索信息,指导树节点的选择或生成;并设计相关的剪枝规则,提高搜索效率;③系数空间探索模块:其为对上一步获得的每一个公式模型运行指定代数的PSO算法,以得到适合此公式模型的系数。
此算法流程如图3所示。当算法满足停止条件:到达设定的循环次数或者适应度函数小于设定阈值,则算法停止。

图3 MCTS-SR算法流程
3.1 深度策略网络模块
如第2节问题描述所示,每次蒙特卡洛树搜索过程是强化学习中的一个“状态-动作”序列生成过程,所以可通过强化学习的方法获得公式模型生成的策略函数π,从而指导蒙特卡洛树搜索。如式(4)所示,本文中使用深度策略网络表示策略函数
π(a|s)=p(a|s)
(4)
式中:s表示当前状态,包含数据集和当前公式模型,a代表可选择的动作
p(a|s)=softmax(v)
(5)
v=Network(s)
(6)
其中,Network表示CNN-RNN联合提取公式模型生成特征网络,v表示动作特征,softmax表示动作选择概率函数。在计算深度策略网络输出时,首先使用神经网络Network提取动作特征v,再使用softmax输出动作选择概率。
深度策略网络结构如图4所示。该网络使用CNN来提取数据训练集中的空间特征,这是因为CNN对于提取数据的空间关系有较好的效果[13];使用RNN来提取公式模型的序列特征,这是因为公式模型使用树结构进行表示,树节点之间有较强序列关系,而RNN能够较好地学习序列关系之间的特征[14]。最后使用Merge层融合CNN和RNN提取的特征,并通过输出层来得到当前环境(当前数据集和公式模型)下动作选择概率。
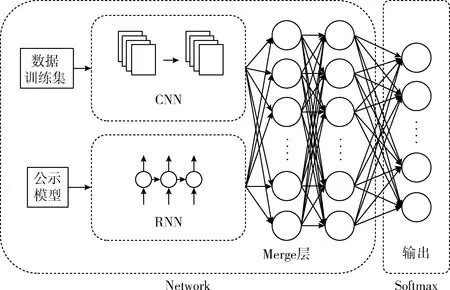
图4 深度策略网络结构
3.2 模型空间探索模块
本模块使用MCTS算法在模型空间中搜索较优公式模型。MCTS算法根据深度策略网络的公式生成信息和蒙特卡洛树包含的模型空间探索信息,来指导树节点的选择和生成。相较于使用随机策略的MCTS算法,MCTS-SR算法会根据上述信息优先搜索可能找到较优公式模型的局部空间,提高搜索效率。
蒙特卡洛树中的节点表示模型空间中的子空间,此节点下的子树是对子空间的探索;同时这些探索过程又生成了该子空间的“利用信息”。如果仅使用“利用信息”在该子空间下进行搜索,搜索结果容易陷入局部最优;如果不考虑“利用信息”,将使得搜索效率下降。
为平衡在模型空间探索中的搜索与利用问题,使用式(7)在所有可选择的动作中选取一个当前最优动作
(7)
式中:c为搜索与利用平衡系数,nj为子节点j的搜索次数,p(a|si) 为状态si下深度策略网络输出的动作选择概率,paj为第j个动作(也是选择第j个子节点)的动作值。其中c的数值越大,蒙特卡洛树就可以尽可能多地探索未被搜索过的子节点;c的数值越小,蒙特卡洛树就可以使用更多的“利用信息”。式(7)可以较好平衡搜索与利用问题,在保证有效利用“利用信息”的基础上,兼顾搜索未添加过的节点,以较高的效率搜索到较优的公式模型。
MCTS算法主要流程如图5所示。
(1)根据式(7)对路径中每一个状态(节点)选择一个paj最大的动作,进行下一个子节点的选择或者拓展。当公式模型中再无位置可被基本符号替换时,则为完成一次蒙特卡洛树搜索。此步骤对应图5中(4)-(6)行。
(2)根据paj生成下一个状态的公式模型。如果下一个状态的公式模型不在蒙特卡洛树中,就把此公式模型添加到子节点中。此步骤对应图5中(7)行。
(3)使用本文3.3节系数空间探索模块对每一个新生成的公式模型完成系数空间搜索,已在蒙特卡洛树中的公式模型跳过此步。此步骤对应图5中(8)行。
(4)更新整条路径上的搜索信息。新添加的节点搜索次数置为1,其余节点的搜索次数加1。此步骤对应图5中(9)行。MCTS-SR算法循环运行上述步骤,直到达到最大搜索路径次数或适应度小于设定阈值。

Algorithm: Model Space Exploration AlgorithmInput: Test Set,DY={d1,d2,..dn}, Model POutput: bestF_fitness(1) initMCTS(mct)(2) Fori=1,2,3,…,Ndo:(3) Repeat(4) ST=mctTostate(mct)(5) pa=predictByPolicy(P,ST,DY)(6) a=argmax(pa)(7) ExpandNode(mct)(8) bestF_fitness=CSA(DS,ST)(9) update(mct)(10) until mct can not grow(11) end fors
为了加快MCTS算法的搜索效率,在搜索过程中增加剪枝操作,以避免重复搜索同一子空间。其剪枝规则如下:①在蒙特卡洛树搜索过程中,如果叶子节点已经被搜索过,则把此节点标记为不可搜索节点;②如果某节点的所有子节点全部被标记为不可搜索节点,则此节点同样会被标记为不可搜索节点。在MCTS算法中加入剪枝操作可以避免蒙特卡洛树多次搜索同一条路径,提高搜索效率。
3.3 系数空间探索模块
在每添加一个节点后,需要对此节点表示的公式模型进行系数搜索。系数空间搜索使用PSO算法进行实现。首先,PSO算法随机初始化种群中粒子位置。本文将PSO算法的粒子表示指定公式模型的系数,其编码方式为Coe=
其次,粒子的速度(系数的变化大小)决定粒子移向何处。在PSO算法中粒子的速度主要由种群中最优粒子和各个粒子自身的历史位置决定的。式(8)为粒子的速度计算公式
vi=vi+c1*rand()*(Coepbesti-Coei)+
c2*rand()*(Coegbest-Coei)
(8)
式中:vi表示第i个粒子中系数的变化值,rand()是[0,1]之间的随机数,Coei表示第i个粒子表示的系数值,c1和c2是学习因子,Coepbesti是第i个粒子保存的自身的历史最优系数,Coegbest是整个种群中保存的历史最优系数。使用式(8)可以得到系数的变化值,再使用式(9)更新粒子的位置,得到新的一组系数值
Coei=Coei+vi
(9)
式中:Coei表示第i个粒子的当前位置(系数值)。不断迭代运行式(8)、式(9)使粒子(系数)趋近于最优解。
最后,在每更新完粒子一次位置后,使用适应度函数(式(3))评价当前系数是否为该公式模型的最优系数。当达到最大迭代次数或者搜索到最优解时搜索停止,再判断该公式模型与对应系数是否为符号空间中最优公式,如果是则标记出来。系数空间探索模块流程如图6所示。

图6 系数空间探索模块流程
3.4 算法分析
相比GP算法从符号空间中直接生成种群个体,MCTS-SR算法是在符号空间划分出的模型空间和系数空间中交替搜索,这样可以避免两个空间相互干扰,提高搜索效率。
在本文中假设非终结符号f={+,-,*,sin,cos,x2}, 其中一元函数f1={sin,cos,x2}, 二元函数f2={+,-,*}。 终结符号T={x,c}, 常数c的精度是0.001,根据式(10)可以迭代计算出第d层公式树可以表示的公式数

(10)
式中:Ld为第d层公式树可以表达的公式数目。相较于GP算法MCTS-SR算法在搜索模型空间时无需引入常数c,所以搜索空间会小很多。例如根据本文选用的上述基本符号,可算出 |T|=1001、 |f1|=3、 |f2|=3,L0=1007。 由式(10)可以计算出当深度d为4时,则符号空间中可以选择的公式个数大约为1.47*1055。
在只考虑模型空间的情况下,当深度d也为4时,MCTS-SR算法的符号空间可以选择的公式个数约为7.93*1010。这比直接在符号空间中搜索的复杂度要小很多,所以可以使得搜索效率提高。并且一个公式模型只需记录一组对应的最优系数,使得无需使用额外空间记录系数空间中的系数。
4 实验结果
4.1 数据集与环境
本实验选用的符号空间中的基本符号共有8个,分别为:1,x,+,-,*,sin,cos,x2。其中终结符号为1,x;非终结符号为+,-,*,sin,cos和x2。
深度策略网络的训练数据通过以下过程来生成:①随机生成6000个不同的公式模型;②针对每个公式模型,随机生成20组系数,系数范围为[0,1]。每个随机生成的公式模型包含7种基本符号种类(“+”拥有1+x和x+x两种),并且每个公式模型最多有7个基本符号的作用位置(非叶节点)可以选择,所以深度策略网络共有49个动作可以选择。其中正确动作选择对应的标签(奖励值)为1,其余动作选择对应的标签(奖励值)为0。依据上述方法,最终生成46.5万条训练数据。
深度策略网络使用Keras深度学习开发平台,其训练参数如下:RNN的输入维数为15,CNN的输入维数为(10,20,1)。其中CNN共拥有卷积层4层,其卷积核个数分别为64、32、32、32,池化层一层;RNN中有两层LSTM,其单元个数分别为64、32。CNN与RNN都与有1024个节点的全连接层相连,再使用Merge层进行合并,最后与两层分别有512、256个节点的全连接网络相连。本实验采用基于mini-batch的Adam优化方式训练参数,学习率设为0.001。损失函数为多类的对数损失(categorical crossentropy)。
4.2 实验结果分析
使用上述的训练集对深度策略网络进行训练,在整个训练集上训练200代,得到训练集的准确率为56.4%,准确率变化如图7所示;在保留的测试集中测试的准确率为41.2%。本实验结果表明:在上述深度策略网络的训练准确率下,可以高效搜索到较优公式。

图7 深度策略网络准确率
本实验使用表1中的随机公式生成的测试数据集对MCTS-SR算法进行测试,并与GP算法进行比较,其中GP算法参数设置见表2。
由于GP算法是不稳定的算法,每次运行结果不一定一样,所以在每个测试数据集上运行10次,每次运行1000代。MCTS-SR算法是一种较稳定的算法,只运行1次,在蒙特卡洛树中搜索1000条路径。比较两种算法的适应度高低,越低代表越贴近所给函数的特征。图8是10次GP算法适应度与MCTS-SR算法适应度的对比图。表3是MCTS-SR算法的适应度依次与10次GP算法中的最优适应度、平均适应度和最差适应度进行对比。

表1 测试公式
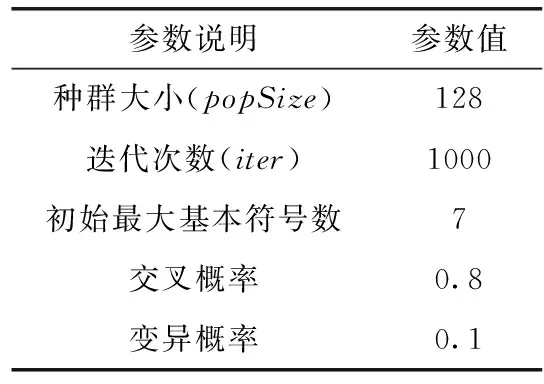
表2 GP算法参数

图8 MCTS-SR算法与GP算法比较
通过表3可以看出,MCTS-SR算法在全部的测试数据集中的适应度都小于GP算法的平均适应度,在公式F1中甚至要比GP算法中最优的适应度还要更好。这说明了MCTS-SR算法可以在符号空间中找到较优的公式。
MCTS-SR算法在算法稳定性上要优于GP算法。GP算法是一种不稳定的算法,受种群初始化、交叉变异参数选择的影响较大,不能保证每次运行都能得到最优的结果。如表3中公式F5所示,GP算法最优和最差适应度可以相差380倍左右,即使是相差最小的公式F4也相差了6倍左右。这使得GP算法必须运行多次才能得到较优解,解决问题的效率较低。而MCTS-SR算法是一种较稳定的算法,只要深度策略网络训练完毕,则蒙特卡洛树搜索过程中每次选择或拓展的节点依据式(7)也就确定了,所以MCTS-SR不会像GP算法一样上下限差距很大,可以稳定得到一个较优解。
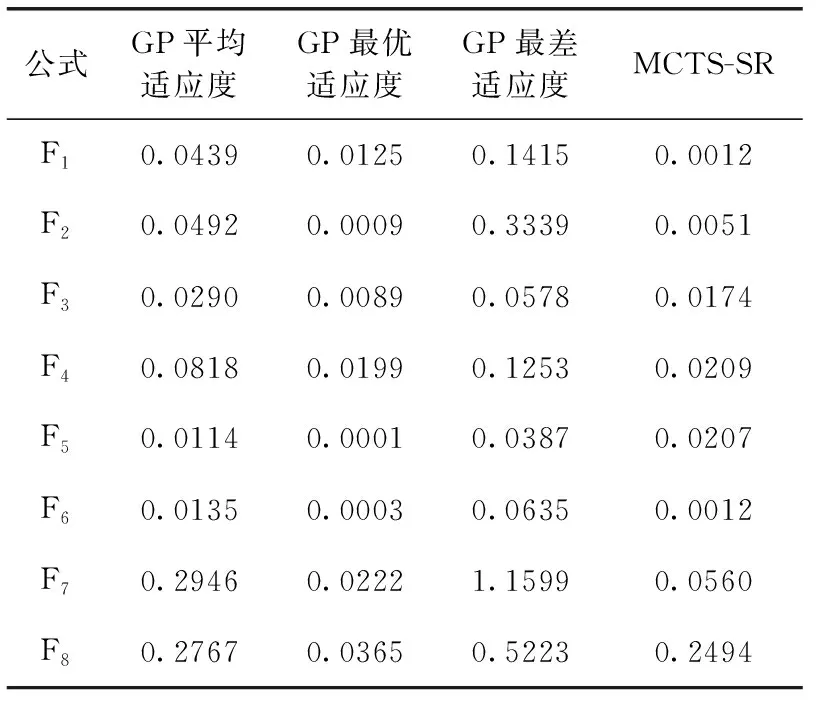
表3 GP算法与MCTS-SR算法对比
MCTS-SR算法相比GP算法不易陷入局部最优解。由图8可以发现MCTS-SR算法在搜索时适应度函数会不断下降,而GP算法在快速下降之后就趋于稳定。这是因为GP算法并不会记录已搜索过的种群,所以有可能会在同一空间内进行重复探索,导致陷入局部最优解。而MCTS-SR算法中有剪枝操作,不会重复搜索相同的公式模型,这使得MCTS-SR可以一直探索新的子空间,发掘新的较优公式,不易陷入局部最优。
5 结束语
针对GP算法存在无法充分利用数据特征、收敛效率低、易陷入局部最优解等问题。本文把符号空间分为模型空间和系数空间。模型空间使用模型空间树表示,可以记录每次搜索的公式模型,不会重复搜索同一子空间,避免陷入局部最优解。并且MCTS-SR算法使用深度策略网络辅助进行公式模型生成,可以充分利用数据特征生成公式模型。由实验可知,相较GP算法而言,使用MCTS-SR算法获得的公式适应度值更优、稳定性更优、不易陷入局部最优。
