讯飞语音输入法方言识别在新冠疫情防控中的应用评估*
2020-09-04汪高武李晨光杨豆豆
汪高武,庞 博,李晨光,杨豆豆
(北京师范大学 文学院 北京 100875)
提 要 在各种社会重大突发事件的应急处理中,智能语音技术能起到弥补人力资源严重不足、紧急处理海量信息、有效应对风险、降低损失的作用,具有独特的优势。在2020年新冠肺炎疫情中,全国各地支援湖北,不同方言人群之间的沟通也成为一个问题,这对语音识别技术提出了要求和挑战。本文以科大讯飞智能语音输入法为例,根据全国多种方言(139个方言点,共283位发音人)在疫情防控模拟场景下的语音识别材料,对其成效进行了评估和分析,并探讨了智能语音技术的应用和发展。
一、引 言
智能语音技术是人机交互中最为重要的一种,计算机通过语音的交互方式理解、辅助人类(陈鹏2017;王海坤,等2018)。智能语音技术具有永不疲倦、降低人力成本、智能可扩展等特点,已广泛应用在各种领域,包括医疗健康(张海波,等2017)、出版传媒(胡郁,等2016;朱晶晶2016)、教育教学(张筱兰,王保论2011)、公安警务(肖益茂,等2018)、呼叫中心(李枫,徐韬2016)、客服质检(林可希2013)等等。其中语音转为文字的技术,帮助人们免于手写或打字的限制与劳累,为社会做出了很大的贡献。以科大讯飞智能语音输入法为例,2019年全国讯飞输入法用户语音录入共计35 560亿字,可为用户节省8.38亿分钟,接近9.6万年(中关村在线2020)。
随着社会发展、人口集中、人力成本越来越高,对智能语音技术的需求也日益增长。特别是在各种社会重大突发事件中,智能语音技术能起到弥补人力资源严重不足、紧急处理海量信息、有效应对风险、降低损失的作用,具有独特的优势。重大突发事件的特点主要有:(1)突破生活常态,意味着新的场景、任务和交流,以及庞杂的人员聚集重组。人类对某些场景的适应性很强,但有些情况,例如不同方言和不同语言之间的障碍,却不是短时间内能适应解决的。等适应了、学会了,应急处理可能又过去了,语言学习就显得不太划算。(2)重大突发事件,特别是重大自然灾害,往往是人员大量受损、人力资源紧张甚至枯竭的时候,为避免诸如医疗资源被挤兑甚至“击穿”的风险,正需要语音智能去帮助沟通、辅助筛查、缓解人力、安抚情绪,减轻医疗、救援及工作人员的负担。例如本次疫情中,有智能语音呼梯系统帮助避免电梯按键接触式感染、人工智能辅助医疗协助基层医生进行疫情筛查防控和防疫知识宣教、智能医疗助理为一线提供最迫切需求的医疗服务和国家基层医疗培训等各种应用(任晓宁2020)。
在本次疫情中,全国各地支援湖北,方言沟通成为一个问题。为帮助外地援鄂医疗队解决医患沟通的方言障碍问题,教育部语言文字信息管理司指导组成了“战疫语言服务团”,迅速研制了涵盖湖北九大方言片区的《抗击疫情湖北方言通》,为抗击疫情的医护人员及相关群体提供多维度语言服务(李宇明2020)。可以预期,将来智能语音技术会在防疫等重大紧急事件中起到相当的作用。为此,我们也需要对智能语音技术在这些实际应用场景下的性能进行第三方独立的、非商业的、科学的评估,为将来国家制定行业标准、政府采购智能语音技术产品提供科学依据和参考,以更好地为社会民生服务。
由于欧美国家医疗健康产业更为发达,人力成本也更昂贵,所以对人工智能技术在健康卫生行业的应用和评估也比较多(Johnson et al. 2014),但国内对智能语音识别技术的测试评估比较少(蒋平,吴振国2003)。因此本研究将以语音输入法对疫情防控场景相关语料的识别为例,讨论智能语音技术的应用情况和表现。智能语音目前有很多家的技术和产品,选择以讯飞输入法为例是因为:首先,讯飞输入法识别语言种类最多,提供了全国23种汉语方言的识别(其硬件产品“讯飞翻译机”可提供59种语言翻译)。其次,讯飞技术相对较成熟。有医疗团队在对儿童发音评估的研究中,对比了两种语音识别软件,发现其识别率更优,性能更稳定(韩源,等2017)。最后,讯飞输入法应用最为广泛。在移动互联领域,讯飞输入法用户达4亿,活跃用户数1.1亿(中国网2016)。同时,科大讯飞被国家科技部列入新一代人工智能开放创新平台名单,为同行业唯一(科技部2017)。
二、研究方法
(一)语料设计
要评估智能语音技术的应用状况,最佳方案是在防疫工作医疗实际场景中进行调查。但为了避免影响防疫工作、增加医疗人员或患者的负担,以及避免调查志愿者感染风险,我们采取部分模拟真实场景的一种体验方式,让发音人(被试)用方言念相关的语料。语料应该涵盖可能症状的描述(例如咳嗽、发烧、呼吸困难)和相关的医疗用语(例如打针、口罩)等。在教育部语言文字信息管理司指导下成立的“战疫语言服务团”,根据语料库统计和医用场景调研,遴选了156个词和76个短句(北京日报客户端2020),应用广泛,较为典型。但根据我们预调查的反馈,其篇幅对于本次的调查任务来说还是比较重。经过多次反馈和调整,尽量用较少的文本包含更多的信息,本次调查研究从中选取了21个跟疫情最为相关的词汇(包括症状、医疗、程度副词、否定副词),以及20个短句,并对短句加以扩充(加入不同的亲属称谓、医疗用语等)和调整,作为本次调查研究的语料,具体内容请见下文和附录。
(二)发音人情况
本次调查研究共有100位志愿者参与,均为学习语言学课程的学生。调查对象为志愿者自己与其居家隔离亲友,共计283位发音人。年龄从9岁~84岁,平均年龄35.7岁,标准差17.97岁。其中96位男性,187位女性,女性比男性多主要是因为班级学生的性别比例女性占多。有鼻炎、鼻塞现象的3例,牙齿缺失的7例,经人耳听辨录音,对于发音没有太大影响。除了极个别情况(例如带鼻炎的“发烧”人耳听辨无问题,但输入法识别为“放手”),语音识别也没有太大问题,属于可接受范围。
(三)实验步骤
调查方法是让发音人在自己的手机上下载并安装讯飞语音输入法,根据自己的方言情况,从讯飞输入法提供的23种方言中选取跟自己最接近的方言。然后让发音人用自己的方言,以对应普通话词句的当地表达方式,对着手机说话,由志愿者记录下方言的文本和讯飞输入法识别出的文本。然后由志愿者标记语音识别的错误之处,并加以分析,填写到调查表中。同时保留录音,以做后期的校对和分析。调查表收取后,经过研究小组的校对和核查,用Python和Matlab编程进行数据文件的处理和统计分析。
三、结果分析
(一)基本情况
本次调查的发音人地点有139个,详细到城区或乡镇。除青海和台湾外,全国各省市自治区均有分布,地址为“乡/镇”的57个,“市/区/县”的82个,城区略占优势。讯飞输入法提供的23种“方言”,是一种笼统的、并非学术意义上的说法,大体相当于23种“地方话”。本次调查没有发音人选择天津话、苏州话和合肥话作为识别方言,另外有些发音人没有母语方言只会说普通话,所以最终在图1中列出了20种“方言”和普通话的人数分布。
本次研究,是让发音人自行从讯飞输入法提供的23种方言中选取,所以会遇到选择错误的情况。一般人对自己方言的认识,往往是以距离、行政归属来判断,对于语言学里划分的方言、次方言、片区等并无太大概念。本次调查中,有6人选择了错误的方言,占总人数的2.1%。例如:104号发音人是讲河南省安阳市内黄县井店镇的方言,初期选择了输入法提供的河南话,实际上安阳话属晋语邯新片获济小片,不属于中原官话,保留了入声,跟通常所说到的河南话区别很大,相比较而言更应该选取输入法提供的山西话(太原)来识别。143号发音人是讲江西省赣州市蓉江新区潭东乡的方言,根据行政归属选择了讯飞提供的江西话(南昌)。实际上,赣州话是一个方言岛,市区是西南官话,周边都是客家话。这个地点在赣南师范大学黄金校区附近,经录音听辨,有入声,基本上还是客家话。以上都在讯飞提供的23种方言中有更好的选择,但还有很多方言,只能相对择优,选择其中一种最为靠近的方言,这会严重影响识别错误率,这些将在下文讨论。
另外,为了解社会大众对智能语音技术特别是语音输入法的认知状况,本次研究在调查问卷中设置了9个相关的问题,具体情况将另文介绍。总体上看,语音识别技术还是广泛进入社会生活、被大众认知的,但只有很少一部分人(占比16.4%)使用过方言识别的功能。
(二)识别错误分析
1.错误率的判断标准
对于智能语音识别(语音输入法),最重要的衡量指标就是把语音识别成文字的正确率或错误率。英语的错误率一般用错词率,汉语一般用错字率。通常设定普通人类错词率为5.9%,受过严格训练的专业速记员错词率在3%左右。2018年的Pyramidal-FSMN语音识别模型,错词率低至2.97%,将全球语音识别准确率纪录提高到97.03%,超过了受过严格训练的专业人类速记员(Yang et al. 2018)。但无论算法如何改进,只要是基于统计模型,识别正确率都只会无限趋近而不会达到100%。而且这些正确率都是基于特定的数据库,真实场景的正确率实际上会降低,这也是语音识别没有更为普及的原因。当然相比于自动驾驶、机床操作等对安全有极高要求的领域,语音的识别错误相对来讲更容易被用户接受,达到“可信任”水平。
本次主要研究汉语方言,错误率的判断标准说明如下:(1)因为汉语基本上是一个汉字对应一个音节,所以计算错误率的时候可以用字符数或音节数计算均可。但日常使用语言当中常常会有英文和数字,例如这次的语料里就含有英文“CT”和数字“38”,以及常见的“WC、18、花儿”等,我们这里统一标准,都按字符算成两个字。(2)“的、地、得”之类的混淆不算错误。这3个字的发音一样,在短句正文中即使输入法识别错误,对正确意思的理解也几乎没有影响,就不计入错误。(3)标点符号。一般的情况(例如逗号、句号等)对正确理解影响极小。除了极个别情况,例如问号和句号弄错。但在本次调查的语料中,所有的问句都含有疑问词,例如“要不要紧?”“治得好不?”“在哪儿?”“哪个医院?”等,所以对于普通话以及北方方言一般都能识别为问号。但对于有些方言,其疑问方式未必带有疑问词,例如云南曲靖方言,“我外婆的病要不要紧?”对应的方言表达为“我外婆的病可严重?”,就会被输入法识别为陈述句。所以标点符号的识别错误会跟正文字符分开单独处理。
2.各方言点的识别错误率
表1是各方言点的识别错误率,包括21个孤立词和20个短句的错误率。从表中可以看出,普通话短句的错误率为2.5%,达到了宣称的97%正确率水平。孤立词的错误率稍高,这是正常的,因为缺少上下文环境,难以区分同音词。选择普通话识别的,大部分是北京人或新疆、黑龙江、内蒙古等地的移民家庭成员(特别是已经不说方言而以普通话为母语的年轻人)。东北话的识别错误率3.1%也比较低,这是因为相对于其他方言,东北方言内部一致性更高,差别较小。表1中各方言的排序大致有几个规律:
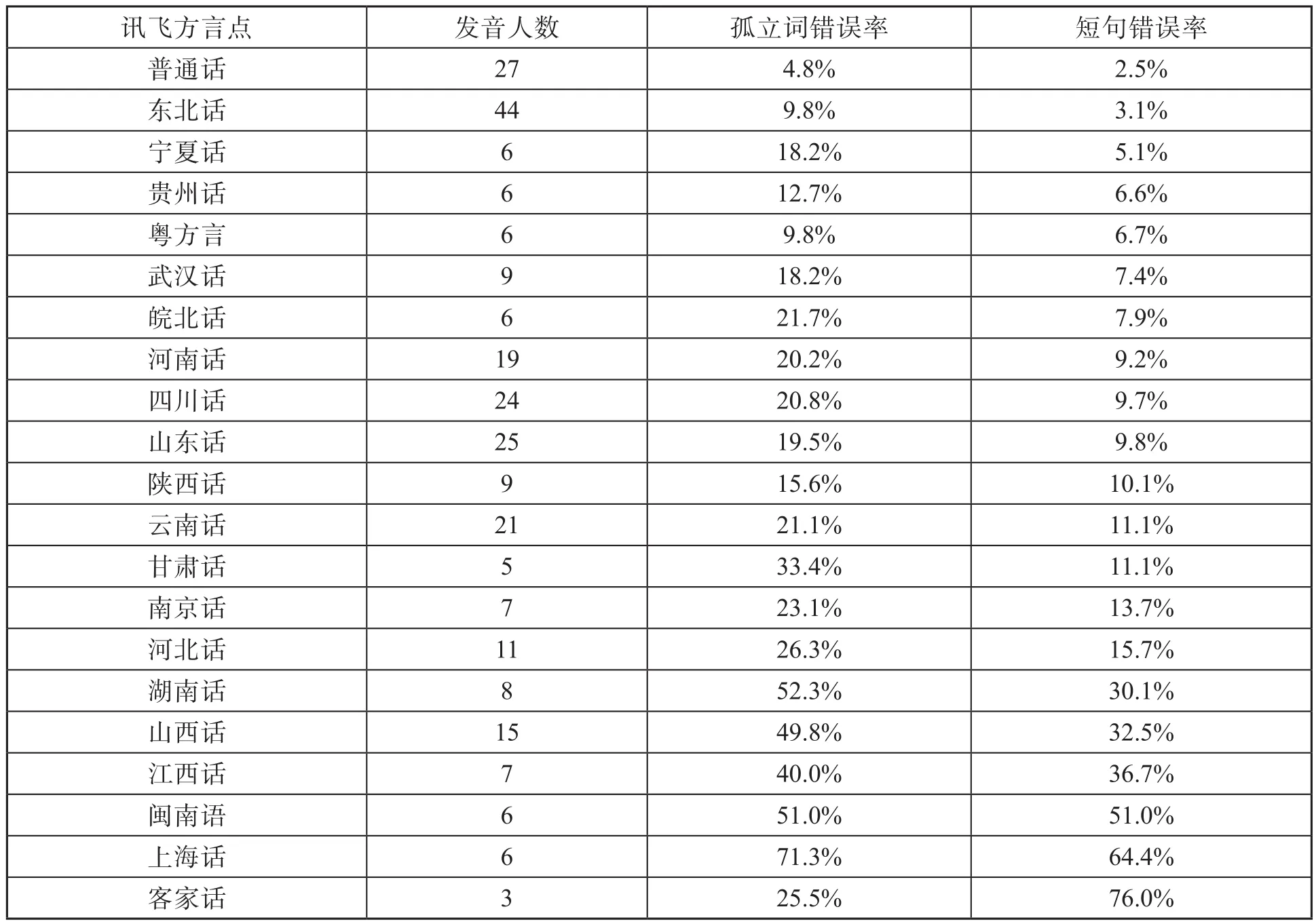
表1 各方言点识别错误率
(1)北方方言(或者说官话)内部一致性相对较高,所以即使我们的发音人不是恰好在讯飞方言所提供的方言点,区别也不会很大,其识别错误率会相对较低,除了山西话(晋语),绝大部分的短句错误率在15%以下。
(2)南方方言(或者说东南方言)内部区别较大,有的邻近地区甚至无法沟通,发音人所说方言若跟讯飞方言选点不在一处,其识别错误率极高,几乎无法识别。例如,125号发音人说的是海南省海口的方言,选择的讯飞方言是闽南语,识别错误率高达80%。这可能是因为海口方言属于闽语琼文片府城小片,与闽南片差距较大。发音人还尝试了选择粤方言和客家话,准确率都很低。
(3)南方方言内部一致性相对较低,发音人的分布对错误率影响较大。例如选择贵州话的6位发音人都是贵阳市区的,与讯飞输入法选点(大概率为贵阳市)一致,错误率较低。而同为西南官话的武汉话、四川话和云南话错误率却相对较高,这是因为发音人分布较广,例如选择云南话的21位发音人分属昆明市、曲靖市、玉溪市和昭通市,与讯飞输入法的选点“云南话(昆明)”有一定差异,所以错误率较高。粤方言的内部差异也不小,但在本次调查中,由于其使用人数少、分布又集中,所以作为南方方言错误率反而较低。
(4)方言交界地区的方言点,往往受到临近多个方言的影响,同时带有不同方言的特点,按方言归属来选择讯飞输入法的方言点,错误率就会很高。例如,40号发音人是湖南省株洲市茶陵县的方言,根据行政归属选择了讯飞提供的湖南话(长沙),方言划分上也同是湘语长益片长株潭小片,但错误率依旧接近40%。实际上湖南省株洲市茶陵县处于湖南江西交界地带,紧邻江西井冈山,受赣客方言影响较大。同样的录音,选择客家话和江西话,也基本无法识别。所以对于交界地带受各种方言影响的方言点来说,语音识别很是困难。以上规律说明,智能语音输入法如要提高方言特别是南方方言的识别正确率,需要更加细分的方言选点。
3.具体语句的识别错误分析
本次调查的语料包括疫情相关的21个孤立词和20个短句。虽然在实际生活场景中,也会有单独词成句的,但孤立词因为没有上下语境,语音识别的难度会高很多。本次调研选取的21个疫情相关用语,其平均识别错误率如表2所示。错误率最高的是“发麻”,识别出的错误结果有“发吗、发嘛、烦吗、坏吗、花马、喝嘛、号码、干嘛、干吗、嘎玛、福马、服务忙、放忙、番麦、砝码、伐麻、发息、发墨、发膜、发毛、发忙、发码、发马、帮忙、白马、霸蛮、爸妈、发墨、丈母娘啊、Fame”等。错误率第二的“呕吐”,在很多方言里的说法为“哕”,这样的一个单音节词是很难被识别出来的,识别错误有“哦、敢约、约、干约、干悦、与、原、月、我、晕、约”等等。由于篇幅限制,关于孤立词和短句更为具体的错误分析将另文讨论。

表2 调查表中21个孤立词语的识别错误率
四、讨 论
本研究是以讯飞语音输入法在疫情防控场景下的识别情况为例,对智能语音技术在重大突发事件中应用评估的初步探索。可以看到,社会大众对智能语音输入法已经有了相当的了解和期待,讯飞输入法对于疫情语料的识别,在官话地区的方言表现较好,可以达到实用水平,而在东南地区的方言表现较差,需要更加细分的方言选点。由于现实条件的多种限制,本次调查语料样本的数量和部分方言点的发音人数量(少于10人)还不太够,这也使得调查数据有一定的随机性,导致最终结果受手机状况、背景噪音、发音人状况、分布等各种因素的影响,这些我们将在下一步的工作中加以改进。其中有两个问题需要在这里讨论一下。
(一)言语表达方式的问题
本次实验的语料是固定的,调查表里的21个词语和20个短句,都是普通话的表达方式,但在各个方言里往往会有不同的说法,甚至具体到某个发音人,表述的方式都可能有所不同。这也跟发音人的言语转换能力和风格有关,其中老中青不同年龄段发音人的说法往往就不一样。例如赣方言某方言点,其老中青三代对“鸡蛋”的说法分别是“嘎=子”①此处在字后右上角加等号“=”表示同音字。“鸡子”“鸡蛋”。一般来说,越年轻的人受普通话影响越多,会用方言的读音来念普通话的句子(例如有些方言里年轻人不再说“哕”,而只是用方言的读音来念“呕吐”),而中老年人会用更为本地方言甚至濒临消失的表达方式(常常被认为是特别“土”的表达方式),这对识别错误影响会很大。从实际需求来看,在语言应急服务中,以解决方言障碍为目标的主要人群是中老年人,所以我们在调查和实验的时候,需要考虑周到,把各年龄阶段的老中新派方言表达方式都要涵盖进来,以更好地应社会所需。
(二)方言的选择和划分问题
汉语方言差异较大,划分复杂,给语音识别提出了很大的挑战。从本次调查研究可以看出,方言的选择和划分对识别结果影响很大,需要认真对待。(1)从使用者角度来看,需要恰当选择方言,不仅仅是根据距离和行政区划,还要根据方言学上的划分。但普通人一般都不会具备这样的语言学知识,所以还需要语音技术(结合地理定位功能)能够更加智能地识别方言,这就需要知道并能提取各方言的特征因素(戴庆厦,等2018)。另外,语音识别的错误率跟方言间的可懂度、互通度等因素有关,但可懂度不是划分方言区属的唯一依据,也不是最为重要的依据,所以方言区属划分跟语音识别的效果偶尔会出现矛盾,在实际应用中应当以识别效果为准。(2)从技术研发者角度看,需要给出更多的方言点。但方言犹如颜色一样,界限模糊,可以无限细分。另外,普通话长期形成了规范的文语对应,而方言很多时候“考本字”都很困难,分得太细,则语料库的训练成本会很高。那方言到底要细分到什么地步?好在到了智能信息时代,可以有新的思路。首先是数据获取更为容易,在需求驱动下,哪个方言点的用户多、使用频率高,软件搜集的数据越多,对该地区方言的划分就可以更细。所以不一定以方言划分为唯一标准,而是以识别效果为标准,不降到一定的错误率标准,就继续细分,达到实用程度为止。其次是用户参与,现在智能终端普及,人手一机,均可对本家乡方言的识别结果加以校正,这种方式可以大大降低成本,使得技术能更快地进入社会使用。值得注意的是,对于商业应用来讲,需要考虑到市场和成本因素,但从社会民生角度来讲,需要适当地保障语言“少数、弱势”群体的权益。
五、展 望
本次疫情中,语音智能技术并没有得到如我们所期望的大规模应用。原因之一是对新生事物要求往往会更高更挑剔。好比自动驾驶技术已经可以比人类司机事故率更低,但只有其安全系数高出很多倍,才有可能被认可进入大众生活。语音技术也是如此,虽然本次调查表明大众对语音技术是期望的,但根据我们另外一项对159人的调查,大众对语音识别技术依然不满意,认为需要改进的地方有:准确率低(占比54.09%)、转换速度慢(31.45%)、缺少方言识别(64.15%)、缺少外语识别(29.56%)、无法感知话语中的情感态度(45.28%)等。语音识别技术要真正达到实用,进入日常生活,还需要继续降低识别错误率。目前语音智能技术(采用深度神经网络)有两个缺陷:(1)计算量庞大,大量参数迭代收敛、训练封装后如果有新的数据需要学习,用户端的简单设备就做不到了;(2)模型不可解释,难以保证下一次不犯同样的错误。有学者提出了深度模糊系统及其快速学习算法可以克服这两大缺陷,是一个很好的发展方向(Wang 2003)。另外,人的大脑适应性极强,具有很强的泛化能力,但神经网络无法把学到的东西泛化到和训练集统计规律稍有区别的地方。长期以来,语音智能技术依靠统计模型,很多试图从规则知识出发或者采用两者结合的方法都不是很成功。最近的符号主义人工智能提出了一个切实可行的道路,就是利用符号和它的一套操作系统,重新把知识和模型教给神经网络(Marcus 2020)。这些新方法都为降低错误率提供了新的发展方向。
目前很多语音智能识别技术的高正确率是基于特定语料库的,从本次调查和研究可以看到,智能语音技术在疫情防控场景下,特别是对方言的识别效果,还是有很大的改进空间。我们期待语言学和计算机领域的学者,不断探索新思路、新技术,提升智能语音技术,在重大突发事件中能更好地为社会民生服务。
(感谢参与调查工作的诸位志愿者:白荐楠、陈丽琳、陈璐、陈雯茜、程娅惠、从恩竹、崔泽馨、樊星辰、范婧婕、冯星云、冯驿雯、付羿雨、高凡舒、高山倩、高子庭、关乔之、郝雨洁、胡砚才、黄悦、贾紫琳、姜启宁、姜玉郎、金灵、拉姆、李晨光、李吉霞、李康敏、李乐乐、李祺溦、李宛婷、李正、梁霄云、刘晨筱、刘会珠、刘麓基、刘瑞秋、刘一新、刘玉萍、罗会露、罗家淇、马悦霞、毛翎、欧阳瑞美、潘新宇、庞博、彭晓钰、彭彦涵、蒲素素、蒲璇妃、陕月、尚鑫欣、邵芊涵、孙建亚、孙铭泽、孙千千、唐锐奇、汪子涵、王春醒、王家琪、王京欣、王晓宇、王雪莹、王祎琳、王瑜琦、尉然、鲜欣仪、肖开捷、熊莉萍、徐立恒、鄢冉、杨豆豆、杨涣涣、杨子谦、姚安甫、殷王会、尹雪力、袁诗梦、张竞兮、张沁萌、张瑞颖、张婷婷、张钰琪、张钰扬、张芸鹭、赵姝忞、赵怡昕、赵玥、周博闻、周婧妍、朱思恒、朱芷妍、曾心怡、邹雨桐等。并向身体不便特别是手指受伤无法写字、打字的文字工作者致敬!本调查为独立进行,跟任何语音公司,包括科大讯飞,均无利益关联。)
附录(调查表中的20个短句):
(1)我头疼,我头晕。
(2)我咳嗽,干咳,我咳得出不了气了。
(3)我女儿拉肚子,肚子痛。
(4)我全身酸痛,我没有力气。
(5)我奶奶平时身体还好,没有什么别的病。
(6)我外婆的病要不要紧?
(7)医生,我妈妈的病治得好不?
(8)我爸爸输液输完了,要拔针头。
(9)我家里有人好像不舒服,还没确诊。
(10)我想上厕所,厕所在哪儿?
(11)我老婆吃了饭,还没有吃药。
(12)我爷爷发烧,烧得很厉害,烧了几天了。
(13)我量了体温,我老公的体温是38度多。
(14)我外公做过CT、做过核酸检测、做过采样了。
(15)我昨天到湖北去过一趟,没有去过武汉。
(16)我今天应该到哪个医院、哪个科室去看病?
(17)护士,我对青霉素和其他抗生素都不过敏。
(18)我喉咙疼、我腰疼、我胸口疼。
(19)我自己没事,就是我儿子有点流鼻涕。
(20)我的头很疼,都快要炸了。
