基于视觉特征的仿冒域名轻量级检测技术
2020-09-04宁振虎周艺华
朱 怡,宁振虎,周艺华
(北京工业大学信息学部,北京100124)
0 引言
作为互联网的基础,域名系统(Domain Name System,DNS)的重要性不言而喻,但近年来DNS却频繁遭受恶意攻击或因故障瘫痪,传播恶意软件、促进命令和控制服务器[1]通信、发送垃圾邮件、网络钓鱼网页[2]等给网络安全造成了极大冲击。DNS 的安全性之所以难以保证主要原因有:首先,DNS的服务角色决定了DNS 具有稳定性和公开性,而且缓存的影响使得地址不会频繁地更改,因此在DNS 服务器遭受攻击时无法替换和隐藏IP 地址;其次,DNS 的集中性,在正常情况下,DNS服务器为多个网站或者用户提供服务,攻击服务器具有很大的影响范围,大大提高了攻击的效率;最后,DNS 的匿名性,DNS 服务使用用户数据报协议(User Datagram Protocol,UDP),黑客可以很好地隐藏自己的踪迹以免被追踪。
在DNS 遭受的网络攻击中,仿冒域名因攻击成本低、危害范围广、盈利手段多样化等特点,已经成为威胁互联网安全运行的重要问题之一[3]。仿冒域名是网络蟑螂的一种形式,是一种域名抢注行为,指抢先注册网络使用者因输入错误而访问的域名,以期望用户访问仿冒域名而非目标网站域名。仿冒域名通常是与流行的知名域名非常相似的域名,大量的仿冒域名站点被攻击者用来显示广告、将流量重定向到第三方页面、部署钓鱼网站或提供恶意软件而从中获利[4]。例如,攻击者可以注册facebo0k.com、microsolt.com 等域名,当网络使用者不小心错误输入或者被钓鱼邮件视觉迷惑时,就会访问这些网站,攻击者由此牟取非法利益或实现非法目的[5]。
仿冒域名网络攻击如今已成为国内外安全社区和相关机构的重点防护对象,提前防范仿冒域名攻击对于保障互联网正常运行具有重要意义。基于此,本文全面了解DNS 所面临的威胁,对仿冒域名行为进行重点研究,提出了一种基于视觉特征的仿冒域名轻量级检测方法,在仿冒域名检测和保护网络终端免受仿冒域名侵害和攻击上有显著效果。
1 相关工作
本章首先对仿冒域名进行概述,研究仿冒域名的构造特点;接着对当前主要的仿冒域名检测技术进行分类研究,主要划分为主动检测和被动检测,并针对这两大类检测技术的原理和不足之处作详细分析;最后介绍本文主要工作。
1.1 仿冒域名特征
仿冒域名属于典型的抢注域名[6],仿冒域名的数目随域名注册数目的不断增多而不断上涨,在实际应用中,用户经常会因为错误拼写域名而被链接到仿冒域名网站[7]。此外,计算机硬件错误也会导致用户访问仿冒域名网站[8]。仿冒域名的构造方式极其简单,非法者通常能通过选择目标域名快速注册大量的仿冒域名。
为了解仿冒域名的构造特点,从以下三方面进行研究:
1)编辑距离或手指距离。手指距离是通过结合键盘上字符的排列特征对编辑距离进行的一种改进,即利用键盘上相邻位置的字符将一字符串转换为另一字符串的最小插入、删除、替换操作数)。Moore 等[9]从 Alexa[10]排名前 6 000 的域名中选取了3 264个域名作为目标域名,构造了编辑距离和手指距离小于3(1 和2)的191 738 个注册域名作为候选仿冒域名集。实验结果显示,与目标域名的编辑距离为1 和手指距离为1 的候选仿冒域名集中,仿冒域名所占比例都高达90%以上,但在编辑距离为2 和手指距离为2 的候选仿冒域名集中,仿冒域名所占比例相对较低,分别低于60%和80%。
2)目标域名的Alexa 排名。早期非法注册者主要针对Alexa排名靠前的域名来注册对应仿冒域名。后来,随着域名数目的增长,非法者在注册仿冒域名时选择的目标域名范围也随之不断扩大。Szurdi 等[11]针对 Alexa 排名前 100 万的域名,选取长度大于5 的域名作为目标域名,利用手指距离操作构造生成候选仿冒域名集,通过比较目标域名的Alexa排名情况,发现Alexa排名靠前的域名对应的仿冒域名数量更多。
3)目标域名长度。早期,Banerjee 等[12]研究认为目标域名长度是影响仿冒域名数量的一个重要因素,非法者通常会针对长度较短的目标域名注册仿冒域名。随后,Moore 等[9]针对不同长度的目标域名分别统计对应的仿冒域名的注册情况,发现只有当目标域名长度小于5 时,对应的仿冒域名的注册比重稍低,除此之外,域名长度对仿冒域名的注册影响很小。此后,Agten等[13]再次指明,非法者在注册仿冒域名时,不再过多关注对应目标域名的长度。
1.2 仿冒域名检测技术
仿冒域名吸引了众多研究者的关注,他们通过检测仿冒域名和测量仿冒域名现象以分析背后的盈利策略。Moore等[9]通过手动检查2 195个候选仿冒域名样本,发现编辑距离为1或2的域名基本都是仿冒域名。Kintis等[14]对域名中的品牌名称和其他关键词进行了组合研究,结果表明,仿冒域名被广泛用于执行各种类型的攻击,包括网络钓鱼、社会工程攻击、分支滥用、商标滥用和恶意软件。为了探索哪些统一资源定位符(Uniform Resource Locator,URL)相对其他URL更易受到仿冒域名攻击,Tahir等[15]使用不同的URL和DNS数据集定量测量了每个URL 的仿冒现象,交叉验证了域名中存在的某些语义特征使其更容易受到仿冒域名攻击。Agten等[13]对仿冒域名的相关信息进行了持续跟踪,发现仿冒域名在用户和抢注者之间具有流通性,抢注者可以通过变换网页类型改变盈利策略。Spaulding等[16]量化了不同域名仿冒方式在欺骗用户方面的有效性,发现用户通常能够识别在域名中添加或删除字符的仿冒域名,欺骗用户最有效的仿冒方式是字符的替换。
通过对已有的仿冒检测技术进行研究,可将其相关检测方法分为主动检测和被动检测两类[17]。主动检测方法[16,18-21]的基本工作原理为:首先确定一个受保护目标集合,然后按照一些构造策略得到所有可能的仿冒域名列表,针对这些构造的域名,收集Whois 注册信息、DNS 解析信息、网页信息,主动分析并发现识别可能已由抢注者注册的仿冒域名。常见的构造策略有缺少点、缺少字符、字符换位、字符替换、字符重复、顶级域替换等[12,18],常见的字符拼写错误原因如键盘上邻近字符击打错误[9]、视觉错误[22-23]、听觉错误[24]、字符的比特位错误[25]等也会体现在构造策略里。被动检测方法是在网络环境下进行的,通过分析流量中仿冒域名的方式并发现与受保护集合中元素编辑距离不超过2的域名,将之判断为仿冒域名。
显然,主动检测方法需要收集域名的相关信息进行判定,低级DNS 通信提供了有关DNS 请求和响应的足够详细信息,使对恶意域名进行更全面的搜索和分类成为可能[26-27],但这也限制了这些类型的检测方法的应用场景,因为它们必须具有监视DNS 服务器流量的权限,例如在大型互联网服务提供商(Internet Service Provider,ISP)或学校或公司的网络中心中,此外,访问DNS 服务器可能会导致隐私问题。主动仿冒域名检测方法存在存储和计算开销较大、隐私权限等问题,不适于在线检测。被动检测方法为了克服主动检测方法的这些不足,试图仅利用域名本身的特点进行检测,即其算法的输入仅仅是域名。研究[28-31]表明,良性域名和恶意域名在长度、后缀分布和有意义字数比等方面存在差异,可以作为检测的特征。被动仿冒域名检测方法大都以计算域名对之间的编辑距离为基础,但是对短域名的检测易产生大量假阳性结果,即对于顶级域名相同且二级域名字符串长度为2 的域名来说,其编辑距离永远不会超过2。以检测京东的域名“jd.com”的仿冒域名为例,所有权威域长度为2 的.com 域名(如“qq.com”)与“jd.com”的编辑距离都不会超过2,按照基于编辑距离的方法就会将其判定为仿冒域名,由此带来大量错误。Liu等[22]基于编辑距离算法提出了一种反向查找方法TypoPegging,可以快速准确地获得给定域中最相似的热门网站,但是没有很好地处理域名视觉模仿的问题。
可见,已有的主动、被动仿冒检测技术都存在一定的缺陷。基于此,本文设计了基于视觉特征的仿冒域名轻量级检测方法,并在真实数据集上验证了该方法的有效性,主要工作包括以下几点:
1)采用仅基于域名字符串的轻量级检测策略进行仿冒域名检测,降低了计算和存储开销,适合应用在大规模DNS 应用环境下的场景检测。
2)提出了域名视觉相似度的计算方法。一方面,结合域名视觉相似度构建仿冒域名检测模型能解决传统编辑距离在仿冒域名检测上带来的假阳性问题;另一方面,从视觉角度检测仿冒域名可以很好地处理域名视觉模仿的情况。
3)在真实数据集上进行了大量实验,验证了检测效果。
2 视觉特征测量
本章主要介绍域名的视觉特征测量方法,通过对传统编辑距离算法的改进并结合域名的视觉相似度来构建仿冒域名检测模型。
编辑距离是对两个给定字符串间差异程度的量化测量,编辑距离越小,两字符串越相似,当两字符串相等时,编辑距离为0。测量的方式是看至少需要多少次的操作把一个字符串转变成另一个字符串,其中,许可的变换操作包括:插入、删除和替换。
对于两个给定的字符串P 和Q,记其长度分别为m 和n,那么字符串 P 和 Q 之间的编辑距离记作 DP,Q(i,j),递归公式为:

其中:1 ≤ i ≤ m,1 ≤ j ≤ n。编辑距离算法伪代码见算法1,其空间复杂度和时间复杂度均为O(m*n)。
算法1 编辑距离。
function Edit_Distance(string P,string Q)
m<-length(string P);n<-length(string Q)
创建一个距离矩阵G[x + 1,y + 1]
#初始化
for(i = 0;i ≤ m;i + +)
G[i,0]= i
for(i = 0;i ≤ n;i + +)
G[0,i]= i
#递归
for(i = 1;i ≤ m;i + +)
for(j = 1;j ≤ n;j + +)
if(P[i - 1]== Q[ j - 1])
G[i,j]= G[i - 1,j - 1]
else G[i,j]= min(G[i,j - 1],G[i - 1,j],G[i - 1,j - 1]) + 1
#输出
return G[m,n]
传统编辑距离算法中并没有考虑域名字符的位置、字符相似度、操作类型(插入、删除、替换)等因素,统一赋值为相同的权重(设置为1)。从机器的角度考虑,编辑距离能够测量两个字符串的相似度。但是,在面对域名时,人的视觉却与机器的“视觉”不同,字符的位置、字符相似度、操作种类都可能影响该域名是否是仿冒域名的判断。
鉴于此,提出了基于视觉特征的仿冒域名轻量级检测方法,主要考虑字符的位置、字符相似度、操作种类对字符串相似度的影响,具体说明如下。
字符的位置:对于一个给定域名,分别改变其首字符和靠后位置的字符形成新域名,通常人们更容易察觉出改变首字符的那个域名的不同。 比如域名“nicrosoft. com”和“microsolt. com”与正常域名“microsoft. com”的编辑距离相同(编辑距离都为1),但是,对于“nicrosoft. com”和“microsolt.com”,人们更容易察觉出“nicrosoft.com”与“microsoft.com”的不同。这说明域名字符的位置对人视觉的影响不同,应对不同位置的字符赋予不同的权重。
字符相似度:字符不同,对人的影响也不同。比如域名“arnazon. com”(ARNAZON)与 正 常 域 名“amazon. com”(AMAZON)的编辑距离为2,“akazon.com”(AKAZON)与正常域 名“amazon. com”(AMAZON)的 编 辑 距 离 为 1。 即 使“arnazon. com”(ARNAZON)与 正 常 域 名“amazon. com”(AMAZON)的编辑距离更大,但是,却更难察觉“arnazon.com”与“amazon.com”的不同。因此,应对不同的字符赋予不同的权重。
操作种类:操作种类不同,人的视觉反应也不同。比如,对于“日本之窗”的域名“jpwindow.com”,当删除其第二和第五个字符时会变换为“jwidow.com”;当替换其第二和第五个字符为其他字符时会变换成“jqwimdow.com”。显然,“jpwindow.com”和“jwidow.com”容易区分开,而“jqwimdow.com”和“jpwindow.com”却相对困难;但事实上,“jwidow.com”和“jqwimdow.com”都与正常域名“jpwindow.com”有相同的编辑距离(编辑距离为2)。因此,应对不同的操作赋予不同的权重。
域名视觉特征的测量基于对编辑距离的完善,在编辑距离中加入了对字符位置、字符相似度、操作种类的考虑,将加权编辑距离定义为:

其中:1 ≤ i ≤ m,1 ≤ j ≤ n,∅ 表示空字符;Pi表示字符串P 的第 i 个字符,Qj表示字符串 Q 的第 j 个字符;sub 函数的计算公式如式(3)所示,其中,α 反映字符位置的影响,M 值反映字符相似度和操作种类的影响。

其中:c1、c2表示字符串中的某两个字符;l1、l2表示此两个字符在对应字符串中的位置。从式(3)可以发现,原编辑距离式(1)本质上是加权编辑距离的一种特殊情况,如式(4)所示:
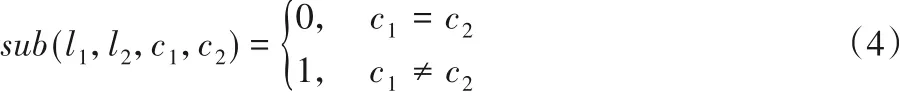
3 字符相似距离测量
本章主要介绍字符相似距离的测量方法,即计算M 值。对于字符“0”(零)和“o”(字母o),对应的M 值计算方法如图1所示。
两个字符的视觉相似距离计算过程描述如下:
1)将字符转换为黑白二值图片。
2)将字符二值图片转换为一维向量,转换方式如图1所示:
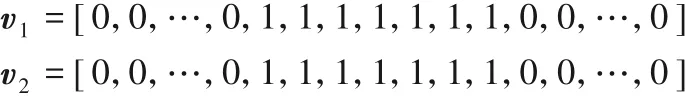
3)计算两个向量直接的视觉距离,向量v1和v2的视觉距离为:
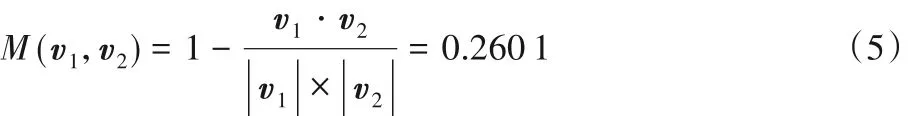
关于字符相似度,考虑以下几方面:
1)单字符与单字符间的相似度。这涉及到“0~9”“a~z”“-”(连字符)“.”(点字符)共计38 个单字符,因为域名字符串中只允许使用此38 个字符,且不区分大小写。此方面能排除相似单字符带来的视觉干扰,例如“0”(数字零)与“o”(字母o)、“1”(数字1)与“l”(小写字母 L)、“2”与“z”、“i”与“l”、“c”与“o”、“h”与“n”等。
2)两个“窄”字符与一个“宽”字符间的相似度。“窄”字符有“1”“-”“.”、“i”“j”“l”等,除此之外,其余都是“宽”字符。此方面是考虑到了两个“窄”字符与某个“宽”字符相似的情况,例如“ii”与“n”相似等。
3)两个“宽”字符与一个“宽”字符间的相似度。此方面考虑到了某两个“宽”字符与某个“宽”字符相似时带来的视觉干扰现象,例如“nn”(两个小写的字母N)与“m”、“vv”(两个小写的字母V)与“w”、“rn”(小写的R和N)与“m”相似等。
4)一个“窄”字符加上一个“宽”字符与其他“宽”字符间的相似度,例如“cl”(小写的C和L)与“d”相似等。
5)两个“宽”字符与两个“宽”字符间的相似度,例如“nm”与“mn”、“hn”与“nh”相似等。

图1 字符相似距离的计算过程示意图Fig. 1 Schematic diagram of computation process of character similarity distance
综上,综合考虑字符位置、字符相似度和操作种类对仿冒域名检测的判断影响,基于视觉特征的编辑距离算法伪代码见算法2。
算法2 基于视觉特征的编辑距离。
function Compound_Edit_Distance(string P,string Q)
删除string P,string Q 对应位置相同的字符得到string P1,string Q1
m<-length(string P1);n<-length(string Q1)
构造4个list,list1保存单字符间的相似值M1,list2保存单字符与
双字符的相似值M2,list3 保存双字符与单字符的相似值M3,
list4保存双字符与双字符的相似值M4
构造两个一维数组V0[n + 1],V1[n + 1]
for(i = 0;i ≤ n;i + +)
V0[i]= position_weighti
for(i = 0;i ≤ m;i + +)
V1[0]= i
for (j = 1;j ≤ n;j + +)
if(string P[i - 1]==string Q[ j - 1]):
V1[ j]= V0[ j - 1]
else if 当前比较的两个字符in list1:
V1[ j]= min(V0[ j]+ position_weight,V1[ j - 1]+
position_weight,V0[ j - 1]+ position_weight*M1)
else if 当前比较的两个字符in list2:
V1[ j]= min(V0[ j]+ position_weight,V1[ j - 1]+
position_weight,V0[ j - 1]+
position_weight*M1,V0[ j]+
position_weight*M2)
else if 当前比较的两个字符in list3:
V1[ j]= min(V0[ j]+ position_weight,V1[ j - 1]+
position_weight,V0[ j - 1]+
position_weight*M1,V0[ j]+
position_weight*M3)
else if 当前比较的两个字符in list4:
V1[ j]= min(V0[ j]+ position_weight,V1[ j - 1]+
position_weight,V0[ j - 1]+
position_weight*M1,V0[ j]+
position_weight*M4)
for(j = 0;j <= n;j + +)
V0[ j]= V1[ j]
#输出
return V1[n]
4 实验与结果分析
本章利用所提出的策略构建了一个仿冒域名检测的原型系统,并且在真实数据集上进行测试。实验环境为Windows 10 主机,8 GB 内存,512 GB 固态硬盘(Solid State Disk,SSD),编程软件为JetBrains PyCharm,编程语言为Python。所选用的实验对比方案采用了目前最常用的基于编辑距离的判定方案。
4.1 评价标准
所有实验都在真实的数据集上进行,且对所有技术都给出了性能评价,评价的指标包括精确率、召回率和F1值。
精确率针对预测结果而言,它表示预测为正的样本中有多少是真正的正样本。“预测为正”有两种可能,其一是把正类预测为正类,其二是把负类预测为正类,精确率即是第一种情况所占的比重。召回率针对原来的样本集而言,它表示的是样本中的正例有多少被预测正确了。预测时也有两种可能,其一是把原来的正类预测为正类,其二是把原来的正类预测为负类,召回率即是第一种情况所占的比重。精确率和召回率取值在0~1,数值越接近1,评价结果就越高。但研究表明,精确率与召回率两者基本存在一种“互补”的关系,即其中一个的值必随另一个值的增高而降低。所以需要一个调和的度量标准,F1值即为精确率和召回率的调和平均值,它可以综合这两个指标,直接被用来评价被评估对象的整体水平。对分类器的精确率P(Precision)、召回率R(Recall)和F1值的定义如下:

其中:真正例TP(True Positive)表示样本为正类,预测结果也为正类的个数,即分类器能够正确地检测出仿冒域名;真负例TN(True Negative)表示样本为负类,预测结果也为负类的个数,即分类器能够正确地检测出正常域名;假正例FP(False Positive)表示样本为负类,预测结果为正类的个数,即分类器不能正确地检测出仿冒域名;假负例FN(False Negative)表示样本为正类,预测结果为负类的个数,即分类器不能正确地检测出正常域名。
4.2 数据集
实验的数据来源于真实数据。其中目标域名来自Python编程爬取Alexa 排名靠前的域名,由于Alexa 根据域名三个月累积的访问信息为排名依据,因此使用这些数据作为白名单比较合理。实验数据集的规模为33 412,其中正样本数为16 273,负样本数为17 139。
正样本数据构造:对于Alexa 排名前500 的域名,利用NCC Group 在 GitHub 上开源的 typofinder 工具[32]获得其仿冒域名列表。该工具基于常见的仿冒域名构造策略对给定域名构建可能的候选仿冒域名列表,并主动获取每个候选域名的相关信息来判定其是否为真实的仿冒域名,因而精确率相对较高。对这500个域名,限制域名长度不大于20,总计获取了16 273个仿冒域名,构成了实验数据的正样本。
负样本数据构造:基于爬取出的目标域名构造了17 139个仿冒域名,这17 139 个域名是除去了上述500 个域名后从Alexa 排名前50 000 的域名中随机选择的目标域名构造产生的,域名长度同样限制为不超过20,为了更好地观察在短域名上的检测效果,限制域名对的编辑距离不超过3,排除了那500 个,所以这其中的任何一个域名都不会是另外一个网站的仿冒域名,由此构成了实验数据的负样本。
此外,typofinder工具的构造策略包含:
删减字符:原始“abc”,构造:“ab”“ac”“bc”;
复制字符:原始“abc”,构造:“aabc”“abbc”“abcc”;
转置字符(交换两个字符的位置):原始“abc”,构造:“acb”“bac”;
按照键盘上该字符的附近位置的字符替换原字符:原始“abc”,构造:“abd”“abf”“abv”“abx”“afc”“agc”“ahc”“anc”“avc”“qbc”“sbc”“wbc”“xbc”“zbc”;
键入错误的序列:原始“aabcc”,构造:“aabdd”“aabff”“aabvv”“aabxx”“qqbcc”“ssbcc”“wwbcc”“xxbcc”“zzbcc”;
按照键盘上该字符的附近位置的字符插入字符:原始“abc”,构 造 :“abcd”“abcf”“abcv”“abcx”“abfc”“abgc”“abhc”“abnc”“abvc”“aqbc”。
4.3 结果分析
对于判定一个域名是否为另一个域名的仿冒域名问题,将本文基于视觉特征的仿冒域名轻量级检测方法与基于编辑距离的判定方法进行了对比。基于编辑距离的方法需要计算两个域名间的编辑距离,如果编辑距离小于或等于设定的阈值θ,则认为前一个域名为后一个域名的仿冒域名,在实际应用中,编辑距离的阈值θ通常取1或2。一共做了10组对比实验,同组对比实验使用同样的数据集,组与组之间使用不同的数据集,这10 组对比实验的数据集都是基于4.2 节中提到的方法构造的正、负样本分别为16 273、17 139,总规模为33 412的数据集。表2 为基于编辑距离的判定方法在θ取值分别为1、2 和3 时的实验结果。对这10 次实验结果取平均可以看到,在基于编辑距离的判定方法中,当阈值θ= 1 时,F1值最大,为 0.904 9,但是随着阈值θ的增大,F1值会骤减;当θ= 2时,F1值降至0.844 5;当θ= 3时,F1值更是下降到0.521 2,所以用基于编辑距离的方法进行仿冒域名判定时,阈值θ设定为1,即当编辑距离小于1 时,就认为该域名为比对域名的仿冒域名。
此外,由表1 可以看到,基于编辑距离的方法在θ= 2 时精确率较低,这是由于存在这样的实际情况:对于“jd.com”和“qq.com”这样的域名对,此两个域名之间的编辑距离为2,在阈值(θ= 2)范围内,所以会被判定为仿冒域名,但事实上这两个域名都属于知名域名,并不存在仿冒现象。
在应用本文方法基于视觉特征的仿冒域名轻量级检测方法进行实验时,字符位置的权重α是这样设计的:从域名的首字符开始,权重设定为α的等比递减数值(α,α2,α3,…,αn),这样比较符合域名首字符的影响较大的现实情况。不同α取值得到的实验结果如图2所示,可以看到当α= 0.95时的效果最好,所以设定字符位置的权重定为0.95 的等比递减值(0.95,0.952,0.953,…,0.95n)。

图2 字符位置权重α不同取值下的评价结果Fig. 2 Evaluation results under different values of character position weight α

表1 基于编辑距离判定方法的实验结果Tab. 1 Experimental results of determination method based on edit distance
实验过程中,不再手动设置阈值θ,而是将阈值θ设定在(0,2)的区间内,从0开始每次递增0.01得到对应的F1值,让程序输出选择最大的F1值,同样进行10 次实验,每次实验所用的数据集都分别与上述基于编辑距离的判定方法的10 次实验的数据集保持一致。本文基于视觉特征的仿冒域名轻量级检测结果如表2所示。
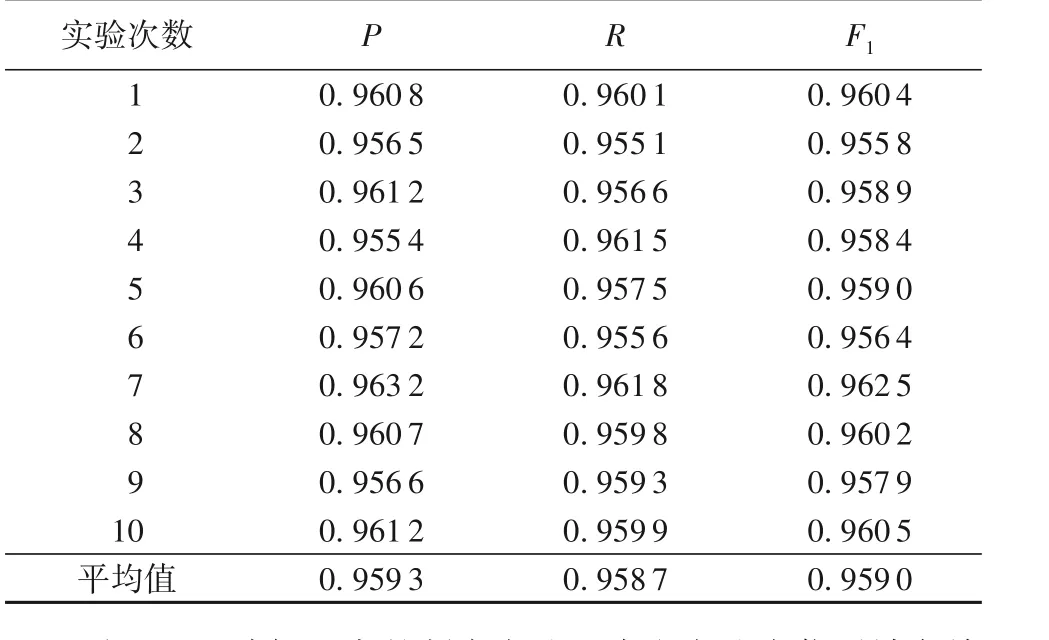
表2 基于视觉特征的仿冒域名轻量级判定方法的实验结果Tab. 2 Experimental results of lightweight detection method for typosquatting based on visual features
对于基于编辑距离的判定方法和本文方法在仿冒域名检测上的效果可以通过F1值进行比对,分别对基于编辑距离判定方法在θ分别取1、2、3的10次结果和本文方法的10次结果的F1值取平均,可以得到图3的检测效果对比。

图3 两种仿冒域名检测方法效果对比Fig. 3 Comparison of two detection methods for typosquatting
从图3 可以得到,本文基于视觉特征的仿冒域名轻量级检测方法相较基于编辑距离的判定方法在阈值θ= 1 和θ= 2时,F1值分别提高了5.98%和13.56%,由此可见,本文方法对于仿冒域名检测有更高的检测精确率和召回率,从字符的位置、字符相似度、操作种类三个方面改进传统编辑距离算法能解决域名视觉模仿的情况,使得仿冒域名的检测效果更好,准确度更高。
4.4 性能分析
在相同的实验环境下分别构造文献[26-27,33]中的模型、基于传统编辑距离算法的仿冒域名检测模型和本文基于视觉特征的仿冒域名检测模型,它们的性能比较结果如表4所示。
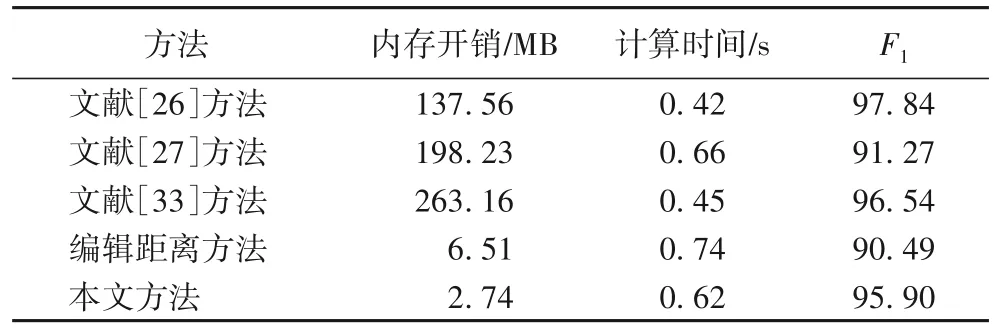
表3 各方法的性能比较Tab. 3 Performance comparison of various algorithms
由表4 可以看出,文献[26-27,33]中提出的检测方法的内存开销较大,这是因为这些算法均需要收集域名的相关特征信息如Whois 注册信息、DNS 解析信息、网页信息、流量等进行检测判断。与文献[26-27,33]中的方法相比,基于编辑距离的方法和本文方法内存开销较小,这是因为其算法输入仅是域名字符串,不需要利用DNS 解析信息等额外特征信息,能大幅减小存储开销,本文算法的“轻量级”也正是体现在此,算法仅利用域名的字符串进行判断。此外,相比原编辑距离算法(算法1),本文方法(算法2)在空间复杂度和时间效率上进行了优化,通过对算法结构的调整,将二维数组改为两个一维数组,其空间复杂度由O(m*n)减小到了O(min(m,n));通过删除字符串中相对应位置相同的字符后进行计算,使得计算量减小,所占内存减少,提高了计算效率,时间复杂度降为O(m1*n1)(m1≤m,n1≤n)。由表3 也可看出,本文方法在内存开销、计算时间和F1这几个指标上都优于原编辑距离算法。综合考虑算法内存开销、计算时间和F1值等可知,本文提出的基于视觉特征的仿冒域名检测方法性能更优。
5 结语
本文针对仿冒域名的检测问题,提出了一种轻量级的基于域名字符串的检测方法,通过综合考虑域名字符位置、字符相似度、操作种类对域名视觉的影响,提高了仿冒域名的检测效率。实验结果表明本文方法具有良好的检测效果,对于防范仿冒域名攻击具有重要意义。
