基于向量化标签的视频推荐算法研究与实现
2020-09-03许良武
许良武
(南京苏宁软件技术有限公司,江苏 南京 210000)
当今互联网技术迅速发展,信息爆炸时代随之而来。信息过载导致用户无法直接从中获取有效信息,推荐系统应运而生。常见推荐算法包括:基于隐语义模型、基于协同过滤算法、基于图的推荐[1]。以上3种方法应用广泛,但也存在不足:(1)新用户冷启动问题。(2)复杂兴趣推荐问题,如用户兴趣转移较快时推荐不准。(3)可解释性差,提取特征多为隐特征,推荐的可解释性不直观。
基于标签的视频推荐系统架构中,视频信息包括视频标题、标签、分类、视频简介、导演演员、评分、评论等。标签作为视频信息的高度抽象,通过分析用户标签可以精准地挖掘出用户兴趣偏好,从而为用户推荐满意的视频。标签推荐整体架构如图1所示。
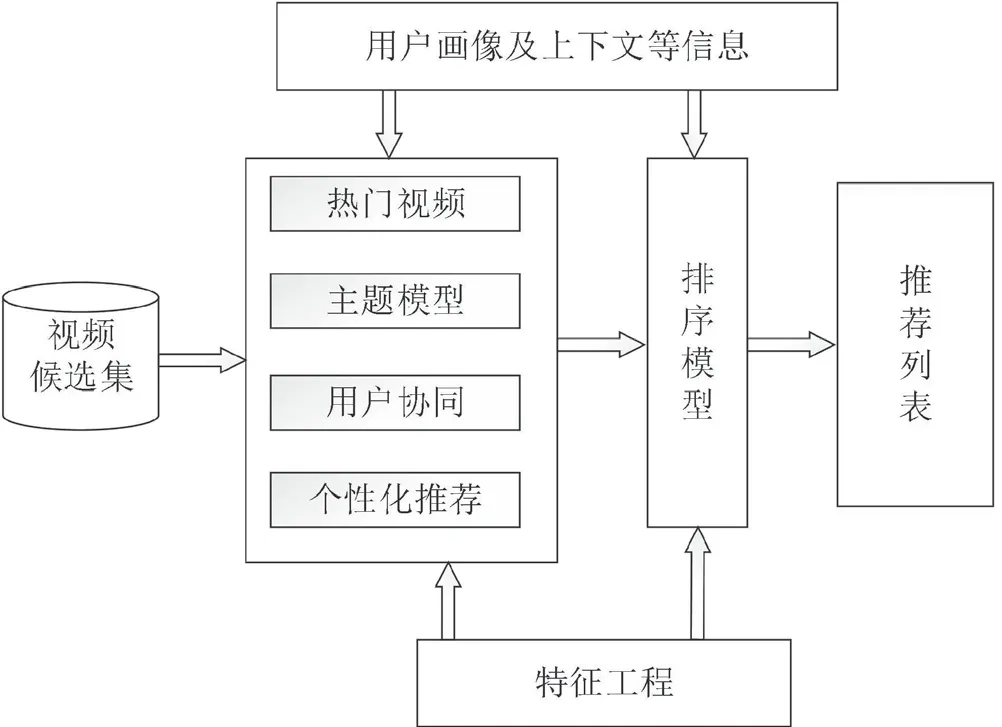
图1 标签推荐整体架构
1 标签概要
视频播放平台上的编辑功能为视频打上丰富且高质量的标签,能较好地抽象视频内容。视频可用于推荐的内容并不是很丰富,因此,基于标签推荐就成为一种重要途径[2]。视频信息如表1所示。
长视频通常分为电视剧、电影、少儿、综艺等众多类别,本文实验数据来自视频播放平台,在电影和电视剧上实验。用户规模选取1.2万,电影电视剧4 200,近3个月约304万条播放记录。主要基于表1中tags和type字段推荐,tags标签池包含132个标签。
2 相似度计算
相似度计算在推荐召回中有多种方法,基于标签的相似度量通常采用Jaccard系数和余弦相似度。
Jaccard系数计算如公式(1)。给定两个集合的交集与并集的比值,值越大说明相似度越高。若两个集合任一为空,则相似度为0。

余弦相似度,通过两个向量夹角的余弦值,衡量两者相似度[3]。由公式(2)计算:
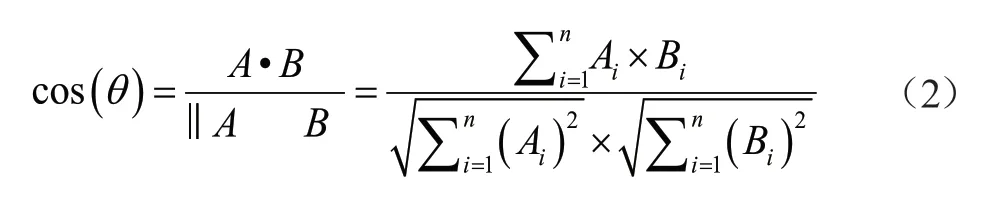
3 用户画像
为了达到千人千面的效果,根据用户历史观看行为,获得用户画像,从而推荐可能感兴趣的视频。tags标签池132维,而且近3个月人均播放视频数约253个,因此,构建132维用户向量能很好地表征用户兴趣偏好。基于标签的推荐,将用户观看历史所有视频标签统计作为用户对不同类型影片的偏好。

表1 长视频基础信息
3.1 热门标签降权
用户标签向量在相似计算中倾向于热门标签,不能充分体现用户兴趣点,因此,借鉴TF-IDF思想对热门标签降权[4]。如式(3):

其中,λi为132维标签各维度的系数,Ni为每个标签在所有视频中出现的次数。
3.2 时间衰减
用户兴趣转移,观看行为距离当前越近,越能表征用户真实兴趣点,距离当前越久远,表征用户兴趣点的能力越弱。衰减系数为超参数,根据实验效果设定。本文实验选择衰减系数0.95,衰减周期为一周。
3.3 播放完整度
播放完整度在一定程度上体现了用户的喜爱程度,用户画像采用播放完整度作为不同视频标签对用户画像的贡献度。
用户画像完整过程:首先,根据时间衰减,计算不同视频的标签权重,乘以播放完整度体现对用户画像贡献度的差异,接着将所有观看历史标签累加到132维的用户标签向量,再结合各维度系数λi,获取用户对不同兴趣标签的偏爱程度,最后,对标签向量归一化得到标准化的用户向量。
4 基于标签的多路召回
推荐场景主要有“相关推荐”和“猜你喜欢”。“相关推荐”采用主题模型,“猜你喜欢”则采用多路召回,如热门视频、用户协同、个性化推荐、主题模型等多维度兼顾用户喜好和覆盖度。
4.1 热门视频
长视频的电影、电视剧等不同类型下,根据近一周视频播放量、评论数、点赞数综合评分获得热门视频。
近一周播放量、评论数、点赞数升序排序,分别通过公式(4)映射到[0.5,1]范围。由公式(5)加权计算综合评分,根据评分降序排序取TOPN获得热门视频。

其中,score为评分,sort_no为排序序号,size为视频规模。
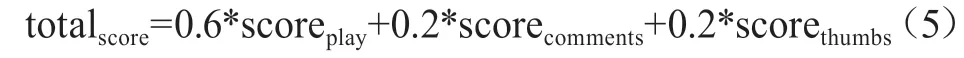
其中,totalscore为综合评分,由播放量、评论数、点赞数评分6∶2∶2加权获得。
4.2 主题模型
视频标签通常3~5个,而标签池规模达到132个,视频132维标签向量化表示计算视频之间的相似度过于稀疏。因此,采用Jaccard相关系数计算相似度,倒排取TOPN。
例如,3个电影的标签分别为:A=(动作,爱情,武侠,香港),B=(冒险,动作,惊悚,剧情,欧美),C=(冒险,动作,剧情,大陆)。通过Jaccard系数计算,J(A,B)=0.125,J(A,C)=0.143,J(B,C)=0.5,从而得到B与C更相似。若当前视频是B,则给用户推荐顺序为C,A。
主题模型基于物品的相似度召回,同时结合导演演员标签信息,从而获得相似度较高的视频。
4.3 用户协同
用户协同作为应用最广泛的推荐算法,寻找相似用户群,根据群体智慧推荐,通常可获得一些相似度不高,但能让用户惊喜的推荐效果,拓展用户的兴趣范围[5]。本文基于多标签的用户画像向量,通过余弦相似度、度量不同用户的相似度,并排序得到近邻集合,将近邻用户历史播放视频聚合统计,按观看次数,倒排取TOPN,最终过滤目标用户已观看视频。
最近邻用户规模过小,无法体现集体智慧效果,规模过大又趋于热点视频。因此,近邻规模的选择对用户协同至关重要。本文选择近一周播放历史作为预测集,近3个月播放记录除预测集外均为训练集。近邻规模从50起,按50间隔递增,不同近邻数情况下计算的准确率和召回率,如图2所示。
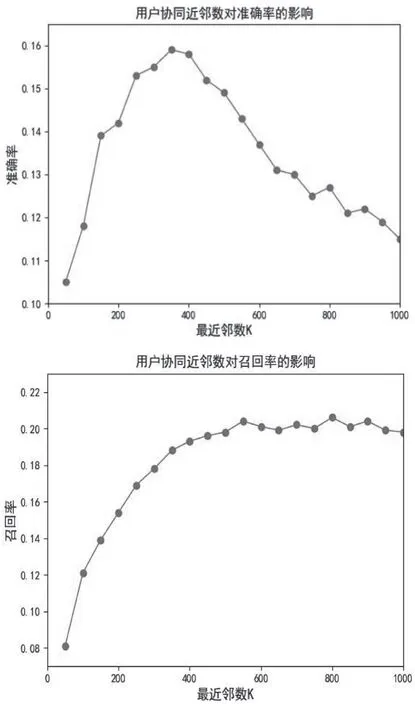
图2 最近邻数K对用户协同效果的影响
从准确率和召回率曲线来看,用户规模较小时准确率和召回率均较低,当近邻规模增加时两指标均有较大提升,当用户规模达到400附近时准确率最高,此后开始逐渐下降,而召回率在500左右达到最高,后续维持在一定水平,当规模超过800缓慢下降。通过准确率和召回率指标综合权衡,选择近邻数为400效果最佳。
4.4 个性化推荐
基于上述用户画像向量,同时,将视频表示为132维归一化向量,采用余弦相似度计算用户与视频之间的相似度。本文采用向量矩阵运算如图3所示,用户矩阵为N行132列,视频向量转置得到132行M列,矩阵相乘获得N行M列矩阵,用户向量和视频向量均为归一化向量。因此,最终的N×M矩阵为N个用户分别与M个视频之间的相似度,根据相似度取TOPN,过滤评分较低的视频,得到用户的个性化推荐列表。
5 排序模型
多路召回为粗排策略,极大地缩小了推荐结果集,从多个角度覆盖用户的兴趣,但不同召回集之间排列顺序未知,因此,需要精排模型获得统一的排序。
本文采用图4经典的3层DNN模型[6],基于标签的用户画像向量(132维)、视频向量(132维)以及上下文(位置、设备类型、网络类型、播放时间等)信息Embedding方式构成自变量,用户观看历史的播放完整度为因变量,迭代训练模型,最终将多路召回集构建Embedding特征通过模型预测用户对每个视频的播放完整度,倒排取TOPN。
通过DNN模型预测播放完整度,将完整度较高的视频列表推荐给用户,兼顾用户兴趣及视频相似度的同时,尽可能地将高质量视频推荐给用户,以此来提升用户的满意度和播放时长。
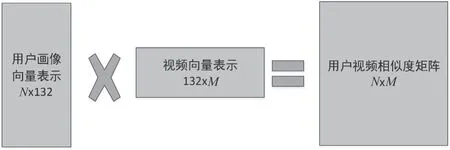
图3 标签用户画像与视频向量矩阵运算相似度矩阵
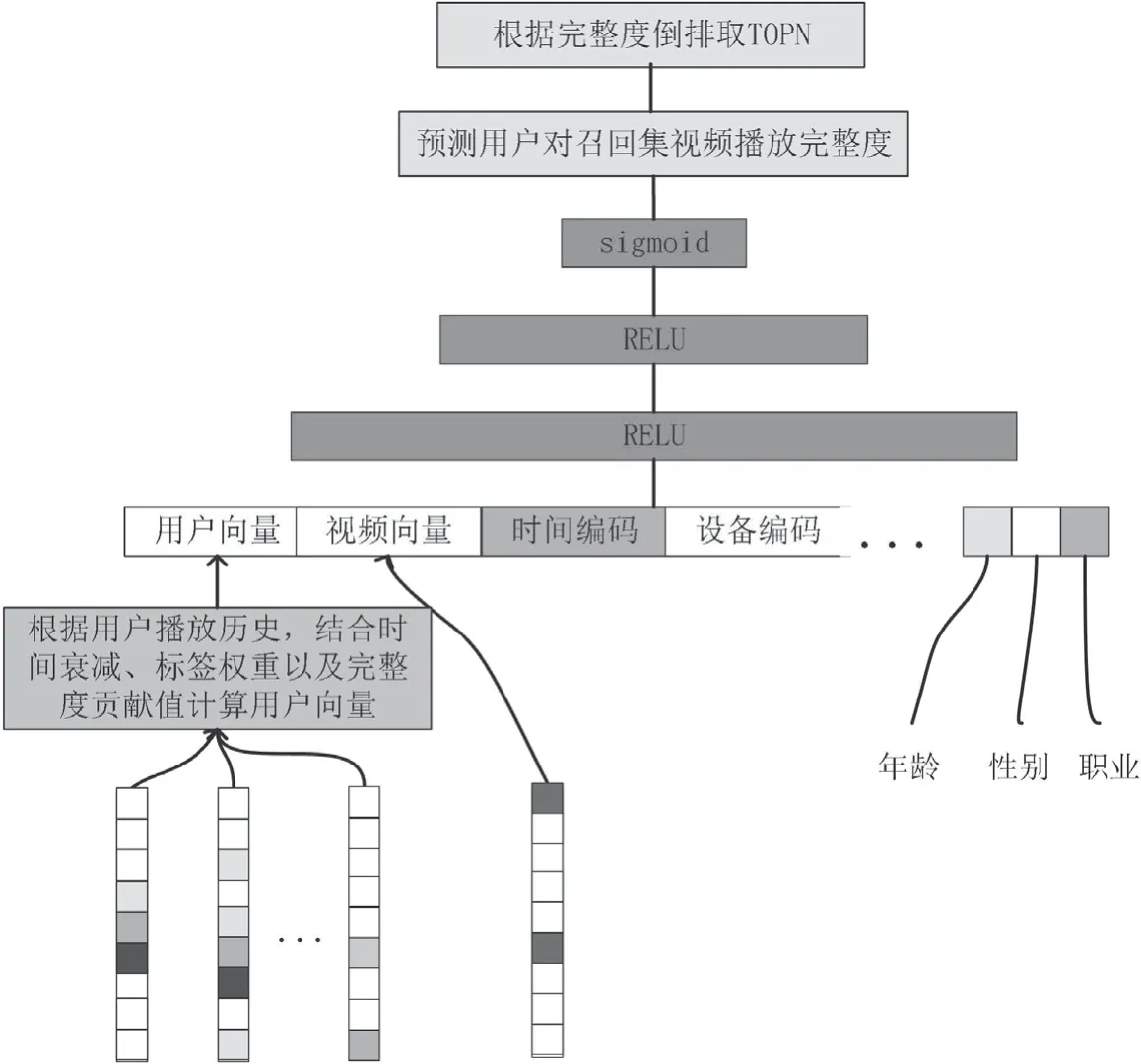
图4 DNN播放完整度预测模型
6 结语
本文研究和实现基于标签的视频推荐系统。多路召回策略后,基于标签的用户画像向量、视频向量以及上下文信息构建Embedding特征向量,通过3层DNN模型来预测用户对视频的播放完整度,根据完整度值取TOPN推荐给用户。通过融合本文基于标签的推荐算法,经过一周的线上测试数据发现,UV提升2.3%,PV提升12.6%,人均播放次数提升8.1%,人均播放时长提升15.3%。兼顾用户兴趣和视频质量,最终获得令人鼓舞的推荐效果。
