基于XGBoost的无线传播预测模型
2020-09-02朱家鹏段宇帅
朱家鹏 段宇帅


摘 要:传统的无线传播模型通常需要根据经验模型对传播场景进行划分。为了解决其在实际应用中不够精确的问题,通过在大量工程参数中设计并选用合适的特征参数作为模型输入,构建基于机器学习方法XGBoost的无线传播预测模型,实现新环境下无线信号覆盖强度的准确预测。实验结果表明,该模型相较于基于长短记忆网络(LSTM)、線性回归方法,预测均方根误差最小,为9.101。该方法在预测精度和模型鲁棒性上都较好,对在不同场景下的信道传播路径损耗进行准确预测具有重要意义。
关键词:集成学习;无线传播模型;数据分析;特征工程
DOI:10. 11907/rjdk. 192477 开放科学(资源服务)标识码(OSID):
中图分类号:TP301文献标识码:A 文章编号:1672-7800(2020)008-0035-05
Abstract:Traditional wireless propagation models usually need to divide propagation scenarios based on empirical models. In order to solve the problem that it is not accurate enough in practical application, this paper designs and selects the appropriate feature parameters as input to the model through a large number of engineering parameters. The wireless propagation model based on machine learning XGBoost can accurately predict the wireless signal coverage in the new environment. The experimental results show that compared with the long-short memory network (LSTM) and linear regression method, the predicted root mean square error is 9.101, and the error is the smallest. The method of this paper is good in the accuracy of prediction and the robustness of the model. It is of great significance to accurately predict the channel propagation path loss in different scenarios.
Key Words: integrated learning; wireless propagation model; data analysis; feature engineering
0 引言
随着5G技术的长足发展与逐步普及,高效的网络估算以及合理的基站站址选择,在运营商部署5G网络中具有非常重要的意义。无线传播模型正是通过对目标通信覆盖区域内的无线电波传播特性进行预测,使得小区覆盖范围、小区间网络干扰以及通信速率等指标估算成为可能。由于无线电传播环境复杂、会受到传播路径上各种因素的干扰,如建筑物、湖泊、平原等,使电磁波不再以单一方式和路径传播而产生复杂的折射、散射、透射,因此难以建立一个模型实现对不同场景下特定地理位置的实际平均信号接收功率(RSRP)进行准确预测。
针对不同频段选择合适的无线传播模型,有助于5G通信系统的空口规划和硬件选型,使工程师预测特定站址在实际环境下的传播损耗,为网络规划及优化奠定基础[1]。在无线网络规划工程中, 传播模型预测传播损耗的准确性从根本上决定了无线网络规划的合理性[2-3]。现有无线传播模型一般可分为:经验模型、理论模型和改进型经验模型[4]。经验模型可从经验数据中获取固定的拟合公式,典型模型有Cost 231-Hata[5-6]、Okumura[7]等。理论模型主要根据电磁波传播理论,考虑电磁波在空间中的反射、绕射、折射等进行损耗计算,比较有代表性的是Volcano模型[8]。改进型经验模型通过在拟合公式中引入更多参数从而为更细分类的场景提供计算模型,典型的有Standard Propagation Model(SPM)[9]。
经典计算方法在处理复杂数据和捕获特征之间的内在联系方面还存在困难。近年来,随着机器学习的发展,大数据驱动的机器学习技术获得了长足进步,并且在语音识别[10]、图形图像处理[11-13]、自然语言处理[14]和模式识别 [15-16]领域获得了不错效果。正是因为在应用过程中的高实用性以及低复杂性使其与无线通信的紧密结合成为可能。
为了快速准确实现无线传播模型的预测效果,提高新环境下RSRP精度的准确预测,本文构建了一种基于集成学习方法极端梯度提升(XGBoost)的无线信号预测模型。本文运用数据清洗、特征设计和选择方法获取约38万条数据进行模型训练,选取10个相关指标作为参数特征。然后通过对特征的编码、归一化操作,将特征融合到XGBoost模型中进行训练。该模型采用5折交叉验证对模型评估并优化参数,最后调用模型参数预测新小区下的RSRP。在相同数据集下,与线性回归方法、长短记忆网络(LSTM)方法相比,该模型的拟合效果和预测性能整体较好,鲁棒性更强。
1 集成学习方法XGBoost
由集成学习方法可以推广出XGBoost的预测模型[17],如式(1)所示。
2.2 特征工程
本文选择决策树搜索算法用于特征产生过程[18],主要步骤如下:首先构建根节点,将从原始数据集提取出的所有特征放在根节点,选出一个最优特征;然后根据选中的特征将原始数据集分成子集,使得每一个子集得到最好的结果。此时,如果在子集中能够获得较好结果,就将子集分到相应的叶子节点上去。本文选择的特征参数如表1所示。
对原始数据集进行异常值清洗,本文通过栅格(X,Y)上的地物类型索引(Clutter Index)与栅格(X,Y)上的建筑物高度(Building Height)的相互关系进行第一步初步处理。表2中列举了一部分异常数据值,小区发射机的一些属性字段省略,例如当地物索引为10时,其对应的建筑物高度应该大于60m,则小于或等于60m的数据即为异常数据。
数据处理除上述方法外,本文通过观察数据集发现同一个小区的发射机相关属性信息大体一致,因此可以根据Altitude、Building Height、Clutter Index 3个特征先实现分组再进行数据合并,同时对相应的RSRP与Distance取其均值。本文将加粗标示的数据进行合并操作,如表3所示。
2.3 模型框架与构建
在无线信号传播过程中,站点工程参数和目标地理环境等因素对信号接收强弱有很大影响。为了更好地拟合不同特征参数与RSRP之间的关系,寻找设计合理的特征预测新环境下的RSRP,本文搭建了基于XGBoost的算法模型。该算法在每一轮训练结束后,会降低被正确分类的训练样本权重,增大分类错误的样本权重。多次训练后,一些被错误分类的训练样本会获得更多关注,而正确的训练样本权重趋近于0,得到多个简单的分类器,通过对这些分类器进行组合,得到一个最终模型。
考虑到输入特征数据的度量标准不统一,本文使用最大—最小标准化对原始数据进行线性变换,如式(12)所示。
其中,minA和maxA分别是属性A的最大值、最小值,x是A的一个原始值,通过最大—最小标准化映射到区间[0, 1]的值为[x]。
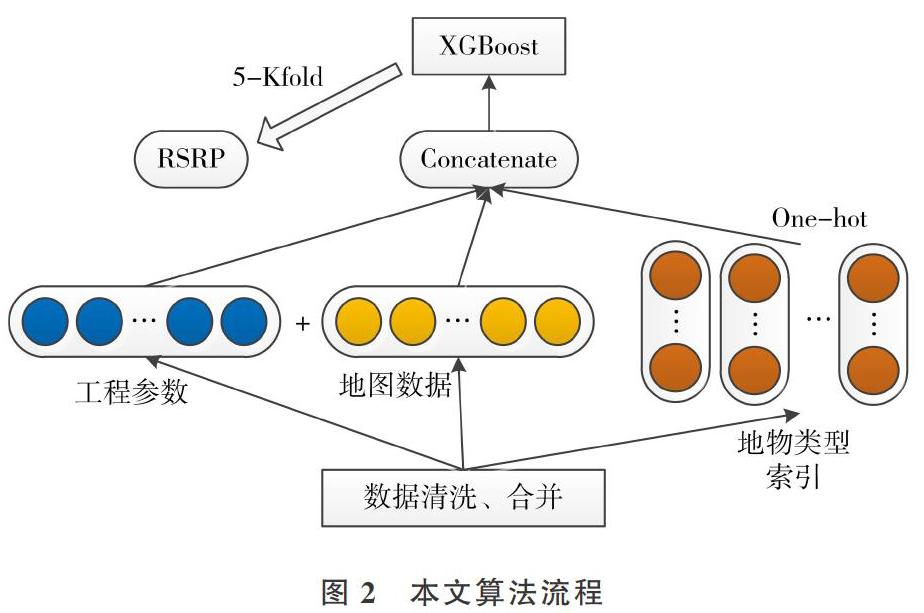
本文算法流程如图2所示。首先根据地物类型名称编号的含义清洗掉200万条数据,再通过对格栅上的海拔高度(Alitude)、小区站点格栅的地物类索引(Clutter_Index)、格栅上建筑物高度(Building_Height)3个条件进行分组合并数据,从而得到最终训练数据集38万条。然后选取工程参数、地图数据和两者计算的距离共8个指标作为特征,将两个地物类型索引进行单热编码后融合所有特征放入XGBoost模型進行训练预测。并且,使用5折交叉验证优化模型参数:先选择较高的学习速率(Learning Rate),再选择对应于此学习速率的理想决策树数量。XGBoost有一个很有用的函数“cv”,该函数可以在每一次迭代中使用交叉验证,并返回理想的决策树数量。对于给定的学习速率和决策树数量,进行决策树特定参数调优(max_depth, min_child_weight, gamma, subsample, colsample_bytree)。在确定一棵树的过程中,可以选择不同参数,进行xgboost的正则化参数调优(lambda, alpha)。这些参数可以降低模型复杂度,从而提高模型表现,最后降低学习速率,确定理想参数。最终参数为树的深度、学习速率、迭代次数和损失函数(max_depth=6,learning_rate=0.01,n_estimators=160,objective=“reg:logistic”)。在新的小区环境下可以调用保存的模型直接预测RSRP值。
2.4 实验结果与分析
本文数据集需要先自行处理和划分,然后将其应用于算法模型训练及预测。最终清洗得到38万条数据,对其进行可视化,结果如表4所示。可以看出,距离的标准差最大,距离值震荡最大。每个小区内的参数大多数都相同,不同小区数据集之间才会有很大差异,因此通过观察这些参数特征,直观上距离是主要影响因素。本文将在两个新的小区112501和115001预测RSRP,编号112501小区测试集有4 548个样本,编号115001小区测试集4 463个样本。
本文基于XGBoost算法模型的特征提取如图3所示。图中f0~f9代表依次输入到表中的特征参数(如表4所示),条形图上的数据代表重要特征个数。由图3可以看出,距离(Distance)是影响RSRP预测的主要因素,这与当初预想的相同。此外,两个小区预测后表现的特征重要性先后顺序没变,可以看出本文模型较稳定,不会剧烈变化,由此可以推断该模型泛化能力和准确率均较好。
为验证基于XGBoost的无线信号预测模型有更好的泛化性能和在预测结果上的优势,本文采用线性回归[19]和基于LSTM方法[20]进行对比。线性回归就是拟合一个线性函数,传统的线性回归会受因子多样性和不确定性影响,大量数据下表现不佳。而LSTM可以模拟数据之间的依赖关系,本文特征之间没有特别的时序关系,故效果会存在局限。本文在清洗出的相同数据集上进行训练测试,在表4中对比了LSTM、线性回归、本文使用的XGBoost模型3种方法的RMSE。结果表明,本文使用的XGBoost在不同交叉验证迭代上的训练集的RMSE均最优。本文XGBoost在所有网络结构中表现最好,因为本文网络结构能够更好地决策出比较重要的特征,惩罚选取的相对次要的特征参数。
3 结语
不同环境因素下信号会受到相应干扰,本文算法模型能够合理利用选择的特征预测RSRP并减少干扰,所使用的特征和输出数据有一定可靠性。并且,本文构建的基于XGBoost的无线信号预测模型,在与LSTM和线性回归方法的比较中表现最优。通过对数据可视化和实验结果的特征重要性分析发现,该模型能够较为精准并稳定地预测出各小区的RSRP。同时,本文研究还存在一些不足和改进空间:数据合并时对Distance和RSRP取均值可能影响差值较大的数据;模型还能进一步优化,模型融合和距离单调性都是需要探索的方向,因此未来可考虑融合规则和特征的特性。
参考文献:
[1] 杨光, 陈锦浩. 5G移动通信系统的传播模型研究[J]. 移动通信, 2018, 42(10): 32-37.
[2] 韦再雪,张涛,杨大成. 一种无线网络规划中的双斜率传播模型校正算法[J]. 电子与信息学报, 2007, 29(10): 132-135.
[3] 朱江,王婷婷,宋永辉,等. 无线网络中基于深度Q学习的传输调度方案[J]. 通信学报,2018(4):35-44.
[4] 刘欣. 基于GSM无线网络传播模型的基站发射功率开场测试研究[J]. 中国无线电, 2014(10): 54-55.
[5] VERMA R, SAINI G. Statistical tuning of Cost-231 Hata model at 1.8 GHz over dense urban areas of Ghaziabad[C]. New Delhi: International Conference on Computing for Sustainable Global Development,2016.
[6] WU H, ZHANG N, WEI Z, et al. Content-aware cooperative transmission in HetNets with consideration of base station height[J]. IEEE Transactions on Vehicular Technology, 2018,67(7): 6048-6062.
[7] 张延华, 段占云, 沈兰荪, 等. Okumura-Hata传播预测模型的可视化仿真研究[J].电波科学学报, 2001,16(1): 89-92.
[8] 方明. Vlcano模型的分析及应用[D].上海:复旦大学, 2008.
[9] LI H, WEI F, FENG X, et al. On improvement to the Shock Propagation Model (SPM) applied to interplanetary shock transit time forecasting[J]. Journal of Geophysical Research Space Physics, 2008, 113(A9):A09101.
[10] HOSHIMI M, NIYADA K. Method and apparatus for speech recognition[J]. Journal of the Acoustical Society of America,2018,109(3): 864.
[11] 白琮, 黃玲, 陈佳楠, 等. 面向大规模图像分类的深度卷积神经网络优化[J].软件学报,2018,29(4):137-146.
[12] 高如新, 李雪颖. 双边滤波的改进高光去除[J].中国图象图形学报,2018, 23(1):9-17.
[13] PASQUINI C, BOATO G, BOHME R. Teaching digital signal processing with a challenge on image forensics [SP Education][J]. IEEE Signal Processing Magazine, 2019, 36(2): 101-109.
[14] ONE K,KJELL K,GARCIA D, et al. Semantic measures: Using natural language processing to measure, differentiate, and describe psychological constructs[J]. Psychological Methods, 2018, 24(1): 92-115.
[15] SELVACHANDRAN G, GARG H, ALAROUD M, et al. Similarity measure of complex vague soft sets and its application to pattern recognition[J]. International Journal of Fuzzy Systems,2018, 20(6): 1901-1914.
[16] 聂栋栋, 贺悦悦, 马勤勇. 基于PCA_LDA和协同表示分类的人脸识别算法[J]. 燕山大学学报, 2019,43(2):86-91.
[17] CHEN T, HE T, BENESTY M. XGBoost: extreme gradient boosting[R]. Package Version 0.4-2,2015,.
[18] 陈辉林, 夏道勋. 基于CART决策树数据挖掘算法的应用研究[J]. 煤炭技术, 2011, 30(10): 164-166.
[19] 喻一凡, 曾道建, 李峰, 等. 线性回归的渡船精准定位方法研究[J]. 小型微型计算机系统, 2018, 39(7): 234-241.
[20] HOCHREITER S,SCHMIDHUBER J. Long short-term memory[J]. Neural computation, 1997, 9(8): 1735-1780.
(责任编辑:孙 娟)
