基于非关系型数据库的水文大数据存储方法研究
2020-09-01余国倩陶光毅封得华赵天宇
余国倩 ,陶光毅 ,封得华 ,赵天宇 ,李 薇
(1. 山东省水文局,山东 济南 250002;2. 山东国基光晔信息科技有限公司,山东 济南 250021;3. 南水北调东线山东干线有限责任公司,山东 济南 250103;4. 水利部信息中心,北京 100053)
0 引言
随着水文事业的发展和信息技术的进步,水文行业数据采集能力不断提升,能够收集到更多、更广的数据。这些数据呈现出多源异构、分布广泛和动态增长的特点,数据体量大,种类多,持续增长,已经形成水文大数据,且利用价值高,需要长期保存。从数据格式看,这些海量的水文数据既包括结构化数据,还包括各种格式电子文件,诸如文档、图片、语音、视频等非结构化数据。
洪勇豪等[1]提出现有的技术架构无法高效地处理多源异构的海量数据。黄忠佳[2]认为水利大数据的规模巨大到无法在合理时间内通过主流软件工具实现存储、管理。陈军飞等[3]认为水利大数据是用常规的数据分析方法难以在合理时间内获取、存储、处理和分析的数据集。当前,水文部门一般采用关系型数据库存储和管理水文结构化数据。龚琪慧等[4]认为当前水利数据中心主要釆用关系型数据库组织和管理结构化数据,非结构化数据釆用关系型数据库管理目录加文件存储方式组织管理,这种架构在数据存储方面存在瓶颈。关系型数据库对数据表格的定义有严格的要求,具有固定的表结构,扩展性差[5],已经无法满足各种类型的非结构化数据的大规模存储需求[6]。
面对海量数据的存储和处理要求,传统的关系型数据库已无法满足用户需求,甚至制约着海量数据的存储和处理[7]。非关系型数据库突破了关系型数据库严格的表结构,解决了关系型数据库不易表达复杂嵌套数据结构的问题。田伟等[8]认为非关系型数据库 TRIP 具有跨平台的存储机制,多维的层次数据存储结构,可容纳多种数据类型。莫荣强等[9]提出水利大数据存储支撑平台由关系型和非关系型数据库(NoSQL)构成,存储结构化和非结构化数据。因此,采用非关系型数据库存储海量的水文结构化和非结构化数据具有现实的应用价值。
1 非关系型数据库存储水文数据的基本要求和技术特点
1.1 基本要求
1.1.1 非关系型数据库结构的基本要求
要具有开放性、扩展性、可用性,能够存储多种类型、格式的水文结构化和非结构化数据,保障水文结构化和非结构化数据之间的可靠联系,能够与关系型数据库进行水文结构化数据和非结构化数据的交换。
1.1.2 非关系型数据库字段类型的基本要求
要求创建不同类型的字段,存储多种格式的水文数据,并能根据用途和需求变化对字段进行增加、删除和修改。字段类型包括字符串、数值、日期、时间、文本、二进制等字段,其中字符串、数值、日期、时间字段用于存储水文结构化数据;文本字段用于存储自由文本中的句子和段落,包括从文本格式的非结构化数据中抽取的文字信息;二进制字段用于存储文本、图像、音频、视频等水文非结构化数据。
1.2 技术特点
非关系型数据库在结构设计上与关系型数据库有很大的不同,共同特点是去掉关系型数据库的关系型特性,更加关注对数据高并发读写和对海量数据的存储。高艳霞等[10]提出非关系型数据库 TRIP是面向大数据对象设计开发的,不管数据对象是大是小,一律存放在数据库文件中。杨成月等[11]提出非关系型数据库不需要部署在高性能服务器上,运行在常规的 PC 集群中就可以支撑其高性能和高扩展性的表现,并将实验平台部署在 5 台普通 PC 机(i3-2100 处理器)上。王伟晨[12]提出非关系型数据库 HBase 具有良好的扩展性,适用于 PB 级别海量数据的存储。黄培[13]提出在文件型大数据存储系统平台的实验中部署 5 台 PC 机(i5-3420 处理器)用于非关系型数据库 MongoDB 存储数据。
2 数据来源与非关系型数据库存储水文数据的方法
2.1 数据来源
数据来源于山东省水文局提供的降水自记纸数字化提取的分钟降水数据、图像文件及人工记录信息,以及水文论文、测站图像文件。为进行水文大数据存储的实验,基于这些数据生成相当数量和容量的模拟水文数据。
2.2 硬件和软件环境
硬件环境如下:1)实验平台部署在 3 台 PC 机上,1 台 PC 机包含 i7-3770 处理器,内存容量为8 GB,硬盘容量为 2 TB;2 台 PC 机包含 G 3240 处理器,内存容量为 4 GB,硬盘容量为 2 TB。2)分别与 3 台 PC 机数据连接的磁盘存储装置,主要是若干个容量为 2 和 3 TB 的移动硬盘。3)若干个蓝光光盘,每个光盘容量为 100 GB。
软件环境如下:1)操作系统为 Windows;2)非关系型数据库为 TRIP;3)网络为局域网。
根据数据容量,可以增加移动硬盘的数量和容量。
2.3 存储方法
采用非关系型数据库 TRIP 存储水文数据,包括水文结构化和非结构化数据。数据库由记录组成,记录由字段组成。每个数据库由 3 个独立的数据库文件组成,分别是 baf,bif,vif 文件[14],对数据库中所有文字、数值、日期、时间内容进行索引。baf文件存放水文数据,bif 文件存放索引,vif 文件存放词汇片段索引。baf 文件存储在移动硬盘上,bif和 vif 文件存储在 PC 机或移动硬盘上,数据库管理系统安装在 PC 上,可以管理若干个数据库。
3 基于非关系型数据库的水文数据存储研究结果
3.1 水文结构化数据存储
以分钟降水量为例。按照存储水文结构化数据的字段类型基本要求,创建分钟降水数据库字段,主要有站码、站名、起始日、起时间和降水量等 5 个字段,字段定义如表 1 所示。

表1 分钟降水数据库字段定义
研究结果表明,分钟降水量标准文件为单站单日数据文件,文件格式为 csv 文件,每个 csv 文件存储 1 440 条分钟降水记录。采用 C/S 方式,分批多次将 csv 文件中约 14 亿条模拟分钟降水记录导入数据库,数据库文件容量约为 90 GB。
3.2 文本格式电子文件存储
以水文论文为例。水文论文为 word 和 pdf 格式文件,按照存储水文结构化和非结构化数据的字段类型基本要求,创建水文论文数据库字段,主要有论文名、文字信息、电子文件容量、电子文件等 4 个字段,字段定义如表 2 所示。
研究结果表明,将 word 和 pdf 格式文件放入1 个或多个文件夹,采用 C/S 方式,分批多次将文件夹中约 1 000 万篇模拟水文论文导入数据库,数据库文件容量约为 1.1 TB。

表2 水文论文数据库字段定义
3.3 图像格式文件存储
以测站图像文件为例。测站图像文件一般是jpg,tiff 和 png 等图像格式文件。按照存储水文结构化和非结构化数据的字段类型基本要求,创建存储测站图像文件数据库字段,主要有测站图像名、电子文件容量、电子文件等 3 个字段,字段定义如表 3 所示。
研究结果表明,将 jpg,tiff 和 png 格式文件放入 1 个或多个文件夹,采用 C/S 方式,分批多次将文件夹中 120 万个模拟图像文件导入数据库,数据库文件容量约为 1 TB。
3.4 水文结构化和非结构化数据存储

表3 测站图像文件数据库字段定义
以降水自记纸图像文件和人工记录信息为例。降水自记纸正面有降水迹线和人工记录信息,背面有人工记录信息,对降水自记纸进行双面扫描,生成正面和背面图像文件。降水自记纸图像文件是 jpg格式图像文件,人工记录信息是结构化数据。按照存储水文结构化和非结构化数据的字段类型基本要求,创建降水自记纸图像文件数据库字段,字段定义如表 4 所示。
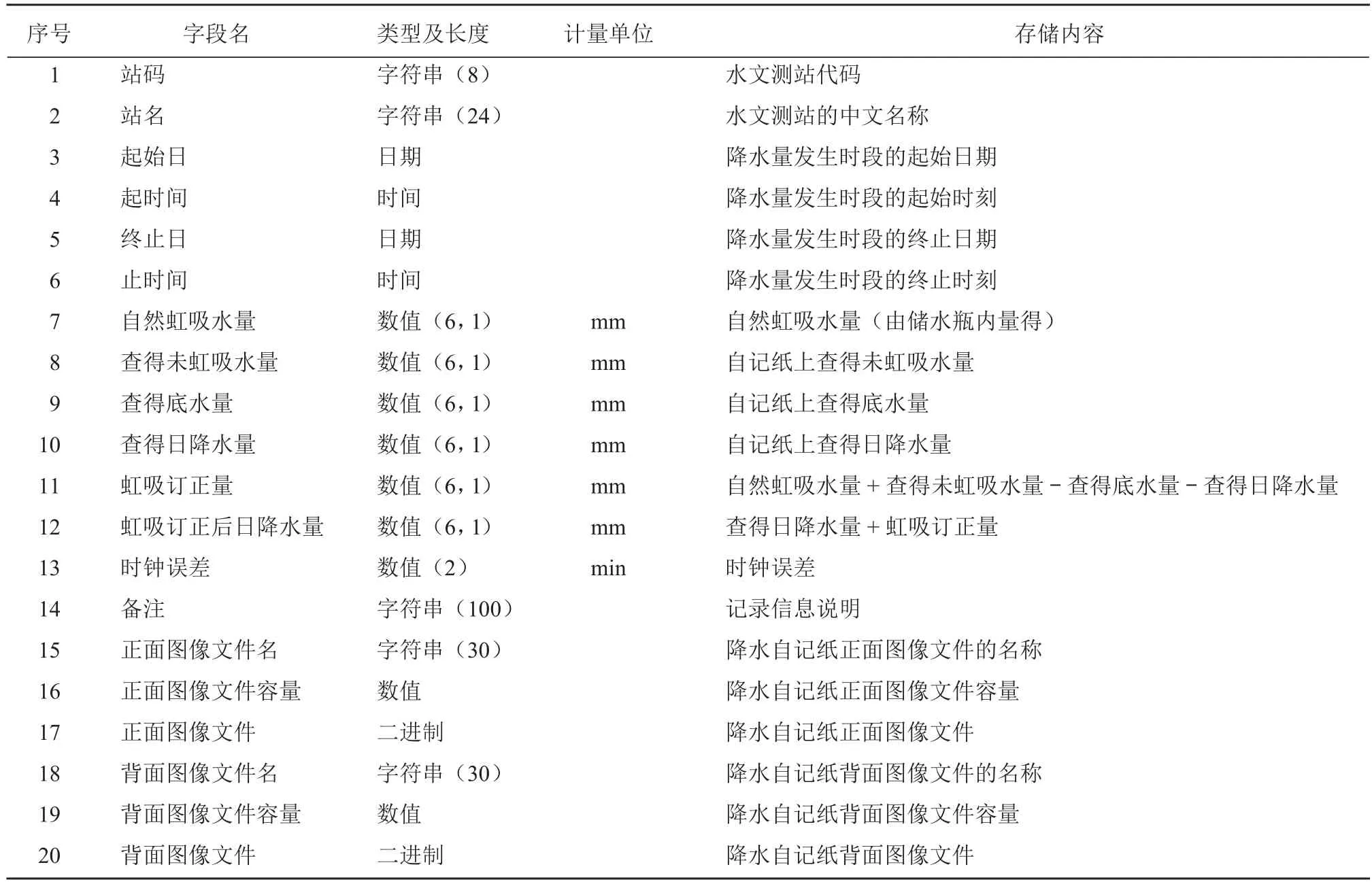
表4 降水自记纸图像文件数据库字段定义
研究结果表明,将降水自记纸正面和背面图像文件按照多站单年放入 1 个文件夹,将人工记录信息按照多站单年录入 Excel 文件。降水自记纸正面和背面图像文件名包含站码和终止日,与 Excel 文件中站码和终止日有匹配关联关系。采用 C/S 方式,分批多次将文件夹中约 50 万个 jpg 格式图像文件与 Excel 文件中的结构化数据按照匹配关联关系导入数据库,数据库文件容量约为 800 GB。
3.5 非关系型数据库备份与还原方法
3.5.1 非关系型数据库备份
离线备份是数据库重要的备份方式,备份介质可以是磁盘、固态硬盘和光盘。当水文非结构化与结构化数据一起装入数据库时,数据库会迅速变大。数据库备份有以下 2 种情况:
1)当非关系型数据库的容量小于备份介质的容量时,可直接对数据库整体进行复制备份。分钟降水数据库文件容量为 90 GB,分钟降水数据库整体复制备份到 1 张 100 GB 容量的蓝光光盘上。
2)当数据库容量超过备份介质的容量时,将数据库拆分成容量小于备份介质容量的若干个子数据库,然后将各子数据库分别复制备份到备份介质上。水文论文数据库文件容量约为 1.1 TB,测站图像文件数据库文件容量约为 1.0 TB,降水自记纸图像文件数据库文件容量约为 800 GB,都大于 100 GB 蓝光光盘的存储容量,需要将这些数据库拆分为若干个子数据库,每个子数据库文件的容量均小于 100 GB蓝光光盘的实际存储容量,然后将各子数据库分别复制备份到多张 100 GB 容量的蓝光光盘上。
非关系型数据库拆分是将 1 个数据库分成若干个数据完整的子数据库,拆分以记录为单位,因此,子数据库中的各记录关联数据完整,数据库管理系统可以直接在子数据库中完成该记录范围的数据检索和查询,不需要对同一记录的不同字段数据在各子数据库间进行数据检索,保持了各子数据库的数据完整性[15]。
3.5.2 非关系型数据库还原
1)数据库还原。整体备份的数据库直接还原到原数据库系统,可将备份在 100 GB 容量的蓝光光盘上的分钟降水数据库文件直接还原到原数据库系统。对拆分备份的若干个子数据库进行还原时,是将全部子数据库合并还原为一个数据库。将备份在所有蓝光光盘上的水文论文、测站图像文件、降水自记纸图像文件等子数据库文件分别合并还原到原数据库系统。
2)数据库合并。数据库合并是数据库拆分的逆操作,是将若干个子数据库合成 1 个数据完整的数据库。数据库合并是以子数据库中的记录为单位进行的,从各子数据库中提取相应的记录,按顺序将记录导入 1 个数据库[15]。
3.6 数据库数量与容量
在 PC 机上进行水文大数据存储实验,建立的数据库分析如下:
1)在 1 台 PC 机上建立 4 个数据库。分别为1 个分钟降水数据库(数据库容量约为 90 GB),1 个水文论文数据库(数据库容量约为 1.1 TB),1 个测站图像文件数据库(数据库容量约为 1.0 TB),1 个降水自记纸图像文件数据库(数据库容量约为800 GB),总容量约为 3 TB,数据库文件分别存储在 2 个移动硬盘上。
2)在 1 台 PC 机上建立 12 个数据库。分别为模拟的分钟降水、水文论文、测站图像文件、降水自记纸图像文件等数据库各 3 个,每个数据库容量和前面建立的 4 个数据库中相关数据库容量一致,则总容量约为 9 TB,数据库文件分别存储在 4 个移动硬盘上。
3)在 1 台 PC 机上建立 100 个模拟分钟降水数据库,总容量约为 9 TB,数据库文件分别存储在4 个移动硬盘上。
4 结语
非关系型数据库 TRIP 不需要部署在高性能服务器上,在硬件低配置的条件下,使用 PC 机和磁盘存储装置可以满足海量水文数据存储要求,充分证明了基于非关系型数据库开展水文大数据存储的可行性和可操作性,为水文行业存储水文大数据提供了新的技术途径。为解决数据库备份的问题,利用数据库拆分技术,可将大容量数据库拆分备份在蓝光光盘上。下一步,将研究构建由非关系型数据库与关系型数据库组成的分布式异构数据库,优化和完善水文大数据的存储系统。
