基于随机森林的非正规金融风险因素识别----以P2P为例
2020-08-31江萍萍郑瑞坤
江萍萍,郑瑞坤
(湖北工业大学理学院,湖北 武汉 430068)
世界银行将那些被中央银行监管控制的金融活动定义为正规金融[1],非正规金融则相对应于正规金融而言,当前学术界对其并没有明确的说法。国外学者认为非正规金融是除银行信贷、股票及债券市场等金融活动之外的融资机制[2],而国内学者则视之为民间借贷[3-4]。我国的金融制度和体系尚未完善,非正规金融与正规金融在不同因素冲击下表现出互补或替代关系[5],两者缺一不可。非正规金融可以有效降低农村居民陷入贫困的可能性[6],也提高了我国的经济效率,为民间金融逐步阳光化提供了保障[7],但其发展过程中也产生了一系列风险问题,甚至会干扰到金融市场秩序的稳定和国家宏观政策的调控[8]。近10年来,我国P2P行业高速发展的背后却衍生出异化的模式[9],网贷市场的监管缺失与非理性羊群行为导致众多金融乱象,加剧了金融脆弱性,这也凸显了健全外部监管体制和完善平台内部运营机制的紧迫性[10]。然而,P2P行业作为我国非正规金融市场的特殊组成部分,业务覆盖到传统金融触及不到的借款人和投资人,不仅弥补了我国传统金融机构的市场空白,还帮助一部分小微企业解决了融资问题。据“网贷之家”网贷资讯平台的研究报告显示,P2P行业的累计成交量在2019年6月底达到8.6万亿元。与此同时,湖南、山东、重庆等地区对辖区内的P2P网贷业务全部予以取缔,致使投资风险陡然加剧。本文基此,以P2P网贷行业为例,分析影响非正规金融在运营过程中的各种风险因素,为其良性发展提供决策依据。
1 P2P非正规金融风险识别模型的构建
国外学者从P2P内部运营特征探究风险影响因素,认为盈利能力高、流动性高和资产规模大的平台不易发生违约风险,而高负债和高杠杆的项目违约风险较高[11],国内学者主要采用Cox比例风险模型,以及逻辑回归模型、支持向量机等对平台风险进行测评[12-14]。本文的非正规金融风险因素的评估方法,除了识别非正规金融的风险,还需要对重要风险因素进行评估。国内学者在评价地下水水质、地表灰尘重金属污染,以及精准识别贫困等问题时[15-18],普遍采用随机森林模型,这一方面可以对问题实现分类预测功能,另一方面又可对各变量的重要性进行度量。因此,使用随机森林模型来识别P2P网贷平台是否存在问题并度量关键风险因素。
1.1 P2P非正规金融风险指标集构建
数据来源于“网贷之家”官方网站。该网站创办于2011年10月,是当前国内较为权威的第三方网贷机构。运用Python爬虫从网页爬取了2018年6—11月共6个月的月度成交数据以及平台状态(正常平台与问题平台)。每组数据包含四个维度的指标:“成交量”维度的指标包含成交量、平均预期收益率、平均借款期限、待还余额;“人气”维度的指标包含投资人数、人均投资金额、满标用时、前十大投资者待收金额占比;“平台运营”维度的指标包含注册资本、资金净流入、运营时间;“分散性”维度的指标包含借款标数、借款人数、人均借款金额以及前十大借款人待还金额占比。四个维度下共有15个特征指标(表1)。

表1 风险特征指标及含义
对表1中代表风险特征的指标进行预处理。删除缺失值后,得到共计370个平台的1790组成交数据;将平台状态分为正常平台和问题平台两类,每组数据包含15个风险特征指标和1个平台类别指标。
1.2 P2P非正规金融风险识别方法
以P2P平台为例,随机森林模型的风险识别过程(图1)包括以下三个步骤。
1)运用Bootstrap方法在初始P2P平台训练集中重复抽出n个平台训练集,每个训练集的样本容量与网贷平台原训练集一致,未被抽中的样本组成平台测试集,称作袋外数据OOB(Out of Bag)。这部分数据用来检验模型的预测识别效果。
2)分别对上述n个网贷平台训练集选择最优的风险因素作为分裂属性,得到n个决策树模型。使用R软件生成决策树的过程中,有影响模型准确性的重要参数,它们分别是mtry和ntree。mtry表示节点中用于二叉树的变量个数,即风险指标的个数,该值是从1至15逐一尝试,直到所对应的模型误判概率达到最低;ntree表示随机森林所包含的决策树数目,可通过图形大致判断模型误差稳定时的ntree值。
3)将k个决策树的结果进行组合,基于树分类器投票的多少形成最终结果,即可对平台的风险状态进行识别。

图1 随机森林生成流程
1.3 风险重要性度量
使用MDA值(Mean Decrease Accuracy)计算风险指标的重要性。MDA具体计算过程如下:
1)用网贷平台的测试集去测试已构建好的随机森林模型,得到n棵树的OOB误差;
2)将平台测试集中某个风险变量Q的值打乱,再次计算这n棵树的OOB误差;
3)对上述两次OOB误差的差值进行平均,得到单棵树对风险变量Q的重要性值。
(1)
从式(1)看出,变量重要性与MDA值的变化方向相同。
2 实证分析
2.1 P2P非正规金融风险特征
对所有风险指标的数据特征进行分析,各统计量如表2所示。从标准差来看,除平均预期收益率和平均借款期限之外的各风险指标均波动较大;从峰度和偏度来看,各指标均呈现不同程度的尖峰厚尾和有偏的数据特征,并且仅平均预期收益率和运营时间两个指标呈负偏态分布;另外,各指标的JB统计量和其对应的P值显示,所有指标均拒绝正态分布的原假设。

表2 各指标基本统计量
2.2 P2P非正规金融风险识别
本文中运用R软件实现随机森林分类过程。首先使用sample( )函数按0.7∶0.3的比例进行有放回抽样,将网贷平台数据集分为训练集和测试集。对70%的训练样本进行训练,选择mtry(图2)和ntree(图3)的最佳数值以确定最终的随机森林模型。
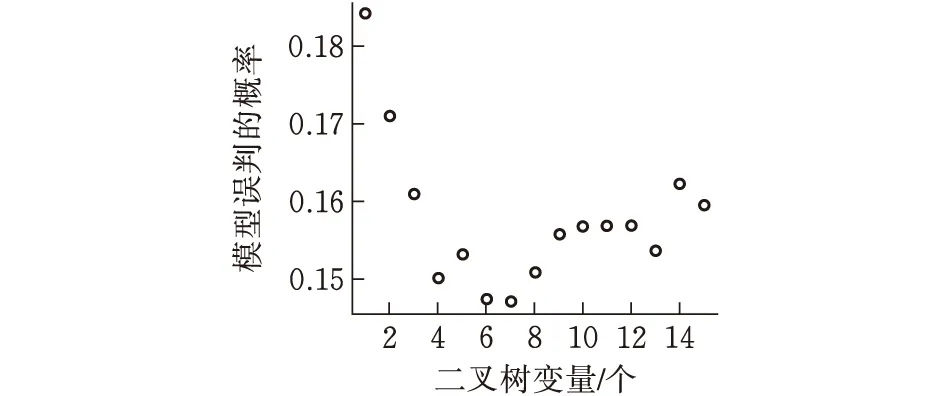
图2 二叉树变量个数及其误判概率散点图
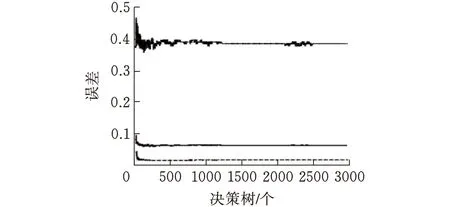
图3 决策树数量及其对应模型误差变化图
由图2通过对比可发现,当二叉树的个数即mtry=7时,模型误差最小;绘制mtry=7的情况下模型误差与决策树数量之间的关系图(图3)可知,当ntree在2600左右时,模型内误差保持相对稳定状态,因此将ntree选定为2600。两个重要参数值由此确定下来。
为了检验上述构建模型的分类预测效果,将测试集的数据代入模型中,测试集包含522组数据,其中472组正常平台数据,50组问题平台数据,分类结果如表3所示。正常平台的识别率达到93.43%,问题平台的识别率达到80%,总体识别率是92.15%。模型识别效果较好,可用于风险重要因素识别。

表3 网贷平台测试集预测分类结果
2.3 P2P非正规金融重要风险因素识别结果
根据训练集得到随机森林模型,输出各变量指标对应于正常平台和问题平台的重要性权重如表4所示,权重值越大表明该因素越重要。
从表4可以看到,对于正常平台,运营时间、平均预期收益率、前十大借款人待还金额占比、待还余额等风险因素比较重要,兼顾这些因素的平台一般拥有一定的人气,也较为安全。总的来说,需重点关注平台运营、成交量、运营时间三个维度的风险因素。运营时间长的平台风险管理水平较为成熟;平均预期收益率在正常范围内波动,贷款资金较为分散使得平台遭受违约风险的相对较低;待还余额在可承受范围,平台总体安全度较高。对于问题平台,除了重点关注运营时间、平均预期收益率以及待还余额之外,还需关注人均投资金额和满标用时这两个人气维度指标。问题平台可能因运营时间不长,未能积累足够人气,期望通过提高收益率来吸引投资者从而增加借款对象,若因运营时间过短而未能积累一定的风险防御经验,易导致资金周转不良等风险问题。

表4 平台风险因素对应权重
2.4 风险重要因素识别结果的验证
MDA值衡量的是某个风险变量受到干扰时随机森林模型准确率下降的程度,下降幅度越大则说明这个风险变量对模型的预测效果影响越大。测算结果见图4。
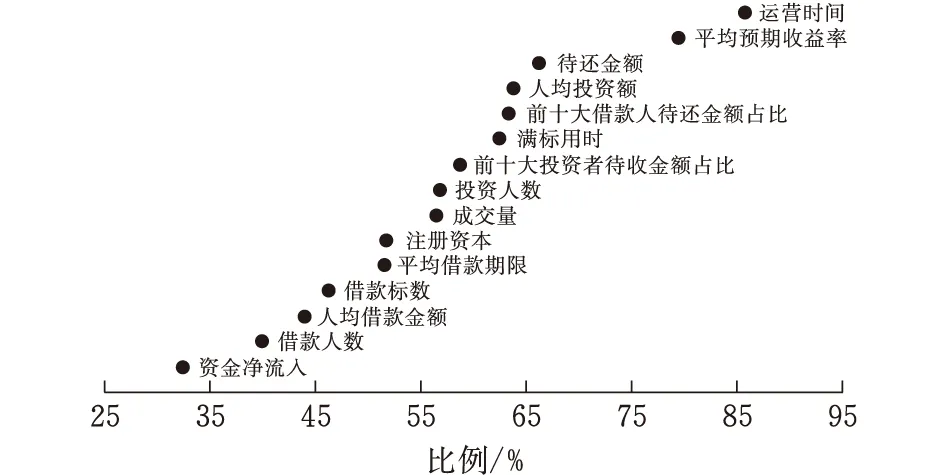
图4 MDA值及其对应风险因素的散点图
若不区分问题平台和正常平台,总体考虑MDA值。从图4可以看到,运营时间、平均预期收益率、待还余额、人均投资金额以及前十大借款人待还金额占比等风险因素的重要性较高,而借款人数和资金净流入的重要程度较低,这也与表4的变量权重所展示的结果总体一致,说明风险因素识别具有可靠性。上述因素可以作为P2P网贷行业风险管理关注的内容。
3 结论
以P2P网贷行业为例,运用网络爬虫方法收集数据,并运用随机森林分类方法,对非正规金融市场风险因素进行了研究。该方法对平台风险有较好的识别效果,得到平台的关键风险因素主要是运营时间、平均预期收益率、待还余额、人均投资金额以及前十大借款人待还余额占比等。对我国 P2P平台的风险进行分析,可以有效帮助投资对象识别 P2P网贷问题平台和正常平台从而选择优质的投资平台,避免因问题平台带来资金受损;对风险因素的重要程度进行评估,可以为政府部门和监管机构对非正规金融的风险监管提供一定的决策支持,并且对如何提高识别非正规金融风险提供了思路。
