一种改进的RFID系统的双向安全认证协议
2020-08-29陈明忠
陈明忠
(汕头职业技术学院机电工程系,广东 汕头 515078)
0 引言
RFID(radio frequency identification)技术是一种先进的自动识别技术,附着在防伪对象中的RFID标签具有揭下自毁功能,有效防止复制盗用.而UHF(超高频)射频识别技术是当前RFID发展的前沿,它具有读写距离远,标签成本低,读取速度快等优点,已经被应用到包括物流管理、交通运输[1]等各个方面.
一套典型的RFID系统由电子标签、读写器、上位机和远程服务器组成.如图1所示:

图1 RFID系统的组成
当带有RFID标签的物品经过RFID读写器时,读写器激活标签并通过无线电波将标签中携带的信息传送到读写器中,读写器通过串口将信息传送到上位机,上位机通过网线将信息传送到远程服务器的数据库中,以完成信息的自动采集工作[2-3].标签与读写器之间采用无线电波作介质,为不安全信道;读写器与远程服务器的数据库之间采用物理连接,为安全信道.
在不安全信道中,数据传输容易遭受恶意攻击,如非法读取、窃听、假冒、位置跟踪等,导致隐私信息泄露,从而影响了RFID系统的广泛应用[4].针对上述问题,本文在分析现有RFID认证协议的基础上,研究并设计了一种低成本、安全、高效的双向认证协议,确保标签与读写器间数据传输的安全性.
1 现有的RFID认证协议分析
目前,国内外学者已提出多种基于密码学的RFID认证协议,其中最具代表性的有Hash-Lock协议、随机Hash-Lock协议[5],但在安全性上都存在一定的问题.
1.1 Hash-Lock协议
初始状态下,每一个标签内存储有自身ID、密钥K和Hash函数,ID和密钥都由芯片厂商写入,具有唯一性.两者区别是:ID可以读出,易被复制,但密钥不可读出.后台数据库存储所有标签的ID、K和metaID,其中metaID=Hash(K),如图2所示.
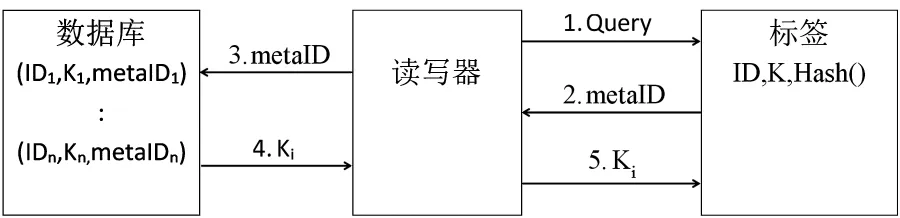
图2 Hash-Lock协议示意图
当标签收到Query后,就根据自己的K值计算metaID=Hash(K),并把metaID依次传回读写器和数据库.当数据库找到metaID所对应的Ki值,就将Ki值依次发给读写器和标签,标签将Ki值和自己的K比对,若相等,则认证成功.
在Hash-Lock协议中,使用metaID代替ID来标识标签,有效防止标签信息被非法读写器读取,但是K值在整个过程中以明文方式传输,无法防止攻击者对标签的位置追踪和重放攻击.
1.2 随机Hash-Lock协议
初始状态下,每一个标签内存储有自身ID、随机数生成器和Hash函数,后台数据库存储所有标签的ID[6],如图3所示.

图3 随机Hash-Lock协议示意图
当标签收到Query后,就生成一个随机数r,并计算H(r||ID),随后将r、H(r||ID)传回读写器和数据库.数据库遍历每个标签的ID,若存在H(r||IDi)=H(r||ID),则将IDi依次发给读写器和标签,标签将IDi和自己的ID比对,若相等,则认证成功.
在随机的Hash-Lock协议中,由于标签的每次应答都有随机数参与,并且进行加密,可以有效防止攻击者的窃听和位置[7]追踪.但ID仍然以明文的方式在读写器和标签中传输,无法防止攻击者对标签的重放攻击.
2 一种改进的RFID双向安全认证协议设计
上述两种典型的RFID认证协议各具长处和短处,为扬长避短,本文有针对性地对两种典型的认证协议进行改进,设计了一种新的基于Hash函数的RFID安全双向认证协议,如图4所示.

图4 基于Hash函数的RFID双向认证协议示意图
初始状态下,每一个标签内存储有自身ID、密钥K、随机数生成器和Hash函数,并处在锁定读取状态;后台数据库存储所有标签的ID和K值,以及Hash函数.认证过程如下:
(1)读写器生成一个随机数r1,并将r1和读写请求Query发送给标签;
(2)标签接收到Query和r1后,自己也生成一个随机数r2,并计算H(r2⊕K),再将r2,H(r2⊕K)传回读写器中;
(3)读写器将 r1,r2,H(r2⊕K)转发给后台数据库;
(4)在后台数据库中,针对每个标签的K值,循环计算每一个标签的H(r2⊕Ki),若存在H(r2⊕Ki)=H(r2⊕K),表示被请求的标签为有效标签,则退出循环,继续计算H(r1⊕r2⊕Ki),并将H(r1⊕r2⊕Ki)发送给读写器;若不存在,则认证失败;
(5)读写器将H(r1⊕r2⊕Ki)发送给标签,标签根据自己的密钥K计算H(r1⊕r2⊕K),若H(r1⊕r2⊕K)=H(r1⊕r2⊕Ki),则标签认为读写器为有效读写器,于是去掉锁定状态,进入应答状态等待读写器读写.
3 新设计协议的安全性分析
目前,对认证协议的安全性分析有两种方法,一是形式化分析,采用BAN逻辑对认证协议进行形式化推理,确定预期目标,并对预期目标加以证明.二是非形式化分析,用自然语言分析认证协议是否存在各种安全隐患和缺陷[8].
3.1 新设计协议的形式化分析
用T表示标签,R表示读写器,针对图4的形式化推理如下.
(1)建立协议的初始假设

(2)建立协议的理想化模型
M1:R → T:Query,r1;
M2:T → R:H(r2⊕K),r2;
M5:R→T:H(r1⊕r2⊕Ki);
在M1中,信息为明文传递,不影响协议的安全性,可以去除;在M5中,Ki=K.采用BAN逻辑语言表示改进后的式子,得协议的理想化模型如下:
M2:R◁H(r2,K);R收到由r2、K组成的,并经Hash()函数加密过的信息;
M5:T◁H(r1,r2,K);T 收到由 r1、r2、K 组成的,并经 Hash()函数加密过的信息.
(3)确定预期目标,并加以证明


3.2 新设计协议的非形式化分析
下面针对攻击者的一些常见的攻击行为,对本文设计的双向认证协议的安全性进行分析.
(1)防非法读取:当RFID标签与读写器双向认证之后,RFID标签才会取消锁定状态,等待读写器读写.如果使用的标签或读写器有一个是非法的,标签中的信息就不会被读写器读取.本协议有效防止标签信息被非法读取,避免了标签信息泄露[9].
(2)防窃听:在每次传输之前,作为标识标签的密钥K都要与随机数异或后,再用Hash函数加密成为密文.在传输过程中攻击者即使截获这些密文,也不能破解其中的内容.
(3)前向安全性:由于每次认证时都有随机数参与,标签和读写器每次的输出值都是不同的.攻击者即使截获某一次会话的输出值,也不能以之作为下一次认证的信息[10].本协议能有效保证前向安全性.
(4)防位置跟踪:由于每次认证时都有随机数参与,标签每次的输出值都是不同的,毫无规律可言.攻击者即使截获大量的输出值,也不能区分不同标签的特征,更不能推断标签的位置信息[11].本协议能有效抵御位置跟踪.
(5)防重放攻击:由于每次认证时都有随机数参与,标签和读写器每次的输出值都是不同的.攻击者即使截获某一次认证的输出值,也不能通过重新发送该输出值的方法来获得下一次认证[12].本协议能够防止重传及假冒攻击.
三种协议安全性能比较,见表1.

表1 三种协议安全性能比较
4 三种协议的时空性能
安全协议的设计,不仅要考虑RFID系统的安全问题,还要考虑RFID系统的计算量和存储量问题.如果计算量和存储量太大,那么势必降低认证效率,增加RFID系统的成本[13].因为普通的RFID标签的容量小、计算能力低,所以选取的安全协议必须满足较好的时空性能.
(1)协议的时间性能
协议的时间性能是指一个协议单次成功认证时,RFID系统各部件(如电子标签、读写器和数据库)各自花费的时间,它决定着RFID系统的计算量[14].
假设RFID系统有n个标签,定义TH为一次Hash函数运算时间,TXOR为一次异或运算时间,TR为产生一个随机数时间.下面统计图4新设计协议的时间性能.
①RFID标签:产生一个随机数,开展2次Hash函数运算,3次异或运算,因此RFID标签的时间性能为:2TH+3TXOR+TR.
②读写器:只产生一个随机数,因此读写器的时间性能为:TR.
③后台数据库:假设遍历数据库中最后一个K值即Kn,才存在H(r2⊕Kn)=H(r2⊕K),此时开展n次Hash函数运算和n次异或运算.随后,数据库又开展1次Hash函数运算和2次异或运算,因此数据库的时间性能为:(n+1)TH+(n+2)TXOR.
(2)协议的空间性能
所谓协议的空间性能,是指采用该协议之后,RFID系统各部件(如电子标签、读写器和数据库)各自存储的标签标识、标签密钥或读写器标识的长度[15].它决定着RFID系统的存储量.
以一个任意长度的消息作为输入,Hash函数的输出值总是128位;电子标签标识、密钥,读写器标识的长度也为128位,因此可定义长度L=128位.下面统计图4新设计协议的空间性能.
①RFID标签:存储自身ID、密钥,空间性能为2L.
②读写器:只用来传递信息,空间性能为0.
③后台数据库:存储n个标签的ID、密钥,空间性能为2nL.
三种协议的时空性能如表2所示.

表2 三种协议的时空性能比较
从表2中可以看出,本文设计的协议在计算量上虽然有所增加,但增加的倍数不多,没有n数量级以上的增加.在存储量上,与其它协议不相上下,甚至比Hash-Lock协议还小.因此,本文设计的协议的时空性能较好.
5 结束语
本文针对现有RFID认证协议所存在的漏洞与不足,设计一种改进的RFID双向安全认证协议,该协议实现了RFID标签和读写器之间双向认证,具有防非法读取、防窃听、前向安全性、防位置跟踪以及防重放攻击等优点,有效解决了现有协议的所有安全问题,该协议不仅具有较高的安全性,而且存储容量小、运行效率高.广泛应用于大量电子标签的场合.
