基于隐语义模型的推荐算法研究
2020-08-28王子岚曹路舟
王子岚,曹路舟
(1.黄山职业技术学院 工业与财贸系,安徽 黄山 245000;2.安徽黄梅戏艺术职业学院 图文信息中心,安徽 安庆 246000)
随着当前网络信息量的不断增加,信息过载现象逐渐涌现,并造成搜索引擎精确度下降等问题,为此隐语义模型逐渐成为推荐搜索系统领域的热点名词.传统的关键词推送方法在进行数据迭代寻优的过程中,通常使用梯度下降类算法中的随机梯度下降法完成任务,且传统人工信息分类不能满足用户的需求,在一定程度上很难控制分类的质量,对于不同用户行为数据很难给出多种相对应分类,隐语义模型充分考虑传统人工信息分类的不足,很大程度上改善问题[1].隐语义模型是指从用户的行为数据角度考虑,自动找到这些分类规则,然后进行适合用户的个性化推荐,以此完成用户行为数据算法推荐,相关方面的研究越来越得到众多专家和学者的关注.
杨辰等[2]提出融合语义和社交特征的电子文献资源推荐方法,在基于用户的协同过滤方法的基础上引用隐语义主题模型,充分考虑用户的信息数据的推荐方式,运用相似性的非监督体系进行信息融合,在此基础上实现对电子文献资源推荐方法进行优化.李艳娟等[3]提出基于蜂群K-means聚类模型的协同过滤推荐算法,首先设计用户隐语义聚类模型,以此为依据计算用户与目标用户之间的聚类模型中各聚类中心的连接距离,通过蜂群K-means聚类模型完成协同过滤推荐算法的计算,最后根据计算结果同时通过相识度计算搜索目标用户的推荐信息.
基于隐语义模型的推荐算法,可实现根据关键词来获得更多有效信息,进一步解决当前用户信息搜索结果不精确的问题.基于隐语义模型的推荐算法成为现阶段人们从信息海洋中获取有效信息的关键途径之一,通过对用户历史行为记录数据进行整合分析,获取其特征数值,从而有效判断用户的偏好,准确推送用户所需的信息.不考虑隐语义模型推荐过程中常见的数据损失现象,结合传统的信息特征推荐梯度下降算法进行优化,分析两类梯度下降算法的优缺点,并进行结合和优化处理,从而更好地提高基于隐语义模型的推荐算法的准确性.
1 基于隐语义模型的推荐算法
1.1 隐语义模型数据特征值采集
为保障信息推荐的准确性,首先对隐语义模型数据特征进行采集,获取用户的个性化喜好信息,并针对采集到的特征数据及搜索关键词,进行信息分类和推荐.为保障信息推送的准确性,结合最小梯度下降算法和隐语义模型对数据信息特征采集和分类算法进行规范[4].首先采用小样本梯度下降法对用户兴趣信息进行随机抽取,并对收取到的特征信息进行挖掘,则采集到的信息特征相关性数值算法可记为
(1)

(2)
式中,Qa和Qb分别表示为相似度预选评分数值和相似度评分均值.根据数据特征系数进一步对不同的数据相似性结果进行分类,若ΔV>1则可将数据归类至相似特征集;若ΔV≤1则进一步对数据特征进行挖掘分类,计算其特征相似类别[5].针对不同的信息特征相似度数值进行特征等级划分,并整合为特征集合,以便对不同等级中的差异性特征数值进行评价,并选择最优评价尺度进行记录.结合模糊控制算法对网络流量信息特征进行采集,进一步对用户检索信息趋向进行挖掘数,并规范参考特征数值,其限制条件可记为Y,则信息特征数据挖掘兴趣度算法为
I(n)=Sij×ΔV×C(Yi+Yj),
(3)

(4)
式中,h表示每一个特征等类别都会包含一个组列,u表示各个特征子集之间的共性特征属性,e表示差异性特征数值,t表示数据中的隐语义信息挖掘次数,n表示数据特征类别数量.基于以上算法有效对用户非重要性关键词进行排查和检测,根据特征数值进行特征类别划分,从而更好地帮助用户筛选喜爱的兴趣信息.基于上述算法对用户兴趣信息进行评价,判断信息共性特征的评分向量,确定用户新相似性及相似程度,以便更好地进行隐语义特征数据类别的分类筛选和有效推荐.
1.2 隐语义模型信息推荐步骤优化
基于上述算法进行信息数据的筛选和推荐,为保障数据推荐的准确性,对筛选步骤进行优化,并在人际交互界面上对特征信息进行显示,以便提供给用户进行判断,并对隐语义模型的行为特征数据进行筛选.在信息推荐过程中,对兴趣信息相似度是提高推荐精度很重要的一部分.在不同的推荐场景中,选择的相似度的计算方法也不相同.设An点特征向量取值范围为(a1,a2,a3,…,an),Bm点特征向量取值范围为(b1,b2,b3,…,bn),则An点与Bm点的共性特征表示公式为
(5)
根据用户历史信息浏览和收藏情况进行反馈和检测,判断用户最高检索情况和数据点击率,同时分析数据搜索结果,进行有效信息的筛选,并提供个性化推荐列表.结合协同信息原理进行数据特征过滤,对任意指定的兴趣信息进出筛选.假设在进行信息筛选的过程中存在与用户搜索兴趣相似的一组特征集,结合隐语义原理对采集到的特征信息相似度标准进行规划和搜索,评价过的兴趣信息的评分来预测对筛选信息的评分[7].信息推荐的联系方式主要分为用户与用户联系、与项目联系以及与特征联系,从而通过推荐系统联系到推荐的项目.具体的数据推荐管理关联原理如图1所示.

图1 数据推荐管理关联原理
基于以上原理,结合网络信息协同过滤原理进行用户兴趣信息的特征采集处理,对于任意一个用户,假设其拥有与之兴趣相似的一组数据特征类别,则基协同过滤原理和隐语义模型进行信息相似度对比,为保障特征采集的准去性需要进行特殊分类标准的规划,需要对用户以往的搜索行为进行兴趣类别比分析,并对比其他用户的相似搜索信息进行信息特征类别的筛选,根据筛选结果进行分类评价,获取用户潜在兴趣项目的评分,根据评分内结构推送相似信息[8].对不同信息的相似度计算并划分相似度等级,从而在推荐系统中得到不同等级的差异结果数值,根据差异数值对不同用户需求选择不同的相似度评价方法进行分类处理,并进行多种排列尝试,构建了基于大数据的电子商务框架图,如图2所示.

图2 基于语义模型的信息处理块
基于以上模块进行用户信息的筛选分类,并构建隐语义信息库模型,选取信息的最优行为路径,然后对筛选出的相似信息和并向推荐库发送传输请求,并按照用户兴趣计算推荐信息,最后对客户端响应结果进行显示[9].进一步利用隐语义模型找到用户搜索趋向及采集到的相似数据进行筛选和推荐,当用户对该信息给予高度评价时,推荐给用户与该信息相似度较高的其他信息,保障信息推荐的快速和精准.
1.3 基于隐语义模型信息推荐的实现
1.3.1 信息重要性影响排序
为了更好地实现对用户信息进行推荐,首先对隐语义模型中的模糊数据进行统一评价,并根据评价结果对语义模型推荐功能进行改善,在进行隐语义信息的推荐过程中,受到的语义模型多元化重要性因素影响,对推荐信息进行分步评估和加固处理,所推荐的相关特征信息数据的最大有效性特征范围在Kmax范围内,其计算公式为
(6)
式中,Hj表示隐语义模型筛查出的相似特征内容数据信息推荐要求,Ni表示特征信息的初始推荐功能偏好.在上述算法中,若i=(1,2,3,…,n),j=(1,2,3,…,m),设筛选出的相似信息重要性特征影响度为P,推荐信息的评估体系构成要素为n,每个评估体系的重要性影响度数据编码集合为Pij,且Pij={P1,P2,…,Pi},通过对隐语义模型特征信息推荐的重要性影响进度数值S进行数据编码和集中分类管理,继而从筛选的数据结果中划分出数据推送的重要程度等级,最后再对隐义模型数值特征行为所受重要性影响等级进行计算,得到公式(7):
(7)
若G为隐语义模型数据的总体信息评测有效度,在进行信息推荐的过程中,受到zij个重要性因素干扰,且干扰程度为D,则筛选出的信息重要性影响排序算法为:
(8)
采用上述步骤对隐语义模型信息特征的多元化属性影响因素进行优化,获取关联性信息的最终特征相似性测评影响数值,利用计算机网络用户的相关动作数据特征,辅助区别正常推荐数据与异常推荐数据,并对这些推荐数据的特征进行匹配,以此实现对隐语义数据数据的挖掘和分类[10].再对获取到的信息特征规则进行统一归类和数据更新,构建出相对较完备与精准的信息储备库,以便对信息数据进行准确推荐.
1.3.2 用户兴趣数据信息推荐
由于在进行数据推荐的操作过程中,需要进行大范围的数据搜索,为保障数据搜索的有效性需要对采集到的全部信息特征值汇总潜在关键词进行提取,最大程度上缩小信息搜索的范围,由于隐语义模型关键词存在一定的隐藏性,因此在进行信息推荐的过程中存在较大的信息挖掘难度,为此需要结合模糊聚类隐语义融合模型推荐算法对不同数据特征类别集合进行挖掘训练,并整合出数据的相应特征的聚类簇集合,并将采集到的集合信息特征存入隐语义模型中的分布式数据库数据处理模块,设计隐语义模型训练因子排列等级评估模型,具体模型结构如图3所示.

图3 隐语义模型训练因子排列等级评估模型
为保障信息推荐的合理性,进一步对隐语义模型推荐流程进行优化,分别在离线和在线状态下对信息推荐流程进行优化处理,判断相似信息及特征集,从而进行信息推荐,具体信息推荐流程如图4所示.

图4 基于隐语义模型的信息推荐流程
根据以上流程对推荐信息进行相似性筛查和排序处理,可更好的提高对用户兴趣数据推荐的有效性,同时保障在海量数据环境下对特征数据的准确挖掘.
2 实验结果分析
为验证基于隐语义模型的推荐算法,对比传统推荐算法进行了准确性对比检测,为保障检测结果的准确性,首先对实验环境及参数进行统一设置.
实验采用的集群由三台机器组成,其种一台为Master,作为Name Node节点来配置,其余两台为Slave来配置,处理器CPU为lntel(R) Core(TM)i7-7700 CPU@3.60GHZ,内存128G,操作系统为CentOS6.6.实验数据来源为Group Lens Research项目组提供的Movielens数据集,在数据集内排除限定条件较多的样本集,排除与本文研究拟合程度较低的样本集,排除特征不明显的样本集,剩余样本集合90个.
将样本集合分为9组,进行9次测试实验.为在上述实验环境下进行多次对比检测,将用户兴趣值作为数据推荐有效性的评价标准,为方便对实验结果进行观察和记录,将本文算法检测结果记为A,将文献[2]算法检测结果记为B,将文献[3]算法检测结果记为C.具体用户兴趣值对比检测结果如图5所示.
由图5可知,对比文献[2]算法、文献[3]算法以及本文方法大致可分为两种模式,文献[2]算法、文献[3]算法在10~30个样本集下的用户感兴趣程度最高,而本文与之相反,可满足不同样本集的不同需求,且其整体用户感兴趣程度始终高于其他两种文献方法,说明本文提出的基于隐语义模型的推荐算法在进行信息推荐的过程中,用户兴趣值相对较高.为进一步验证本文算法的合理性,对比本文算法和文献[2]算法和文献[3]算法的准确性进行验证,其准确率公式如式(9)所示.
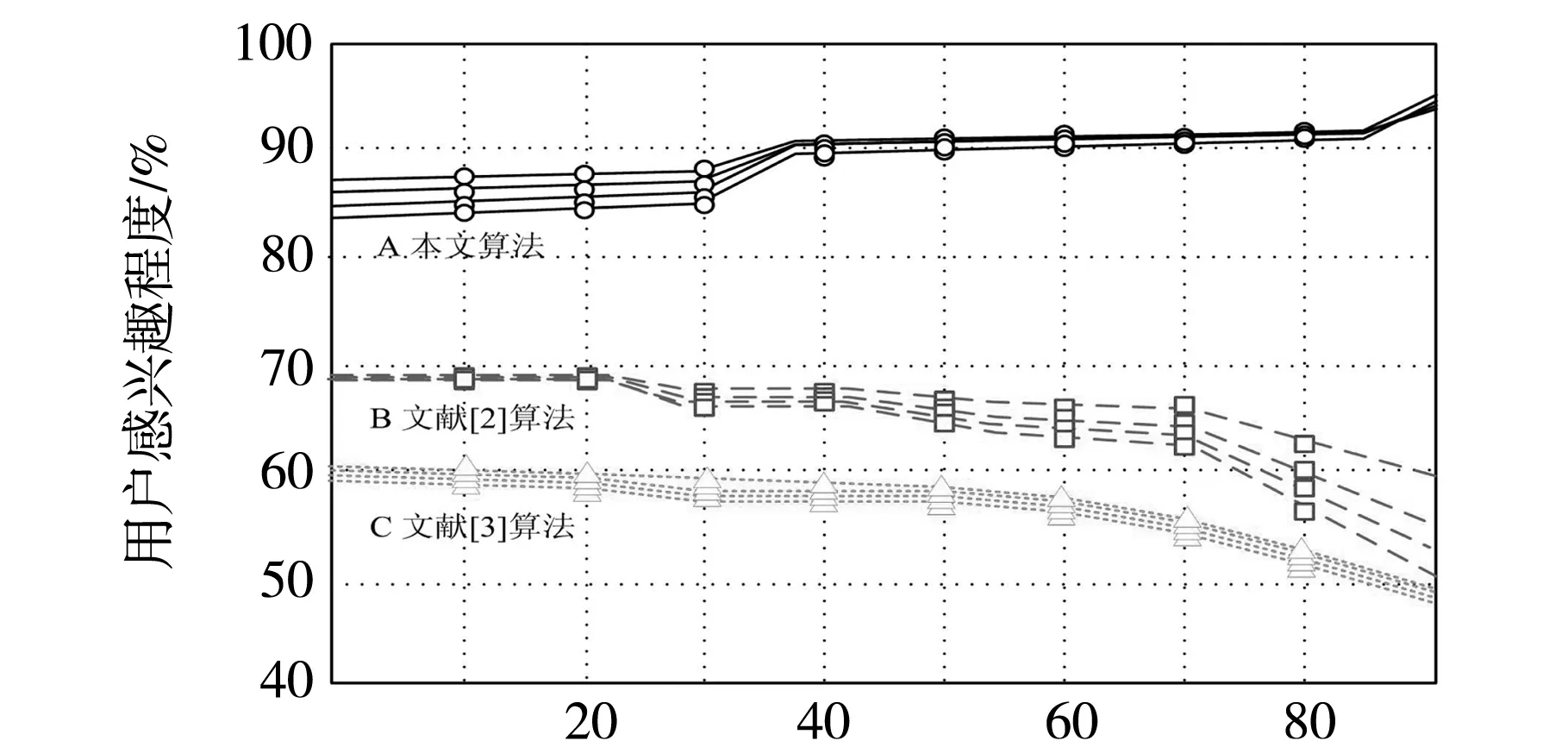
用户样本集/个图5 用户兴趣值对比实验检测结果
(9)
在公式(9)中,G(a)表示a最终选择对象集合的总量;H(a)表示a最终选择对象集合的数值量;F表示对象集合.利用准确率公式计算本文算法和文献[2]算法和文献[3]算法的分布等级准确性,其中误差最大值为20%,区段误差最大值为1%,误差值越低则表示模型越准确,其结果如表1所示.

表1 三种方法准确性分布等级对比
由表1可知,与文献[2]算法和文献[3]算法对比,本文算法的对比误差仅为5%,远远低于允许取值误差;文献[2]算法和文献[3]算法误差分别处于25%和26%,远远高于允许取值误差20%,且区段误差只有本文算法保持在规定极限以内,文献[2]算法和文献[3]算法的区段误差值超出允许区段误差值.由此证实基于隐语义模型的推荐算法具有较高的准确性和实用性,为用户行为数据的推荐奠定了基础,增加了推荐结果的完整性和可行性.
3 结 论
用户需要花费大量的时间从众多数据获得自己想要的信息,造成信息过载过重,这时就需要有技术或工具能够帮用户过滤掉不感兴趣或者与所想要的信息不相关的信息,为此提出了基于隐语义模型的推荐算法,通过采集用户兴趣信息特征数值,对近邻特征信息进行评估分类,并针对采集到的特征数据及搜索关键词,根据用户平均兴趣度以及不相似度惩罚系数设置向量特征信息值,划分特征等级,以便对兴趣信息进行有效划分.最后通过实验分析,结果表明本文提出的基于隐语义模型的推荐算法能够满足不同用户的需求信息的推荐,且提高信息推荐的准确性,在未来的研究中,可就如何缩短基于隐语义模型推荐算法的推荐时间进行深入的研究.
