DBN和CNN融合的脱机手写汉字识别
2020-08-26李兰英周志刚陈德运
李兰英 周志刚 陈德运


摘 要:针对脱机手写汉字形近字多,提取特征难,识别不准的问题,提出了一种卷积神经网络和深度信念网络的融合模型。首先在数据集上分别训练卷积神经网络和深度信念网络,发现二者的综合TOP-2准确率可达到99.33%。利用卷积神经网络和深度信念网络在图像分析中各自的优势,采用了一种融合比较策略,在两者的TOP-2分类中尽可能准确地取出一个分类结果以提高识别的能力。实验结果表明:卷积神经网络和深度信念网络的融合模型比单独使用卷积神经网络和深度信念网络具有更好的识别效果。
关键词:卷积神经网络;深度信念网络;脱机手写汉字
DOI:10.15938/j.jhust.2020.03.021
中图分类号: TP391.4
文献标志码: A
文章编号: 1007-2683(2020)03-0137-07
Abstract:Aiming at the problem that some offline handwritten Chinese characters are similar in shape and it is difficult to extract the feature of characters and the recognition is not accurate, a convolutional neural network and deep belief network fusion model is proposed. Firstly, the convolutional neural network and the deep belief network are trained on the dataset respectively. It is found that the comprehensive TOP-2 accuracy of the both can reach 99.33%. Using the advantages of convolutional neural networks and deep belief networks in image analysis, a fusion comparison strategy is adopted to extract a classification result as accurately as possible in the TOP-2 classification of the two to improve the recognition ability. The experimental results show that the fusion model of convolutional neural network and deep belief network has better recognition effect than convolutional neural network and deep belief network.
Keywords:convolutional neural network; deep belief network; offline handwritten chinese character
0 引 言
手寫汉字在试卷、邮件封皮、银行票据等方面都有广泛的应用[1]。实现手写汉字识别,可以进行机器阅卷,邮件自动分拣,票据识别等,极大地方便工作和生活。但是,由于汉字类别繁多、字形结构复杂,存在大量的相似汉字,手写汉字更是因人而异,千差万别,导致手写汉字识别困难,故手写汉字识别一直是研究难点和热点[2][3]。目前手写体汉字识别可分为脱机识别和联机识别两种。联机字符识别是指利用手写板或电子触摸屏书写,计算机根据书写汉字的笔画走向、书写速度、笔画顺序和总数等多种参考信息进行识别,信息涵盖内容丰富,具有一定的追溯性和连续性,识别相对容易,准确度也较高[4]。脱机字符识别没有联机字符识别的多种信息,仅依靠静止的二维图像信息来提取图像特征,故识别更加困难和复杂,准确度较难提高[5]。
至今为止有很多研究者对于脱机手写汉字识别进行了大量研究。一些研究者是基于傳统的机器学习的方法进行的研究,如文[6]采用了一种改进的仿射传播聚类算法;文[7]提出一种基于支持向量机SVM的多特征手写体汉字识别技术,在提取网格特征的基础上增加对汉字质心特征、笔画特征、特征点的提取,并采用SVM分类器实现手写汉字识别。这类方法需要进行数据的预处理,复杂的特征提取,难以较全面的提取出准确的特征。文[8]采用一种基于LS-SVM的部分级联特征分类方案,采用低阈值霍夫空间采样结果作为粗分类特征,对粗分类用局部二支分布直方图作为细分类特征,先粗分后细分实现样本分类;文[9]采用修正的二次判别函数(Modified Quadratic Discriminant Function,MQDF)和卷积神经网络(Convolutional Neural Networks,CNN)级联的方法取得了比单独的MQDF和单独的CNN方法要高的准确率;和文[10]相似,文[11]采用MQDF和深度置信网络(Deep Belief Networks,DBN)级联的方法取得更高的准确率。一些研究者基于深度学习算法,通过改进网络结构或者提出改善的训练方法的方式来提高识别性能。如文[12]应用深度残差网络(Residual Networks,ResNet),通过改进残差学习模块的单元结构,优化网络性能;文[13]在卷积神经网络中采用迭代求精改进的方法;文[14]将卷积神经网络中的VGGNET模型用到汉字识别中;文[15]将人脸识别中提出的center loss损失函数应用到手写汉字的CNN网络中来,减小类内距离,增加类间距离,提高识别性能;文[16]使用一个深层的CNN网络,结合印刷体数据集和手写体数据集训练识别网络,并且通过构建一个服务来扩展训练数据集,提高对不同书写样式的适应能力。
卷积神经网络和深度置信网络都是现在深度学习中对图像分析非常有效的方法[17-18],为了进一步的探索脱机手写汉字的识别方法,本文提出了一种卷积网络和深度信念网络融合的识别模型,结合两种网络在汉字识别中的优势,提高汉字识别的能力。
1 卷积神经网络
卷积神经网络CNN是一种结构化的有监督的多层前馈神经网络,主要应用于二维数据处理,它能够通过大量学习,自动提取图像特征,最终达到图像分类的目的。它由交替出现的卷积层、采样层和全连接层组成,每个卷积层包含多个卷积核。卷积层中的每一个神经元与上一层的局部区域进行连接,通过卷积运算提取二维数据的特征信息,并且降低噪声对特征的干扰。采样层对二维数据进行抽样,降低分辨率,在尽量保存图像的特征信息的同时降低数据的维度,减少参数数量,提高网络运算速度。Yann LeCun在1998年提出的LetNet-5是经典的神经网络结构[19],其结构图如图1所示。
1.1卷积层
对于卷积层,卷积核与上一层的特征图(feature map)进行滑动卷积运算,再加上一个偏置量(bais)得到净输出,如公式(1)所示,最后通过激活函数(Activation function)的非线性作用得到卷积的结果,即输出特征图,即
klij是第l层的第i个卷积核中的第j通道;bli是第i个卷积核对应的偏置量;uli是l层第i个卷积核对应的净输出;运算*代表卷积操作。xli是第l层第i个特征图。f(·)是激活函数,通常采用Sigmoid函数,Sigmoid函数如公式(3):
1.2 采样层
采样层是对上一层的输出特征图进行降采样操作,把输入的特征图用采样窗口划分为多个不重叠的图像块,再对每个图像块采用最大池化或者平均池化方法。假设采样窗口的尺寸为n×n,输入特征图的尺寸为iS×iS,输出特征图的尺寸如式(4)所示。最大池化如式(5),平均池化如式(6)所示
式中:l代表当前的采样层;N代表输入特征图的个数,与输出特征图的个数相同;Vkj,j=1,2,…,oS2代表第k个输入特征图的第j个图像块,每一个图像块含有n2个元素;xlki,i=1,2,…,n2是Vkj图像块中的第i个元素;xlkj是当前层的第k个输出特征图上的第j个元素。
1.3 全连接输出层
经过卷积层和降采样层后,原始图片的高级特征已经被提取出来,全连接层的作用就是使用这些特征对原始图片进行分类。全连接层对这些特征做加权求和,再加上偏置量,最后通过激活函数获得最终的输出,如式(7)所示。输出层本质上也是全连接层,只是激活函数采用分类函数来进行分类。
式中:xl-1是前一层的输出特征图,里面的元素都是通过卷积和降采样提取出来的高级特征;wl是全连接层的权重系数;bl是全连接层l的偏置量。
卷积神经网络一般用于多分类的情况,分类函数一般采用Softmax函数,它将最后一层L的未激活输出ZL归一化到(0,1)范围内,同时输出值之和为1,起到分类的作用,ZL的计算式如式(8),Softmax函数如式(9),即
式中:L代表最后的输出层第L层,nL代表L层有n个输出神经元,代表n个分类;aLi是n个分类中的第i个分类输出;zLi代表第i个未激活输出;zLj代表第j个未激活输出;e为自然常数。
2 深度信念网络
深度置信网络DBN是一个具有层次特征的概率生成模型,通过训练神经元之间的权重,可以让整个神经网络按照最大概率生成训练数据。同时DBN是一种深度神经网络,采用自底向上的传递,底层的神经元接收原始的特征向量,不断向更高层次抽象,顶层的神经网络形成易于组合的特征向量。通过增加层次就能够使特征向量更高的抽象化,而且,每一层的网络会弱化上一层的错误信息和次要信息,以确保深层网络的精度。DBN结构如图2所示。其由一系列叠加的受限玻尔兹曼机(restricted boltzmann machine,RBM)和顶层的反向传播网络(back propagation,BP)构成。受限玻尔兹曼机由隐层v和可示层h两个神经元节点构成。可示层的作用是输入数据,隐层的作用是特征检测。区别于玻尔兹曼机,RBM的特点是可示层和隐层之间采用全连接方式,而在可示层内神经元之间和隐层内各神经元之间是无连接的,以二维图的形式存在,相比玻尔兹曼机更加高效。
DBN训练过程包含预训练和微调。首先,预训练阶段利用大量无类标信息数据,无监督地训练每层RBM,将下层RBM的隐层输出作为上一层RBM
可示层的输入。微调阶段则采用有监督学习方式对顶层的BP网络进行训练,将实际输出与预期输出的误差逐层反向传播,目的是调整网络的权值。
3 CNN和DBN的融合模型
CNN模型和DBN模型都可以应用于脱机手写汉字识别任务中,应用各自模型的特点提取手写汉字字符图像的分类特征。由于CNN和DBN有着不同的网络结构,提取特征的角度必然不同,在特征提取方面有着各自的优势。如同对于同一个手写汉字,如果汉字字形规范性不高,或者与其形近字相似,不同的人可能会识别为不同的字符,其中某一个人的识别可能是对的,说明他对这个字的识别能力较高。本文提出的CNN和DBN的融合模型就是基于这种思想,融合CNN和DBN各自在手写汉字识别上的优势,最终产生高于CNN和DBN的识别能力,将此融合模型称为CNN-DBN。CNN-DBN整体过程包括两个过程:训练过程和应用过程,如图3所示。
首先,在训练数据集上分别单独训练CNN和DBN得到训练好的CNN和DBN的识别模型;然后在样本集上统计CNN和DBN对不同的字符的识别能力,对某一字符的识别能力定义为识别正确的个数与该字符总数的比值,计算方法如公式(10)。
式中:pi表示样本集中第i种字符的识别能力;ci表示第i种字符识别正确的次数;ni代表第i种字符在样本集中的总数。
研究的分类数为3755,将CNN对第i种字符的识别能力记为PCNNi,3755种字符相应的识别能力表示为向量:
DBN对第i种字符的识别能力记为PDBNi,3755种字符相应的识别能力表示为向量:
融合算法的实现过程如下:
1)将字符图片经过CNN计算得出分类得分:
将CNN模型的识别分数XCNN与CNN模型的识别能力向量PCNN的点乘结果作为CNN模型的最后的识别得分,表示为:
2)将字符图片经过DBN计算得出分类得分:
将DBN模型的识别分数XDBN与DBN模型的识别能力向量PDBN的点乘结果作为DBN模型的最后的识别得分,表示为:
ODBN=(xDBN1pDBN1,xDBN2pDBN2,…,xDBN3755*pDBN3755)
3)对OCNN的分量从大到小排序,选取最大的两个分量(oCNNk1,oCNNk2)。
4)对ODBN的分量从大到小排序,选取最大的两个分量(oDBNg1,oDBNg2)。
5)融合CNN和DBN的识别结果,设class为分类输出。本文尝试了两种融合方式。
方式A的class的计算方式如下伪代码所示:
If k1=g1 then class=k1
else if k2=g1 then class=k2
else if k1=g2 then class=k1
else if k2=g2 then class=k2
else if OCNNk2OCNNk1>ODBNg2ODBNg1 then class=g2
else class=k1
endif
方式B采用线性可信度累积(Linear Confidence Accumulation,LCA)算法,引入一组加权因子α和β融合XDBN和XCNN作为最后的識别得分,α和β的作用是权衡CNN和DBN各自在融合模型中起到的作用的大小,识别得分计算方式如公式(11)所示。
式中:α+β=1。最终的分类结果class是对O中的分量从大到小排序,最大分量的下标作为最后的class,即
4 实 验
4.1 数据集
采用的数据选取自中科院自动化模式识别国家重点实验室所发布的CASIA-HWDB1.1脱机手写数据集[20]。CASIA-HWDB1.1数据集由很多孤立的手写中文字符的灰度图片及其标签组成。CASIA-HWDB1.1包含了GB2312-80字符集的level-1的3755种中文字符,共300个文件,分别对应300个人,选取前240个文件作为训练集,后60个文件作为测试集。由于CASIA-HWDB1.1中的原始字符图片尺寸不一,不能直接实验,在实验前将图片调整为尺寸为64×64大小的图片,并进行了中心化。处理前后的对比如图4所示。
4.2 网络设置
为了验证提出的融合模型的有效性,实验中使用的CNN模型和DBN模型都是没有经过特殊改进和没有增加技巧的模型。使用的CNN模型类似于VGGNET,网络结构为64×64->100C5->MP2->200C5->MP2->300C5->400C3->MP2->500C3->MP2->2000N->3755N。它的输入层是尺寸为64×64的图片,接下来是含有100个尺寸为5×5的卷积核的卷积层和采样窗口为2×2的最大采样层,后续的隐含层含义与之相似,对于最后一个最大采样层,将输出特征图展开重组为一个含有2000个神经元的全连接层,采用softmax激活函数作为分类函数,得出3755个神经元,每一个神经元代表一个字符类别的识别得分。实验中使用的DBN含有5个RBM层,每一个隐含层的神经元的个数设置为600。根据前文中描述的训练方法和融合方式进行实验。
4.3 实验结果及分析
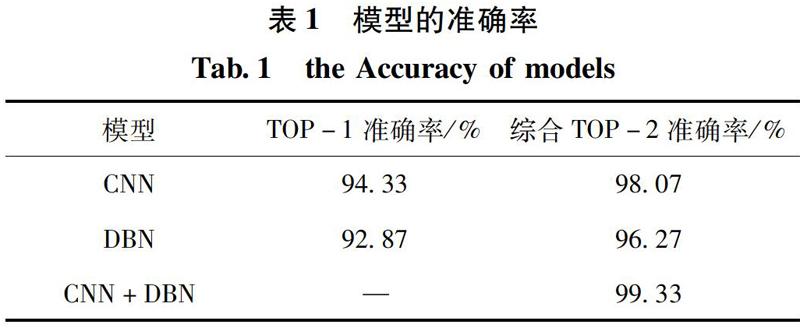
使用的工具为MATLAB R2018a,采用MATLAB的Neural Network Toolbox工具箱构建网络结构进行实验。表1为CNN和DBN网络的TOP-1准确率和CNN和DBN综合的TOP-2准确率,CNN和DBN综合的TOP-2准确率已达到99.33%,采用本文提出的融合模型,在综合的TOP-2的分类结果中选出准确的分类结果。
将采用融合方式A的CNN-DBN模型称为CNN-DBN-A,采用融合方式B的CNN-DBN模型称为CNN-DBN称为CNN-DBN-B。对于CNN-DBN-B,因为α+β=1,所以实验过程中只需将α从0变化到1,β也会随之从1变化到0。先设置α增长的步长值T=0.1,记录下识别准确率,结果如图5所示。从中可以发现,随着α从0增大到1的过程中,CNN-DBN-B的识别准确率Accuracy先增大后减小。
图5中表明随着α的变化,识别准确率会取得一个最大值,这个最大值对应的α和β即为CNN和DBN最佳的融合因子。图5中的识别准确率曲线是在T=0.1时计算取得,曲线为明显的折线,在[0.6,0.8]区间内可能由于步长值T的精度不高错过了更高的准确率,为了进一步探索步长值T的变化对最大准确率的影响,T依次取0.1、0.01、0.001、0.0001、0.00001和0.000001,记录最大准确率,结果如图6所示。
图6表明随着步长值T的精度逐渐提高,最大准确率Max-Accuary首先递增,当T<0.01后,最大准确率不再增加,达到饱和。取T=0.0001再次实验α从0增加到1的过程,实验结果如图7所示,可以看出曲线比T=0.1时更加精确,当α=0.7497时,取得最大识别准确率0.97。
CNN,DBN,CNN-DBN-A和CNN-DBN-B(α=0.7497)对不同字符(Character)的识别能力(Recognition Capability)的比较如图8所示(由于篇幅有限,只截取了10个字符的识别能力)。图8表明CNN和DBN对不同字符有不同的识别能力,使用本文的融合方式后,CNN-DBN-A和CNN-DBN-B在整体上都比CNN和DBN对不同字符的识别能力要高,其中CNN-DBN-B优于CNN-DBN-A。
为了进一步体现本文提出的融合模型的识别性能,在相同的数据集下比较了不同方法和模型的识别准确率,如表2所示。可以看出,深度学习的方法在手写汉字识别上有比较好的效果,本文提出的融合模型获得比较高的准确率,与相近的方法性能相当或更高。
5 结 论
针对脱机手写汉字识别难的问题提出了CNN-DBN手写汉字融合识别模型。通过寻求一种合适的融合比较策略,结合CNN和DBN在脱机手写汉字识别上各自的优势,在CNN和DBN的识别结果中选取出一个可信度较高的识别结果。实验结果表明在本文的数据集上,CNN-DBN融合模型取得了比单独的CNN和DBN与传统机器学习方法更好的识别效果。接下来的研究方向是进一步改善网络结构,探索更好的融合方式。并且脱机手写汉字识别往往应用到一些嵌入式设备中,其资源限制了本方法的应用,所以如何压缩网络结构,节省资源和加速计算也是研究的重点方向。
参 考 文 献:
[1] SHEN XI, RONALDO MESSIN. A Method of Synthesizing Handwritten Chinese Images for Data Augmentation[C]//International Conference on Frontiers in Handwriting Recognition, Shenzhen, China, 2016: 114.
[2] 閆喜亮, 王黎明. 卷积深度神经网络的手写汉字识别系统[J]. 计算机工程与应用, 2017, 53(10): 246.
YAN Xiliang, WANG Liming. Handwritten Chinese Character Recognition System Based on Neural Network Convolution Depth[J]. Computer Engineering and Applications, 2017, 53(10):246.
[3] 金连文, 钟卓耀, 杨 钊. 深度学习在手写汉字识别中的应用综述[J]. 自动化学报, 2016, 42(8): 1125.
JIN Lianwen, ZHONG Zhuoyao, YANG Zhao. Applications of Deep Learning for Handwritten Chinese Character Recognition: A Review[J]. ACTA AUTOMATICA SINICA, 2016, 42(8): 1125.
[4] WU Peilun, WANG Fayu, LIU Jianyang. An Integrated Multi-Classifier Method for Handwritten Chinese Medicine Prescription Recognition[C]//International Conference on Software Engineering and Service Science, Beijing, China, 2018: 1.
[5] WANG Zirui, DU Jun. Writer Code Based Adaptation of Deep Neural Network for Offline Handwritten Chinese Text Recognition[C]//International Conference on Frontiers in Handwriting Recognition, Shenzhen, China, 2016: 548.
[6] 钟治权, 袁进, 唐晓颖. 基于卷积神经网络的左右眼识别[J]. 计算机研究与发展, 2018, 55(8):1667.
ZHONG Zhiquan, YUAN Jin, TANG Xiaoying. Left-vs-Right Eye Discrimination Based on Convolutional Neural Network[J]. Journal of Computer Research and Development, 2018, 55(8): 1667.
[7] 吕启, 窦勇, 牛新, 等. 基于DBN模型的遥感图像分类[J]. 计算机研究与发展, 2014, 51(9): 1911.
LV Qi, DOU Yong, NIU Xin, et al. Remote Sensing Image Classification Based on DBN Model[J]. Journal of Computer Research and Development, 2014, 51(9): 1911.
[8] 楊怡, 王江晴, 朱宗晓. 基于仿射传播聚类的自适应手写字符识别[J]. 计算机应用, 2015, 35(3): 807.
YANG Yi, WANG Jiangqing, ZHU Zongxiao. Adaptive Handwritten Character Recognition Based on Affinity Propagation Clustering[J]. Journal of Computer Applications, 2015, 35(3): 807.
[9] 周庆曙, 陈劲杰, 纪鹏飞. 基于SVM的多特征手写体汉字识别技术[J]. 电子科技, 2016, 29(8): 136.
ZHOU Qingshu, CHEN Jinjie, JI Pengfei. The Technology of Multiple Features Handwritten Chinese Character Recognition Based on SVM[J]. Electronic Sci. & Tech, 2016, 29(8): 136.
[10]叶枫, 邓衍晨, 汪敏,等. 部分级联特征的离线手写体汉字识别方法[J]. 2017, 26(8): 134.
YE Feng, DENG Yanchen, WANG Min, et al. Offline Hand-Written Chinese Character Recognition Based on Partial Cascade Feature[J]. Computer Systems & Applications, 2017, 26(8): 134.
[11]WANG Yanwei, LI Xin, LIU Changsong. An MQDF-CNN Hybrid Model for Offline Handwritten Chinese Character Recognition[C]// The 14th International Conference on Frontiers in Handwriting Recognition, Heraklion, Greece, September, 2014:246.
[12]LIU Lu, SUN Weiwei, DING Bo. Offline Handwritten Chinese Character Recognition Based on DBN Fusion Model[C]// Proceedings of the IEEE International Conference on Information and Automation, Ningbo, China, August, 2016:1807.
[13]张帆, 张良, 刘星, 等. 基于深度残差网络的脱机手写汉字识别研究[J]. 计算机测量与控制, 2017, 25(12): 259.
ZHANG Fan, ZHANG Liang, LIU Xing, et al. Recognition of Offline Handwritten Chinese Character Based on Deep Residual Network[J]. Computer Measurement & Control, 2017, 25(12): 259.
[14]YANG Xiao, HE Dafang, ZHOU Zihan. Improving Offline Handwritten Chinese Character Recognition by Iterative Refinement[C]//The 14th IAPR International Conference on Document Analysis and Recognition, Kyoto, Japan, November, 2017: 5.
[15]WANG Zirui, DU Jun, HU Jinshui, et al. Deep Convolutional Neural Network Based Hidden Markov Model for Offline Handwritten Chinese Text Recognition[C]//Asian Conference on Pattern Recognition, Nanjing, China, November, 2017: 26.
[16]YANG Shimeng, NIAN Fudong, LI Teng. A light and Discriminative Deep Networks for Offline Handwritten Chinese Character Recognition[C]// The 32nd Youth Academic Annual Conference of Chinese Association of Automation, Hefei, China, May, 2017:785.
[17]ZHUANG Hang, LI Changlong, ZHOU Xuehai. CCRS: Web Service for Chinese Character Recognition[C]//IEEE International Conference on Web Services, San Francisco, CA, USA, July, 2018:17.
[18]YANN LECUN, LEON BOTTOU, YOSHUA BENGIO. Gradient-Based Learning Applied to Document Recognition[J]. IEEE Journals and Magazines, 1998, 86(11):1.
[19]LIU Chenglin, YIN Fei, WANG Dahan. CASIA Online and Offline Chinese Handeriting Databases[C]//International Conference on Document Analysis and Recognition, Beijing, China, November, 2011: 37.
[20]YIN Fei, WANG Qiufeng, ZHANG Xuyao. ICDAR 2013 Chinese Handwriting Recognition Competition[C]//The 12th International Conference on Document Analysis and Recognition, Washington, DC, USA, August, 2013:1464.
(編辑:温泽宇)
