基于双向线性回归的监督离散跨模态散列方法
2020-08-25刘兴波聂秀山尹义龙
刘兴波 聂秀山 尹义龙
1(山东大学软件学院 济南 250101)2(山东建筑大学计算机科学与技术学院 济南 250101)(sclxb@mail.sdu.edu.cn)
近年来,爆炸性增长的多媒体数据在微博、微信、Facebook等社交媒体上广泛传播,给信息的检索带来了巨大挑战.同时,此类多媒体数据可以由诸如文本、图像和视频等多种模态来表示,而这些异构的多模态数据之间存在语义鸿沟,如何解决语义鸿沟问题也是需要研究的问题.另一方面,在实际应用中,当用户使用一种模态,例如文本,去检索感兴趣的话题时,他们通常会希望得到与此话题相关的其他模态,例如图像或视频等信息的反馈.跨模态检索正是解决以上问题的一个可行方法,因此,近年来跨模态检索已经成为多媒体领域的热门研究方向.
跨模态散列学习是跨模态检索领域的主要方法之一,跨模态散列学习通过机器学习技术,将文本、图片、视频等多模态数据转化为海明空间中一组简短的二值码(称之为散列码).散列码之间的相似性关系与原始数据之间的相似性关系保持一致,利用公共空间的散列码可实现跨模态的检索.散列码之间的相似性是通过海明距离来衡量的,而海明距离的计算可以在硬件上通过按位异或运算来实现.因此,与其他距离的计算相比,海明距离具有更高的效率[1].多媒体数据的散列表示可以实现高效地检索,并有效地降低存储成本.因此,散列学习已成为大数据背景下跨模态检索最受欢迎的方法之一.
在现有的跨模态散列方法中,线性模型是一种常用的建模方法.为了获得更高的检索精度,基于线性模型的散列方法重点设计一组包含不同约束项或惩罚项(这些项考虑了样本的语义信息、邻域关系和散列表示的特异性)的广义线性目标函数来实现散列学习.在现有监督线性模型散列学习中,标签和散列码之间的回归项是重要的函数项.但是,现有方法仅考虑两者之间的单向回归关系(详细描述见论文2.2节).如果把相应的标签和散列码看作数据不同的特征表示,两者的单向回归形式并未充分利用样本的标签信息.与现有方法不同,本文提出了一种基于双向线性回归的监督离散跨模态散列算法(mutual linear regression based supervised discrete cross-modal hashing, SDCH),该方法在使用线性映射将散列矩阵回归到相应的标签矩阵的同时,使用相同的线性投影将标签矩阵回归到相应的散列矩阵.本文提出的方法所学习到的线性投影可以有效描述散列矩阵和标签矩阵之间的稳定且唯一的关系.
本文的主要贡献概括为2个方面:
1) 使用同一映射矩阵来描述散列矩阵和标签矩阵之间的双向回归关系,使得散列学习的过程更加稳定和精确;
2) 在学习用于生成未知样本散列码的模态特异映射时,保持了异构模态的特征分布与语义相似度的一致性.
1 相关工作
跨模态散列学习方法主要包括基于线性模型和基于深度模型的方法两大类.与深度模型的方法相比,基于线性模型的散列方法在训练过程中可解释性更强,且速度更快,在实际应用有很大的优势.本文主要研究基于线性模型的跨模态散列方法.因此,本部分内容简要总结一下线性模型的跨模态散列方法.
线性跨模态散列学习可以分为无监督跨模态散列[2-4]和有监督跨模态散列[5-10].无监督的跨模态散列方法通过挖掘训练样本的模态内和模态间关系来学习散列函数.例如,文献[2]提出了媒体间散列,通过保持模态间和模态内的语义一致性来学习散列码;在文献[3]中,潜在语义稀疏散列将稀疏编码和矩阵分解结合起来以学习潜在的公共海明空间;文献[4]中提出了联合矩阵分解散列,该方法假设不同模态的样本具有相同的散列码,进而使用联合矩阵分解从样本的不同模态中学习统一的散列码.有监督跨模态散列方法利用训练数据的语义标签作为指导信息来提高散列码的精度;文献[5]中提出了一种最大化语义相关性的跨模态散列方法,其利用标签来计算语义相似度矩阵,并试图用学习到的散列码重建该相似度矩阵;文献[9]无缝地将矩阵分解和离散优化结合在一起,提出了可拓展的基于矩阵分解的离散跨模态散列方法;文献[10]提出的跨模态散列方法在散列学习和样本外拓展映射的学习过程中都尽可能地保持住语义信息.因为有效利用了标签信息,通常来说,有监督的跨模态散列的准确度优于无监督的方法.
二值化约束是跨模态散列学习中的一个重要的约束项,此约束会产生二值离散优化问题.为了解决这个问题,在优化过程中采用松弛策略,先求出优化问题的实数解,然后使用阈值策略[11]将实数转化为二值表示.但是,这些采用松弛策略的方法通常会产生累积量化误差并且容易陷入局部最优解.为了解决这个问题,离散跨模态散列[12]使用离散循环坐标下降法[13]来直接求解离散的散列码.离散跨模态散列通过使用线性分类器最小化预测误差,来学习从散列码到语义标签的投影.使用这种策略,离散跨模态散列比采用松弛策略的监督跨模态散列方法表现出更好的性能.但是,由于最小二乘回归不稳定[14],导致了离散跨模态散列的散列学习过程可能也不稳定.因此,为稳定地利用监督信息并减少训练时间,在文献[15]中提出的快速离散跨模态散列,将样本的语义标签回归到对应的散列码.但是,单向的线性回归并未充分地利用标签信息,因此,本文提出一个基于双向线性回归的跨模态散列学习算法,充分利用标签信息的同时,也更好地捕捉了散列码和标签之间的稳定关系,提升了散列学习的准确度.
2 基于双线性回归的跨模态散列
本节首先说明本文算法用到的符号,然后给出本文提出的跨模态散列方法以及算法优化过程.最后,对所提出方法的时间复杂度进行了分析.不失一般性,本文以2种模态——图像和文本——为例来介绍算法,其他模态可以用类似的方法进行拓展.
2.1 符号定义
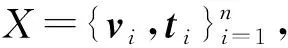
2.2 基于双向线性回归的跨模态散列方法
本文提出的方法是一个两步的模型,即第1步先利用训练集的语义标签学习训练集的散列码,第2步针对2个模态,学习用于生成新样本散列码的映射.
2.2.1 训练样本的散列学习
给定散列矩阵H和语义标签矩阵Y,现有线性方法大多利用回归模型来描述散列矩阵和标签矩阵之间的相互关系.例如在离散跨模态散列[12]中,通过映射矩阵WH建立从散列矩阵H到标签矩阵Y的回归模型来建模,过程表示为
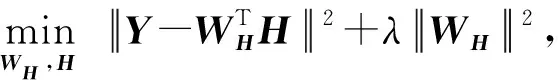
(1)
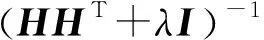
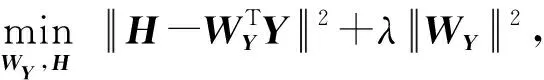
(2)
WY的闭式解可以表示为WY=HYT(YYT+λI)-1.通常,现有的基于线性模型的有监督散列方法会将散列矩阵回归到标签矩阵,或者相反,并且映射矩阵是不同的,即在式(1)和(2)中,WH≠WY.
为更好地捕捉散列矩阵和标签矩阵之间的相互关系,本文方法中利用双向的线性回归关系来对散列矩阵和标签矩阵进行建模,并使用相同的映射矩阵增强散列学习的精度和稳定性.
采用以上策略的动机和原因为:通常来说,散列码可以看作样本在海明空间的特征表示,而类别标签可以看作样本在语义空间的特征表示.因此,散列矩阵H和类别标签Y可看作样本的不同特征表示,如果使用相同的映射矩阵刻画两者之间的关系,则标签矩阵Y散列矩阵H之间的回归损失可以表示为
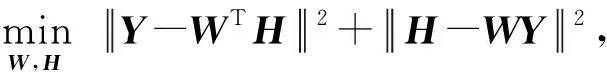
(3)
其中,投影矩阵W用于将标签矩阵Y映射到散列矩阵H,而WT则用于将散列矩阵H映射到标签矩阵Y.投影矩阵W和WT可以看作是彼此的逆映射,根据集合论可以证明逆映射是唯一的[16].因此,W的最优解是唯一且稳定的.根据Bousquet和Elisseeff的研究[17],采用稳定的映射W会使得未知样本的散列码学习过程会更加稳定.
另外,众所周知,散列学习的关键要素之一是保持样本在海明空间中的相似性.可以证明,在标签矩阵Y和散列矩阵H双向映射关系之间使用相同的映射矩阵,可以很好地保持语义相似性.
对于一个数据集,类别标签一般是二值向量,代表样本的语义类别,而散列码也是数据的一种二值语义表示.显然,用类别标签向量作为数据的二值表示用于检索是最理想的.但是,相关研究[18]表明,由于语义距离和评估标准之间存在分歧,在检索中使用标签向量不一定是最佳选择.尽管如此,标签是真实的语义表示,仍然具有非常好的检索准确性.受此启发,一些研究者试图使标签和对应散列码的内积尽可能接近,以保持语义相关性,尽可能从标签中获取有利信息.这种思路的主要方案就是尽可能让
YTY=HTH
(4)
成立.从式(4)可以推导出
HYTYYT=HHTHYT.
(5)
进一步,有
HYT(YYT+λI)=(HHT+λI)HYT
(6)
成立.由此可以得出
(HHT+λI)-1HYT=HYT(YYT+λI)-1.
(7)
也就是说,如果WH=WY,则YTY与HTH有相似的值,因此散列码和标签矩阵之间采用相同的映射矩阵来刻画回归关系可以很好地保持语义相关性,并尽可能使散列码的内积逼近标签内积.
综上所述,在本文算法中根据标签矩阵学习散列码的优化问题表示为
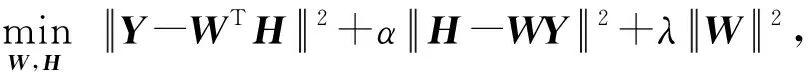
(8)
其中,α是一个超参数.值得注意的是,该策略与以前基于矩阵分解的方法[4]不同.基于矩阵分解的方法通常采用2个不一定相同的矩阵来描述散列矩阵与标签矩阵之间的相互回归关系,而本文中的投影矩阵W被认为可以用来描述标签矩阵和散列矩阵之间的更强的相关性.
2.2.2 新样本散列码学习
对于训练集中的图片模态数据V和文本模态数据T,本文分别用线性映射PV和PT来描述它们与公共散列码H之间的关系.
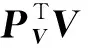
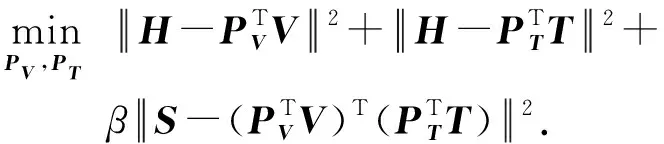
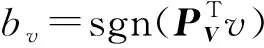
2.3 问题求解
本文提出的方法是一个两步的散列方法,即首先学习训练集的散列码,然后学习用于生成新样本散列码的映射.因此,求解问题时也是先求解训练集的散列码,然后求解用于生成未知样本散列码的映射.
2.3.1 散列学习问题求解
式(8)中的散列学习问题是一个非连续非凸的问题,本文试图用迭代的步骤去求解这个问题:
第1步: 固定散列矩阵H不变,求解映射矩阵W.那么,式(8)中的问题变为
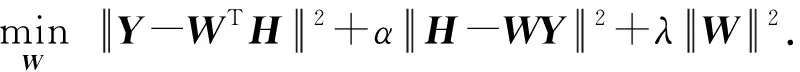
将式(10)展开,有
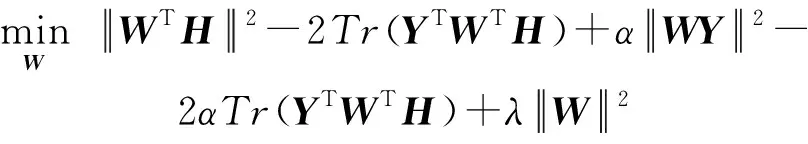
成立.其中,Tr(·)是迹函数.令式(11)对W的偏导数为0,有
HHTW+W(αYYT+λI)=(1+α)HYT
(12)
成立.式(12)是一个典型的希尔韦斯特方程.可以利用文献[19]中类似的方法求得W的数值解.
第2步: 固定映射矩阵W不变,求解散列矩H那么,式(8)中的问题可以简化为
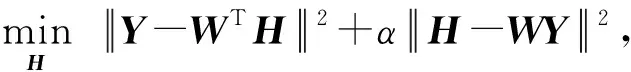
(13)
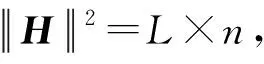
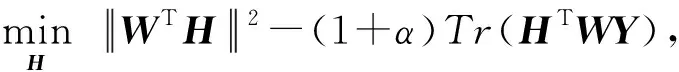
(14)
因为矩阵H是二值的,所以式(14)中的问题仍然很难求解.本文利用离散循环坐标下降法[13]来逐位求解H.具体地,定义h为散列矩阵H的第k行(k=1,2,…,L),U为H不包含h的部分.类似地,定义w为映射矩阵W的第k行,E为W不包含w的部分.定义q为WY的第k行.问题式(14)变为
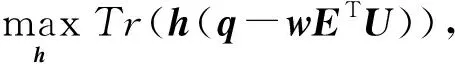
(15)
则h的闭式解表述为
h=sgn(qT-UTEwT).
(16)
2.3.2 新样本散列码学习问题求解
学习到训练集的散列码之后,本文算法需要学习一组从各个模态样本特征表示到公共散列矩阵的映射,以用来生成未知样本的散列码.本文同样采取一个迭代的步骤来求解这组映射.
第1步: 固定文本模态的映射PT不变,求解图像模态的映射PV.式(9)中的问题变为

令式(17)对PV的偏导数为0,可以得到PV的闭式解为
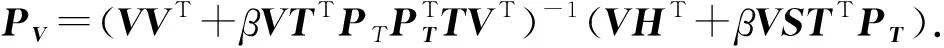
第2步: 固定图像模态的映射PV不变,求解文本模态的映射PT.式(9)中的问题变为
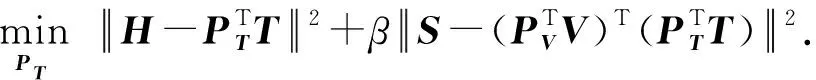
令式(19)对PT的偏导数为0,可以得到PT的解析解为
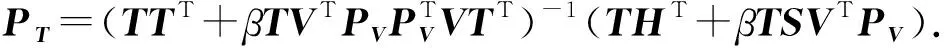
式(18)与式(20)中的VVT,TTT,TVT和VSTT可以提前计算好并在训练过程中直接载入,以节省训练时间.
2.4 时间复杂度分析
本文提出的跨模态散列方法在训练过程中一共有4个未知变量需要求解,即W,H,PV和PT.在每一轮迭代中,求解W的时间复杂度是O(nc2+nL2+ncL+L3);求解H的时间复杂度是O(ncL2);求解PV与PT的时间复杂度分别是O(ndL+4fdl+d2L)与O(nfL+4fdl+f2L).因为n≫c,n≫L,假定迭代次数为M,所以SDCH的训练时间复杂度可以简化为M×O(nL(cL+d+f)).可以看出,本文提出的算法训练时间与训练集的样本数量成线性关系,这为大规模训练集的使用提供了可能性.
3 实验与结果
本节主要介绍本文要用到的数据集、方法的评估标准、超参数设置以及实验结果与分析.
3.1 数据集说明
MIR-flickr是从Flickr上收集的图像-语句数据集[20].每个样本对拥有一个24维的类别标签.图像模态由150维边缘直方图来表示,而文本模态则由主成分分析法[21]降维到500维后的词向量来表示.在本文中,使用了15 902个样本对作为训练集,836个样本对作为测试集,将训练集与测试集的并集作为检索集.
NUS-WIDE是从互联网上收集的1 000类的图像的数据集[22],本文选取了样本数目最多的10类用作研究.在此数据集中,图片模态使用500维SIFT词袋向量[23]来表示,而文本模态使用10维的标签作为特征.在本文中,使用了17 000个样本对作为训练集,994个样本对作为测试集,剩余的50 000个样本对作为检索集.
本文所提出的方法SDCH在MIR-flickr上的参数设置为α=2,β=10-4,λ=10-6;在NUS-WIDE上的参数设置为α=2,β=10-7,λ=10-6.在2个数据集上迭代次数都是6次.
3.2 评估标准
基于以上2个数据集,本文测试了2种跨模态检索任务:1)Img2Text,用图片检索文本数据库;2)Text2Img,用文本检索图片数据库.检索任务中广泛使用平均精度均值(mean average precision, mAP)被用作评估指标.mAP是通过平均检索到的排序后的样本平均精度值(average precision, AP)来得到的.此外,准确度precision@K,即仅考虑检索出的前K个样本,也被用于本文的性能评估.
3.3 实验结果与分析
本文在上述2个数据集上,通过实验比较了本文所提出的方法与跨视图散列(cross-view hashing, CVH)[24]、媒体间散列(inter-media hashing, IMH)[2]、潜在语义稀疏散列(latent semantic sparse hashing, LSSH)[3]、最大化语义相关性(semantic correlation maximization, SCM)[5]、离散跨模态散列(discrete cross-modal hashing, DCH)[12]、快速离散跨模态散列(fast discrete cross-modal hashing, FDCH)[15]、可拓展的离散矩阵分解散列(scalable discrete matrix factorization hashing, SCRATCH)[9]和两步跨模态散列(two-step cross-modal hashing, TECH)[10]8个跨模态散列方法. 其中,CVH,IMH,LSSH是无监督的,其他的方法都是有监督的.此外,这些基线方法的所有超参数都按照原始论文中的建议进行了初始化.我们对于上述基线方法和所提出的方法都是运行了5次,然后取平均性能进行比较.由于本文提出的方法是基于线性模型的,因此没有考虑与深度方法进行比较.表1展示了本文中提出的方法与8个基线方法在MIR-flickr和NUS-WIDE上的mAP分数.表格上半部分是Img2Text任务的性能,下半部分是Text2Img任务的性能.最好的mAP分数用加粗字体表示.可以看出,随着散列码长度的增加,mAP分数也越来越高;本文所提出的方法在2个数据集上的2种任务,即Img2Text与Text2Img,都取得了最好的mAP分数.
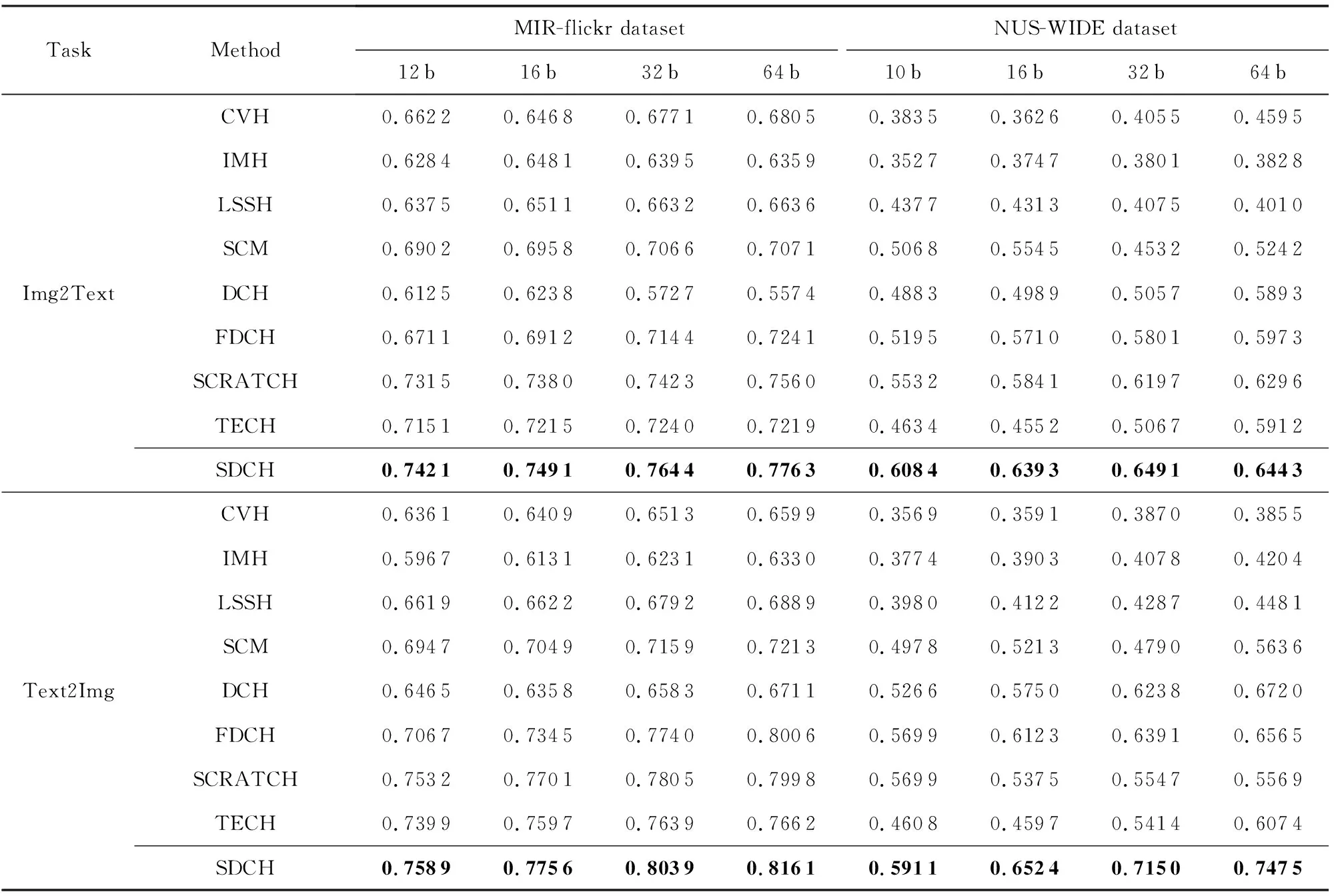
Table 1 mAP Scores for Two Retrieval Tasks Based on two Benchmark Datasets表1 各方法在2个基准数据集上的mAP分数
图1是散列码长度分别为16 b,24 b,32 b,48 b,64 b,96 b和128 b时,SDCH方法与其他方法的在2个基准数据集上2种检索任务平均的precision@50性能折线图.从图1可以看出,相比于8个基线方法,本文所提出的方法SDCH表现出更好的性能.还可以看到,在大多数情况下,较长的散列码精度较高,这是因为较长的散列码可以保留样本更多的语义信息.
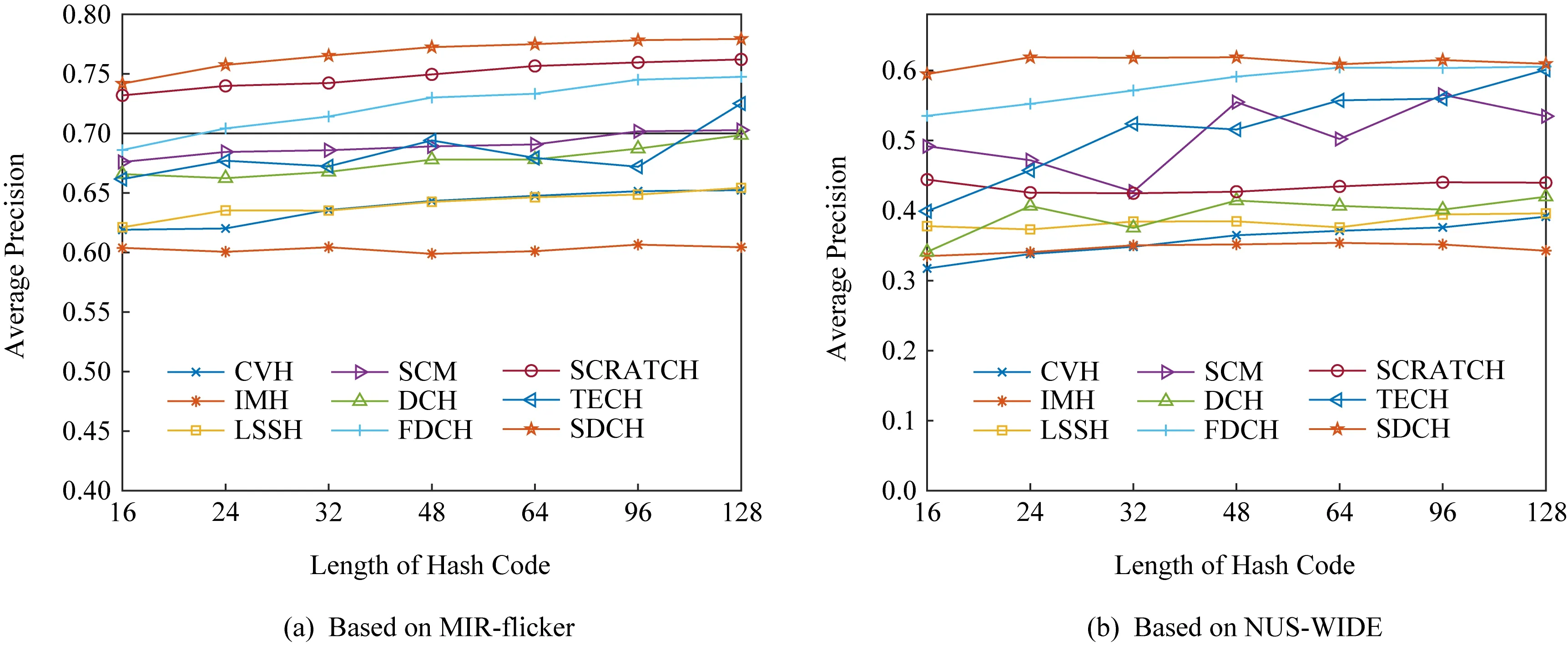
Fig. 1 Average precision@50 of two retrieval tasks based on two benchmark datasets图1 各方法在2个基准数据集上2种检索任务的平均precision@50分数
为了验证所提出方法的参数灵敏度,并指导参数的调整,本文设置了一系列不同参数的实验.图2显示了当α数值在{0.1,0.3,0.5,0.7,1,3,5}范围内变化和lgβ数值从-7到-1时SDCH在2个数据集、2种检索任务上平均的precision@50的性能.结果表明,本文提出的SDCH方法具有较好的算法稳定性和参数灵敏度.
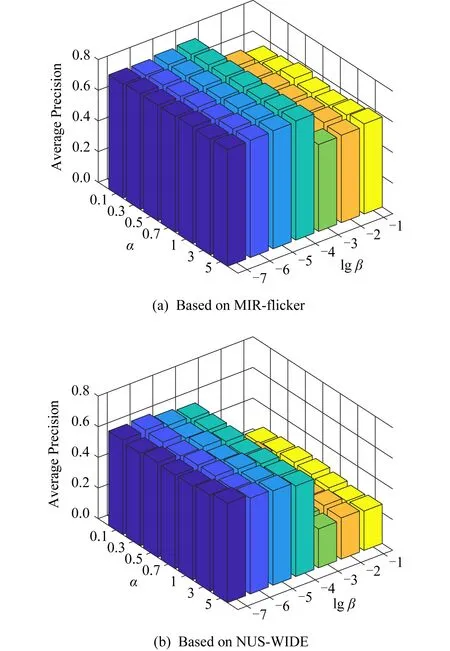
Fig. 2 Average precision@50 with differentsetting of α and β图2 当α和β在一定范围内变化时的平均precision@50分数
图3展示了使用本文提出的SDCH的目标函数值在2个基准数据集上随着迭代次数的增加的变化图.其中MIR_H表示在MIR-flickr数据集上散列学习过程中的目标函数值变化曲线,MIR_P则表示学习用于产生新样本散列码的映射的目标函数值变化曲线.类似地,NUS_H与NUS_P表示在NUS-WIDE数据集上相应的目标函数值变化曲线.散列码长度是64 b.每条线中,第1次迭代时的值被当作100%.从图3可以看出,随着迭代次数的增加,目标函数值迅速变小且稳定.本文提出的方法SDCH在训练过程中迅速达到较好的收敛水平,从而大大减少了训练所需的时间.
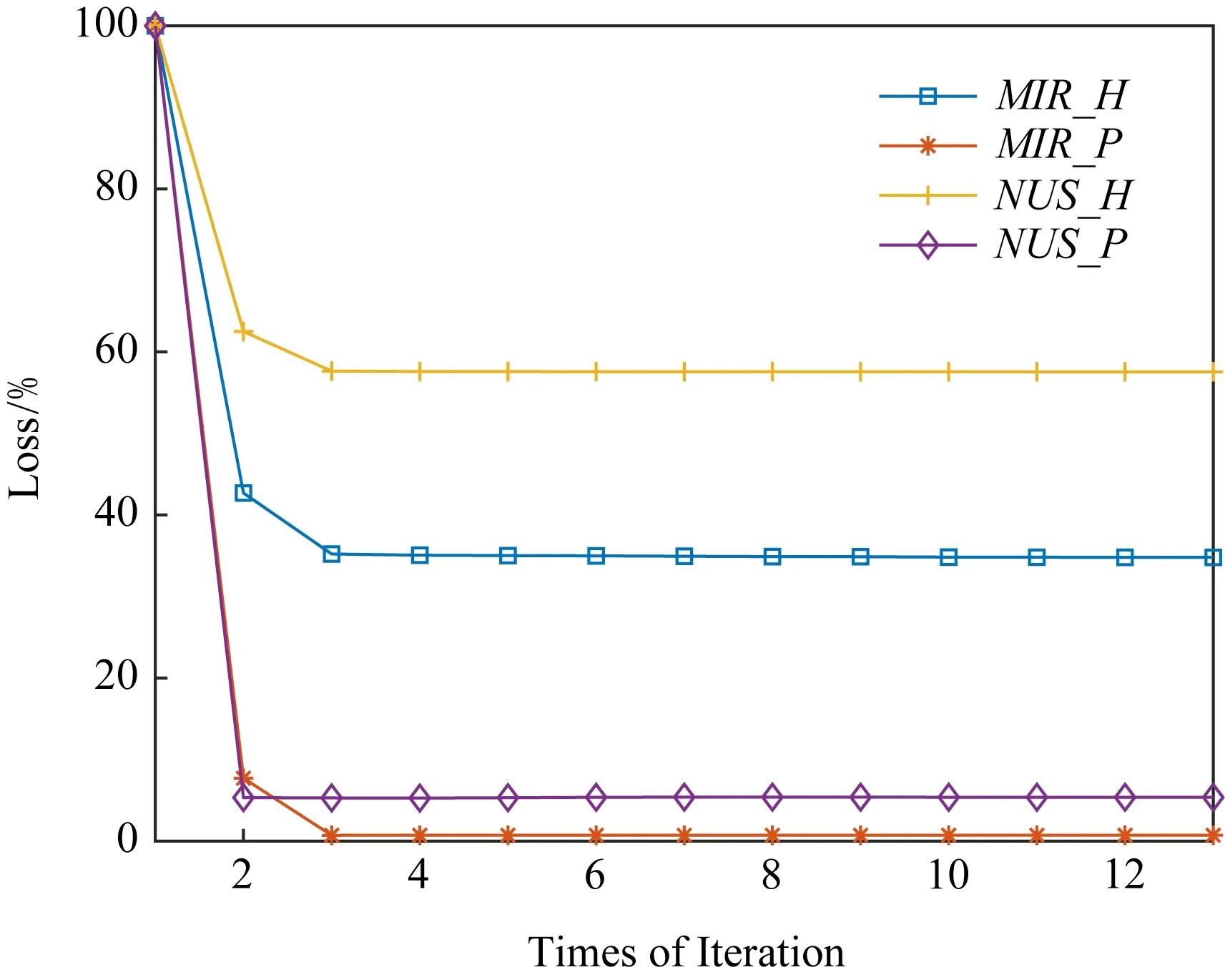
Fig. 3 Changes of objective function value图3 目标函数值随着迭代次数增加的变化
4 结 论
本文提出了一种有监督的离散跨模态散列方法SDCH.此方法采用了一个双向映射矩阵来描述散列矩阵与标签矩阵的关系.这种策略可以很好地保持语义散列码与标签之间的语义相关性.此外,本文在学习用于生成新样本散列码的模态特定的映射时,保持了各个模态特征数据与相似度矩阵的一致性.另外,所提出的方法仅使用相当少的变量和参数,从而在参数调整和训练过程中节省了大量时间.在2个基准数据集上进行的大量实验证实了所提出的方法的优越性.将来,我们计划用神经网络模型来改进本文的方法以获得更高的准确度.
