基于多源情境协同感知的药品推荐
2020-08-25廖祥文刘同柱童贵显
郑 值 徐 童 秦 川 廖祥文 郑 毅 刘同柱 童贵显
1(中国科学技术大学计算机学院 合肥 230027)2(福州大学数学与计算机科学学院 福州 350116)3(华为技术有限公司 杭州 310051)4(中国科学技术大学附属第一医院 合肥 230027)(zhengzhi97@mail.ustc.edu.cn)
随着人口的增长与老龄化的加剧,人们对于高质量医疗服务的需求不断攀升,医疗系统的接诊压力与日俱增.根据国家卫健委所发布的全国医疗卫生统计数据显示(1)2018年1~10月全国医疗服务情况. http://www.nhc.gov.cn/mohwsbwstjxxzx/s7967/201901/296ad9bb4a594a60b8755e7dcfff0f20.shtml,2018年1~11月,全国医院诊疗人次共32.3亿人次,同比增长5.3%.与之相对应的是,截止2019年,我国每千人口医生数为2.59人(2)国家卫健委:我国每千人口医生数达到2.59人. http://news.cctv.com/2019/09/26/ARTIWoF5GSg6C8JBZIBRsFaL190926.shtml,与发达国家相比仍有着较大的差距,也导致了医护人员沉重的负担和医疗资源巨大的缺口.因此,若能有效借助人工智能技术,实现患者病情的智能化诊断与药品推荐,将极大地提高医疗系统运行效率,提升我国医疗服务的整体质量.
幸运的是,随着信息技术在医疗行业的普及,电子病历(electronic medical record, EMR)开始被各大医院广泛采用.通过医疗记录的数字化,海量丰富的诊疗信息,如患者的病程记录、检查检验结果、医嘱、手术记录、药品记录等得以记录,并有力支撑下游由大数据驱动的各种智能应用.在此基础上,相关领域的学者们展开了一系列的研究,并在智能导诊[1]、医疗影像分析[2]和慢性病随访[3]等方面取得了不错的成效.但在面向医疗文本的智能化诊断与药品推荐方面,受限于数据、技术等方面的原因,进展尚较为缓慢.首先,我国电子病历推广较晚,导致目前可靠的医疗数据来源较少,且存在数据积累较少、各科室数据无法关联的问题.其次,与传统的推荐系统类似,药品推荐问题对数据质量较为敏感,也极大地影响了其推荐的效果,主要体现在3个方面:1)绝大多数患者仅有一次就诊记录,不可能采用常规的个性化推荐技术加以建模;2)疾病分布严重不均,常见疾病占据了绝大多数的病历记录,而小众人群和罕见疾病则严重稀疏,难以保障其推荐质量;3)疾病的症状之间存在较高比例的重叠.以本次爆发的新冠肺炎为例,其早期症状与其他肺炎乃至普通流感有着颇多相似之处,即使有经验的医生也存在误判的风险.上述3个方面最终导致了一个共同的结果,即推荐的药品倾向大众化,缺乏面向特定人群、特定疾病的针对性.因此,我们迫切需要一种更为精细的推荐方法,以提升药品推荐的精确性和针对性.
与此同时,我们注意到电子病历在记录病人病情与诊疗过程的同时,也往往记录一些周边的情境信息,如患者的个人情况、开支、就诊时间等.而这些信息可望为我们实现人群细分的针对性诊断和开药带来新的线索.例如,通过就诊时间追溯天气、温度的变化,有助于我们诊断部分心脑血管或上呼吸道疾病;又如,根据病人是否采用医保支付,可以在确定推荐药品的品种时有所取舍.一个典型的例子是,在空气污染较为严重的时段,“流涕”对应抗过敏药物的概率要高于一般时段,因为此时这一症状更可能由于污染而非常规感冒导致.显而易见,借助情境感知数据挖掘技术,将为我们解决前述的困境提供了新的思路.
然而,这些数据同时也带来了新的难点,即如何综合考虑这些情境信息以实现有效诊疗.一方面,情境信息多属多源异构数据,面临信息不全、结构不统一的问题,除部分结构化数据外,还有大量信息以半结构化或非结构化文本的形式存储,处理起来较为困难;另一方面,情境信息对于药品的影响方式不同,如患者的性别和年龄的不同会导致患者适用药品的不同,而患者发病时的天气、温差等外界因素,则会导致患者易发不同的疾病,从而间接影响医生为患者所开的药品.因此倘若笼统地对所有的情境信息进行不加区分的建模,则可能削弱这些信息所起到的贡献.此外,最为重要的是,情境信息的类别多种多样,每种类别又对应着多种取值,若按照传统推荐系统的做法将每种组合当成一个“用户”,在情境信息数量较多时组合数也会迅速增加,带来“维度灾难”的问题,从而导致对训练数据量的需求过大,在实际应用中难以取得良好的效果.
为了解决上述的问题,本文提出了一个基于多源情境协同感知的药品推荐方法Medicine-LDA(以下简称MLDA).事实上,本文通过模拟现实中医生对病人的诊断过程进行建模.在实际诊疗过程中,医生首先获取患者主诉并进行体格检查,然后进行必要的化验,通过化验所得的异常结果以及主诉和体格检查中的信息综合判断患者所患疾病,进而考虑患者的年龄、医保等情境信息,给出一组合适的药品.受此启发,本文通过4个步骤对此过程进行建模:
1) 提取数据中患者的主诉文本与检查检验异常,使用词袋模型将其综合为一个文档,用此文档代表此患者,称之为病情文档;
2) 使用主题模型对病情文档进行建模,假设该文档拥有一个潜在主题,该潜在主题代表患者所患疾病,拥有对应的药品分布和词分布;
3) 将患者对应所有情境信息综合为一个文档,称之为情境文档,使用LDA模型对其进行建模,获得患者的情境主题分布;
4) 假设情境主题对于患者所患疾病和患者适用药品均会造成影响,使用一个统一的概率模型框架融合药品主题和情境主题,从而对情境信息、病情信息和药品信息综合建模.
本文的主要贡献包括3个方面:
1) 提出一种基于LDA的情境信息处理方法,将患者的情境信息表示为情境主题分布,解决了不同情境信息组合数过多的问题.
2) 提出一种通用的融合情境信息的主题模型,该模型在融合情境信息时,同时考虑了情境信息对于患者易患疾病的影响和患者适用药品的影响,能够更有效地对情境信息的作用进行建模,并且具有良好的可扩展性与可解释性.
3) 在一个真实的来自大型三甲医院的数据集上进行了充分的实验,实验结果表明本文方法在药品推荐上具有较好的有效性,证实了模型的实际应用价值.
1 相关工作
本节从药品推荐系统,情境感知推荐系统以及主题模型3个方面介绍本文的相关工作.
1.1 药品推荐系统
目前,关于药品推荐的研究并不十分广泛,大部分药品推荐主要是利用用户与药品的交互记录,基于协同过滤技术来进行推荐.如文献[4]为了解决协同过滤推荐精度低的问题,提出基于用户相似度和信任度的药品推荐算法.该方法通过对药品聚类来降低时间复杂度,引入共同评分药品阈值和相似度阈值辅助选取相似邻居,并根据用户推荐可信度和评分可信度建立相似计算模型,从而提高系统推荐精度.文献[5]在用户评分相似度的基础上,引入人口属性相似度,通过加权线性融合来得到用户相似度.文献[6]提出利用聚类和基于用户的协同推荐算法对网上购药的用户进行个性化药品推荐.针对协同过滤冷启动以及数据稀疏性等问题,提出使用张量分解对用户、症状、药品三者进行建模.
以上研究均使用传统协同过滤中针对用户和物品的交互关系进行推荐的思想,并且仅使用患者对药品的打分以及患者的症状等简单信息描述一名患者.然而在实际应用中,患者的数量巨大,且绝大多数患者的记录数据较少,使用协同过滤的方法难以扩展至医院等大型医疗场所.另外,由于药品推荐的特殊性,仅仅使用患者口述症状和患者对药品的打分记录对患者进行刻画是十分不准确的.因此,以上方法由于模型本身的缺陷以及使用信息的不全面,难以实现有效的落地应用.
1.2 情境感知推荐系统
传统推荐系统,如基于内容的推荐与协同过滤等方法,忽略了用户在不同情况下会具有不同的偏好行为[7].因此,研究者们提出了“情境感知”的数据挖掘技术以提升推荐的效果.所谓“情境”,指所有与人机交互相关的,用于区分标定当前特殊场景的信息.由于相同用户在不同情境下的喜好往往不同,基于情境感知的推荐系统可以根据用户所处的特定境况来给出更相关的推荐结果.文献[8]对情境感知推荐系统进行了较为详细的综述,指出情境感知推荐系统中的推荐流程可以有情境预过滤、情境后过滤、情境建模3种形式.其中,情境建模方法直接在推荐中把情境信息作为预测的显式因素来考虑,是研究最为广泛的情境感知方法.例如文献[9]提出将情境信息作为特征维度加入推荐系统的表示向量空间中来进行情境建模.该文使用支持向量机(support vector machine, SVM)作为分类器,证实了情境感知的SVM推荐效果优于非情境感知SVM.而文献[10]使用张量分解的方法,对情境信息与基于隐式反馈的协同过滤进行了结合,并针对评价指标MAP进行了优化.
在药品推荐系统中,情境信息泛指一切影响患者病情与适用药品的因素.例如患者的性别、年龄、医保信息等内因会影响到患者的适用药品,当地的天气、温差等外因会影响患者的易患疾病并间接影响患者药品.本文提出了一个能够有效融合各类情境信息的药品推荐系统,能解决药品推荐实际应用中的问题.
1.3 主题模型
主题模型(topic model)是对语料库中的隐含语义结构进行聚类的统计模型,被广泛应用于自然语言处理中的语义分析和文本挖掘问题.隐含狄利克雷分布(latent Dirichlet allocation, LDA)是最常见的主题模型[11],其假设文档以一定的概率选择某个潜在主题,再从主题中以一定的概率选择一个单词,从而生成整个语料库.LDA可以通过引入外部标签信息进行各种扩展,如Labeled-LDA(LLDA)[12]是对LDA模型在多标签语料库中的扩展,其假设语料库中的标签与潜在主题一一对应,从而使得模型直接学习外部标签与文档词之间的关系,在文档多标签学习任务中取得了较好的效果,Author-Topic Model(ATM)[13]在LDA中融合了作者信息,从而获得不同作者对于不同主题的偏好.扩展过的主题模型可以被应用于推荐系统,如文献[14-16]利用主题模型对推特标签进行推荐,文献[17-18]利用主题模型对微博等文档进行推荐.
通过LDA模型得到的主题本质是隐式地学习得到词语之间的共现关系,此类方法在文档平均单词数较多的语料中效果较好,而面对如推特、短信息的平均词数较短的文本时,由于短文本中的词语共现不够频繁,此类方法效果往往不佳.有部分工作针对这一问题进行了研究,如文献[19]提出Twitter-LDA,假设每个文档仅有一个主题,并使用一个伯努利分布判断文档中的词语属于主题词还是背景词,全部的主题词均由文档的唯一主题对应的词分布生成,在推特数据集上的实验证实Twitter-LDA在推特文本数据集中可以比LDA取得更好的效果.文献[20]提出BTM(biterm topic model),直接对整个语料库中的词语共现关系进行显式的建模,从而缓解了短文本中词语共现次数不足的问题.实验表明BTM不仅在短文本上的表现超过LDA,并且在长文本上也取得了优于LDA的效果.本文基于文献[19]加以改进,假设每篇文档仅有一个主题,有效地提高了模型的效果.
2 预备知识
本节我们首先介绍本文研究工作中所采用的数据集及预处理情况,然后对本文所探讨的药品推荐问题给出正式的定义.
2.1 数据预处理
首先,我们通过模拟现实中医生对病人的诊断过程对问题进行描述.在实际诊疗过程中,医生往往会在患者的医疗文本中记录患者的主诉病情,以及医生对患者进行的体格检查.医生为患者编写的医疗文本,以及患者进行的化验等检查检验的结果是判断患者病情最为重要的依据.为此,本文选择医疗文本和患者检查检验描述患者病情,并对患者对应的医疗文本与检查检验进行如下处理:首先,对医疗文本进行分词处理,并去除停用词,得到患者对应的文本文档.然后选出患者进行的化验中的全部异常项,并将每一个异常项的与对应的异常状态组合成若干个词,如将“乙肝核心抗体”与其对应的异常状态“偏高”组合成词“乙肝核心抗体偏高”,由此得到患者的化验文档.随后,将患者的文本文档与化验文档组合起来,即得到了基于词袋模型的病情文档,用于描述患者病情.
对于患者对应的情境信息,由于每种情境信息可能对应较多的取值,如“年龄”这一情境信息可以对应上百种取值(0~100以上),因此需要对情境信息进行分段处理,将同一类别的情境取值范围进行分段,并将每种情境与其对应的分段组合成若干个情境词,如将“年龄”和“老年”组合成“年龄-老年”,由此得到患者的情境文档.在表1中,我们对本文用到的全部情境信息与其对应分段方法进行了总结,分段的依据包括:1)生活常识,如性别分为男女,季节分为春夏秋冬;2)数据特征,如麻醉类型分为了全身麻醉、局部麻醉与未麻醉;3)外部知识,如依据常见年龄分段法对年龄进行分段,依据保险金额与条件对保险情况进行分段;4)对于温差、气温等无参考知识的情境,依据生活常识与数据分布,使得不同分段内的数据分布较为均匀,同时分段方式贴近人们对于生活的认知.

Table 1 Context Information and Segmentation Method表1 情境信息与其分段方法
2.2 形式化描述
基于2.1节中的定义,我们将本文所研究的问题形式化描述如下:在情境感知药品推荐任务中,训练集中包含每一名患者i对应的病情文档Wi={wi,1,wi,2,…,wi,p},其中wi,·为医疗文本的分词得到的单词或单个化验异常项.相应的,我们有情境文档Ti={ti,1,ti,2,…,ti,q},其中ti,·为单个情境词.此外,我们有药品集合Di={di,1,di,2,…,di,s},其中di,·为医生为该患者所开的全部药品中的某一种药品.本文所研究问题的目标是通过对训练集进行学习,使模型在给定测试集中新病情文档W′和新情境文档T′时,可以对于任意一种在数据集种出现过的药品di,输出其对此患者使用的概率pi.
由此可见,该问题本质上是一个多标签学习问题,且要求所用方法能够给出全部标签的概率分布.为此,本文使用基于主题模型这一概率模型的方法来融合情境信息进行药品推荐.
3 情境感知药品推荐方法
本节我们将对本文所提出的多源情境协同感知的药品推荐方法,及其所涉及的情境信息建模技术进行详细的介绍.
3.1 模型概述
本文所提出的模型大致步骤为:
1) 模型需要对情境信息进行处理.尽管在数据预处理部分中已经对情境信息的取值进行分段处理,然而,若假设有K种情境信息,每种情境有N个取值分段,则将有NK种组合方式,导致模型难以处理较多数目的情境信息.为此,本文使用LDA模型,通过情境信息主题化的方式对情境信息进行软聚类,从而缓解情境信息组合爆炸的问题.
2) 本文使用一个概率框架对情境信息、病情文档、患者药品进行联合建模.建模思想来自实际医疗场所中的诊疗过程,即医生首先根据患者的症状、体格检查、化验报告来确定患者可能患有的疾病,然后根据患者对应的情境信息给出对此疾病适宜的药品.为此,本文使用基于主题模型的建模方法,假设每一篇病情文档均拥有一个隐变量,表示该患者所患的疾病,因此称之为疾病主题.具体而言,模型通过疾病主题联系情境、病情、药品3种信息进行建模,其技术细节将在以下的章节给出详细的介绍.
3.2 情境信息建模方法
为了解决患者情境信息组合爆炸的问题,需要设法对情境信息进行降维处理.一般而言,聚类是解决此类问题的常用手段,其大致可分为硬聚类和软聚类2种.其中,硬聚类方法对数据进行确切的分类,规定样本只能完全属于某一个类或完全不属于某一个类,代表算法有K-Means算法等.在本文场景中,情境信息代表人群的特征,由于人群特征多种多样,不同人群相似度、不同特征的重要程度均不尽相同,对人群进行硬聚类在应用中缺乏合适的分类标准,且难以给出合理的解释,因此不适用于本文场景.
与硬聚类不同的是,软聚类把数据以一定的概率分到各类中.例如,高斯混合模型(GMM)就是一种典型的软聚类方法.而对于文本数据,利用LDA主题模型进行软聚类的方法更为常用.对于患者对应的情境信息而言,若使用词袋模型把每名患者对应的全部情境信息视为一篇情境文档,则可使用LDA模型通过主题建模来进行软聚类.图1为LDA模型的概率图表示,其中w为文档单词,z为隐变量表示文档主题.在训练得到每种主题的词分布后,LDA模型可以将任意文档表示为一个主题分布,此即为软聚类中各类别的概率分布.
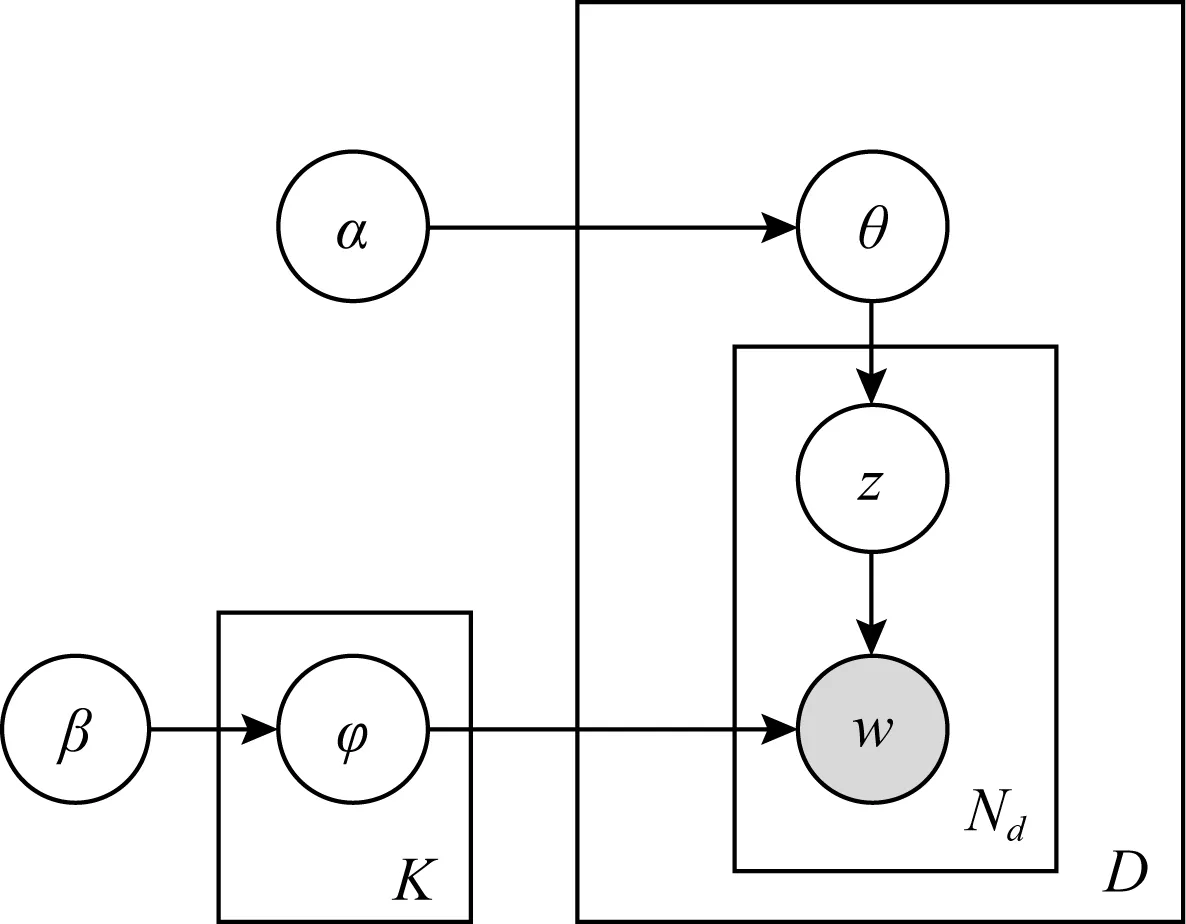
Fig. 1 Graphical representation of LDA图1 LDA模型的概率图表示
本文采用文献[21]中的LDA吉布斯采样法对模型进行求解.首先,对每一篇情境文档中的每一个词赋予一个随机情境主题.在接下来的每一轮迭代更新中,针对文档中的每一个词,首先根据其他词的主题赋值来求解该词被赋予不同情境主题的概率,然后根据这个概率对该词重新赋予情境主题.在多次迭代收敛后,每个词均被赋予了固定的情境主题,从而可以使用式(1)计算得到每一篇情境文档的主题分布.
(1)
其中nd,z表示情境文档d中词语被赋予主题z的数量,α为狄利克雷先验参数,K为情境主题数.
3.3 情境感知的药品推荐方法
完成对情境信息的软聚类后,即可对全部信息进行综合建模.本文提出的建模方法基于对诊疗过程的2点假设:1)情境主题是情境信息的软聚类,每种情境主题既可能影响患者的适用药品,又可能影响患者的易发疾病.如以天气、季节等因素为主的情境主题会更偏向于影响患者的易发疾病,而以手术、医保等信息为主的情境主题更可能影响医生对于患者的药品使用.2)每名病人的数据对应一个隐变量,代表患者所患疾病,称之为疾病主题.疾病主题是连接情境信息、病情文档、药品三者的纽带,情境主题影响疾病主题的分布,而疾病主题影响病情文档中的词分布以及药品集合中的药品分布.根据这2点基于真实诊疗过程的假设,本文提出了一个统一的概率模型Medicine-LDA(简称MLDA)进行情境感知的药品推荐.以下给出模型的详细描述.
假设语料库中有K个疾病主题,F个情境主题,每一个疾病主题拥有一个对应的病情文档词分布,每一个疾病主题和情境主题的组合拥有一个对应的药品分布.令φ为疾病主题对应的病情文档词分布,φB为背景词分布.θ为每种人群对应的疾病分布,f为每种疾病主题和每种情境主题的组合对应的药品分布,ψ为患者对应的情境文档的情境主题分布,π为一个伯努利分布,其作用如文献[19]所述,用于筛选文档中与主题推断关系较小的词语,控制病情文档中的词属于背景词还是主题词.图2给出模型的概率图表示,病情文档与药品集合的生成过程如下所述,其中符号描述如表2所示.
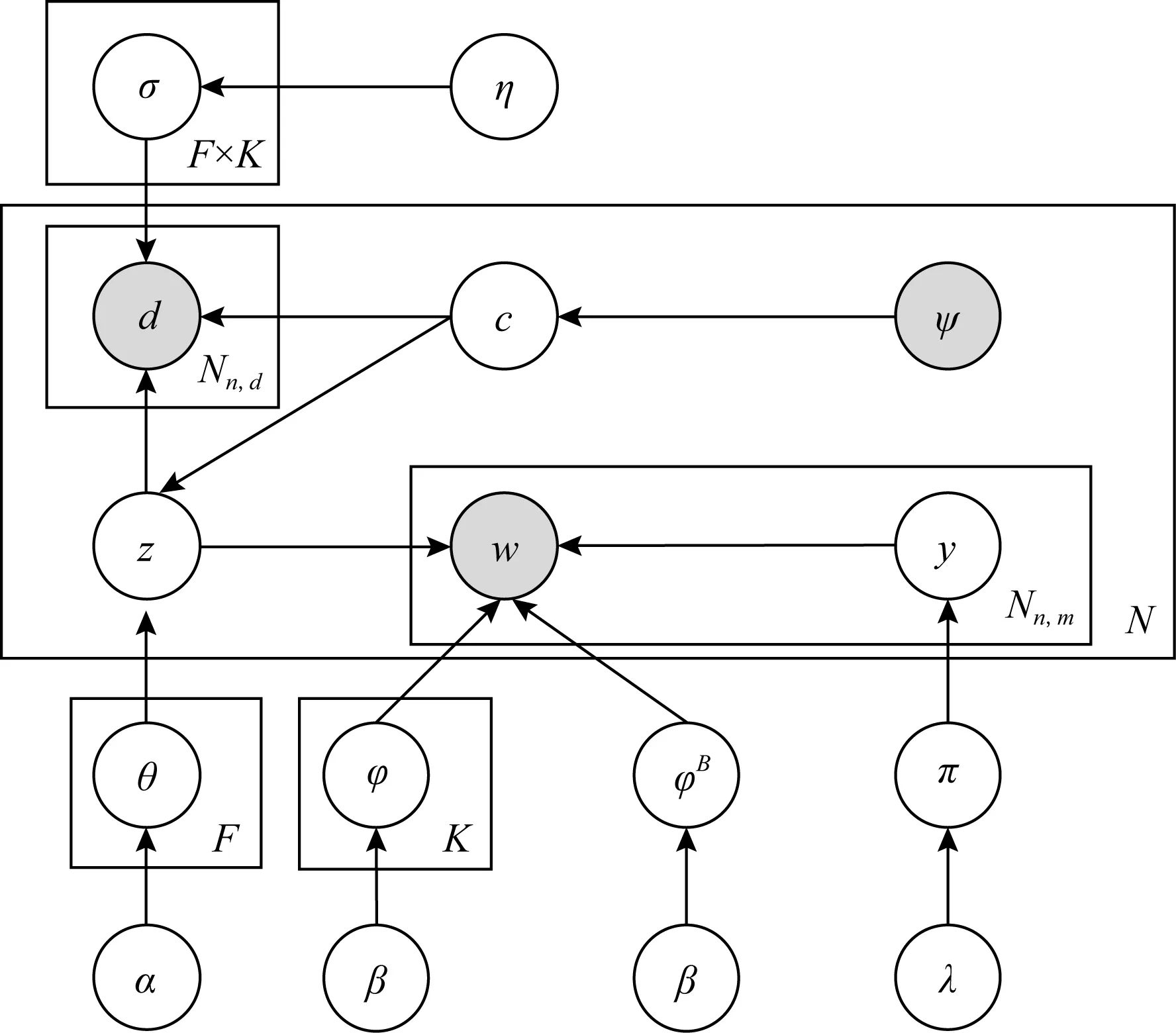
Fig. 2 Graphical representation of MLDA图2 MLDA模型的概率图表示

Table 2 Basic Symbols Description表2 基本符号描述
1) 采样获得φB~Dir(β),π~Beta(λ).
2) 对于每一种疾病主题z∈{1,2,…,K}采样获得φk~Dir(β),对于每一种情境主题c∈{1,2,…,F}采样获得θc~Dir(α),对于每一种疾病主题与情境主题的组合(z,c)∈{(1,1),(1,2),…,(K,F)},采样获得fz,c~Dir(η).
3) 对于每一名患者n∈{1,2,…,N}:
① 采样获得患者情境主题cn~Multi(ψn);
② 采样获得患者疾病主题zn~Multi(θc);
③ 对于病情文档中每一个词m∈{1,2,…,Nn,m}:
i. 采样获得yn,m~Ber(π);
ii. 若yn,m=0,则采样wn,m~Multi(φB);若yn,m=1,则采样wn,m~Multi(φZn);
④ 对于药品集合中的每一种药品m∈{1,2,…,Nn,d},采样获得dn,m~Multi(fz,c).
3.4 采样与推断算法
MLDA需要对隐变量z,c,y进行推断,由于精确推断算法不可解,本文使用倒塌的吉布斯采样法(collapsed gibbs sampling, CGS)对隐变量进行采样,并根据统计获得参数θ,φ,f,进而使用训练得到的参数对新患者进行药品推荐.
训练时的采样算法如下.首先对与训练集中所有数据进行随机初始化:对于第n条数据,随机赋予情境主题隐变量cn和疾病主题隐变量zn,对于第n条数据中的第m个病情文档词,随机赋予其对应标识隐变量yn,m.随后在吉布斯采样的每一轮迭代过程中,对于任意一篇文档的任一隐变量,将对给定其余隐变量时该隐变量的条件概率分布进行采样,从而更新其取值.隐变量z与c的条件概率分布为
p(zn=k,cn=f|ψn,w,d,z,y,α,β,η)∝
(2)
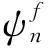
对于病情文档中的每一个词,其对应的标识变量y的条件概率分布为
p(yn,m=0|w,z,c,d,y,λ,β)∝
(3)
p(yn,m=1|w,z,c,d,y,λ,β)∝
(4)
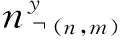
经过多轮迭代至收敛后,可以根据文档集中全部隐变量的赋值获取参数θ,φ,φB,σ,π的取值.
θf,k表示情境主题对应的人群患有某种疾病的的概率:
(5)
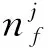
φk,w表示某种疾病主题生成某个词的概率:
(6)
其中φk,w为疾病主题k对应的文档中单词w出现的次数.
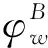
(7)
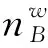
σf,k,d表示某种人群在患有某种疾病时使用某种药品的概率:
(8)
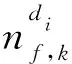
πy表示词语是源自疾病主题还是背景主题的概率:
(9)
其中ni表示标识符i出现的次数.
3.5 药品推荐
假设给定一组测试数据集,其中患者对应药品未知.利用式(5)~(9)的结果可以直接计算出该患者对应所有药品的概率,而无需在测试集中进行采样,因此本方法的药品推荐过程可以非常快速的完成.
推荐过程的具体方法为:假设给定一条新病历(W,T),其中W={w1,w2,…,wp}为患者对应的病情文档,T={t1,t2,…,tq}为患者对应的情境文档.首先通过情境文档处理步骤中训练得到的LDA模型获得T中的情境主题分布ψ,随后由式(10)便可获得该患者对应任意一种药品d的条件概率.
(10)
(11)
获得全部药品概率后,按照概率从大到小进行排序即得到药品推荐的最终结果.
4 实 验
本节详细描述本文实验中所用到的数据集、度量指标、基准方法、参数设置以及实验结果分析.
4.1 实验数据集
Fig. 3 Medicine Frequency图3 药品频率统计
本文实验所用数据来源于某大型三甲医院住院部2015—2018年的电子病历数据库,且经过脱敏处理.对数据集进行清洗、去重等处理,得到158 556条完整电子病历记录,每条数据包括患者从出院到入院所进行的完整诊疗过程记录.通过3.1节所述预处理步骤得到最终所用数据集,其中检查异常种类共1 242种,主诉与体格检查报告分词后得到共41 309种词.药品种类共1 428种,医生平均为每名患者开出20种药品.药品分布存在较为严重的长尾现象,即数据中存在大量低频药品,药品出现频率见图3,其纵轴表示该药品在多少条记录中出现.图4给出了药品出现次数统计的对数形式,纵轴为图3对应点取值以10为底的对数.
Fig. 4 Medicine Frequency with log图4 药品频率统计对数形式
4.2 评价指标
本文所研究的药品推荐问题本质是一个多标签学习(multi-label learning)问题.多标签学习问题的评价指标主要分为2类,分别是基于分类的评价指标和基于排序的评价指标[14].药品推荐的目标是使得真实药品在推荐列表中尽可能排名靠前,为此,本文选用基于分类的评价指标Precision@K(P@K),Recall@K(R@K),F@K和基于排序的指标NDCG@K两个常用的评价指标评测模型的推荐性能.Precision@K,Recall@K,F@K的计算公式如下:
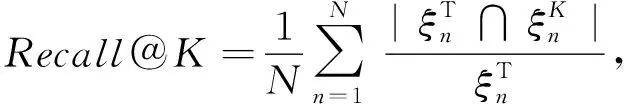
(14)
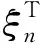
(15)
其中,reln,i表示第n条数据中的第i个药品是否在真实药品集合中,若在则取1,不在则取0.|RELn|表示第n条数据真是药品集合大小.
4.3 基准方法
为了验证本文所提出的MLDA模型的效果,本文选择使用以下12种基准方法进行对比实验,包括主题模型、协同过滤、多标签学习、深度学习等方法,以及本文所提出的模型的变种.
1) Frequency(Freq).该方法统计训练数据中每种药品出现的次数,由高到低进行排列.在进行推荐时,对于测试集中的每一条数据均给出此列表.任何效果低于此方法的推荐方法均视为完全无效.
2) LLDA.Labeled-LDA(LLDA)[12]是对LDA模型在多标签语料库中的扩展,其假设语料库中的标签与潜在主题一一对应,在此将每种药品视为一种标签,将情境文档与病情文档混合作为训练文档,然后使用文献[12]中的方法进行训练与推荐.
3) TagLDA.TagLDA[22]假设每个主题同时拥有文档词分布与标签分布,同时假设文档的标签是对文档的描述,因而文档的主题分布应该与其标签的主题分布相同.在进行推荐时,通过给定的文档获得文档主题分布p(z|doc),然后使用如式(16)计算全部标签d得到概率:
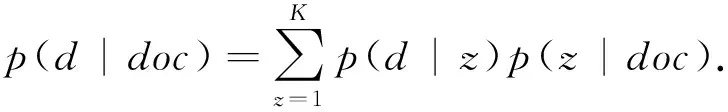
(16)
4) KNN.文献[23]提出了一种文档标签推荐方法,是K近邻算法在多标签数据集中的扩展.给定一个文档doc,此方法根据文档的内容相似度,如cosine距离,来找出与此文档最相似的k个文档.这k个文档中标签出现的概率大小即为模型推荐的标签概率.在本文的药品推荐任务中,由于文档单词数过多,直接计算cosine距离会导致计算量过大,为此本文首先得到患者病情文档,然后使用LDA模型得到病情文档的主题向量,进而使用cosine距离寻找相似文档.
5) MLDT.多标签决策树(multi-label decision tree, MLDT)[24]是决策树算法(decision tree)在多标签学习问题上的扩展.该方法将决策树算法中熵的计算公式扩展至多标签情形,形式为
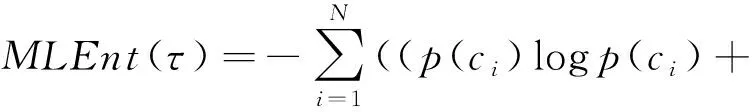
(17)
其中,p(ci)表示类别ci的概率,q(ci)=1-p(ci).
6) CTR.协同过滤(Collaborative Filtering, CF)是推荐系统领域应用最为广泛的方法,其通过相似用户的喜好为用户推荐可能感兴趣的物品.协同过滤可以分为基于邻居的方法(neighborhood methods)和基于隐因子模型的方法(latent factor models)[22],而后者往往可以取得更高的预测精度,其中基于矩阵分解的隐因子模型[25-27]是最为成功的一类模型.
然而,此类方法会遇到冷启动(cold start)问题,对于数据中未曾出现的用户或物品,算法无法直接通过矩阵分解获得其向量表示.为此,文献[28]提出了一种结合主题模型与矩阵分解的协同过滤推荐算法CTR(collaborative topic regression model).该方法使用Topic Model对文本进行表征,从而在冷启动环境下依然可以获得向量表示.根据文献[28],可以使用LDA模型获得每一名患者j对应文档的主题分布θj,进而使用公式ri,j=(ui)Tθj计算药品i推荐给病人j的概率大小,其中ui为药品的表示向量.为了得到药品的表示向量,CTR使用下式对训练集进行建模:
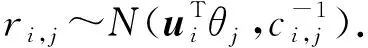
其中,ri,j取值为0或1表示药品i的在患者j的药品集中出现与否.ci,j用于控制药品出现与否对于向量影响的重要程度,形式为
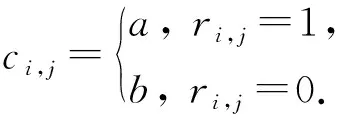
7) MLP.多层感知机(multilayer perceptron,MLP)是神经网络的一类经典模型,包括输入层、输出层和多个隐藏层.MLP模型可以简单且高效地进行特征表示,进而进行各类推荐任务.在此将患者的病情文档和情境文档进行联合作为输入层的输入,使用Relu函数作为激活函数,训练其输出每种药品推荐的概率.
8) W&D.Wide & Deep(W&D)[29]是一种得到广泛应用的深度学习推荐模型,其模型融合了浅层(Wide)和深层(Deep)神经网络,利用浅层模型的记忆能力和深层模型的泛化能力,实现单模型对精确性和扩展性的兼顾.在此将患者的病情文档和情境文档进行联合作为模型浅层和深层部分共同的输入,另外,由于W&D模型是为点击率预测问题设计,其输出单元维度为1,在此对其进行扩展使其输出多个维度.
9) NTM.Neural Topic Model(NTM)[30-31]是近年来新兴的一类融合主题模型与深度学习的方法,在文本建模[30]、推荐系统领域[32]均取得了应用.NTM采用变分推断对主题模型进行求解,并使用深度学习技术对变分推断过程进行拟合[30],从而提高模型的训练速度与准确率.本文采用文献[33]中的方法使用变分推断求解MLDA模型,并使用神经网络进行训练.值得注意的是,MLDA模型中的情境主题模块无法简单融入NTM模型,因此使用与MLP模型相同的联合文档作为输入.
此外,我们通过对本文方法剔除部分模块以进行消融实验,所涉及的对比方法包括:
10) MLDA-pure.修改本文提出模型,不考虑情境信息的影响,仅根据病情文档进行推荐.
11) MLDA-z.修改本文提出的模型,不考虑情境主题c对于药品分布f的影响,仅考虑c对于疾病主题z的影响.
12) MLDA-c.修改本文提出的模型对于情境信息的处理方法,不对情境信息进行单独处理,而是将原始的情境文档中的词直接加入患者的病情文档,直接将其视为与化验异常、医疗文本词作用相同的用于描述患者的文本特征.
4.4 实验结果
表3给出了不同方法在数据集上的性能表现,每个实验结果均为5折交叉验证所得.其中LLDA模型中主题-词先验设为0.01;Tag-LDA中主题数设为50;主题-词先验设为0.01,CF中向量维度设为30,相似文档数设为40;CTM中向量维度设为30,参数a和参数b分别设为1和0.5,正则化参数设为2;MLDT中设置叶节点中最小包含样本数目为30.在本文提出的MLDA模型中,设参数K=400,F=10,α=0.1,β=0.1,λ=0.1,η=0.01,迭代次数为30轮.所有模型参数均通过网格搜索法调至最优.
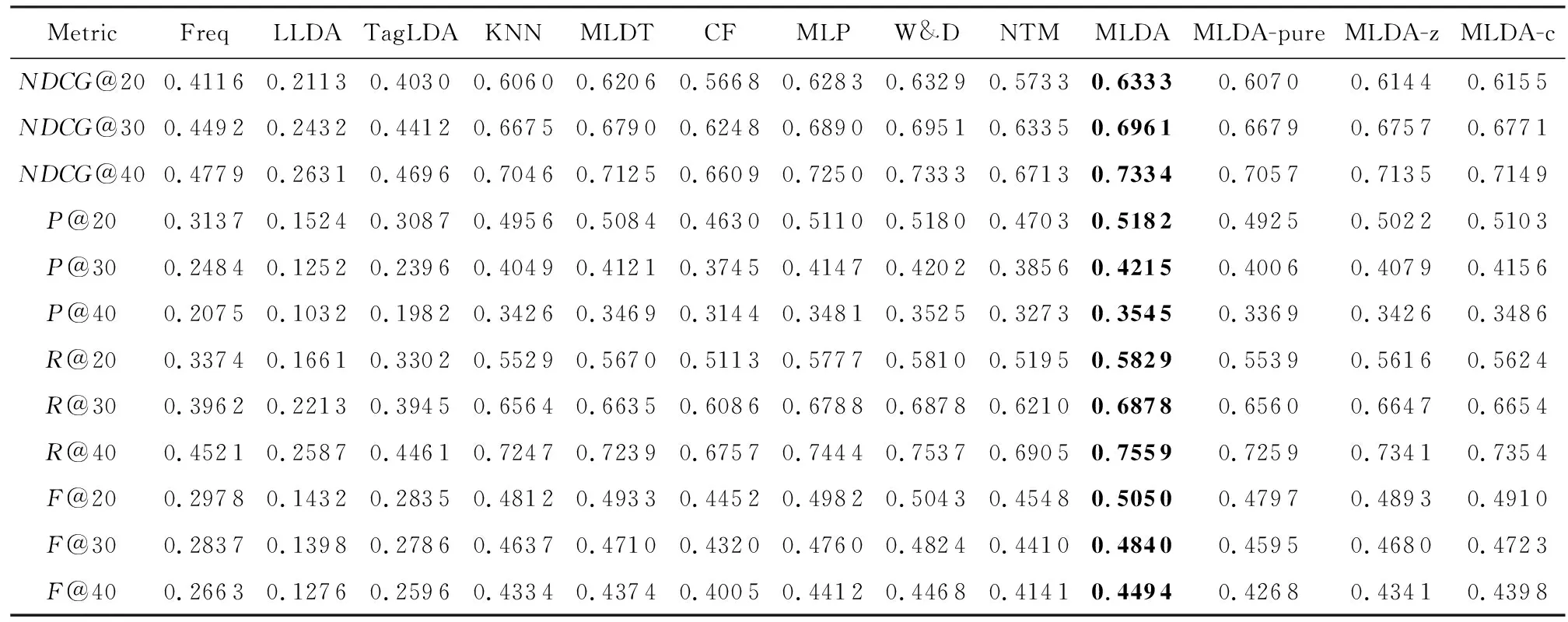
Table 3 Comparison of Different Methods表3 不同方法性能对比
通过对表3的观察可以得出5个结论:
1) 基于传统主题模型的推荐方法LLDA和Tag-LDA的效果均未超过Frequency,即可视为完全无效果.这是由于数据的特点导致,患者的病情文档是病人所患疾病的反映,其内容往往只围绕某一种或几种疾病.而传统主题模型假设每篇文档均有较多的主题,此种假设在文本较长、文本内容较丰富的语料库中效果较好,而面对文本较短、文本含义较为集中的医疗文本效果不佳.
2) 基于协同过滤方法的CTR模型效果较差,实验效果被传统机器学习模型ML-KNN和ML-DT所超越.这是由于药品推荐问题中没有“用户”这一概念,每一名患者都需要重新进行诊断,即文献[25]中所述“out-of-matrix prediction”.协同过滤方法在此条件下会面临冷启动问题,从而影响预测的准确率.文献[25]中的实验部分也证实了这一点.
3) 基于深度学习的推荐系统MLP、W&D模型在准确率方面表现较好,效果与MLDA模型十分接近.然而药品推荐问题对于模型的可解释性要求较高,医生与患者往往希望得知某种药品得到推荐的理由.深度学习方法采用的端到端训练模式,难以提供较好的可解释性.相较而言,本文提出的MLDA模型采用主题模型进行建模,在可解释性方面较为优秀,同时能够取得良好的推荐效果,因此更适用于药品推荐领域.
4) 基于深度学习的NTM模型相比MLDA模型效果有一定差距,这是因为其采用了变分推断的求解方式,相对于Gibbs采样在求解精度方面有一定差距.同时,NTM模型无法直接对情境信息进行充分利用,导致其推荐效果有所下降.
5) 从消融实验的对比来看,由于同时考虑了情境对于疾病和药品的影响,MLDA在全部评测指标中均取得了最好的效果.相较而言,在MLDA模型的3类变种中,MLDA-z模型只考虑情境对于疾病的影响,实验结果表明MLDA模型效果优于MLDA-z.同时,MLDA-pure模型不考虑任何情境的影响,其效果低于MLDA和MLDA-z.这充分证明了本文所提出模型对于情境信息利用的有效性.
此外,值得注意的是,增加情境对于疾病的影响带来的收益,其效果要低于增加情境对于药品的影响所带来的收益,即情境对于药品的影响要大于对于疾病的影响.这是由于本文所用数据集的特点所导致.本文所用数据来源于大型三甲医院,此类医院所接诊的病人中有相当一部分患者身患较严重疾病,如严重的外伤、各类肿瘤、传染病等.此类疾病的发病与否受患者情境信息的影响相对较小.相对的,在此类大型医疗机构中,医生会更加注意患者的性别、年龄、医保、手术等情境信息对于患者所使用药品的作用效果.因此,情境信息对于药品的作用效果更加显著.
6) MLDA-c模型相比于MLDA-pure模型增加了对情境信息的利用,但其提升效果不是十分明显,相距MLDA模型差距较大,这是由于情境信息与患者检查检验与医疗文本词相比而言数量较少,若直接将其与病情文档混合作为描述患者的文本特征,则情境信息对于结果的影响力会被大大减弱,从而导致模型难以取得良好的效果.
下面对本文提出的模型进行参数敏感性分析.图5(a)展示了情境主题数量对于模型效果的影响,其中K=400,调节不同的F值大小.图5(b)展示了疾病主题数量对于模型效果的影响.其中F=10,调整不同的K值大小.观察可见,模型在K=400,F=10处取得最好效果,并且模型对于参数变化展示出了良好的鲁棒性,参数在较大范围内变化时,模型效果仅在0.01量级的范围内波动,这证实了本文提出方法的良好性能.
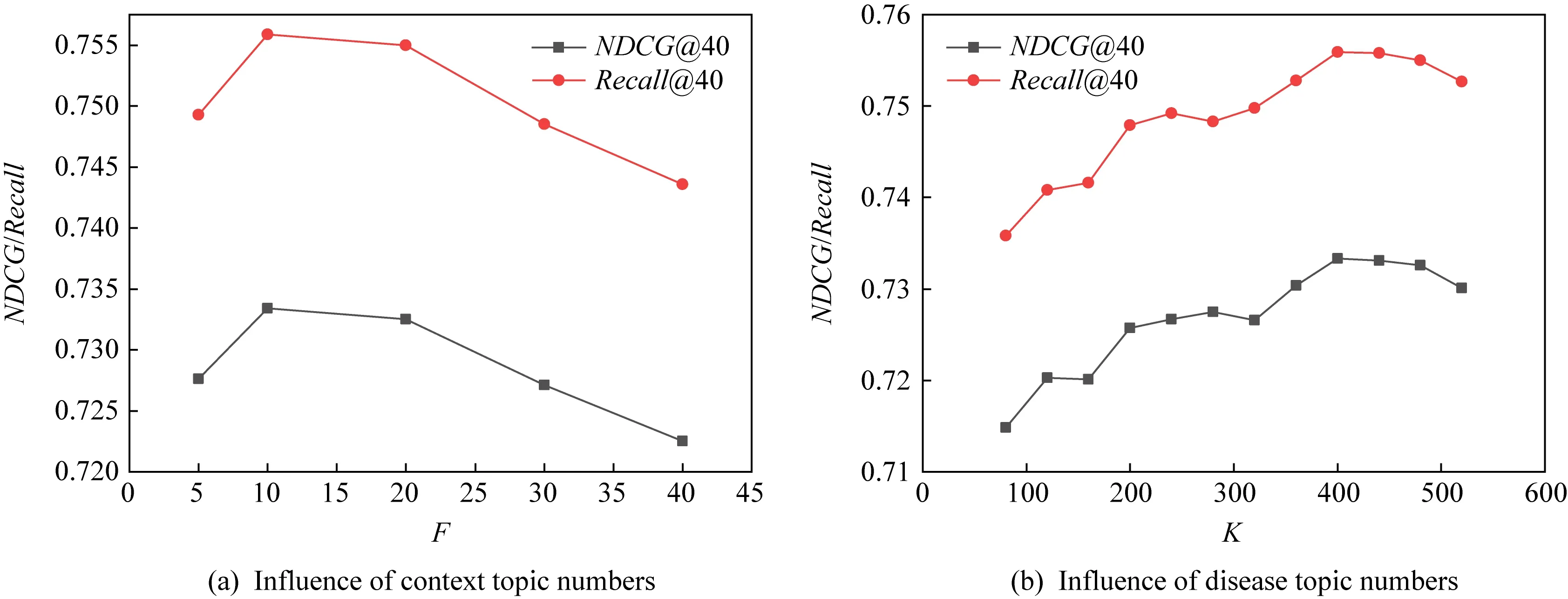
Fig. 5 Influence of context topic numbers and disease topic numbers to results图5 情境主题与疾病主题数量对于模型效果的影响
为了进一步研究所提出方法的优越性,我们对模型挖掘所得内容进行分析.具体而言,在本文所提出的模型中,疾病主题表示了一种或一类疾病,而情境主题则表示一类患者,同时疾病主题对应的文档词分布表示了某种疾病对应的化验异常与症状.理想的模型可以较为准确的挖掘得到此类信息,从而为模型的推荐结果提供有力的支持,提高模型的可解释性.
表4给出了部分疾病主题的挖掘结果,其中高频词语部分展示了该疾病主题对应的词分布中频率由高到低排列的前几个词语,并通过对高频词语的观察给出了主题对应的含义.通过对高频词语的观察与分析,可以发现模型挖掘得到的疾病主题具有明显的医学含义,且化验结果和医疗文本均对疾病主题的推断起到了重要的作用.

Table 4 Results of Disease Topic Mining表4 疾病主题挖掘结果
下面分析不同情境对于疾病和药品的影响程度.定义情境主题c对于疾病的影响度Sc,z:
(20)
其中,vc,z代表情境主题c对应的疾病主题分布向量,dis代表2个向量的欧氏距离.疾病影响度反映了不同情境主题对应的易患疾病相对于平均人群的偏差度,疾病影响度越大,代表该情境主题对于患者易患疾病的影响越大.定义情境主题c对于药品的影响度Sc,f:
(21)
其中,vc,k代表情境主题c与疾病主题k对应的药品分布向量,dis代表2个向量的欧氏距离.药品影响度反映了相同疾病下情境信息对于药品分布的影响.药品影响度越大,代表该情境主题对于患者的药品使用的影响越大.
疾病影响度最大的2个情境主题如表5所示.可以发现,天气、气温、季节等因素是影响患者易患疾病的主要因素,年龄的不同也起到了一定的影响作用.药品影响度最大的2个情境主题如表6所示.可以发现,性别、年龄、保险情况、是否手术与麻醉等因素是影响医生对于患者药品使用的主要因素.以上结果有力地证实了本文在4.3节中提出的假设.

Table 5 Two Context Topics With the Greatest Disease Impact表5 疾病影响度最大的2个情境主题
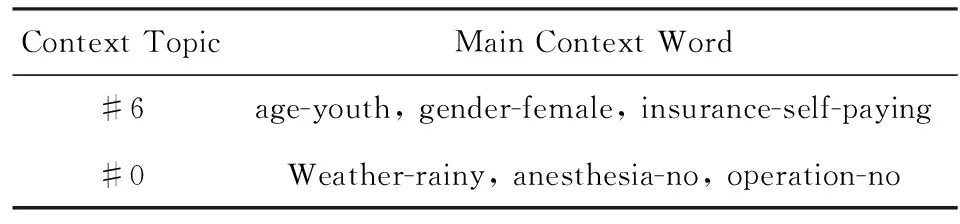
Table 6 Two Context Topics With the Greatest Medicine Impact表6 药品影响度最大的2个情境主题
最后对某一情境主题对于药品分布的影响进行具体分析.定义药品d在情境主题c下的提升度Ic,d:
Ic,d=rankall,d-rankc,d.
(22)
其中,rankall,d代表药品d在全部数据中的出现频率排名,rankc,d代表药品d在情境主题c对应的数据中出现频率的排名.在此,以情境主题#9为例进行展示,表7给出了情境主题#9的主要情境词,表8给出了情境主题#9对应的提升度最大的几种药品.可以看到,情境主题#9代表的人群主要为进行了手术的患者,并且进行了全身麻醉,代表患者可能身患重病.表8给出了情境主题#9对应的提升度最大的几种药品及其功效,可见各类治疗肿瘤、缓解化疗副作用、消炎药物等提升幅度最大,这与情境主题#9代表的重病类患者的含义一致.

Table 7 Main Context Word of Context Topic#9表7 情境主题#9的主要情境词
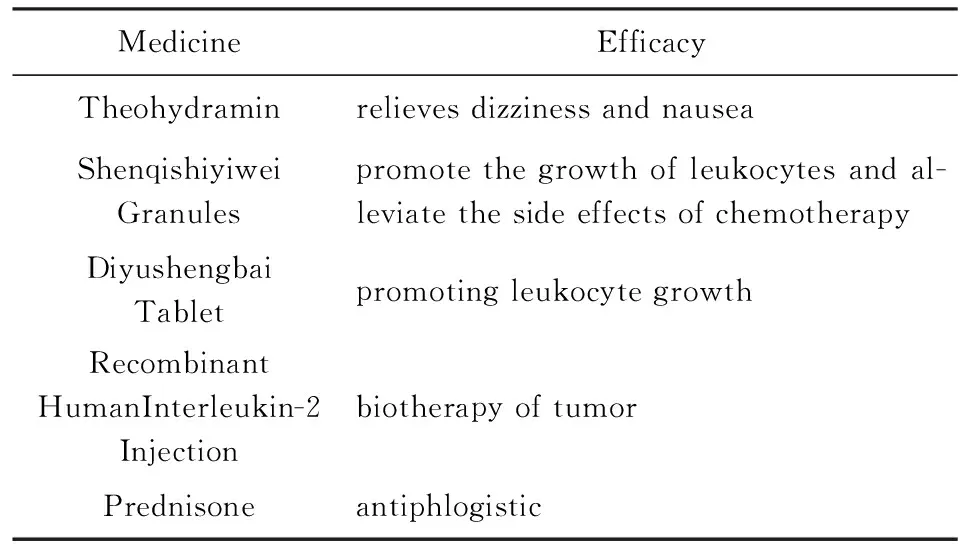
Table 8 Medicines With the Greatest Promotion Degree and Their Efficacy表8 提升度最大的5种药品及其功效
以上案例分析的内容充分证明了本文提出的模型不仅能够给出准确的推荐结果,还能够从数据中挖掘得到大量有意义的信息和规律,证实了模型的实际应用价值和指导意义.
5 总结与展望
本文提出了一种基于情境感知的药品推荐模型Medicine-LDA,模型使用一个通用的概率框架来描述真实生活场景中的诊疗过程,具有良好的可解释性.该模型依据患者的化验异常与医疗文本组成的患者文档来推断患者可能患有的疾病,并提出使用疾病主题来描述患者患有不同疾病的概率.同时,该模型考虑到药品推荐的结果会受到情境信息的影响且作用方式不同,进行了有针对性的建模.另外,对于多源情境信息导致组合爆炸的问题.本文提出使用LDA模型对情境信息进行建模得到患者的情境主题,并将情境主题融入本文提出的概率模型当中,从而有效地对情境信息的作用进行建模.最后,通过在一个来自某大型三甲医院的数据集上的实验,表明本文提出的模型在准确性上的表现优于常用的传统机器学习模型、主题模型以及协同过滤模型,同时,针对模型学习所得结果进行分析可以得到一系列有价值的信息,证实了模型的良好性能与其在实际应用中的价值.
本文所提出的方法也有其局限性.由于采用了主题模型,当某些疾病的症状较为相似,且从情境信息难以得到区分时,可能会导致2种疾病的混淆.为此,未来我们将对基准方法中的NTM模型进行进一步的研究,寻找更佳的情境融合与文本建模方法,从而将主题模型的可解释性与深度学习对于特征的学习能力进行结合,进一步增强模型对于此类问题的处理能力.
