国内外古脊椎动物数据库综述
2020-08-24潘照晖
潘照晖 ,朱 敏
1. 中国科学院 古脊椎动物与古人类研究所,中国科学院 脊椎动物演化与人类起源重点实验室,北京 100044;2. 中国科学院 生物演化与环境卓越创新中心,北京 100044;3. 现代古生物学和地层学国家重点实验室(中国科学院 南京地质古生物研究所),南京 210008;4. 中国科学院大学,北京 100049
1 引言
随着地学数据的快速积累和分析方法的不断发展,大数据在地学领域正迎来革命性的创新(Guo,2017; Fan et al.,2020)。借助计算机技术的进步,我们已经能够轻松存储和处理大量的数据,使得原本以实验归纳为基础的实验范式、以分析推演为基础的理论范式和以模拟仿真为基础的仿真范式向数据密集型科学发现(Data-intensive scientific discovery)转变,产生了第四种科研范式(Hey et al., 2009)。新的科研范式需要先汇集、整理大量的已知数据,然后通过计算分析得出之前未知的可信结论。传统地质学正在向地球系统科学转变。与此同时,在保育生物学领域,研究人员也越来越多地关注地质历史资料的积累和综合分析。将生物多样性问题放进地质历史的框架中分析,能够以更广阔的视野认识生物与环境的协同演变规律,由此在最近二十年形成了保育生物学与古生物学的交叉新学科:保育古生物学(Conservation Paleobiology;Dietl and Flessa,2009; Dietl et al., 2011; Dietl et al., 2015; Dietl, 2016;Barnosky et al., 2017)。
保育古生物学通过对地质历史数据的分析,为生物多样性的保护、恢复以及生态系统服务提供依据,避免因气候变化或人类活动造成物种过快灭绝和生态系统崩溃。其数据主要来源于地质历史资料,包括但不限于生物遗存、古环境和古地理记录。保育古生物学能够获取超出人类所能观察到的时间框架外关于物种、群落和生态系统的演化规律(Sayer et al., 2012; Rick and Lockwood,2013; Gillson and Marchant, 2014)。2005年 美 国国家研究理事会生物圈动力学地质记录委员会(Committee on the Geological Record of Biosphere Dynamics, U.S. National Research Council) 提 出,地质历史数据在当今生物多样性问题上具有极其重要的作用。此后,保育生物学相关的研究越来越重视地质历史资料,研究人员开始留意搜集各类相关的地质历史数据。此时,古脊椎动物领域也不断涌现出许多高质量数据库,但相较于古脊椎动物的研究历史来说,仍然有大量散落在各类文献和科学家手中未发表的珍贵数据并未被搜集整理,甚至许多发表在经典古脊椎动物学杂志如Journal of Vertebrate Paleontology等刊物的定量研究,其原始数据也尚未开放供读者使用。古脊椎动物数据通常是直接由文章作者保存,因此获取方式也通常是直接向作者们索取,一旦作者离开原工作岗位,其所在单位普遍缺乏机制来保存、归档研究者们的数据(Uhen et al., 2013)。古脊椎动物领域除已建设的各类专门数据库外,仍需建立有效措施系统地整合、汇聚散落在各处的相关数据。本文将介绍目前互联网上可访问、易获取的古脊椎动物领域数据库,及它们在保育古生物学中的应用实例,为“深时数字地球”(Deep-time Digital Earth, DDE)国际大科学计划提供参考,希望能够为该计划未来整合全球已有的古脊椎动物相关数据,建成地球科学领域知识图谱提供帮助。
2 已有古脊椎动物相关在线数据库概况及古脊椎动物研究实例
Phillips(1860)根据 Morris(1854)的英国化石数据绘制出第一条地质历史的多样性曲线。此后,陆续出现了很多具有系统编目性质的脊椎动物化石记录和脊椎动物化石名录资料,例如The Bibliography of Fossil Vertebrates(Hay, 1902)、The Fossil Record(Harland, 1967; Benton, 1993)、Handbuch der Paläoherpetologie(Steel, 1973)、Handbook of Paleoichthyology(Denison, 1978)和《中国古脊椎动物志》(朱敏, 2015)等。此外,古脊椎动物领域有许多研究使用了大量的数据,虽然其研究的支撑数据可在线获取,但在本文中我们仅称这种数据为数据集,以有别于长期、有组织的存储于在线服务器中、提供较为系统的数据共享和服务的专门数据库。The Fossil Record最初定位于生命史的研究(Benton, 1999),随后的三十年间其数据集不断被扩展,但依旧停留在数据集范畴。直到Sepkoski全球显生宙海洋动物科级化石多样性数据集(Sepkoski, 1983)发展成全球显生宙海洋动物属级化石多样性在线数据库(Sepkoski,2002)之后,真正意义上的古生物数据库才出现。
古脊椎动物数据库可以分为两类,一类是收藏管理型数据库,另一类是研究型数据库(Uhen et al., 2013)。收藏管理型数据库如中国科学院古脊椎动物与古人类研究所标本馆或中国地质博物馆数据库中的古脊椎动物部分,其架构主要为满足机构自身馆藏化石标本的编目、查询和借阅。出于安全或性能方面的考虑,此类数据库多数不对外提供服务或仅提供有限的记录查询服务,且数据库间并不互通,使得科研人员和其他用户获取数据存在障碍。加之收藏管理型数据库由非科研人员主导,设计字段简单,无法满足科研需求。为了克服以上缺陷,美国国家科学基金会的生物多样性藏品高级数字化项目(https://www.idigbio.org/content/nsf-adbc-program-information)应运而生。该项目以iDigBio(Integrated Digitized Biocollections)为主体,借助专题收集网络(Thematic Collections Networks,TCN),联合全美众多博物馆、标本馆等机构共同打造。该项目协助各成员机构在统一标准下构建各自的收藏管理型数据库,由iDigBio作为搜索门户统一对外提供服务,以保障用户便捷高效地获取全美科学藏品的数据。由于有领域科学家深度参与,该项目下的化石数据不仅包含标本图片,还包含相关的地理位置、古地理学、地层学等扩展信息。iDigBio虽然是对收藏管理型数据库的扩展,但由于缺乏科学问题导向,使得iDigBio对于公众科普的贡献明显大于科学研究。
收藏管理型数据库对科学研究的主要贡献之一是提供标本材料的观察对比,这一点对模式标本而言尤为珍贵。由爱沙尼亚自然历史博物馆和塔尔图大学自然历史博物馆联合建设的Fossiilid化石数据库(https://fossiilid.info),提供了大量发表在久远文献中的标本高清照片,显然该团队对这些珍贵标本进行了重新数字化的工作,从而使得这些老数据的价值被进一步提升。比如,在早期发表的文献中,图版多存在缺失或图像模糊的情况,不利于后续研究人员进行对比研究,Fossiilid的数字化工作弥补了这一缺陷。笔者进行早期脊椎动物的形态学研究时,从中获益良多。这些收藏管理型数据库不仅为比较解剖学的基础研究和生物多样性的探索研究提供了保障,而且对其馆藏化石标本的时空分布分析所揭示的空白地层时段或空白地理区域,可以有效地指导下一步的研究和发掘方向,对于古脊椎动物研究而言具有重要的价值。然而,由于收藏管理型数据库可能包含大量未经系统研究甚至尚未研究的标本材料,因此其数据质量可能会存在一定缺陷。
研究型数据库完全由领域科学家主导,瞄准一个或多个特定的科学问题,在数据库设计和搜集数据时有清晰的目的。与收藏管理型数据库不同(表1),研究型数据库中的数据均来源于已正式发表的科研论文,经过同行评审具有很高的质量,是本文主要介绍的类型。
2.1 国家岩矿化石标本资源共享平台
国家岩矿化石标本资源共享平台(http://www.nimrf.cugb.edu.cn/)属于典型的收藏管理型数据库。该平台在科技部经费的支持下,由中国地质大学(北京)联合中国地质博物馆、中国科学院古脊椎动物与古人类研究所、中国科学院南京地质古生物研究所、中国地质科学院矿产资源研究所、中国地质大学(武汉)和吉林大学等单位于2003年创建,主要提供岩矿化石标本数据的收集、存储、标准化、检索查询和数据发布等服务,最终目标是建成国家级的地学领域岩矿化石数据中心。该平台中目前已收录岩矿化石标本资源12.6万件。其中古脊椎动物标本16443件、古人类及古人类遗物标本8046件,占总收藏记录的19.4%。平台中目前已整合具有重要科学价值的模式化石及典型化石群标本6.2万件,古脊椎动物与古人类化石标本主要包括我国境内的古人类与旧石器标本、云南澄江动物群的典型标本、辽西热河生物群的典型标本、贵州海生爬行类标本和黑龙江嘉荫晚白垩世恐龙标本等。

表1 收藏管理型数据库与研究型数据库的比较Table 1 Comparison of the collection databases and the scientific databases

图1 国家自然科技资源平台岩矿化石标本资源共性描述表截图Fig. 1 Screen short of the table of general descriptive information in the National Infrastructure of Mineral Rock and Fossil Resources for Science and Technology
该平台的创新亮点在于,为了整合全国岩矿化石标本资源,规范岩矿化石资源的搜集、保存和鉴定,制定了国家自然资源平台岩矿化石标本资源的共性描述规范,籍此统一标本的共性信息和描述项目。在共性描述规范(图1)中,包含了护照信息、标记信息、基本特征特性描述信息、其他描述信息、收藏单位信息和共享方式,通过这些内容,用户可以实现对标本信息的快速概览。
2.2 VertNet收藏管理型数据库
VertNet(Distributed Databases with backbone;http://www.vertnet.org/index.html)旨在汇集互联网各处的脊椎动物收藏管理型数据库的数据,使得脊椎动物数据可以在线自由获取。目前已有32个国家,约200余个馆藏单位将数据链接至VertNet的门户网站。项目主要人员来自加利福尼亚大学、科罗拉多大学、堪萨斯大学、杜兰大学及部分博物馆,他们曾建设了四个经典的脊椎动物数据库,分别是FishNet(http://fishnet2.net/aboutFishNet.html)、ManisNet(http://www.manisnet.org/)、HerpNet(http://herpnet.org/)和 ORNIS(http://www.ornisnet.org/),这四个数据库是构建VertNet项目的基石。其中,FishNet致力于汇集全球所有鱼类标本信息,ManisNet致力于汇集哺乳动物分布信息,HerpNet致力于汇集两栖爬行类动物信息,ORNIS则致力于汇集北美馆藏的鸟类标本信息。自1999年开始,这四个数据库开始在该项目的统一框架下开放了各自数据库的访问权限。随后,在 2014年 5月,ManisNet、HerpNet和 ORNIS先后停止维护,后续服务在VertNet平台中延续。
VertNet构建的核心目标是为了打破原有四个数据库间的数据互联互通障碍,并解决技术和管理层面水平参差不齐的问题,秉承建立一个可持续、可扩展的云端数据平台的理念,不仅提供数据的有效存储,也提供多种工具和数据接口,使得生物多样性数据对用户来说易获取、易发表和易使用。VertNet的运行方式如图2所示,其中古脊椎动物数据是在VertNet建立后才开始汇集。
VertNet对学术界有三个核心价值:(1)VertNet针对脊椎动物生物多样性监测和评估的高质量数据需求,提供了一个综合的、全球共享的、稳定的数据平台。(2)VertNet展示了一种新的基于云计算平台的数据发布模式,即通过一款由Java编写的开源软件IPT(Integrated Publishing Toolkit)托管和发布用户数据,也可协助用户通过IPT维护相对独立的数据库网站。选择VertNet托管数据的用户无需自己运行和维护在线服务器,依然可以享有对自己数据的所有控制。这一先进的建设理念可以明显推动脊椎动物资料的数字化和长期可持续增长。(3)VertNet有可能改变生物多样性科学的研究范式。研究人员可使用VertNet社区开发的rvertnet开源分析工具或通过API直接调用数据库中的数据进行物种分布、全球生物多样性格局以及生物多样性随时间变化的建模研究等,实现数据驱动下的科学研究范式变革。
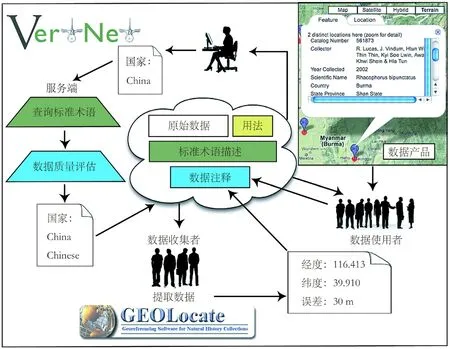
图2 VertNet的运行方式(引自Constable et al., 2010)Fig. 2 Work flow of the VertNet database (Constable et al., 2010)
2.3 GBIF生物多样性信息服务系统
2013年9月13日,VertNet签署“谅解备忘录”(Memorandum of Understanding),正式加入全球生物多样性信息网络(GBIF; https://www.gbif.org/),并在GBIF理事会获得一个席位。GBIF是目前全球最大的生物多样性信息服务机构,在生物多样性信息学领域占有重要地位。该组织通过合作和提供种子基金等方式促进生物多样性的原始数据在世界范围内的开放共享,最终目标是整合世界上已有的生物多样性数据库和收藏管理型数据库,形成一个开放的全球生物多样性综合信息服务系统。与VertNet类似,GBIF通过开发生物多样性数据库网络和相关工具,协助博物馆、标本馆等生物多样性数据的拥有者在GBIF的框架下构建自己独立的门户网站。GBIF则通过提供全球生物多样性元数据注册节点的方式,基于注册节点的内容,构建了中心的门户网站,为用户提供并发的内容索引。
维护和搜索大量分布式数据的难点在于基础数据的规范统一,因此达尔文核心(Darwin Core)元数据规范被广泛用于GBIF网络中。Darwin Core形成的基础是任何自然历史采集和观察数据的信息都具有共同的属性,例如名称、分布地点、采集时间等,这些也是数据库中最基础的信息。Darwin Core提供了一个关于数据概念的描述规范,方便对原始数据检索和集成,是描述自然历史标本和观察数据的最小集合(纪力强等,2005)。Darwin Core目前由生物多样性信息标准(TDWG,Biodiversity Information Standards)维护和管理,多年来为应对数据对象的范围扩大而不断扩充,例如,针对研究生物演化的古生物学信息时,就需要在Darwin Core标准标识符的基础上添加新的标识来描述和管理这些古生物学相关的信息,从而形成Darwin Core的扩展元数据规范(Extension)。目前针对古生物化石和地质学的相关需求,分别设计了古生物学扩展(Paleontology Extension)和地质学环境(Geological Context)。
GBIF数据主要由现生生物数据组成,其中古生物数据记录约600万条,仅占总量的0.43%。古生物数据主要来自PBDB数据库、佛罗里达大学古脊椎动物数据库、堪萨斯大学古无脊椎动物数据库等10个专业数据库(图3)。其中古脊椎动物数据1770053条,占古生物数据总量的29.5%。目前并没有基于GBIF直接开展的古脊椎动物研究,所有相关研究工作均依托其成员数据库如PBDB等专业数据库进行,GBIF更多的是提供了一个在研究初期的综合检索功能。
2.4 NEOMAP新生代古哺乳动物数据门户网站
NEOMAP(Neogene Mammal Mapping Portal;https://ucmp.berkeley.edu/neomap/)致力于建立一个分布式数据库系统,链接互联网上已有的新生代古哺乳动物数据库,为它们提供统一的查询和访问入口。目前已链接的两个数据库为FAUNMAP(A Neotoma Constituent Database)和 MioMap(Miocene Mammal Mapping Project),这两个数据库的数据分别来自已发表的美国渐新世至全新世和加拿大第四纪的哺乳动物化石记录,下文将分别介绍。NEOMAP的科学目标是通过物种与其分布范围的时空演化关系研究,获取人类活动对地球生态系统变化的影响。

图3 GBIF中古生物数据的分布情况Fig. 3 Distribution of paleontological data in GBIF
2.5 FAUNMAP古哺乳动物研究型数据库
FAUNMAP(https://ucmp.berkeley.edu/faunmap/index.html)最初由两个时间互补的独立数据库组成:(1)FAUNMAP I数据库,数据的时间跨度为4万年前至500年前;(2)FAUNMAP II,数据的时间跨度为500万年前至4万年前。目前这两者已经合并为一个数据库,具有统一的查询和访问入口。FAUNMAP的数据结构如图4所示,包括地理位置、地质年代、化石产地、沉积环境和人类文化背景等。大多数全新世化石数据来自于考古学发掘,而全新世之前的化石数据则来自于古生物学发现。
FAUNMAP设计的时候并没有考虑科研人员向数据库贡献数据这一方式,而是选择了由专人将已发表的文献中的数据录入到数据库中,因此数据库中没有为用户开发在线的数据录入功能。但在使用方面,FAUNMAP数据库完全开放,允许任何人自由访问和下载数据。FAUNMAP初期基于Paradox数据库开发,后转换为Microsoft Access数据库,最终升级为开源的MySQL数据库。目前,FAUNMAP虽然仍保留独立的门户网站,但数据已迁移至一个新的数据库——Neotoma古生态数据库。后者的开发队伍更强,具有更好的用户体验,后文将做详细介绍。
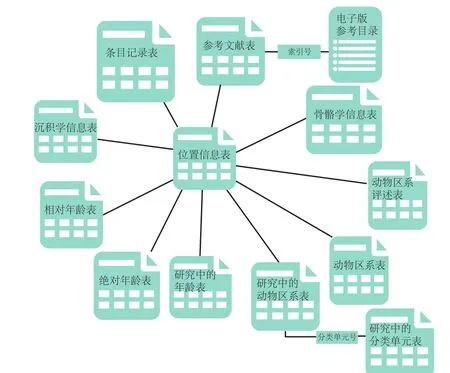
图4 FAUNMAP数据库的结构Fig. 4 Schematic design of the FAUNMAP database
FAUNMAP数据库面向的主要科学问题是上新世到全新世大约500万年间哺乳动物群落组成的变化,可进一步细分为三大科学问题:(1)哺乳动物群落是否和环境变化有紧密联系?物种组合是与环境协同演化,还是物种根据其自身的耐受性对环境变化做出独立响应?(2)哺乳动物区系是如何分布的?(3)相对于地质历史时期来说,目前环境变化情况如何?Burns 等(2003)讨论美国8个主要的国家公园中哺乳动物在全球环境变化背景下的迁徙情况时,选取FAUNMAP中81个种和8个国家公园中132个现居种的分布情况,借助ESRI公司开发的ArcGIS软件,模拟了在两倍碳排放情景下哺乳动物的迁徙趋势,模拟分析表明,南方物种将向北方迁移,南方物种将损失约8%。这项研究认为,固定不变的保护区的功能可能被气候变化削弱,政府应根据哺乳动物的适宜栖息地来动态调整保护区范围。Denniston 等(1999)在研究美国中西部全新世草本植物和环境的变化关系中,除利用石笋和花粉序列等常规环境指标外,也选取了FUNMAP中所有能够鉴定到种级的脊椎动物类群及长耳野兔、囊鼠、地松鼠等的生境作为一项重要的古环境指标。
2.6 MioMap哺乳动物研究型数据库
MioMap(https://ucmp.berkeley.edu/miomap/)开始于2000年,至2005年结束,共汇集了当时已发表的美国晚渐新世到中新世的15000余个哺乳动物化石的产地数据,包含了化石属种信息、经纬度、地质时间范围、地质学信息和埋藏学信息等。其数据结构如图5所示,所有信息均由正式文献佐证。

图5 MioMap数据库的结构Fig. 5 Schematic design of the MioMap database
该数据库关注约3000万年前到500万年前,环境的剧烈变化是如何影响哺乳动物的物种丰度、演化模式和生物地理模式。其科学问题可具体分为三点:(1)阐明环境变化是生物演化的一种驱动力。例如,Barnosky(2001)利用MioMap数据验证,在百年、千年时间尺度上,气候变化对物种丰富度和生物群落组产生了明显的影响。(2)检验生物栖息地碎片化与生物群落更替间的相互关系,以认识全球变化的影响。例如,Barnosky 等(2005)的古生物物种与区域大小的关系研究揭示了物种-面积效应(species-area effect)对古生物物种多样性的重要影响。(3)在更大尺度上分析,什么样的环境变化会引起哺乳动物类群的巨大 化(Carrasco et al., 2000; Barnosky and Carrasco,2002)?基于这些特点,该数据库被广泛用于保护古生物学领域的生物多样性基线研究。
MioMap和FAUNMAP除提供特定字段(如产地、属种等)的文本查询检索外,也允许用户下载全部数据集,并对元数据有清晰的注解,方便用户再次加工使用。更值得重视的一点是,MioMap和FAUNMAP提供一种全新的图形化检索方式——Berkeley mapper(http://berkeleymapper.berkeley.edu/)。Berkeley mapper除了地图的基本功能外,还提供了点选和直接绘制多边形的查询操作,通过标志点的数字、大小和颜色反映标志点及邻近区域的记录数量(图6),等等。
Berkeley mapper(https://github.com/BNHM/berkeleymapper)是基于Google Maps开发的一个开源软件,其目的是满足馆藏标本的地理信息可视化需求。用户可通过简单的XML(Extensible Markup Language)配置文件将数据绘制到谷歌地图上。Berkeley mapper对于数据文件的支持比较友好,Microsoft Excel或其他软件导出的由制表符分隔的文本数据均可直接导入该软件中。大数据时代,大量此类免费资源的存在显著降低了新建数据库的开发门槛和成本。新建数据库者无需重复“造轮子”,通过学习和使用此类成熟工具,可以节省大量时间和资源,将之投入到科学问题为导向的设计与思考中。同时,感兴趣的开发者也可以参与维护此类开源软件,帮助提高代码质量和程序功能。

图6 Berkeley mapper交互界面(界面下方显示检索结果的列表,上方显示结果的空间可视化)Fig. 6 The interface of the Berkeley mapper(The lower part of the interface shows the query results and the upper part shows the geographic distribution of the data)
2.7 Neotoma古生物与古环境研究型数据库
Neotoma(https://www.neotomadb.org/)是为古环境研究而建立,并吸收了其他相关数据库而形成的,例如北美孢粉数据库、植物大化石数据库和上文提到的FAUNMAP古哺乳动物数据库。其数据的时间范围涵盖上新世、更新世和全新世。Neotoma数据库不仅仅是简单的汇总数据,也对原有数据进行了一定的加工,使其符合统一的数据标准,更容易被用于综合性研究。同时,Neotoma提供了多种工具如程序接口(API)和开发者工具(SDK),方便用户直接调用数据而无需下载所有数据。虽然FAUNMAP是Neotoma数据库内古脊椎动物的数据基础,但Neotoma中的古脊椎动物数据并不局限于哺乳动物,还涉及鱼类、两栖类、爬行类和鸟类等。此外,Neotoma还包含了与脊椎动物化石相关的其他不同类型数据,如同位素数据与埋藏学数据等。
为了提高数据的易用性,Neotoma团队借助Dojo框架、OpenLayers库和Google Map开发者工具专门开发了基于浏览器的交互程序——Neotoma Explorer(图7)。通过该程序,用户不仅可以进行可视化的数据查询处理,还可以通过数据的地质时间、地理分布、数据来源等条件进行组合检索。Neotoma Explorer除支持用户检索Neotoma的数据并对检索结果投点成图外,也允许用户上传自己的数据集绘制多个不同的图层。虽然该程序基于开源软件编写,但软件并未开源,仅限Neotoma平台使用。
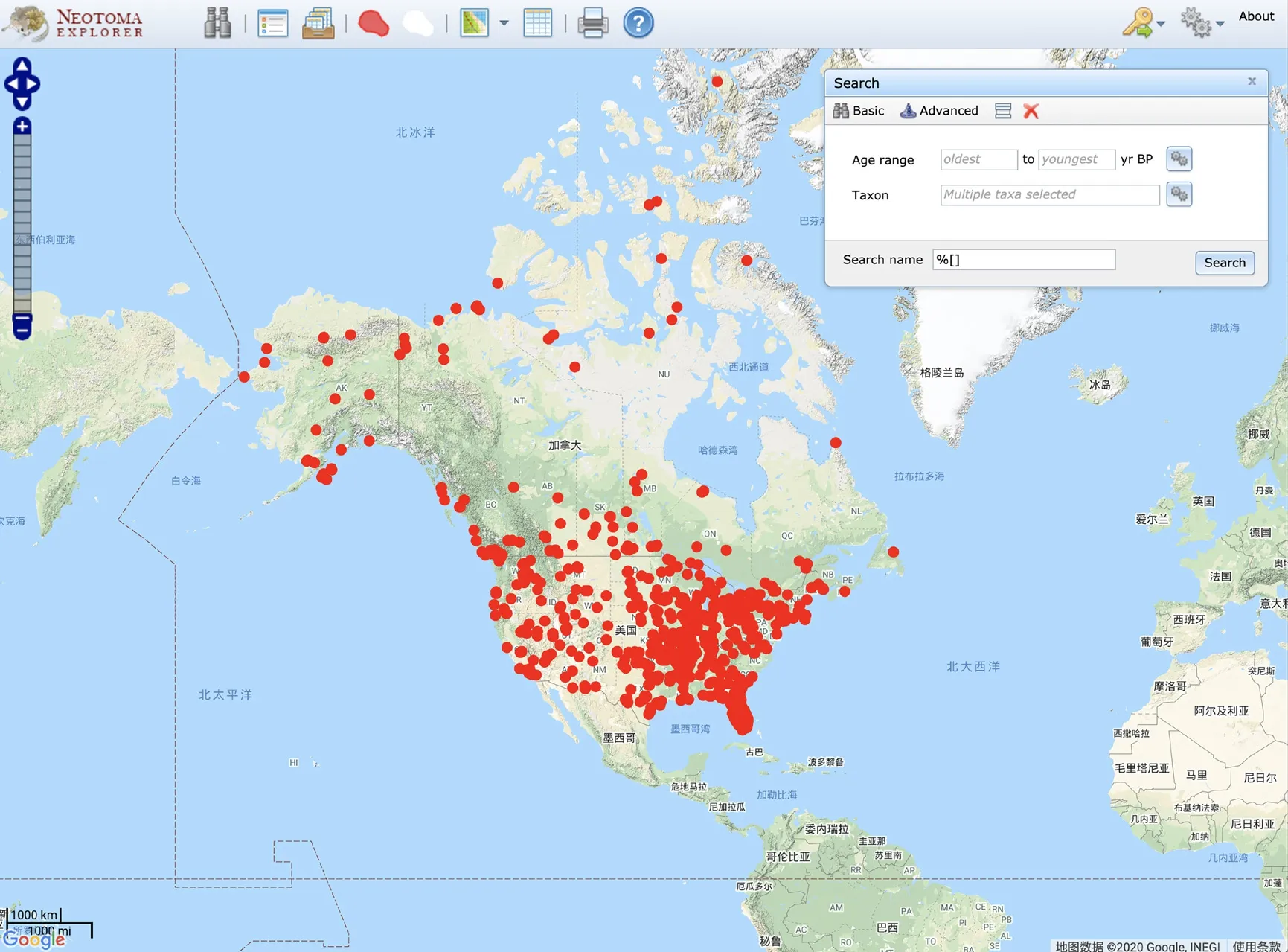
图7 Neotoma Explorer交互界面Fig. 7 The interface of the Neotoma Explorer

图8 计算机模拟的情景8:人类和被捕食物种的种群大小变化Fig. 8 Population dynamics of human and prey species in trial 8 of the computer simulation
利用古脊椎动物数据研究地质历史时期生物大灭绝是大数据分析在脊椎动物领域和保育古生物学领域中的经典应用。Alroy(2001)使用Neotoma数据库中14000年前更新世末期以来北美大型食草脊椎动物的数据,用计算机建模模拟人口增长、狩猎能力和41种大型食草动物的种群大小变化。模型中的第8个情景(trial 8,图8)所预测的物种灭绝情况与实际情况较吻合,该情景包含被捕猎物种种群的快速地理扩散、被捕猎物种间的充分竞争和有限的人类捕猎能力等相关条件,模拟结果显示78%的物种灭绝。该情景模拟的结果与实际情况的不同在于,有6个模型中存活的物种实际已经灭绝,有3个模型中灭绝的物种实际仍然存活。该研究并未考虑气候变化因素和次级生态学影响,因此提出人类过度捕杀才是造成更新世以来大型脊椎动物集群灭绝的主因。
2.8 NOW古哺乳动物研究型数据库
NOW(New and Old Worlds: Database of Fossil Mammals; http://www.helsinki.fi/science/now/)由芬兰赫尔辛基大学的学者领导的一个国际合作团队建立并维护。该团队成员均为专业的古生物工作者,在地理学、地层学、埋藏学、古生态学和分类学等方面有深厚的积累。由于NOW数据库早期是克隆“陆地生态系统演化”数据库(ETE, Evolution of Terrestrial Ecosystems)而来,所以其中的属种和化石产地的数据字段仍遵循ETE数据库的早期定义,后来才加入一些新的数据字段以适应扩展需求。NOW数据库中的数据涵盖了新生代陆地哺乳动物及化石产地,重点关注欧洲中新世到上新世、北美新生代的数据。其数据主要来源于已正式发表的文献和部分成员尚未发表的数据。
除物种起源与灭绝研究外,古脊椎动物大数据研究的另一个热点是脊椎动物的宏演化。Evans等(2012)估算了NOW数据库中7000万年以来非洲大陆、欧亚大陆、美洲大陆以及海洋沉积中共28个目的哺乳动物的最大体重,研究哺乳动物最大体重变化与其演化世代间的关系。研究表明,陆地哺乳动物体重增加1000倍大约需要经历500万代,水生哺乳动物(如鲸鱼)则需要300万代;个体变小的演化比个体变大的演化要快得多,体型变化相同的倍数,前者要快10倍以上(图9)。
上述古哺乳动物数据库由于科学问题不同,所以在字段设计上差异明显,其余主要异同的简明对比见表2。
2.9 AHOB英国古人类研究型数据库
英国古人类数据库(Ancient Human Occupation of Britain, AHOB; http://www.ahobproject.org/)是由利华休姆基金会(Leverhulme Trust)2001至2013年支持的一个科研项目。该项目分三期,汇集欧洲北部旧石器时代到中石器时代古人类的数据。AHOB数据库的目标是研究英国和北欧最早人类出现时的地理、气候和环境背景。Polly 和 Eronen(2011)曾利用该数据库中哺乳动物区系数据估算古温度曲线,从而寻找第四纪英国的哺乳动物区系与气候间的关系。该数据库中的数据主要来源于项目研究过程中产生的数据和已发表的文献,包含了321个古人类遗址点相关的456篇已发表文献的数据,含140幅图片、299种石器技术、146组放射性同位素数据、133组稳定同位素数据,以及相关的地层层位、哺乳动物组成、地球化学和测年等信息(Polly and Stringer, 2011)。该数据库虽计划在2013年项目结束后转为开放获取,但至今该数据库仍有权限限制,只允许项目成员登录后获取。

图9 陆地哺乳动物(黑虚线)与各哺乳动物目(彩线)的最大体重随时间的变化Fig. 9 Maximum mammalian body mass over time for terrestrial mammals (dashed black line) and separate mammal orders (colored lines)

表2 古哺乳动物数据库的比较Table 2 Comparison of the databases on paleomammals
2.10 Morphbank生物图像研究型数据库
Morphbank(https://www.morphbank.net/)是一个生物图像存储网站,由瑞典、西班牙和美国的昆虫学家小组于1998年创立于佛罗里达州立大学,其中不仅包含了现生生物图片,也包含古生物图片及相关信息。该项目设立之初是为了基于形态数据进行系统发育研究,之后才根据需要开发了Morphbank数据库。Morphbank以图片为单位,存储与该图片相关的描述、标本记录、产地、属种名称和评注等。针对古生物图片,Morphbank还存储图片相关的岩石地层和年代地层数据。对于数据贡献者的版权保护,Morphbank除在存储数据时会提供自己独特的数字标识外,也允许数据贡献者在图片上插入项目或机构标识水印以标示版权。Morphbank有两个主要的数据来源:(1)研究者在研究过程中产生的数据,如分类数据、系统发育数据和比较解剖学数据等;(2)馆藏机构对其馆藏标本进行数字化时产生的数据。Morphbank对于用户有一套专门的管理系统,虽然开放注册,但用户权限需要经过网站工作人员审核后激活。用户可以自由创建组,每个组内成员仅可以录入和编辑自己组内的数据,发布必须经过数据库委员会审核。Prieto-Marquez 等(2007)对鸭嘴龙材料的研究,首次丰富了Morphbank内古脊椎动物数据。此后,Prieto-Marquez博士进一步搜集了全球博物馆中可获取的禽龙类材料信息,其数据几乎涵盖当时所有已知的禽龙类标本,共有约1700张图片及相关数据被收录进Morphbank数据库。
2.11 MorphoBank形态学研究型数据库
MorphoBank(https://morphobank.org/)是 经过 同行评审的形态学矩阵数据库和生物形态学多媒体文件存储库。相对于上文提到的Morphbank,MorphoBank虽启动较晚,但却可能在未来产生更大的影响力。MorphoBank不仅仅定位为数据库,也试图成为未来系统发育学研究的云平台,其终极目标是通过表型数据构建生命之树(O’Leary and Kaufman, 2011)。传统的形态学特征矩阵中仅包含特征编码和特征描述,对于特征的编码完全依赖于文字描述,涉及有争议的特征缺少多媒体文件佐证。如果能够将多媒体文件引入特征矩阵中将大大减少对于特征编码的争议,这一设想在过去二十年间被反复讨论(Nixon et al., 2001)。MorphoBank通过独有的MorphoBank matrix editor这一在线系统发育矩阵编辑程序首次将该设想实现(图10),用户除了拥有桌面版演化生物学编码软件Mesquite的全部功能外,还可以上传图片与矩阵中的单元相关联,用以辅助解释特征定义或佐证特征编码。特别是对于同源特征的处理,MorphoBank鼓励用带有注释的图片来对比解释,这种方式相对文字描述更加清晰有效。特征矩阵以项目为单位存于云端,项目成员经授权后可以通过云端协作共同编辑该矩阵。通过由MorphoBank matrix editor创建的特征矩阵可以轻松的在Nexus或TNT等专业软件之间转换,便于用户进行线下数据分析。除此之外,用户可以把MorphoBank作为数据容器来存储标本相关的多媒体数据、分类数据和采集数据,并将这些数据随同论文发表。截至2020年1月,MorphoBank拥有780个开放的项目,包含142256张图片和483个特征矩阵。除此之外,MorphoBank还有1278个正在进行的项目,包含136789张图片和1040个特征矩阵,这些数据将在科研人员的项目结束后开放获取。截至目前,共有2738名科研人员和学生为MorphoBank贡献过数据。
虽然MorphoBank不是专一的古脊椎动物数据库,但与其他古脊椎动物领域的数据库相比,MorphoBank在多媒体数据的积累上优势明显,这得益于其提供给用户不限容量的存储空间用以存放论文相关数据,与专业性期刊杂志形成了良好的互补。其网站界面友好,用户可以自由地查询、获取数据或创建自己的项目。加上近年来MorphoBank举办了很多培训交流会,并协助专业生物类期刊存储论文相关数据,使得MorphoBank的发展进入了良性循环,积累了大量用户的同时,也获得了更多的经费支持。

图10 MorphoBank矩阵编辑界面示例Fig. 10 Interface of MorphoBank matrix editor
在版权保护方面,MorphoBank引入了目前主流出版物中所使用的数字标识符(DOI, Digital Object Identifier)来保护每一份数据。
2.12 PBDB古生物研究型数据库
PBDB(Paleobiology Database; https://paleobiodb.org/#/)和Fossilworks (http://fossilworks.org/)为同一套数据的两个不同门户网站。PBDB始于美国国家生态分析与综合研究中心(NCEAS, National Center for Ecological Analysis and Synthesis)在1998年到2000年间资助的显生宙海洋古动物数据库,由当时身在美国的John Alroy等人创建。其后,该数据库合并了一些老旧的数据库,如史密森尼学会的陆地生态系统演化数据库、芝加哥大学的古地理图数据库、Sepkoski的海洋动物数据库等。PBDB目前由威斯康星大学麦迪逊分校的Shanan Peters团队维护。John Alroy离开美国,前往澳大利亚麦考瑞大学任职后,开发了Fossilworks作为PBDB的每日备份,由其独自维护。Fossilworks门户网站仅提供数据的查询和下载,不提供数据的录入。如果用户有数据录入需求,需联系PBDB团队获取“数据作者”账户,通过PBDB门户网站录入数据。
PBDB的数据由7个主要的数据表组成,分别对应发表文献、分类单元名称、分类单元同异名、分类表、原始采集数据、产地与层位、产地与层位的厘定信息,此外还包括生态学信息表、埋藏学信息表、标本测量信息表和化石标本图片等辅助数据表。这些数据表通过数据库内的专有ID相关联。截至2020年1月,PBDB共收集了71631篇文献、408385个分类单元、207635条采集层位的1458199条化石记录,累计贡献者达410人。
PBDB团队开发了非常先进的PBDB Navigator在线交互程序(图11),提供可视化查询与下载、古今地理投点和多样性曲线绘制等功能。数据库中集成了两套古今坐标系转换算法,极大的方便了用户。最初的算法由著名古地理重建专家Chris Scotese提供,2014年PBDB团队引入了EarthByte团队开发的GPlates转换算法(Wright et al., 2013),但Chris Scotese的算法仍集成在数据库中作为备选项供用户使用。
就目前发展来看,PBDB在交互性和开发能力上较其他数据库更胜一筹,不仅提供数据下载,还提供有各种网页端程序、移动端程序、R语言包及标准程序接口(API)等,使得专业用户和普通用户都能快速、便捷地获取和使用数据。PBDB网站也提供很多免费视频教程供用户参考。强大的功能与突出的用户友好度,使得PBDB积累了大量的用户,是目前最活跃的古生物数据库。
近年来,古脊椎动物研究专家利用PBDB中丰富的数据和数据分析功能,获得了许多重要的科学发现。Fischer 等(2016)研究鱼龙多样性随时间的变化规律时,使用最简约法构建了鱼龙的系统发育树,然后使用贝叶斯方法推算鱼龙的形态演化速率,并比较了由系统发育推测的物种多样性(phylogeny-adjusted diversity estimate)与实际观察到的物种多样性的差异,进而结合海洋化学、海平面高度等环境数据,发现鱼龙在白垩纪早期多样性很高,晚期演化速率越来越低。Fischer等人据此否定鱼龙是在与其他海洋爬行类和鱼类的竞争中落败的假说,提出气候变化是当时海洋生态系统变化的主要驱动力。此外,他们的研究还发现,大约一亿年前发生在白垩纪塞诺曼期的灭绝事件极大的降低了鱼龙的多样性。
2.13 中国古脊椎动物与古人类研究型数据库
中国古脊椎动物与古人类数据库(VPPDB,Chinese Vertebrate Paleontology and Paleoanthropology Database;http://www.deepbone.org)系中国科学院古脊椎与古人类研究所朱敏研究员和潘昭晖等于2019年创建,2020年更名为“深骨计划”(Deep Bone),其资助主要来自中国科学院战略性A类先导专项“地球大数据科学工程”。DeepBone的建设目的是依托中国科学院古脊椎动物与古人类研究所丰富的标本资源和研究实力,逐步汇集中国乃至全球古脊椎动物与古人类领域的标本及相关数据,为探寻生命演化、地质历史中海陆生物多样性变化及其环境制约、重要生物类群的起源与演化等科学问题提供服务(Pan and Zhu, 2019)。

图11 PBDB界面Fig. 11 Interface of PBDB Navigator
有别于其他以化石记录为核心的古生物数据库,DeepBone以标本为核心,收集与标本相关的文献数据、采集数据、测量数据等信息(图12)。DeepBone的数据涵盖了早期脊椎动物、古两栖类与古爬行类、古哺乳动物、古鸟类、古人类和旧石器六大方向。所有标本和数据均来源于已正式发表的文献,并经由领域专家审定,以保证数据质量。此外,DeepBone也引入主流出版物中所使用的数字标识符(DOI)保护数据贡献者的劳动成果。DeepBone鼓励用户在使用数据时引用或致谢相关的数据贡献者,以保证数据库的长期可持续发展。
除了常见的数据模块外,DeepBone中还增加了专门的解剖学特征术语模块,为各化石类群的解剖学术语提供由参考文献支撑的科学释义,并提供相关说明图片供用户参考。未来DeepBone将尝试把解剖学术语直接与标本关联,开发类似于MorphoBank matrix editor的特征编辑功能。
DeepBone的数据完全开放,除提供前台数据浏览、检索和下载外,也提供了通用程序接口及标准开发文档供第三方开发者或数据分析者直接调用,而无需完全下载数据。

图12 DeepBone数据库的结构Fig. 12 Schematic design of the DeepBone database
由于该数据库2019年新建,目前仍处于快速录入数据的阶段,早期脊椎动物数据正稳步增长,未来待数据丰富后将推动数据驱动下的相关科学探索研究。
3 数据驱动的古脊椎动物学新学科:保育古生物学
随着人类活动对地球影响的加剧,人类对栖息地破坏、过度利用自然资源以及物种入侵的认识逐渐增强,当今学界已经充分意识到人类已经成为了改变地球的主要力量,以至于有学者提出人类世(Anthropocene)这一名词,用来指示18世纪末至今人类活动对环境和生态系统造成重要影响的这段地质年代。保育生物学就是在这一背景下产生,其目的是研究如何保护生物物种、栖息地乃至整个生态系统,进而改善人类赖以生存的自然环境。随着保育生物学的不断发展,学者们发现,现有的研究在时间尺度上存在明显的局限性,于是将目光投向时间尺度更大的古生物学,因此保育生物学与古生物学相结合便产生了一门新的学科:保育古生物学。
经过深入、广泛的讨论,保育古生物学被定义为:应用古生物学的方法和理论,研究生物多样性、生态系统服务的保护与恢复(application of the methods and theories of paleontology to the conservation and restoration of biodiversity and ecosystem services;Dietl and Flessa, 2001; Dietl et al., 2015)。该定义体现了保育生物学的核心目标,即保护和恢复生物多样性,维持生态系统的服务。保育古生物学包含两个互补的研究方法,即近时方法(near-time approach)和深时方法(deep-time approach),两者的区别主要在于研究的时间尺度不同(Dietl et al., 2011)。近时方法依据近两百万年来的化石记录,主要聚焦现生物种,探讨当今生物多样性的形成和发展;深时方法则基于更早的地质与化石记录,多尺度分析不同种类、不同时代的生物对环境变化响应的异同,探索地质历史时期生物多样性的演变及其环境背景。其中,深时方法能够在更大尺度上检验生物与环境的相互作用,为生物多样性的保护与恢复提供历史借鉴。
保育古生物学真正引起学界注意是因为2001年北美古生物学大会期间组织的保育古生物学的主题会议——“New Uses for the Dead: Paleobiological Contributions to Conservation Paleobiology”, 此 后相关研究论文如雨后春笋般涌现。截至2020年2月,通过Web of Science核心合集检索“conservation paleo*”,可得到6516篇相关论文记录,其中首篇保育古生物学主题论文发表于2009年(Simões et al., 2009)。为了研究这门新兴学科的发展,我们下载了该搜索结果中的文献记录,包含标题和摘要,利用网络分析(network analysis)方法(Newman,2018;Tyler, 2018)构建了保育古生物学论文关键词网络(图13)。在该网络中,共同出现的关键词越多,说明相关研究的关联性越强(Boyack and Klavans, 2010),借助此方式我们可以观察保育古生物学学科的发展历程。首先,我们将从Web of Science数据库中得到的数据剔除标题和摘要外的信息后,对标题和摘要进行分词;其次,利用二进制计算(binary counting)含关键词的文献次数,而不是计算关键词出现的总数,共得到22498个关键词;为缩小范围,剔除小于10次的结果,得到329个关键词;然后,计算329个关键词网络的相关指数,选取前60%最相关结果共197个,剔除结果中的无意义词汇,例如activity、south、part、index、idea、new insight等,最终得到 120个关键词;最后,对这120个关键词绘制关系网络。
关键词根据相关性被分为3组,在图13中分别以三种不同的颜色标识。每个节点代表一个关键词,节点的大小与关键词在网络中的中心性正相关,节点间的距离则表示两节点在网络中的相关性。蓝色组中,最大节点——物种(species)共出现295次,次大节点——多样性(diversity)出现121次,两节点有很强关联性,说明保育古生物学研究重点关注物种多样性问题。此外,地方性(endemism)、岛屿(island)、动物区系(fauna)、系 统 发 育(phylogeny)、 演 化 历 史(evolution history)、灭绝(extinction)等次级节点不仅内部关联性强,也与另外两组关联较多,说明它们是当前保育古生物学以物种为核心的研究热点。而形态学(morphology)和新种(new species)与其他关联性较弱,可能是因为这两个关键词多出现在传统古生物学研究,保育古生物学并不过多关注新属种的描述及传统的形态学研究。绿色组中,分布(distribution)出现152次,种群(population)出现148次,为该组的主要节点,说明保育古生物学另一大关注方向为种群的分布。该组内我们可以看到扩张(expansion)、扩散模式(distribution)、基因多样性(genetic diversity)、基因流(gene flow)、分化(differentiation)、分异(divergence)、隔离(isolation)、环境变化(climatic change)、残遗种保护区(refugia)等次级节点,这些内容与传统生物学联系紧密,说明保育古生物学不仅以种群为单位从宏观上研究种群的扩散、迁移模式,也从微观角度研究种群内部基因型的变化。红色组中,节点中心性的差异较小,体现在节点大小差异不明显。其中,沉积(sediment)出现93次,系统(system)出现86次,生态系统(ecosystem)出现76次,表明该组与地质学的相关性较大,在保育古生物学中历史环境资料的获取多依赖于地质历史资料。次级节点如水(water)、土壤(soil)、河流(river)、湖泊(lake)、湿地(wetland)、火(fire)等指示了保育古生物学关注的环境因素。过去(past)出现47次、未来(future)出现40次,两者关联性高,说明在保育古生物学中地质历史资料是预测未来生态系统走向的关键。

三组间的关系中,蓝色组和绿色组的相互关联性较红色组高,说明在现阶段的保育古生物学研究中,古生物和现生生物间的综合研究较多,融汇更密切。地质历史资料多独立用于生态系统、环境等系统级别的演化研究,或作为物种、种群研究的环境背景。物种节点中心性最高,说明当前保育古生物学更关注物种水平,种群水平次之。
本次分析中,化石记录(fossil record)和化石(fossil)节点关联物种、种群、多样性、分布、生态系统、灭绝、风险(risk)、过去、保护(preservation)等9个节点,说明化石记录在保育古生物学中具有重要地位,是研究物种多样性、种群多样性、物种分布、生态系统相关保育问题的关键。
3.1 深时方法:揭示早期脊椎动物的起源地研究实例
脊椎动物从鱼到人的演化历程已经被研究了上百年,但前人主要关注颌的起源、牙齿的起源及四肢的演化等比较解剖学问题,很少会追寻其起源地。这主要是由于过去缺乏早期脊椎动物化石记录及其栖息地的信息,也缺乏成熟的数据分析方法,导致对某些早期脊椎动物重要类群的起源与分化地一直未有定论。Sallan 等(2018)从PBDB中获取了特定范围的沉积学数据、地球化学数据和无脊椎动物化石群落数据,以此标定早期脊椎动物的环境背景,然后结合自己汇编的2728条早期有颌类全群出现记录及其环境数据,利用贝叶斯系统发育方法推演早期脊椎动物演化树中主要支系祖先的生境,发现早期脊椎动物起源于浅水潮间带和潮下带,并在这些环境中分化(图14)。此外,研究表明,随着近岸种群的多样化,这些早期脊椎动物由于体型的差异产生了不同的适应性,进而扩散到其他的生境中。该研究指出,体型较大的脊椎动物仍会留在近岸或淡水栖息场所,而体型较小的脊椎动物则会移居较深的水域以避开激烈的竞争环境。Pimiento(2018)强调,当今近岸环境在维持物种多样性上仍具有重要作用,但这类生态系统却是受到人类活动改造最严重的地方。这一研究是保育古生物学深时方法的典型应用案例,为我们理解脊椎动物宏演化,制定改善现有生态环境的策略具有重要指导意义。

图14 中古生代脊椎动物起源于浅海生境Fig. 14 Mid-Paleozoic vertebrates preferentially originated in shallow marine habitats
3.2 近时方法:指导政府制定濒危物种保育策略实例
对保育古生物学关键词的网络分析中存在大量基因相关的节点(图13),表明近年来古DNA分析手段的进步使得保育遗传学(Conservation Genetics)开始关注古DNA信息。保育遗传学是保育生物学的次级学科,主要研究影响物种灭绝的遗传因素和濒危物种的遗传管理,以降低物种的灭绝风险。由于濒危物种往往种群较小,现代DNA数据仅能反映种群发生瓶颈效应后的基因型多样性,因此种群的历史演化过程中存在大量空白,但如果加入古DNA数据,就能很好的弥补这一缺陷(Ramakrishnan and Hadly, 2009)。众多研究结果也显示,加入古DNA或化石数据分析所得出的结论,可以推翻仅基于现生种群的基因研究所得出的假说(Leonard,2008)。
对斯堪的纳维亚灰狼(Canis lupus)起源问题的研究直接关系到该种群的存亡。部分学者支持人为灭绝现今斯堪的纳维亚灰狼的原因是,原斯堪的纳维亚地区的灰狼已经在两百年前人类的捕猎中灭绝,对现今生活在斯堪的纳维亚地区的灰狼线粒体DNA的研究表明,该种群是由俄罗斯灰狼所形成的(Ellegren et al., 1996),那么该种群极有可能来自于动物园的非法放生。当地以畜牧业为主,灰狼对羊群的养殖构成了极大的威胁,如果该种群属于外来入侵种,那么就有充足的理由人为灭绝该种群。但Vila 等(2003)结合古DNA数据进行了分析,结果表明,现今斯堪的纳维亚地区的灰狼种群虽然不是源自该地区古老的土著亚种,但也不是来自非法放生,而是邻近地区的东方狼群中的两只个体迁徙到了这里后繁衍而成,因此对该种群的保护合理且合法。该研究对斯堪的纳维亚地区灰狼种群的政府保育政策起到了重要影响。在Vila等人的研究中,现生DNA数据(线粒体DNA),94件来自1984年至2001年间采集的斯堪的纳维亚地区灰狼标本,93件来自芬兰和俄罗斯中北部现生灰狼,66件来自纯血或混血的狗,古DNA数据来自Flagstad 等(2003)从30个原斯堪的纳维亚灰狼博物馆标本的牙齿中所提取的线粒体DNA数据。他们使用GENETIX v. 4.02软件开展了因子相似性分析(factorial correspondence analysis),以确定样本在二维空间的基因相似性和各种群间的基因多样性,然后使用KINSHIP v. 1.0计算一对常染色体的微卫星基因的似然比以推测个体间的关系,最后在STRUCTURE软件中使用贝叶斯方法评估现今斯堪的纳维亚灰狼祖先基因型起源于不同地方的可能性。研究结果显示,该种群的建群雌性与雄性分别有0.95和0.98的概率来自邻近的东部灰狼种群。该研究结果也得到了地理学研究的支持,现今斯堪的纳维亚灰狼的祖先可能穿越了500 km的驯鹿牧区或200 km的波罗的海冰上通道,抵达了斯堪的纳维亚并定居繁衍(Linnell et al., 2005)。
4 总结与展望
古脊椎动物学研究过去常被误解为“集邮式”(stamp collecting)的科学,缺乏定量研究和数据分析(Mounce, 2014)。但随着研究的不断深入与技术手段的不断发展,当代古脊椎动物学已经非常依赖于收集、计算和分析大量的数据,证实或证伪相关的理论假说或提出新的创新思想。自古脊椎动物学科建立以来,数据一直呈爆发式增长,即使如PBDB这种较为成功的综合性数据库也已不能满足现今古脊椎动物领域科学研究的需求,因此面对特定研究方向和不同使用群体的数据库不断涌现。一旦有古脊椎动物方向的研究论文发表,其相关数据(如特征矩阵、标本照片、三维形态模型、标本关联信息、地层信息等)通常很快被各种数据库收录,这为数据的再利用提供了便利。然而,不同数据库由于侧重点、研究方向、数据库架构或者数据格式不同,往往又会给数据的再利用及跨库的检索造成困难。当科学研究发展到“第四范式”时,无论是研究者个体还是科学共同体都希望能够高效、便捷地获得全面、高质量的数据服务。因此,在地学领域,“深时数字地球”计划(DDE)就应运而生。从古脊椎动物领域的数据库发展来看,构建这样跨领域的大数据体系和数据驱动下的科学研究已经是迫在眉睫了,有必要跳出传统思路的局限,直接瞄准学科未来发展趋势,以开放、共享、复用、智能等原则为指导,通过建立地球大数据知识图谱,搭建面向人工智能时代的智能化平台,实现多源异构数据的融合,为用户提供一站式的数据服务。通过知识图谱技术汇集数据,提供数据共享服务,这将摆脱传统数据库架构和数据规模局限的束缚,打破“信息孤岛”(Luo,2013)。此外,目前古脊椎动物领域的数据搜集仍严重依赖于人力,由科学家个人或团队维护的数据库由于缺乏足够的人力,数据增长缓慢,有时还会导致数据质量存在缺陷。如果结合机器学习和自然语言处理,实现海量文献的知识自动抽取,有监督的构建知识体系,并可持续的补充完善知识图谱,同时对科学问题进行深入挖掘,分析相关科学问题的出现和演化的过程,将可以更好地帮助科研人员获取所需信息,理解细分领域的研究历史和现状,快速识别研究的前沿热点问题,把握科学发现的突破方向。
深时数据的快速积累使得保育古生物学在近二十年内快速发展成为一门重要的学科,试想没有任何一个人工模拟的实验能够媲美地球历史上已经发生的变化,所以为了探寻环境变化的规律和生物对环境变化的响应,最好的办法就是从地球已有的“实验记录”中寻找答案。对这些“实验记录”的科学分析,将可以为我们认识自然界的内在规律、制定生物多样性保育策略及预测未来地球的发展提供帮助。但相比于现今的数据,深时数据存在分辨率低的缺陷,这主要是由地质记录不完整所导致的,解决这一问题依赖于深时数据的不断积累和分析方法的持续创新。可以期待,“深时数字地球”计划一旦成型,将会极大地推动保育古生物学的发展,包括数据的快速增长结合机器学习实现知识智能抽取的愿景,统计分析方法的创新解决分辨率不足的缺陷,数据科学的融合实现数据驱动下研究范式的变革,等等。最终,通过古今数据的融合、互补,或将解决目前人类面临的生物多样性与生态安全等重要科学和社会问题。
致谢:感谢南京大学樊隽轩教授、史宇坤副教授对本文的细致修改和指导,丰富了文章的内涵。编辑与审稿人的建设性意见对本文的修改完善起到了重要作用,在此一并致谢。
