基于局部排序的双虹膜模板保护方法
2020-08-24张文云刘笑楠高艳娜
张文云,刘笑楠,高艳娜
(沈阳工业大学信息科学与工程学院,沈阳110870)
1 引言
近年来,生物特征识别技术已成为研究热点,并在实际中得到广泛应用。但是,该技术中用于识别身份的生物特征模板有可能被盗取从而泄露隐私,威胁用户的隐私安全[1]。并且生物特征是不可再生的,一旦被窃取,用户损失无法挽回。因此寻找一种安全可靠的模板保护方法是保证生物特征识别技术实用化的关键。
虹膜是被广泛应用的生物特征之一,目前最常用的一种模板保护方法是基于不可逆变换的保护方法。不可逆变换法利用不可逆变换函数无法恢复出原始数据的特性实现数据保护。Ratha等人[2]首先将不可逆变换应用于图像领域。此类方法包括随机投影和稀疏表示法[3-4]、随机移位和XOR操作变换法[5-7]、Bloom滤波器方法等。由于随机移位和XOR操作变换法会减少可用于识别的信息量,后续许多学者对该类方法提出改进,采用Bloom滤波器方法,如文献[8-9]分析了基于Bloom滤波器的特征保护方法的不可链接性,并且引入了采用数据不均匀性的不可逆性分析。Dong等人[10]提出了一种基于遗传算法的相似性攻击框架,针对生物哈希法和Bloom滤波器方法进行实验。Rudresh等人[11]提出一种基于随机查表映射的可撤销的虹膜模板生成方法。上述方法几乎都满足不可逆变换这条特性,并且都是在基于二值模板的基础上采取保护措施,这类方法一旦攻击者获取变换函数的相关参数,并且采用多重放攻击,以及解方程能够得到原始模板,也会导致信息泄露。2018年Randa等人[12]提出了一种基于双随机相位编码的可撤销虹膜识别方法。该方法是一种编码加密方法,从获取的特征数据直接通过双随机编码得到加密的二值模板,但是通过逆推法以及解方程也可能获得原始模板。
综上所述,在此提出一种基于局部排序的双虹膜模板保护方法。首先将左虹膜特征数据与右虹膜特征数据进行异或,对左虹膜特征数据进行第一重加密保护,其次,将异或所得结果分块分组处理,并将每组换算为十进制数进行排序,再将排序数值换算为二进制字符串作为最终的加密模板。
2 算法流程
所提的虹膜模板保护方法是利用同一用户的一只虹膜作为密钥去加密需要被认证的另一只虹膜,并通过转换的手段得到最终的加密模板。算法的具体流程如下:
首先,对同一用户左右虹膜的归一化虹膜图像采用log-Gabor变换进行特征提取,获得左虹膜特征数据记作xi=x1,x2,...,xm,右虹膜特征数据记作yi=y1,y2,...,ym,则两特征数据的异或如式(1)所示:

其中i=1,2,...,m,⊕表示异或。
其次,进行分块处理。将异或所得结果分为n块,记作b=b1,b2,...,bn,每块含有a位二值数组,即:bi=bi,1,bi,2,...,bi,a,bi,j=t(i-1)×a+j,其中j=1,2,...,a。将b=b1,b2,...,bn分成g组,即B=B1,B2,...,Bg,Bi={b(i-1)×d+1,...,bi×d},其中i=1,2,...,g,d为分组大小,n=g×d。
然后将上述分块的二进制数转换成十进制数,记作q1,q2,...,qd,即:
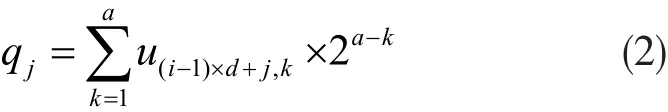
将q1,q2,...,qd排序后转换为二进制序列r(i-1)×d+1,...,ri×d,i=1,2,...,g,存储该模板数据并删掉其它参数。
最后得出分类结果如下式:
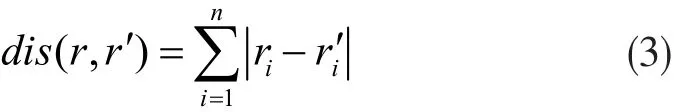
3 算法安全性分析
根据生物特征信息保护标准,安全的虹膜特征模板保护方法应满足不可逆性,在未知右虹膜特征数据的前提下对算法的不可逆性进行理论分析。
不可逆性要求从原始数据到安全模板的转换是不可逆的。若满足不可逆性,则攻击者无法从加密数据模板r中恢复出原始数据模板x。具体分析如下:
当进行逆变换时,攻击者获取存储在数据库中的加密模板即r(i-1)×d+1,...,ri×d时,其中i=1,2,...,g,要将其进行十进制的转换恢复出q1,q2,...,qd,并做反排序处理,最后进行反异或处理得到原始数据特征。在此过程中必须要知道同一用户的右虹膜数据特征即yi=y1,y2,...,ym。在一般情况下,假设转换的十进制数q1,q2,...,qd是按照从小到大的顺序进行的排序,如若攻击者从r(i-1)×d+1,...,ri×d恢复出q1,q2,...,qd,只需要知道同一用户的右虹膜数据特征yi=y1,y2,...,ym,则可恢复出原始数据模板x。
当获取到存储在数据库中的模板r(i-1)×d+1,...,ri×d时,假设由r(i-1)×d+1,...,ri×d可以映射到q1,q2,...,qd的数目为f(d,2a),如下式:
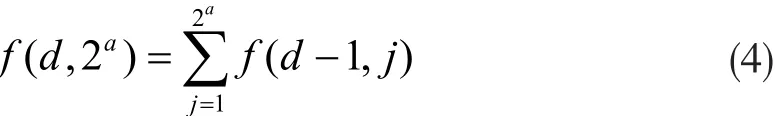
其中,a是块大小,2a为qd所有可能值的数量。
由上述可知qd可取值的范围为0,1,...,2a-1,分别为f(d-1,1),f(d-1,2),...,f(d-1,2a),由此可得初始值为f(d,1)=1,f(d-1,1)=1,f(d-2,1)=1,...,f(1,1)=1,f(1,2)=2,f(1,4)=4,...,f(1,2a)=2a,由此可将式(4)转化为:
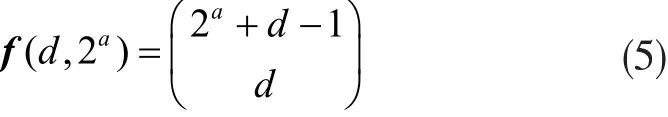
然而该模板总共分为g组,如获取加密模板数据,则可能生成原始数据的数量有:

调节参数a与d,可实现不可逆性。
4 实验结果与分析
为测试算法的各项性能指标,采用数据集CASIA-V3中的两个子图库CASIA-IrisV3-Interval、CASIA-IrisV3-Lamp以及MMU-V1进行算法测试。采用CASIA-IrisV3-Interval图库中的249个人的虹膜图像,CASIA-IrisV3-Lamp图库中的411个人的虹膜图像,MMU-V1图库中的46个人的虹膜图像。
本虹膜识别系统包括注册和认证两个阶段。在图像预处理过程中,采用文献[13]的定位方法分割出虹膜区域,将所得虹膜区域的下半部分进行归一化处理,获得52×624的归一化虹膜图像,再通过log-Gabor变换进行特征提取。预处理及提取效果如图1所示。
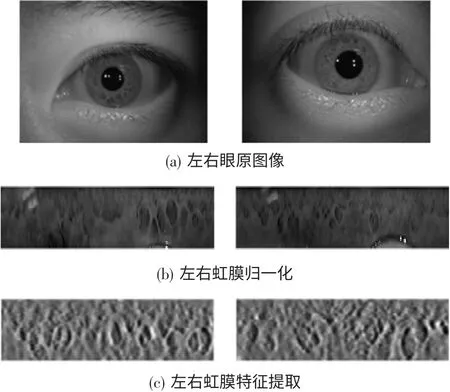
图1虹膜图像预处理及特征提取
注册阶段采用每个人的左右虹膜特征数据进行异或处理,再通过分块以及块分组,将二进制转化为十进制数进行排序处理,在转换为二进制模板作为最终的加密模板。在验证阶段,应用程序通过相同模式得到最终模板并使用汉明距离将其与数据库中的数据进行匹配得到身份识别结果。
为说明算法的识别性能,通过正确识别率GAR、等错误率EER、ROC曲线下的与坐标轴围成的面积AUC三种评价指标来分析。除此而外用可判定性度量d'来区分真实和假冒分布,定义如下:
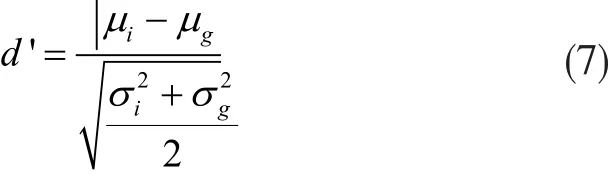
其中μi和μg为假冒者和真实者的均方值,σi和σg为假冒者和真实者的方差。d'越大,表明冒名顶替者与真实分布之间的距离越大,识别性能越好。以上各性能指标的值是通过真实的和冒名顶替者的得分来评估的。这里采用类间匹配得分评估冒名顶替者得分,将每个用户的虹膜模板与其他用户的模板匹配;采用类内匹配得分评估真实者得分,通过每个用户的虹膜与同一用户的其他虹膜模板相匹配,得到类内的匹配总次数。
分别对三种图库进行100次随机注册和测试样本选取,所得各项性能指标的平均值如表1所示。不同算法的ROC曲线如图2所示。
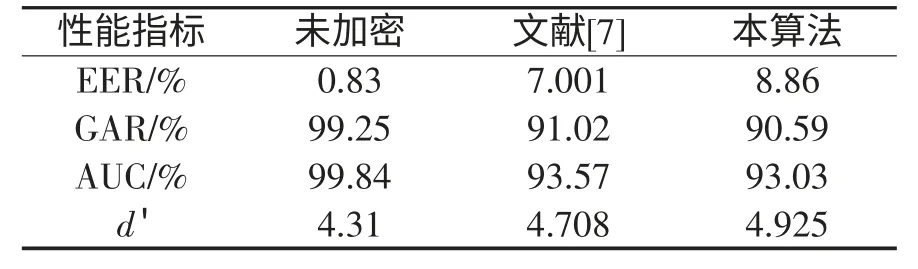
表1不同算法的识别性能比较

图2不同算法的ROC曲线
测试结果表明,本方法识别正确率略低于未进行加密保护的识别算法,但其d'值较高,说明该法的模板保护性能更好。与文献[7]方法相比,虽然本法GAR、AUC略低,但d'值高,说明冒名顶替者与真实分布之间的距离较大,算法保护性能更好一些。
为说明本算法对不同虹膜图像的适用性,将CASIA-IrisV3-Interval,CASIA-IrisV3-Lamp以 及MMU-V1三种图库的测试结果列于表2。

表2不同数据库所对应的GAR/EER(%)
其中,基本算法指未加密的虹膜识别方法。结果表明本方法在三种图库中均能够取得较好的识别效果,并且加密时的识别性能与本算法相差无几,说明本算法在对模板保护的同时能够兼顾识别性能,具有适用性和有效性。
按照文献[7],分块的大小d通常设置为2到64之间的整数,而比特位数a设置为1至8之间的整数。不同取值下的GAR(%)如表3所示,可见,当a=1,d=16时,识别率最好。
5 结束语
针对模板泄露提出的双虹膜模板保护方法,将左虹膜特征数据与右虹膜特征数据进行异或,对左虹膜特征数据进行第一重加密保护,将异或结果分块分组处理,通过十进制数排序与二进制的换算,很好地实现了依据汉明距离对加密模板进行匹配识别,算法满足不可逆性。测试结果表明该算法在保护模板的条件下识别正确率能够达到90.55%,在满足虹膜识别正确率的同时,亦可满足识别性能的需求,有效地保护用户的生物特征信息。
