基于SVM算法的高职贫困生导常行为的研究
2020-08-21周静龙小宏
周静 龙小宏


摘要:目前,我国高职院校基本都已经建立了较为全面的贫困大学生资助体系,但是由于学生的贫困生申请信息偏于主观、贫困指标难以量化等因素,使得贫困生认定工作仍然是高职院校资助决策中的难点问题。一般高职院校贫困生评定流程,一是让学生在家庭所在地开贫困证明,二是学生在学校填写贫困生申请表,三是由学生所在院系组织评议小组对申请人进行评议。但是,学生向学校提交的家庭贫困证明,往往会出现虚假信息的情况,这就给高职院校资助工作带来了难题。因此,如何在高职院校缺乏学生的真实家庭情况以及助学金的金额有限的背景下,将助学金发放到最需要帮助的学生手上成为亟待解决的问题。本文利用大数据技术,对学生在学校使用一卡通产生的消费、进出图书馆、进出教室寝室等数据进行挖掘与分析,判断高职院校目前采用的贫困生评判规则是否合理,并找出其中“伪贫困生”和真正需要帮助的学生,为高职院校学工部在贫困生资助管理工作中提供参考意见。
关键词:贫困生;SVM;异常行为
中图分类号:TP391.41 文献标识码:A 文章编号:1007-9416(2020)07-0103-03
1 高职院校贫困学生认定的现状
高職院校认定贫困学生的方法,大部分采用的是证明、消费和评议三个关卡,班级、院系、学校三级评审[1]。
贫困证明,学生提供在当地政府、街道出具的家庭经济困难证明或者残疾证明。
消费水平,一个消费比较低的学生不一定是贫困生,但消费高的学生一定不是贫困生,因此,消费水平作为认定贫困生的一个重要参考依据。
评议,需要认定贫困的学生,在辅导员监督下,贫困申请学生所在班级的同学根据该学生提交的材料及贫困生本人的综合情况,对其进行评议,投票决定是否上报上一级进行公示。
以上认定方法,流程虽然清楚,但是有一些参数或指标不能够定量,人为因素较大,容易出现偏差,不符合贫困生工作公平公正的原则。
2 模型的选取及应用
2.1 支持向量机理论
支持向量机(Support Vector Machine,SVM)是Cortes和Vapnik于1995年首先提出的,是一种从线性可分数据的“最优分类面”求解方法发展而来,基于结构风险最小化原理(Structure Risk Minimization,SRM)的机器学习方法。该理论在解决小样本、非线性及高维模式识别中,具有许多特有的优势,能够推广应用到函数拟合等其他机器学习问题中。
SVM算法在非线性映射时,将低维样本特征映射到高维特征空间,让非线性可分的问题性质转化成线性可分,但是在无形中增加了计算的难度,还有可能出现维数灾难,SVM解决此类难题的方法是利用核函数方法。
2.2 计算过程及结果
2.2.1 数据预处理
高职院校学生入学报到时,学工部提供了迎新系统中学生的基本信息,辅导员让学生填写学生基本信息表,教务处提供教务管理系统中学生成绩,辅导员负责管理学生并与学生进行深度沟通交流,做好相关记录,学生到校后,在校园内所有消费均使用一卡通交易,为本次实验奠定了良好的基础。
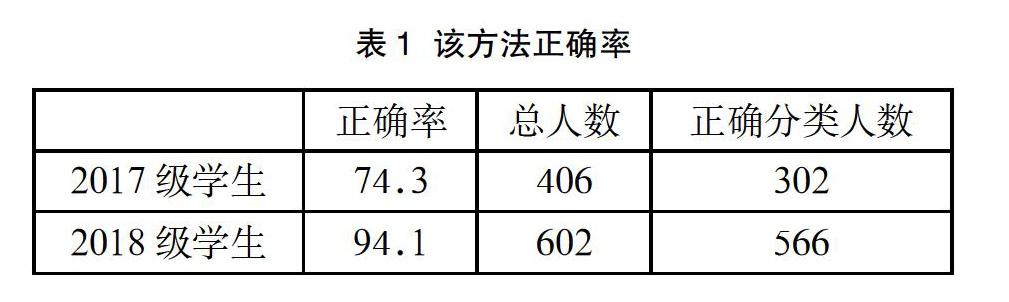
本次实验选取了泸州职业技术学院2017级500多名学生,2018年9月到2019年9月的原始记录,包括406名训练样本和104名实验数据,再获得2018级602名学生2018年9月到2019年9月的原始数据作为实验数据,并认真整理分析了此类信息。
2.2.2 提取相关数据
实验前向学工部有经验的学生管理人员了解情况,深入分析以往已形成的理论与案例,大致了解高职院校贫困学生异常行为[2]有关的因素,如学生家庭情况(家庭成员是否有残疾、是否为单亲)、家庭经济情况(是否有贫困证明)、与同学的关系(是否与学生存在过节)、是否有心理疾病、是否当过班委、是否有男(女)朋友、是否参加了学校的社团、是否做过兼职、是否获得过奖学金等。在进行实验时,提取贫困学生以上九个维度的相关数据。本次的训练样本一共包含406个学生对象,其中重点关注学生是否为重点分类标签。基于分类标签构建训练数据矩阵406×9及一个分类结果406×1,使用支持向量机算法。首先提取学生的数据特征,训练样本并获得分类模型,这是测试阶段进行判断的基础条件。训练过程中重点关注学生作为负样本,即说明学生可能存在学业方面的问题,在学业方面存在异常行为。非学业重点关注的学生,即正样本,这部分学生在学业方面并不存在较大的问题。
2.2.3 求最优化问题
采集的数据可能存在缺失或者不够具体,无法准确的表达学生的详细信息,如学生由于种种原因,并不会坦白自己是否失恋过,因此线性分类器无法准确以此为依据进行分类。本次引入基于最小二乘的支持向量机法进行分类,以期实现精确的分类,此种方法在构造最优决策函数[3]方面引入了间隔的概念,不使用高维特征空间复杂运算,而是使用原空间核函数进行计算,不仅能够达到优化目标的目的,而且同时选取损失函数,有助于规避错误数据。基于此种情况下的优化问题,应符合如式(1)和式(2)。
2.2.4 训练和测试结果
利用SVM分类获得最终结果,测试时在经过训练的分类器中,输入测试贫困学生数据,并结合训练结果来判定学生是否存在异常行为。整个实验过程较为简单,仅需要预先将统计好的学生数据输入系统即可完成异常行为判断。其测试结果如图1所示。
在图1中,用蓝色、红色表示分别表示2017级、2018级的学生。横坐标分别表示非学业重点、实际学业重点、预测非学业重点、预测学业重点关注对象。我们提前与学工部学生管理人员进行深入的沟通,了解学生的情况,并对比分析实际所调查的情况,以验证该方法的正确率。如表1所示,其正确率可达到:
3 结语
精准扶贫是高职贫困认定需解决的一个重要问题,因而对贫困生异常行为的研究是高职院校精准扶贫重点关注的话题。针对高职院校的精准扶贫,本文选取了SVM算法进行对贫困生异常行为研究,采用对某高职院校贫困生总计1106条数据进行实证分析。实验结果表明,支持向量机模型可以较好地根据有学生家庭情况、家庭经济情况、与同学的关系、是否有心理疾病、是否当过班委、是否有男(女)朋友、是否参加了学校的社团、是否做过兼职、是否获得过奖学金等参数评估真正贫困生的概率,为大数据背景下高职院校精准扶贫提供了新的思路和方法。
参考文献
[1] 朱虹,覃向梅,陆蕾.高校精准扶贫工作的落实与路径分析[J].职业,2019(13):114-115.
[2] 邓晗.基于机器学习和大数据技术的高校学生行为分析[D].北京:北京邮电大学,2017.
[3] 戴海辉.基于Hadoop的校园卡数据挖掘的研究与实现[D].南昌:南昌航空大学,2017.
