集成学习之随机森林分类算法的研究与应用
2020-08-21吴兴惠周玉萍邢海花
吴兴惠 周玉萍 邢海花
摘要:集成学习是多分类器学习系统。而随机森林是一个包含多个决策树的分類器,是一种基于Bagging的集成学习方法。随机森林具有预测准确率、不容易出现过拟合的特点,在很多领域都有所应用。本文主要利用随机森林算法对心脏病数据集建立了分类预测模型,实验结果表明,随机森林算法在预测性能上超过了决策树和逻辑回归分类算法,并通过绘制ROC曲线对四种模型进行了对比。
关键词:集成学习;随机森林;预测
中图分类号:TP181 文献标识码:A
文章编号:1009-3044(2020)21-0026-02
开放科学(资源服务)标识码(OSID):
数据挖掘的一个重要领域是数据分类,对数据进行分类和预测是当前比较热门的研究。机器学习中的分类算法属于有监督学习,常用的分类算法有决策树、贝叶斯、神经网络、支持向量机、随机森林等。集成学习是多分类器学习系统。而随机森林是一个包含多个决策树的分类器,是一种基于Bagging的集成学习方法。它包含多个决策树,并且它的输出类别由所有树输出的类别的众数而定。由于它具有预测准确率、不容易出现过拟合的特点,在很多领域都有所应用。随机森林在医学领域、经济学、刑侦领域和模式识别领域取得了较好的效果。本文基于一个心脏病数据集,利用随机森林算法建立分类模型,并将建立的模型与决策树和逻辑回归模型进行对比,并通过数据绘制了各自模型的ROC曲线。结果表明,在对数据分类效果上看,随机森林在预测性能上的效果要比决策树和逻辑回归模型的效果要强些。
1 随机森林算法
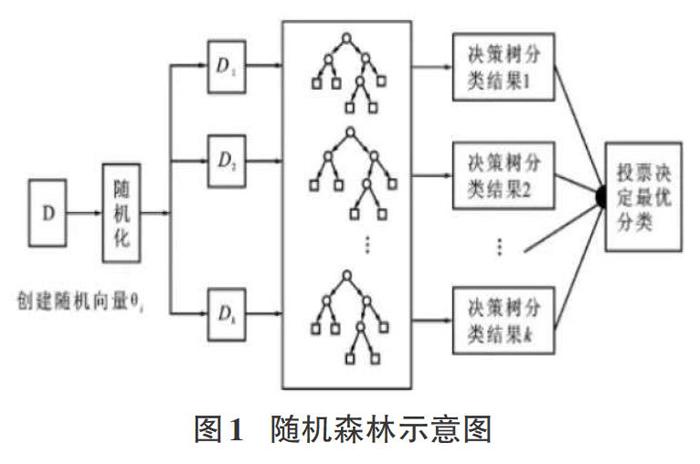
随机森林[1]是一种组合方法,由许多的决策树组成,对于每一颗决策树,随机森林采用的是有放回的对N个样本分N次随机取出N个样本,即这些决策树的形成采用了随机的方法,因此也叫作随机决策树。随机森林中的树之间是没有关联的。当测试数据进入随机森林时,其实就是让每一颗决策树分别进行分类,最后取所有决策树中分类多的那类为最终的结果。随机森林算法如图1所示。
1.1集成学习
集成学习也称为多分类器学习系统,它是结合多个分类学习器来完成学习任务来构建的。弱模型以得到一个预测效果好的强模型。对于分类问题就是指采用多个分类器对数据集进行它的一般结构是将多个个体学习器结合起来,共同发挥作用。个体学习器是通过现有的学习算法来训练数据产生。集成学习方法可分为二种,一是个体学习器间存在强依赖关系,如AdaBoost算法。而另一种是个体学习器之间不存在强依赖关系,可以同时生成个体学习器的并行方法,如随机森林算法。
1.2 随机森林算法原理
随机森林算法,包含分类和回归问题,其算法流程如下:
1)假如有N个样本,则有回放的随机选择N个样本(每次随机选择一个样本,然后返回继续选择)。这选择好了的N个样本用来训练一个决策树,作为决策树根节点处的样本。
2)当每个样本有M个属性时,在决策树的每个节点需要分裂时,随机从这M个属性中选取出m个属性,满足条件m<
3)决策树形成过程中,每个节点都要按照步骤2来分裂(很容易理解,如果下一次该节点选出来的那一个属性是刚刚父节点分裂时用过的属性,则该节点已经达到了叶子节点,无须继续分裂)。一直到不能再分裂为止,注意整个决策树形成过程中没有剪枝。
4)按步骤1-3建立大量决策树,如此形成随机森林。
从上边的步骤可以看出,随机森林每棵树的训练样本是随机的,数中每个节点的分类属性也是随机选择的,这2个随机的选择过程,保证了随机森林不会产生过拟合现象。
2 数据处理
本文使用python语言实现了随机森林算法的整个流程,数据集采用的是UCI数据集上心脏病数据,为了在此数据集上验证随机森林算法的有效性,使用随机森林算法对该数据集进行预测研究。
2.1 数据预处理
首先对本实验中用到的心脏病数据集进行预处理,对数据集中数据变量名、数值分布和缺失值情况等等有初步了解。本数据集有14个特征。对数据集中类别变量不是数值型的数据需要将类别型变量转换为数值型变量。本文采用独热编码为每个独立值创建一个哑变量[2]。对特征中非连续型数值胸痛类型(cp)运动高峰的坡度(slope),血液疾病(thal)三个分类型特征进行哑变量处理。采用的是pandas对one-hot编码的函数pd.get_dummies0。然后对数据集进行分割,把数据切分为训练集和验证集,使用train_test_split0函数,将25%的数据用于验证。
X_train, X_test, y_train, y_test= train_test_split(X,y, test_sizr=0.25,trandom_state=6),并对切分后的数据用函数standardScaler.transform0进行归一化处理。
2.2 特征选择
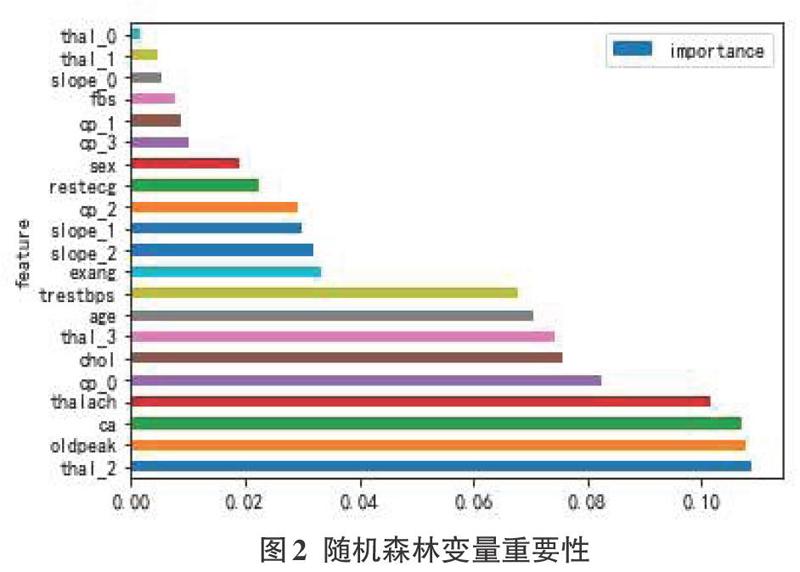
特征选择是为了构建模型而选择相关特征(即属性、指标)子集的过程。指从数据集中已有的M个特征中选择N个特征(M>N),也就是从原始特征中选择出一些最有效特征以降低数据集维度的过程,最后使系统的指标最优化。本文使用随机森林算法得到的特征变量重要性,通过特征变量比较图对特征进行排序,可以剔除不重要的特征。
由图2可得出,thal_2(地中海贫血的血液疾病)、oldpeak(相对于休息的运动引起的ST值)与ca(血管数)这三个特征比其他特征重要性高。可以使用此方法来提取对模型重要的特征,剔除不重要的特征来提高模型的预测效果。
3 模型创建与评估
本实验采用的是随机森林算法对数据进行建模,采用py-thon语言平台Anaconda3实现。在模型训练中,对模型效果的验证寻找合适的参数主要有K折交叉验证、参数网格搜索以及训练集、验证集和测试集的引入等方法。这里采用的是参数网格搜索法为模型寻找更优的参数。在参数搜索过程中,主要使用的函数为GridSearchCVO。通过此方法,可以得到随机森林如下的最优参数:
n_estimators=500, max_leaf_nodes=16, random_state=666.oob_score=True,n_jobs=-l
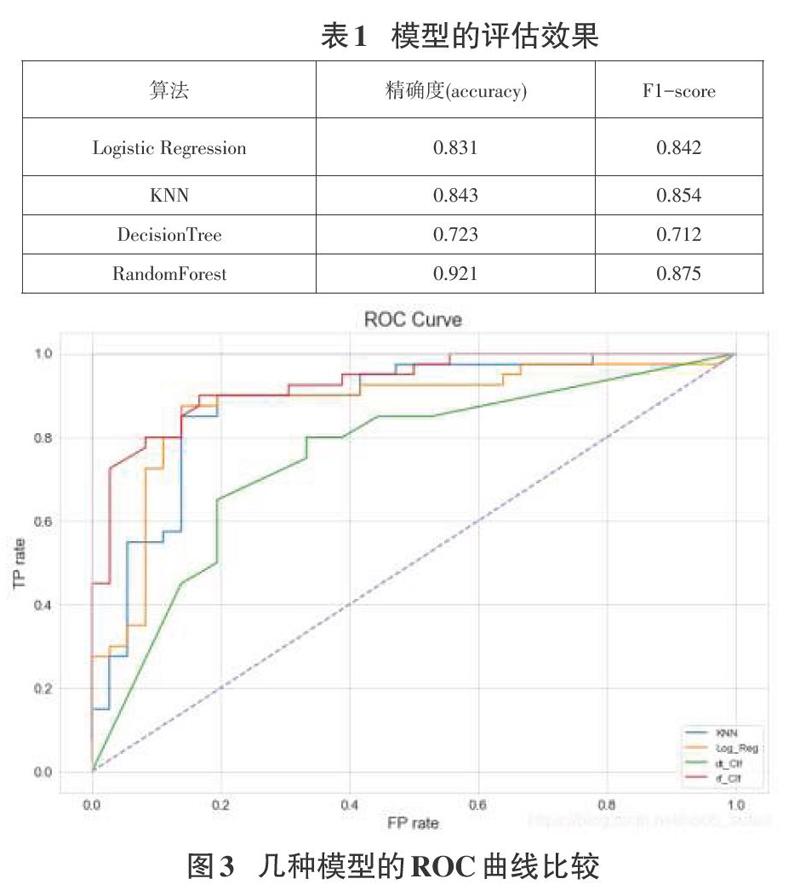
為了更好地验证随机森林的模型性能,本文将逻辑回归,KNN,决策树作为对比模型,并通过F1指标,混淆矩阵,精准率和召回率曲线,绘制每个模型的ROC曲线进行对比,用对比图来对各个模型的效果进行评估。采用ROC曲线下的面积(area un-dercurve.AUC)作为模型性能指标,以下是实验得到的精确度、F1-score及ROC曲线图。
通过图3中的几种模型的ROC曲线比较中,可以得到,Lo-gistic Regression算法下的AUC值这0.8785,KNN下的AUC值为0.8739.DecisionTree算法下的AUC值为0.7527,RandomForest算法下的AUC值为0.9356。对于UCI心脏病数据集的分类效果来看,随机森林的分类的效果更高些。
5 结论
本文对随机森林算法在分类问题上的应用进行了研究,并且对UCI数据集上心脏病数据进行预测,通过实验验证证明此算法有着很好的分类作用。下一步的研究工作是针对随机森林算法的超参数调优寻找更好的方法。
参考文献:
[1]马骊,随机森林算法的优化改进研究[D].广州:暨南大学,2016:43-49.
[2]李河,麦劲壮,肖敏,等.哑变量在Logistic回归模型中的应用[J].循证医学,2008,8(1): 42 - 45.
[3]李毓,张春霞.基于out-of-bag样本的随机森林算法的超参数估计[J].系统工程学报,201 1,26(4):566-572.
[4]曹正凤.随机森林算法优化研究[D].北京:首都经济贸易大学。2014:29-34.
[5]王日升.基于Spark的一种改进的随机森林算法研究[D].太原:太原理工大学,2017:39-47.
[6]夏涛,徐辉煌,郑建立.基于机器学习的冠心病住院费用预测研究[J].智能计算机与应用,2019,9(5):35-39.
[6]冯晓荣,瞿国庆,基于深度学习与随机森林的高维数据特征选择[J].计算机工程与设计,2019,40(9):2494-2501.
[7]杨长春,徐筱,宦娟,等,基于随机森林的学生画像特征选择方法[J].计算机工程与设计,2019,40(10):2827-2834.
[8]吕红燕,冯倩.随机森林算法研究综述[J].河北省科学院学报,2019,36(3):37-41.
[9]梁琼芳,莎仁.基于随机森林的数学试题难易度分类研究[J].软件导刊,2020,19(2):122-126.
【通联编辑:唐一东】
收稿日期:2020-03-15
基金项目:海南省教育科学规划课题:基于一种自学习分类算法的学生成绩评价研究( QJY20181071);海南省高等学校教育教学改革研究项目(Hnjg2020-31);海南省自然科学基金项目(2019RC182)
作者简介:吴兴惠(1975-),女,海南儋州人,海南师范大学副教授,硕士,机器学习;通讯作者:邢海花(1976-),女,海南文昌人,海南师范大学教授,博士,智能空间信息处理。
