基于道路法规知识图谱的多轮自动问答研究
2020-08-19陈金菊王义真欧石燕
陈金菊 王义真 欧石燕

摘 要:[目的/意义]传统的基于知识图谱的自动问答研究主要是针对用户提问直接检索答案,但由于系统对用户问题的理解存在歧义,导致得到的答案不够精确。采用基于知识图谱的多轮自动问答可以有效地改善这一问题。[方法/过程]本文首先构建了以事件为中心的道路法规本体模型,依据该模型从道路法规中抽取实例图谱,并设计出基于道路法规知识图谱的问答框架。然后,对该框架所使用到的模型进行测评。最后,进行系统的总体测评。[结果/结论]从模块测评结果来看,本文所提出BCNN_BiLSM模型在事件识别和意图识别的F1值分别是0.798和0.930,BBiLSTM_CRF模型在本体属性识别F1值为0.807,总体性能优于其他模型。系统的总体测评结果表明,完整句的准确率为0.74,缺省句的任务完成率为0.83。本文提出的基于道路法规知识图谱的多轮自动问答可为相关领域自动问答研究提供参考。
关键词:知识图谱;本体;多轮自动问答;自然语言处理;道路法规
Abstract:[Purpose/Significance]The traditional researches on knowledge-based automatic question answering aim to retrieve answers for user questions directly.However,due to the ambiguity of the systems understanding of the questions proposed by users,the answers obtained are not accurate enough.The use of multiple-round of automatic question answering based on knowledge graph can effectively improve this situation.[Method/Process]This paper firstly constructed an event-centered road regulation ontology model,based on which the sample graphs are extracted from the road regulations.And a question answering framework based on the knowledge graph of road regulations is designed.Then the model used in the framework was evaluated.Finally,an overall evaluation of the system was carried out.[Result/Conclusion]From the results of the module evaluation,the F1 values of the event identification and intent recognition of the BCNN_BiLSM model in this paper were 0.798 and 0.930 respectively,and the F1 value of the ontology attribute identification of the BBiLSTM_CRF model in this paper was 0.807,and the overall performance was better than other models.The overall evaluation results of the system showed that the accuracy of the complete sentence was 0.74,and the task completion rate of the default sentence was 0.83.The multi-round automatic question answering based on the knowledge graph of road regulations proposed in this paper can provide reference for the automatic question answering studies in related fields.
Key words:knowledge graph;ontology;multi-round automatic question answering;natural language processing;road regulations
近年來,道路交通事故频发。面对交通事故,人们需要及时了解和获取相关的法律处理方式及可能承担的法律后果,这往往需要参考大量的道路法律法规及其相关文献等。这些道路法规信息大多以非结构化的形式存储在不同的数据库和网络平台上。目前,人们获取道路法规信息的主要途径有搜索引擎(如百度、谷歌等)、专门的法律法规数据库(如中华人民共和国司法部的法律法规数据库[1]和中国法律法规信息库[2]和专业的社会化网络问答社区(如110法律咨询中心[3]和华律网[4]等。但由于这些方式是基于字符串进行检索,不能精确地理解用户的查询意图,导致查准率比较低。因此,如何从海量的道路法规信息中快速有效地获取符合用户需求的高质量信息已成为一个亟待解决的问题。自动问答系统允许用户以自然语言进行提问,精确地表达自己的信息需求,为用户精确地获取道路法规信息提供了一种有效的解决途径。自动问答系统主要分为两类:基于文本(Text-based)的自动问答和基于知识(Knowledge-based)的自动问答。前者是将用户的自然语言提问转换成查询词,然后利用文本检索技术从文本库中检索到相关文档,再从文档中提取出精确的答案,由于这种自动问答方法需要较高的自然语言处理技术作为支撑,因此无法支持复杂的查询。而后者则是将自然语言提问转换为结构化查询语言,再从结构化的知识库中直接获取答案,因此能够支持复杂的查询。随着人工智能和知识图谱技术的发展,基于知识图谱的自动问答逐渐成为基于知识库的自动问答的研究主流。传统的基于知识图谱的自动问答研究主要是针对用户提问直接检索答案,但由于缺乏问答系统与用户之间的交互,使得系统对用户问题的理解存在歧义,导致得到的答案不够精确。因此,基于知识图谱的多轮自动问答逐渐成为一种趋势,通过系统与用户的进一步交互来精确地理解用户的查询意图,有效地提高了查准率。目前,基于知识图谱的自动问答在道路法规领域仍处于起步阶段。因此,本文首先构建了以事件为中心的道路法规本体模型,依据该模型从道路法规中抽取实例图谱。在此基础上,设计出基于道路法规知识图谱的问答框架,并对该框架所使用到的模型进行测评。最后,对所构建的基于道路法规知识图谱的多轮自动问答系统进行总体测评。
目前,已出现一些道路交通事件本體的相关研究和项目,譬如W3C的交通事件本体社区小组(Traffic Event Ontology Community Group)开发了一个用于表示道路或交通事件(事故)的本体项目,但目前该项目仍在建设中,无法获取相关本体[18];刘吉双构建了一个以行为、条件、交通事件、位置、对象、人员、处罚、交通设施和车辆为核心要素的道路交通事件本体[19],Marupudi S B构建了一个以事件、地点、时间等要素为核心的交通事件本体[20],于云构建了以车辆、道路、人、道路景观为核心的交通领域本体[21]。这些本体都对道路交通事件的某些方面进行了描述,部分要素(如事件、时间、地点、人、车辆和处罚等)的设计可为本文的本体设计提供一定的参考,但是并不能完全满足本文的需求,一方面它们的内容不全面;另一方面也未能反映道路交通事件及其相关事件要素之间的语义关系。因此,本文在参考相关研究的基础上,根据道路法规的特点,以简单事件模型(Simple Event Model,SEM)为基本框架,通过对SEM内容的丰富或扩展来构建道路法规本体。SEM本体由荷兰阿姆斯特丹自由大学语义网小组的Hage W V等设计开发,用于对不同学科领域的事件进行建模[22]。SEM本体较全面地描述了一个事件的基本要素,以事件(Event)为核心,事件涉及的相关要素有事件的类型(Type)、参与者(Actor)、发生地点(Place)、发生时间(Time),其中参与者在事件中可能扮演不同的角色(Role)。该本体还对其定义的主要类的具体类型进行区分,例如事件的具体类型(sem:EventType)有会议、音乐会、突发事件等。在我们的研究中,我们复用了SEM本体的基本要素,对于SEM本体无法描述的实体和关系,一方面复用了Event、FOAF、TIME和GEONAMES等通用本体的类和属性;另一方面构建了一些新的类和属性。最终得到的道路法规本体如图1所示(命名空间为“rore”)。
道路法规本体以道路交通事件(sem:Event)为核心,本文根据道路交通事件所导致的后果的严重程度,将交通事件分为两类:一般交通事件(rore:GeneralTrafficIncident)和交通事故(rore:TrafficAccident),前者是指车辆在道路上因过错或者意外导致的、未造成人身伤亡的事件,后者则是指车辆在道路上因过错或者意外造成人身伤亡或者财产损失的事件。这些事件之间可能存在的关系有从属关系(sem:subEventOf)、因果关系(rore:result)和时序关系(rore:next)。从属关系是指交通事件之间的整体与部分关系,因果关系是指某一交通事件的发生导致了另一交通事件的发生,时序关系是指交通事件在时间上的先后发生关系。交通事件具有(sem:hasActor)参与者(sem:Actor)、发生时间(sem:Time)和发生地点(sem:Place)3个基本要素。参与者是指事件涉及的主体,主要包含人(foaf:Person)、机构(foaf:Organization)和物体(sem:Object)3个子类。其中,人主要指交通事件的当事人(rore:Party),主要包括肇事者(rore:Perpetrator)和受害者(rore:Victim)两类。交通事件涉及的物体主要指当事车辆(rore:Vehicle)。本文参考《中华人民共和国道路交通安全法》,将车辆类型分为机动车(rore:MotorVehicle)和非机动车(rore:NonMotorVehicle)[23]。事件的参与者有主动参与和被动参与两种情况,因此本文在“hasActor”属性下设置两个区分主动和被动参与者的属性:“hasActiveActor”和“hasPassiveActor”。人或机构可能通过某一动作作用于(rore:hasAction)物体,同时人可能是某个机构的成员(org:memberOf)。事件具有(sem:hasTime)的发生时间可以复用时间本体TIME[24]的时间实体类(time:TemporalEntity),以及“time:Instant”和“time:Interval”两个子类对时间点和时间段进行区分。事件具有(sem:hasPlace)的发生地点(sem:Place)可以复用地理信息本体GEONAMES的地理特征点类(gn:Feature)进行识别[25]。
道路交通事件发生后,可能会造成人和物的损失,前者涉及(rore:involve)当事人状态(rore:PersonStatus)和通过鉴定(rore:identify)得到的伤情(rore:hasInjuryState),后者包括损坏(rore:hasDamage)的财产损失情况(rore:DamageState)。当事人状态主要包含医学鉴定结果(rore:MedicalIdentificationResult),而伤情除了包含医学鉴定结果外,还包含伤残鉴定结果(rore:DisabledAppraisalResult)和伤情鉴定结果(rore:InjuryIdentificationResult)。财产损失情况通常有不同的损坏对象(rore:hasObject),根据损坏对象不同,可以将损失情况分为车辆损失(rore:VehicleDamage)和货物损失(rore:CargoDamage)两类。根据人的伤害情况和物的损失情况,交警或法院会对涉事当事人进行判责(rore:judge),判责结果(rore:JudgementResult)主要包括主要责任、次要责任、全部责任和无责任。根据判责结果,交警或法院会对涉事当事人进行处罚(rore:punish),处罚结果(rore:PunishmentResult)主要分为行政处罚(rore:AdministrativePunishment)、刑事处罚(rore:CriminalPunishment)和民事处罚(rore:CivilPunishment)。当事人状态、伤情、财产损失情况、判责结果和处罚结果都有接受对象(sem:isActorOf),通过该属性的3个子属性“rore:isPersonOf”“rore:isOrganizationOf”和“rore:isObjectOf”分别与人、机构和物体3类不同的接受对象进行关联。
上述类包含的主要术语如表1所示。
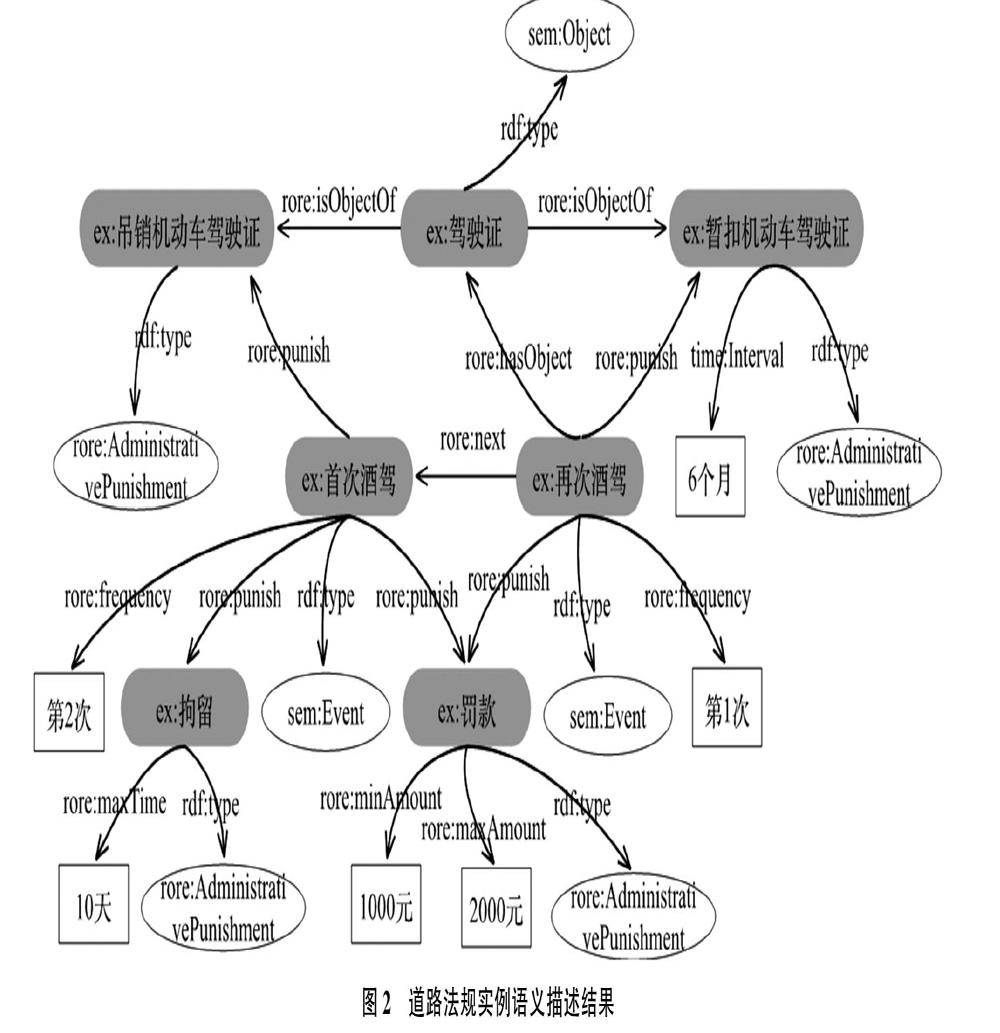
根據上述构建的道路法规本体,本文以《中华人民共和国道路交通安全法》为例,选取第九十一条规定的部分内容进行语义描述,该内容片段为“饮酒后驾驶机动车的,处暂扣六个月机动车驾驶证,并处一千元以上二千元以下罚款。因饮酒后驾驶机动车被处罚,再次饮酒后驾驶机动车的,处十日以下拘留,并处一千元以上二千元以下罚款,吊销机动车驾驶证。”[23]。该规定主要涉及2个“酒驾”事件,事件涉及的物体主要有“驾驶证”,酒驾事件导致的行政处罚结果有“暂扣机动车驾驶证”“吊销机动车驾驶证”“拘留”和“罚款”,其中暂扣机动车驾驶证时间为6个月,拘留天数为10天以下,罚款数额均为1 000元以上2 000元以下。该法规的语义描述结果如图2所示。
基于上述设计的本体,以HTML格式的道路交通法规相关文本作为数据源,构建道路法规知识图谱。本研究将知识提取的任务划分为实体提取、关系提取、属性和属性值提取,并将抽取到的知识用三元组的形式表示:1)实体—关系—实体(Ehead,R,Etail),R是实体Ehead和实体Etail之间的关系,如:驾驶人—驾驶—机动车;2)实体—属性—属性值(Entity-Attribute-Value),属性是描述实体的数据,如“机动车—定义—以动力装置驱动或者牵引,上道路行驶的供人员乘用或者用于运送物品以及进行工程专项作业的轮式车辆”,属性值有数据类型的约束,常用的数据类型有:文本型、数字型、逻辑型、枚举型等。
3 问答框架
道路法规知识图谱实现了道路法规各类知识的关联和整合,以专业化、结构化的方式对知识进行语义表示,是一种高效管理和利用知识的方式。在此基础上,基于构建的知识图谱提出了一种面向知识库的多轮自动问答方法。与常见的聊天机器人(如图灵、微软小冰)不同,聊天机器人主要是无特定目的的对话,本文所构建的问答系统更偏向于目标驱动的特定信息获取,它是一种具有极强的针对性和准确性的问答系统。问答系统的准确性一方面取决于知识库中所蕴含的知识的深度和广度;另一方面取决于系统对用户自然语言理解提问的理解程度。因此,多轮问答通过系统向用户进行多次追问的方式填充用户初始提问中缺失的语义信息,从而帮助系统更好地理解用户的查询意图,提高问答系统的准确率。本研究构建的基于知识图谱的多轮自动问答系统框架如图3所示,该系统框架主要包含3个部分:问题理解(Question Understanding,QU)、知识图谱查询(Knowledge Graph Matcher,KGM)和问答生成(Asking & Answering Generator,AAG)。问题理解模块的功能是对用户输入的自然语言提问进行分词、词性标注等预处理,对其中涉及的交通事件、意图、属性和属性值进行识别,将用户输入的自然语言提问转化成结构化的语义表示。知识图谱查询模块的功能是将问题的语义转换成结构化的查询,从道路法规知识图谱中查询匹配的相关信息。查询到的结果可能是直接的答案或缺失的信息,如果是答案则可以直接返回,如果是缺失的信息,问答系统会生成一个追问。
3.1 问题理解
问题理解是采用自然语言理解技术将用户输入的非结构化的提问转换成结构化的语义表示,包含预处理、本体类识别(包括事件识别和意图识别)、本体属性识别,本质是采用道路法规本体中的类和属性对用户的自然语言提问进行语义标注。
1)预处理是消除原始的文本噪声的重要手段。利用分词工具对输入文本进行一系列预处理,包括中文分词、词性标注、日期类处理、数值类处理等。其中,日期类处理是将带有日期指示词的词语转换成相应的时间格式,例如“今天”是当时的系统时间,如“2019-05-05”。在数值处理时,需要对数值单位进行自动补全和数值格式的转换。数值单位补全是指自动补全用户提问中缺省的单位,如“当事人的血液酒精含量是80”,经过数值处理之后,标准的输出为“80mg/100ml”;数值格式转换是指结合一些转换规则,将不同类型的数值表达转换成统一的数值格式,如将“20%”“百分之二十”和“百分之20”统一转换成“20%”。
2)事件识别是指识别出用户提问中的道路交通事件的实例,实例分属于两类:一般交通事件(rore:GeneralTrafficIncident)和交通事故(rore:TrafficAccident)。
3)意图识别是指识别出用户提问中所蕴含的查询意图,这些意图包括伤残鉴定结果(rore:DisabledAppraisalResult)、伤情鉴定结果(rore:InjuryIdentficationResult)、判责结果(rore:JudgementResult)、处罚结果(rore:PunishmentResult)和财产损失情况(rore:DamageState)等。
4)本体属性识别是指识别出用户提问中包含的属性和属性值,如当事人的血液酒精含量是80,其中蕴含的属性是“血液酒精含量”,属性值是“80”。
下面以“酒驾撞死一人,我报警后,交警检测出的酒精含量是120,初步判定我是全责,这种情况下怎么处罚?”为例,对其进行语义标注的结果如图4所示。
3.2 知识图谱查询
知识图谱查询主要负责对话系统的道路法规知识图谱匹配,预测系统的行为,即返回查询到的子图或者返回需要追问的属性。该模块的输入是用户的会话状态,输出是预测的行为。经由问题理解模块对用户输入的自然语言语句进行事件识别、意图识别以及属性识别,最终可以按照表2中提供的6种Cypher查询模板进行查询。
用户的自然语言问题中蕴含的事件数量分为单事件或多事件两种情形。以经由问题理解模块识别后只含有单事件为例,首先判断意图的情况,然后按照表2中的Cypher查询模版对知识图谱进行查询。其次通过结果计算查询来判断查询到的子图能否满足答案阈值,如果满足则将匹配到的子图传递到问答生成模块,否则进行属性选择计算出需要追问的属性并传递到问答生成模块。其中,结果计算是将从用户的自然语言提问中抽取的本体属性集合依次与查询到的候选子图做差集计算,然后判断差集是否满足阈值条件。属性选择有两种策略:一种是通过法务专家制定的属性权重,先追问权重相对大的属性;另一种是最小候选子图原则,将候选子图与从用户提问中抽取的本体属性做比较,先追问满足阈值的候选子图的属性。
在多事件的情况下,首先按照事件进行分组,每组有且仅有一个事件。同时,意图会被划分到与其相对应的事件组内。这样就可以将多事件情形转换成单事件单意图、单事件无意图或多意图两种情形。依次对每个事件按照图5中系统行为预测部分来进行查询匹配到的子图或选择出需要追问属性。
3.3 问答生成
问答生成包含追问生成和答案生成,前者是用于向用户继续追问待补充的语义信息,后者用于返回将用户当前提问的语义化表示与知识图谱进行匹配得到的答案。根据知识图谱的查询情况需要做出以下选择:1)追问用户:在语义缺失的情况下,通过预定义的语义模版追问用户;2)返回答案:在语义完整的情况下查询子图对应的答案,并将答案返回给用户。
在获取知识图谱查询的结果时,为了保证追问内容的可读性和可理解性,本研究根据不同的本体类或本体属性定义了不同的追问模板,根据要填充的缺失语义的不同,加上一定修饰性描述再返回给用户,显得更人性化。本研究所用到的3種追问模板包含确认事件型、确认意图型和本体属性追问型。表3是一些追问模板的样例。根据表3的内容,4.1中例子需要对“酒驾次数”进行追问,那么系统返回给用户的回复是“请问您这是第几次酒驾被查?”。
4 模块测评
模块测评主要针对问题理解模块的事件识别、意图识别、本体属性识别进行测评。问题理解的结果直接影响到查询知识图谱匹配的效果。本文实验采用的实验测评语料有两种:一种是用于问题理解的语料;另一种是根据本体从道路交通法规中抽取得到的知识图谱。其中,用于问题理解的语料共8 000条,道路法规知识图谱子图约4万个。本研究就系统的问题理解展开实验,以验证所用到模型的效果。本研究的实验环境为:操作系统为Ubuntu16.04,CPU是Intel(R) Core(TM) i7-5930K CPU @ 3.50GHz,内存为64G,GPU为3块Nvidia GTX 1080组成的小型工作站。采用的编程语言为Python,深度学习框架为Tensorflow、sklearn_crfsuite。实验选用的评价指标包括精确率(Precision)、召回率(Recall)和F1值(F1 score)。
4.1 事件识别与意图识别
本研究将事件识别和意图识别看作是文本分类的问题。文本分类采用卷积神经网络(Convolutional Neural Network,CNN)、双向长短时记忆神经网络(Bi-directional Long Short-Term Memory,BiLSTM)、BERT(Bidirectional Encoder Representations from Transformers)作为基线模型,并基于3种基线模型进行改进,改进后的模型分别是CNN_BiLSTM、BCNN_BiLSTM。
CNN模型最大的优势是对输入的句子应用滤波器提取局部特征,经过不同大小的卷积核运算产生不同的特征。从而可以提取局部最优特征。模型参数为:Embedding层的大小设置为256,最大输入文本的长度为128个字符,卷积核的大小设置分别为3、4、5,卷积核的数量为100,隐藏层大小为128,训练轮次为500,学习率为1e-3,正则项系数为1e-3,batch_size为64。
长短时记忆网络(Long Short-Term Memory,LSTM)模型是循环神经网络(Recurrent Neural Network,RNN)的一种改良模型,增加了门控机制有效避免了RNN的梯度消失问题。能够很好地学习句子远距离上下文依赖关系。BiLSTM则看作由两个不同方向的LSTM组成,两个LSTM分别从文本的正向和反向学习上下文信息,将拼接的信息作为当前时刻的输出,这样既能够解决长距离依赖,又能确保特征提取的全局性和完整性。模型参数为:Embedding层的大小设置为256,最大输入文本的长度为128个字符,隐藏层的大小为128,训练轮次为500,学习率为1e-3,正则项系数为1e-3,batch_size为64。
BERT(Bidirectional Encoder Representations from Transformers)模型是谷歌提出的基于双向Transformer构建的语言模型。它是一种基于fine-tuning迁移学习方法模型,通过改变输入和增加隐藏层来应对各种特定自然语言处理任务,不需对原来的模型作大量修改就能够很好地应用在多个NLP的任务。模型参数为:最大输入文本长度为128个字符,学习率为5e-5,batch_size为64,训练轮次为3,预训练的模型为Chinese BERT-Base(共有12编码层,768个隐藏单元,12个头部)。
本研究首先结合CNN和BiLSTM的优点,将CNN卷积的结果作为BiLSTM的输入,并将改进模型记为CNN_BiLSTM模型。模型参数设置为:Embedding层的大小设置为256,最大输入文本的长度为128个字符,卷积核大小为3、4、5,卷积核数量为128,隐藏层的大小为128,训练轮次为500,学习率为1e-3,正则项系数为1e-3,batch_size为64。
BCNN_BiLSTM在CNN_BiLSTM模型的基础上使用BERT模型的最后一层隐藏层的向量替换CNN_BiLSTM模型随机初始化向量编码。与CNN_BiLSTM相比,Embedding层变成768,最大输入文本的长度为128个字符,卷积核大小为3、4、5,卷积核数量为128,隐藏层的大小为128,训练轮次为3,学习率为5e-5,batch_size为64。
实验结果如表4所示,通过表4可以发现:相同参数模型在不同的数据集上的效果与数据集本身特点有关,如类别数量;改进模型较原生模型效果有提升;就CNN、BiLSTM、BERT相比,BERT的fine-tuning模型效果最好,这得益于BERT的大规模语料的预训练效果。
4.2 本体属性识别
本研究将本体属性的识别转化为序列化标注任务,在序列化标注的任务同样可以使用BiLSTM模型。BiLSTM输出的为属性item的分数,选择最高分数对应的属性。但BiLSTM在做实体预测的时候的缺点是无法学习到状态序列(输出的标注)之间的关系。而在实际的预测序列中是存在一定关系的,例如:在B-item输出后面不能是B-item。所以为避免这种情况发生,利用条件随机场模型(Conditional Random Field,CRF)能对隐含状态建模且学习状态序列的特点。将CRF层加在BiLSTM组成Bi-LSTM+CRF模型来做序列化标注。这样结合两种模型的优势不仅避免CRF特征工程,也避免BiLSTM错误序列状态的输出。以“高速上超速一次扣几分?”为例,经由BiLSTM+CRF模型输出可以得到“高速”对应的本体属性名为“Roadtype”,其BIO的标记为“B-roadtype,I-roadtype”。
将CRF作为基准模型,在特征選择方面使用单字、数字、字母、标点符号、Unigram、Bigram等特征。模型参数如下:l1、l2正则化系数设置为0.1,最大迭代次数为200次,梯度下降使用L-BFGS优化方法。
BiLSTM_CRF模型的参数设置如下:Embedding层的大小设置为100,最大输入文本的长度为128个字符,隐藏层的大小为128,训练轮次为500,学习率为5e-3,衰减速度为1e-4,正则项系数为1e-3,batch_size为32。
BBiLSTM_CRF则是在BiLSTM_CRF模型的基础上,使用BERT替换Eembdding,模型参数如下:Embedding层变成768,最大输入文本的长度为128个字符,隐藏层的大小为128,训练轮次为3,学习率为5e-5,batch_size为64。
实验结果如表5所示,可以发现BBiLSTM_CRF的混合模型效果最优,主要原因是结合BERT、CRF和LSTM的优势。
5 系统评测
5.1 系统实现
本研究构建的基于道路法规知识图谱的多轮自动问答系统,在具体实施的过程中,知识图谱的存储采用的是Neo4j图数据,问题理解模块的预处理阶段使用的是Jieba分词工具。此外,在问答系统中有担任“存储器”角色的模块称为对话状态跟踪,该模块为每一位用户分配一个追踪器Tracker,用以记录和维护用户所有的对话状态,包含创建、更新、删除和查找用户对话状态。实际上,对话系统中除了上述对话状态跟踪的基础作用外,往往还需要考虑在多轮交互过程中,存在的轮次打断、恢复、切换等复杂情况。因此,对话状态跟踪模块也具备对用户对话轮次的管理。本文以某一“酒驾致死”事件为例展示多轮自动问答系统,界面如图6所示,6(a)和6(b)共同组成一个完整的对话。首先,用户通过对话框输入一段与道路交通相关的法律问题,采用Web技术将用户输入的自然语言问题提交给问答后台。问答后台按照上述问答框架将用户输入的问题转化成结构化的语义表示。然后,根据知识图谱查询的结果对用户进行多轮次的追问以补充缺失的语义信息。最终,将匹配到的知识图谱子图对应的答案(包含相关法条和参考意见)返回给用户。为方便观察用户与机器之间交互的细节,表6展示了多轮次识别出来的结构化语义结果、当前轮次结束后系统的状态标示以及需要追问的属性。
5.2 系统总体评测
本研究采用200个测试问句对构建的自动问答系统进行总体的实验测评,其中包含100个完整句和100个缺省句,前者只需要系统完整识别出其语义表示,再通过知识图谱的查询就能得到答案,而后者则是需要用户和系统进行多次交互补充缺失的语义才能得到答案。
目前,还没有一套权威的多轮自动问答评价方法能完全客观的评价多轮自动问答系统的效果。本研究中完整句的测试评价指标采用的是准确率(Accuracy),问题中所有的本体类和本体属性都正确识别才算当前问题被正确识别。缺省句的评价指标采用的是任务完成率(任务完成率=成功结束的多轮会话数/多轮会话总数),成功结束的对话数量越多,则认为任务完成率相对较高,从而多轮对话的可用性也可能更好。但需注意的是,对话成功结束,并不一定意味着用户提出的问题得到正确解决,也有可能是用户从问答系统中得到了错误的答案。此外,在缺省句的评价指标中对前3轮对话满意度进行打分,后一轮的结果是基于上一轮的结果基础上进行评价的,即对前一轮结果不满意,则对后一轮结果也不满意。在系统的总体评测中,事件识别和意图识别选用的是BCNN_BiLSM模型,本体属性选用BBiLSTM_CRF模型,其参数与上述参数保持一致。最终得到完整句的准确率为0.74,缺省句的任务完成率为0.83。
6 结论与展望
针对当前自动问答系统以单轮问答为主,交互性差,难以准确地获取用户真实检索意图的问题,本文提出了一个基于道路法规知识图谱的多轮自动问答系统。首先,利用道路法规数据构建了道路法规本体和知识图谱,在此基础上构建了多轮自动问答系统框架,并进行了模块测评。其中,事件识别和意图识别的测评结果表明,相同参数模型在不同的数据集上的效果与数据集本身特点有关;改进模型(BCNN_BiLSTM和CNN_BiLSTM)较原生模型效果有所提升;就CNN、BiLSTM、BERT相比,BERT的fine-tuning模型效果最好。本体属性识别的测评结果表明,BBiLSTM_CRF的混合模型效果最优。最后,对所构建的基于知识图谱的多轮自动问答系统进行系统测评,最终得到完整句的准确率为0.74,缺省句的任务完成率为0.83。本研究在一定程度上弥补了基于知识图谱的自动问答在多轮问答方面的空缺,以及基于知识图谱的多轮自动问答在法律领域的应用空白,对于垂直领域的自动问答系统构建具有一定的借鉴意义。
虽然本文实现了多种有效的自然语言理解模型和事件匹配策略,但是本文提出的方法仍存在一定的不足,特别是面对复杂语义、图谱缺失等问题,仍然有很多可以改进的工作。一方面是通过替换和调整模型的超参数来提高识别的准确率;另一方面通过不断扩充事件图谱的规模来提高系统回答的广度和深度。
参考文献
[1]中华人民共和国司法部的法律法规数据库[EB/OL].http://search.chinalaw.gov.cn/search2.html,2019-04-15.
[2]中国法律法规信息库[EB/OL].http://law.npc.gov.cn/FLFG/index.jsp,2019-04-15.
[3]110法律咨询案例[EB/OL].http://www.110.com/ask/question-14503043.html,2019-08-04.
[4]华律网[EB/OL].https://www.66law.cn/,2019-04-15.
[5]温思琦.基于本体的中医冠心病自动问答系统的设计与实现[D].沈阳:沈阳工业大学,2017.
[6]Lopez V,Pasin M,Motta E.Aqualog:An Ontology-portable Question Answering System for the Semantic Web[C]//European Semantic Web Conference.Springer,Berlin,Heidelberg,2005:546-562.
[7]劉晓强.基于领域本体的客服问答系统的设计与实现[D].青岛:青岛大学,2016.
[8]Lexinfo本体[EB/OL].https://lexinfo.net/,2019-04-17.
[9]Unger C,Cimiano P.Pythia:Compositional Meaning Construction for Ontology-based Question Answering on the Semantic Web[C]//International Conference on Application of Natural Language to Information Systems.Springer,Berlin,Heidelberg,2011:153-160.
[10]Ferrández O,Izquierdo R,Ferrández S,et al.Addressing Ontology-based Question Answering with Collections of User Queries[J].Information Processing & Management,2009,45(2):175-188.
[11]Abdi A,Idris N,Ahmad Z.QAPD:An Ontology-based Question Answering System in the Physics Domain[J].Soft Computing,2018,22(1):213-230.
[12]陈文聪.面向自动问答的游客问题语义模型研究[D].成都:电子科技大学,2018.
[13]陶杰.住房公积金领域自动问答系统关键技术研究[D].哈尔滨:哈尔滨工程大学,2018.
[14]温思琦.基于本体的中医冠心病自动问答系统的设计与实现[D].沈阳:沈阳工业大学,2017.
[15]钱宏泽.基于中草药语义网的自动问答系统的研究与实现[D].杭州:浙江大学,2016.
[16]郭磊.基于领域本体中文自动问答系统相关技术的研究与实现[D].广州:华东理工大学,2013.
[17]曹存根.国家知识基础设施的意义[J].中国科学院院刊,2001,(4):255-259.
[18]Traffic Event Ontology Community Group[EB/OL].https://www.w3.org/community/traffic/,2019-04-15.
[19]刘吉双.基于语义内容的交通监控视频检索研究[D].重庆:重庆大学,2018.
[20]Marupudi S B.Framework for Semantic Integration and Scalable Processing of City Traffic Events[EB/OL].https://corescholar.libraries.wright.edu/cgi/viewcontent.cgi?article=2718&context=etd_all,2019-04-15.
[21]于云.基于本体和描述逻辑的交通事件语义表现方法研究[D].淄博:山东理工大学,2015.
[22]Hage W V,Malaisé V,Segers R,et al.The Simple Event Model Ontology[EB/OL].http://semanticweb.cs.vu.nl/2009/11/sem/,2019-04-15.
[23]中华人民共和国道路交通安全法[EB/OL].http://www.npc.gov.cn/npc/c12488/201104/e8b92a43e3914a959a7cee369e486a 62.shtml,2019-04-15.
[24]Time Ontology in OWL[EB/OL].https://www.w3.org/TR/owl-time/,2019-04-15.
[25]WICK M.The GeoNames Geographical Database[EB/OL].http://www.geonames.org/,2018-04-15.
(责任编辑:陈 媛)
