基于Simhash的协议数据高频相似序列提取算法
2020-08-19黄学波徐正国燕继坤
黄学波,徐正国,燕继坤
盲信号处理国家重点实验室,成都 610041
1 引言
随着互联网应用和传输的数据类型日趋繁杂,网络中出现的协议种类越来越多且越来越复杂。出于网络安全考虑,网络服务提供商和网络管理者更加依赖于网络协议分析技术。协议特征提取技术是相关研究的基础之一,而传统的依赖人工进行的协议特征提取工作已经越发捉襟见肘[1]。在此背景下,自动化的网络协议分析技术成为了研究的热点。
在协议逆向工程和深度包检测等网络协议分析技术的相关研究中,高频相似序列的提取是一种常用的技术手段,应用于协议特征提取、协议分类与聚类、格式规范挖掘等。高频相似序列是指同一协议中出现的大量相同或相似的局部序列。在一种协议中,协议字段中除了部分取值随机性较强的字段之外,大部分字段的取值都在一定范围内,这些取值表示了协议的不同类别、状态、标记等信息,可以作为该协议的一种特征并用于后续的协议分析。
在协议特征挖掘的相关研究中,提取协议特征关键词主流方法采用的是高频相似序列提取。协议特征关键词是指协议报文序列中可以区分协议类型的比特序列[2],有些研究中也称为语义关键词[3]、协议token[4]、特征字符串[5]等。高频相似序列提取通常有两种不同的实现方式:一是采用基于频率统计的频繁集挖掘方法;二是采用序列相似性比对方法。
基于频率统计或频繁集挖掘的方法由于其算法的高效性,应用比较广泛。琚玉建等人[6]提出的基于自适应权值的指纹特征提取算法通过频繁序列挖掘得到协议的指纹特征,类似的还有蔡乐等人[7]提出的基于关联规则挖掘的协议特征提取算法。基于频率统计的方法虽然在一些情况下能够取得较好的效果且效率较高,但在处理含有变长或位置不定字段时效果较差。
序列对齐是序列相似性比对中常用的方法,通过将协议数据两两比对得到高频相似序列和出现的位置。序列对齐的经典算法是多序列比对算法,最早是由Beddoe[8]将其从生物信息领域应用到了著名的协议逆向项目PI[8]中,该项目使用了Smith-Waterman 算法。除此以外,其他一些协议逆向工具比如netzob、ScriptGen[9]中还用到了Needleman-Wunsch等序列比对方法。该类方法的问题是,对于大量协议报文序列来说,将每一个序列都与其他序列进行比较的计算复杂度是非常高的。例如使用Needleman-Wunsch 算法进行多序列比对,假设有M个序列,平均长度为N,当M=5 000,N=1 000 时需要次比较[10]。
针对上述问题,本文提出了一种用于网络协议分析的高频相似序列提取算法。该算法针对协议序列特点将用于文本处理的Simhash算法做了改进,在拥有较高执行效率的同时也能够达到较高准确率。
2 Simhash算法简介
传统的哈希算法将任意长度的输入变换为固定长度的输出,内容相近的输入得到的输出相差一般较大。但是在某些应用领域中需要将相似的输入映射为相似的输出,即满足:
(1)d(x,y)≤d1时P(H(x)=H(y))≥p1;
(2)d(x,y)≥d2时P(H(x)=H(y))≤p2。
其中d(x,y)表示x与y的距离,P表示概率,H表示哈希函数。符合上述条件的一类哈希算法称为局部敏感哈希(Local Sensitive Hash,LSH)算法。根据LSH算法的特性,两个任意长度序列之间的相似度比较被转换为长度较短的哈希值之间的比较,在数据量较大时可大幅提高比较的效率。
Simhash 是 由 Charikar 等 人[11]提 出 的 一 种 LSH 算法,而后被谷歌的Manku 等人[12]应用到网页去重中,在处理海量的文本数据时有较好的效果。此外,Simhash还应用于生物测序数据去重[13]、多媒体数据检索[14]、恶意代码检测[15]等领域。
Simhash 算法的主要思想是降维,即将高维的特征向量映射为一定比特长度的指纹,通过比较指纹的海明距离来确定原始序列的相似性。该算法应用在文本处理中的流程可概括为:
(1)分词:将文本转换为特征向量,由文本中的词(即特征)加权后按顺序排列组成;
(2)计算哈希:对于特征向量集中的每一个特征,用传统哈希函数计算得到f比特的哈希值H;
(3)加权:对每一个特征,初始化一个f比特的向量v,若H的第i位为1,则向量v的第i位加上该特征的权值,否则减去该特征的权值;
(4)合并、降维:初始化一个f比特的向量V,将特征向量集中按上述步骤得到的所有向量v累加,若累加后的第i位为正数则向量V的第i位为1,否则为0,向量V即为文本的Simhash指纹。
协议二进制序列与文本的主要区别是二进制序列无法进行分词,并且长度可能较短。若要将Simhash算法应用于协议序列,需要根据文本与二进制序列的差异对算法进行修改。
3 高频相似序列提取算法
3.1 数据预处理
相比协议载荷部分,协议头部包含了协议数据中的主要特征,因此本文研究对象是协议报文序列的头部。在头部长度未知的情况下,本研究根据实际经验截取固定长度的头部序列作为后续研究的输入。
协议报文序列在无任何先验知识的条件下不存在“分词”的概念,也没有其他自然的划分依据,需要自行设计划分方法。对文本数据来说,计算Simhash的粒度通常是整段话或整个文章,但在一个协议报文的二进制序列中,高频相似序列的提取是要找出相似性较高的局部序列,而不是比较整个报文序列的相似性。因此需要将协议报文序列分割为许多局部序列,对应“文本”的概念,然后再对它们进行“分词”。
这里首先采用自然语言处理中的n-gram方法将序列分割,该方法在协议特征提取中也有较多的应用[16]。例如序列0x12345按n=3 可分割为集合{0x123,0x234,0x345},集合中的每一个元素对应着一个“文本”。然后再对每一个“文本”进行分词,同样使用n-gram 的方式以更小的粒度切分。
通过上述方式,完成了对协议数据报文序列的预处理,将每个序列对应于文本分词的处理方式进行了分割。假设原始数据有m个报文序列,预处理步骤总结如下:
(1)截取每个序列的前N个字节,得到大小为m×N的原始数据矩阵Morigin;
(2)对Morigin的每一行数据按n-gram方式分割(单位为字节),n=n1,得到大小为m×(N-n1+1)的“文本”矩阵Mtext;
(3)对Mtext中的每一行“文本”按n-gram方式分割(单位为比特),n=n2,得到m×(N-n1+1)×(n1×8-n2+1)个“词”,记为Mword。
整个预处理流程如图1所示。

图1 数据预处理流程图
3.2 二进制序列的Simhash算法
要将Simhash 算法应用在二进制数据处理中,除了文本分词外,还需解决算法实现过程中的其他问题。首先在文本去重问题中,Simhash 算法对于不同的词可以设置不同的权值用以表示词的重要程度。在二进制序列中,各个字节之间没有重要程度之分,即权值都为1。
通常用Simhash 处理的一条文本数据中包含的词的数量往往远远大于本文算法中的“分词”数量。Simhash原始算法将文本数据映射为64 比特长度的指纹序列,由于文本维数很高,这样的映射是合理的。但根据前文的预处理方法,一条“文本”的维数往往小于64,因此为了符合二进制“文本”的特点同时提高计算性能,将指纹长度降低。这里取1 字节即8 比特,即大部分协议字段长度的最小单位。
本文提出的适用于二进制协议报文序列的改进Simhash算法如下:

通过上面的改进Simhash算法,得到了所有“文本”的Simhash值矩阵Msh,其中每一个元素是8维的0-1向量。为了比较相似性,最常用的方法是比较它们的海明距离。本文的序列提取衡量指标除了相似性之外还有高频特征,可以先根据上述算法的结果确定哪些二进制序列是高频的,然后再考查高频序列对应的Simhash值之间的相似性,这样也可以减少比较次数,提高算法性能。在得到了所有的高频相似序列之后,再在原始数据中找出对应的二进制序列,并将相邻的序列拼接即得到最后的结果。整体的算法流程如下:

序列拼接是指将多个在位置上有重叠部分的序列合并成一个序列的过程。拼接可以减少结果序列数量,但待拼接序列的重叠部分的取值不一定相同。为了提高算法效率,这里采用较为简单的处理方式,即将取值不同的位置用通配符代替,表示该位置的取值不确定。比如有两个序列开始位置为0与3,取值分别为abcdefg和aefbh,拼接后的序列为abc*ef*h。
该二进制序列的Simhash算法与传统的文本Simhash算法相比,指纹长度更短且指纹间的比较次数更少,在本文的问题上可以达到更好的效果。
3.3 评价指标
Simhash算法的优势在于处理海量文本数据的高效性,并且已经在实际应用中得到验证,但该算法在本文的问题上还没有公认的评价标准。除了算法的时间复杂度外,为了评价算法的有效性,本文还提出一种评价指标来评估算法的准确程度。
首先要确定评价指标的比较基准。本研究选取已知协议各字段的实际取值作为高频相似序列提取正确与否的参考基准。这是由于协议报文头部字段中含有的控制信息通常会重复出现在协议通信数据中而成为高频序列。
计算基准的高频序列时,先将原始的报文数据按真实的字段划分切分,对每一个字段统计其取值范围,若一个字段的一种取值出现次数高于指定的阈值,则认为是高频序列,且同一个字段可能有多个高频序列。这样得到的高频序列的集合S={s1,s2,…,sq}就可以作为评价的基准。
本文的高频相似序列覆盖率定义为:

其中,|· |表示序列长度,T={t1,t2,…,tp}为Simhash算法得到的高频相似序列。表示两个序列的交集长度,即相同位置出现相同值的个数(含有通配符时视为是相同值),一方面反映了两个序列位置上的准确性,另一方面反映了序列取值的偏差程度。根据定义可知,覆盖率的取值范围为[0,1],S中的所有元素都能被T中的元素完全覆盖时取1,都不能覆盖时取0。该指标可以在一定程度上反映高频相似序列提取结果的准确率。
4 实验与分析
4.1 对比算法
为了更好地对比算法性能,在实验中选择与另外两种在网络协议分析中较为常见的算法进行比较。
首先是基于n-gram的频率统计算法。该算法先将数据按n-gram 方式切分,然后对每个序列片段出现的频率进行统计,频率大于阈值则认为是高频序列,最后将相邻的高频序列拼接。这种算法因为实现简单,所以处理效率很高,但在处理字段长度可变协议和文本协议时效果不好,并且只计算了完全相同而不是相似的序列。
第二种算法是基于Needleman-Wunsch 算法(简称NW算法)的序列比对算法。该算法通过计算两个序列的最长公共子序列,可以实现序列对齐、相似性比较等功能。比如有两个字符串序列aabcdab和abbccdbaccb,它们通过该算法得到的最长公共子序列为a*b*cd*a**b,*表示不匹配的位置。由于该算法的比对结果长度为两个序列的最大长度,本文要计算的高频相似序列为局部序列,故将比对结果切分为若干子序列,分割依据是连续出现*的个数大于阈值时则分割。该算法对于字段位置不敏感,准确率较高,但算法效率较低。
4.2 实验环境与数据集
本文的实验环境及其配置如表1 所示。实验数据均为在某校园骨干网和实验室网络环境下采集的网络协议数据。通过wireshark网络协议分析工具提取了常见的四种二进制协议和一种文本协议,如表2所示。
由于http协议的报文数据并不一定都有协议头,甚至是只包含非文本的载荷,为了在实验中测试本文算法在二进制协议和文本协议中的效果,http协议数据选择了只含有文本协议头的数据。

表1 实验环境及配置
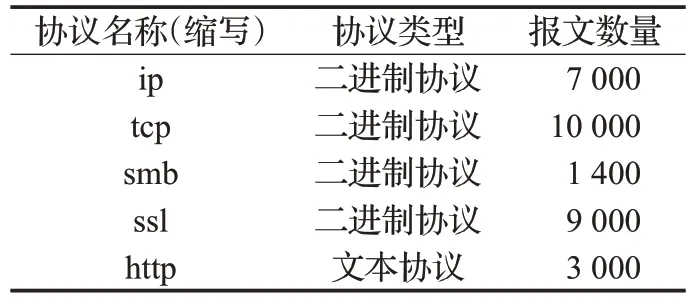
表2 实验数据
4.3 参数选择
在数据预处理时,用到了两次n-gram算法,参数分别是n1和n2。根据上文的分析,高频序列对应着高频字段,它们之间的长度是有相关性的。协议数据按内容类型可分为二进制协议和文本协议,这两类协议的字段划分方式不同。对于二进制协议,字段划分位置通常是确定的,长度一般在1~8个字节之间,且短字段较多,这里设n1=3。而对文本协议来说,通常以分隔符来划分字段,比如空格或换行,字段往往较长,这里设n1=6。对于“词”长度n2来说,图2是两种协议数据在本文算法中取不同的n2得到的覆盖率。

图2 不同n2 值的覆盖率
从图2 的结果中可以看出,取n2=5 时几种协议数据的覆盖率最高。这是由于n2设置过小,则“词”取值范围过窄,导致哈希运算效果不明显,设置过大时,一条“文本”中包含的“词”较少,导致“文本”特征较少。
4.4 实验结果
4.4.1 时间性能对比实验
为验证本文提出的高频相似序列算法的时间性能,选取一种二进制协议和一种文本协议分别统计在不同的报文数量时算法的运行时间,并与两种对比算法进行比较。图3(a)是ip协议的实验结果,协议数据截取长度N=20,图3(b)是http协议的结果,N=200。
从图3 中可以看到,NW 算法相比另外两种算法运行效率非常低。除了比对次数多的因素外,该算法是全局序列比对算法,当序列长度N增大时该算法的运行时间呈指数级增长。n-gram 算法不需要序列间的比较,时间主要消耗在统计每个序列片段的出现频率上。本文提出的二进制序列Simhash 算法由于在提取高频序列时已经将待比较的序列数量大幅缩减,并且比较的序列长度都是8比特的0-1序列,运行效率较高,已经接近于n-gram算法。
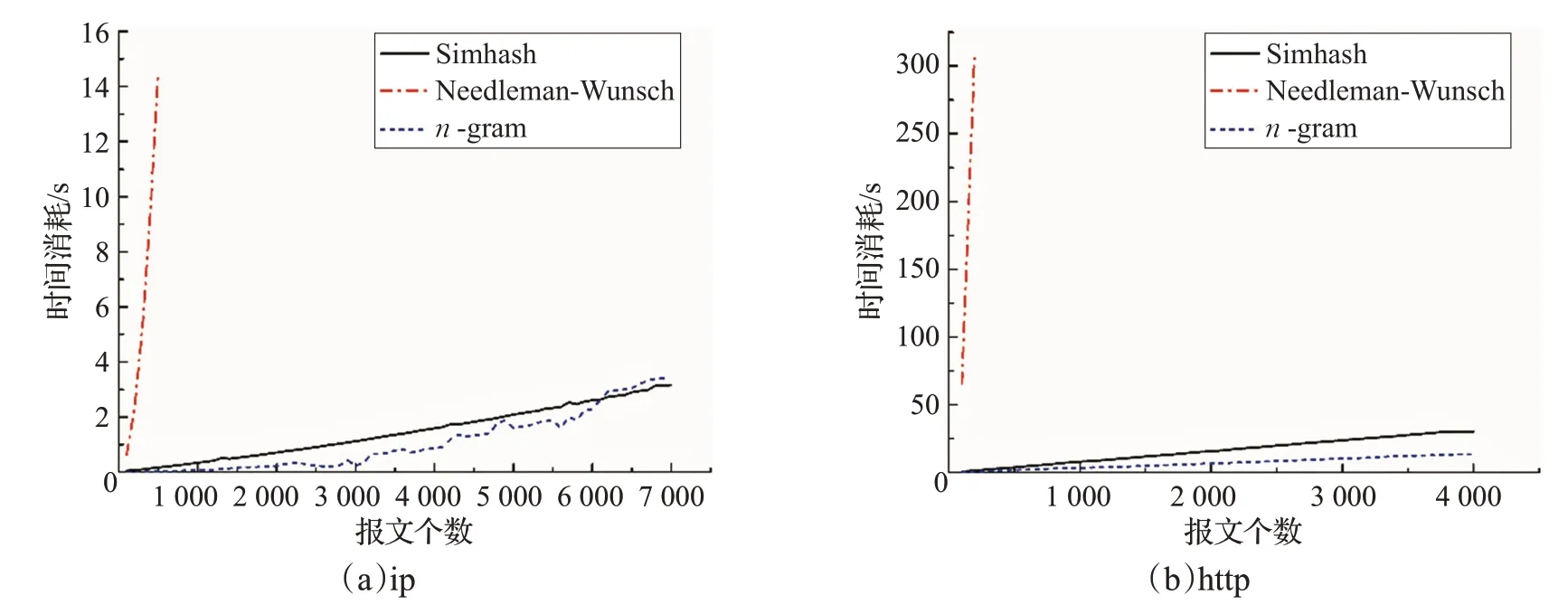
图3 运行时间结果对比
4.4.2 覆盖率对比实验
为了衡量本文提出算法的有效性,针对实验数据集中的五种协议数据,分别计算它们的覆盖率,同时与另外两种对比实验的覆盖率进行比较,得到结果如图4所示。

图4 覆盖率结果对比
从整体上看,NW 算法的平均覆盖率为78.76%,是三种算法中最高的,但这是以牺牲时间来换取的。Simhash 算法的平均覆盖率为74.28%,n-gram 算法的平均覆盖率为60.26%。n-gram 算法由于没有考虑高频序列的位置变化和取值的相似性,导致覆盖率较低。结合实验结果,Simhash 算法兼顾了结果的准确率和运行效率,实用性更强。
5 结束语
本文提出了一种基于Simhash 的高频相似序列提取算法。Simhash 算法的应用场景一般是文本处理,本文根据二进制序列的特征将Simhash 算法引入到了协议数据处理中。通过实验证明,该算法在时间效率上大大优于序列比对算法,并且平均覆盖率达到了74.28%,接近于序列比对算法,能够为协议分析研究提供支撑。在下一步的研究中,将进一步优化该算法并探索Simhash算法在其他二进制处理和协议分析等问题中的应用。
