基于深度神经网络损失函数融合的文本检测
2020-08-19罗时婷
罗时婷,顾 磊
南京邮电大学 计算机学院,南京 210023
1 引言
自然场景图像中除了含有丰富的纹理、形状、颜色等低层物理信息,还含有很多蕴涵重要语义的文本信息,这些具有重要语义信息的文本,可以更好地表达场景视觉信息,对描述和人们理解图片内容具有十分重要的作用。现如今对场景图像的文本理解,首先是文本检测,即找到图像中存在文本的区域的边界框;而后是文本识别,对边界框中的文字进行识别。将这两步合在一起是端到端文本识别。文本检测是其中的第一步,也是很重要的一个步骤。目前文本检测已经应用于拍照翻译软件、图书检索[1]、视频字幕提取[2]等领域,并且成为近几年计算机视觉领域的热门研究话题。
目前,自然场景文本检测主要分为两类:基于传统手工设计特征的文本检测和基于深度学习的文本检测。基于传统手工设计特征的文本检测,依赖于手动设计的特征,大多是基于字符的,即先对字符进行检测,然后将字符进行关联组合。Epshtein等人提出了笔画宽度变换算子(Stroke Width Transform,SWT),通过将原图变换成笔画宽度映射图,再结合几何推理恢复出文本的形态,提取背景图像中的文本[3]。Neumann 等人提出的基于最大稳定极值区域(Maximally Stable Extremal Regions,MSER)的算法通过从图像中提取MSER区域,利用形态学操作和几何规则来检测文本所在区域[4]。赵宇提出基于形态学滤波的MSER,实验证明改进后的笔画宽度变换算法能够很好地保持字符区域的完整性[5]。易尧华等人采用MSCR(Maximally Stable Color Regions)算法与MSER算法提取候选字符区域,然后用检测器对字符区域进行检测[6]。最近,哈恩楠等人将对象建议算法与传统MSER算法相结合进行文本检测,相比传统MSER 算法检测效果较好[7]。近年来,随着神经网络的发展[8],先后诞生了R-CNN[9(]Regions with CNN)、Fast R-CNN[10]、SSD[11]、ResNet[12]等目标检测算法,这些高效的算法在现实生活中得到了广泛的应用[13-14],并且推动了文本检测的发展。在2015年,Zhang等人提出利用全卷积网络(Fully Convolutional Networks,FCN)[15]生成特征图,并使用分量投影进行方向估计,检测效果较好[16]。在 2016 年,Tian 等人提出CTPN(Connectionist Text Proposal Network)[17],通过垂直候选框机制,构建了CNN-RNN(Recurrent Neural Network)联合模型来检测文本行,对于水平方向上的文字检测效果较好,但是对于多方向上的文字检测效果不好。Yao 等人提出将图像以整体的方式来进行文本检测,将FCN 应用于文本检测,获得了较好的检测结果[18]。在2017 年,Zhou等人[19]提出了一个高效、准确的检测器(Efficient and Accurate Scene Text Detector,EAST),是基于U-Net[20]机制的全卷积神经网络,非极大值抑制(Non-Maximum Suppression,NMS)[21]是其后处理部分,通过直接检测图像中的文字或文本行,放弃了不必要的中间过程,并且可以检测不同尺度和不同方向上的文本行,在性能和速度上都明显优于以前的方法。与传统手工设计特征方法相比,这些基于深度学习的文本检测方法[16-19,22]在诸如ICDAR[23-25]的自然场景文本检测比赛中获得更好的准确率。
EAST 网络尽管在文本检测中有着较好的表现,但是它仍然存在着不足,本文就是在深入研究EAST网络的基础上,针对EAST 的缺陷,对它的损失函数部分进行了改进,将一种损失函数Balanced loss,利用加权方法融入EAST中,形成一种新的深度神经网络。文中将融入损失函数后的网络简称为Balanced EAST,实验结果表明能有效提升网络的检测准确性。
2 EAST网络结构
EAST 网络[23]是一个深度神经网络模型,整体网络结构如图1 所示。首先,输入一组图像,通过网络训练后输出得分结果Y^ ;然后,计算Y^ 与真实标签Y之间的损失值L;最后,将损失值反向传播到网络中,通过优化函数进行网络参数的更新。提取特征图、合并特征图、输出层是EAST网络的三个关键部分。
特征图提取,先用一个通用的网络ResNet 作为基础网络用来提取特征图。输入尺寸为512×512×3的一组图像,512×512为图像的长和宽,由于是彩色图像,每个像素由3个RGB(红黄蓝)值组成,因此图像的通道数为3。这些图像首先被送入卷积核大小为7×7,个数为16个的卷积层进行卷积(conv)操作,特征图尺寸变为256×256×16;接着,依次经过4 个卷积块(Block),首先通过Block1,得到尺寸为 128×128×256 特征图f4,再通过Block2,得到尺寸为 64×64×512 的特征图f3,再通过Block3,得到尺寸为32×32×1 024 的特征图f2,最后通过Block4得到尺寸为16×16×2 048的特征图f1。其中,Block1、Block2、Block3、Block4对应ResNet中的Conv2_x、Conv3_x、Conv4_x、Conv5_x 部分,包含多个卷积层,根据对图像不同尺寸的需求,提取ResNet 中对应尺寸的特征图。
特征图合并,将提取的特征图逐步进行合并,合并的规则采用了U-Net[24]的思想。首先,将特征图f1进行上池化(unpool)操作,得到扩充后尺寸变为32×32×2 048的特征图g1;其次,将特征图g1与低一层的特征图f2沿通道轴合并成为一个特征图,将合并后的特征图依次通过卷积核大小为1×1、个数为128的卷积层,卷积核大小为3×3、个数为128的卷积层,得到尺寸为32×32×128的特征图h1;再次,将得到的特征图h1与f3、f4进行同样的合并操作;最后,将输出的特征图通过卷积核大小为3×3、个数为32的卷积层,得到尺寸为128×128×32的特征图。一些相关公式如下:

其中,gi是合并前的特征图;hi是合并后的特征图;fi对应提取的特征图;[;]代表将特征图沿通道轴进行连接;conv3×3代表将特征图送入卷积核大小为3×3 的卷积层进行卷积操作,conv1×1代表将特征图送入卷积核大小为1×1的卷积层进行卷积操作。
输出层,输出包含文本得分和几何得分。文本得分为1通道的特征图,尺寸为128×128×1,分数为每一像素点属于文字的置信概率。几何得分为4 通道的特征图和1通道的特征图组成,尺寸分别为128×128×4、128×128×1,对应的分数是像素点到文本框4 个边界的距离和文本框的旋转角度。i代表特征图合并的阶段数。
通过网络的输出层,EAST 会对每张图像检测出近万个文本框,为了得到最终的文本检测结果,最后还要用到NMS 进行图像的后处理,对检测出的文本框去除冗余。
NMS(即引言中介绍的非极大值抑制后处理方法)是文本检测的后处理过程,如图2 所示,在网络检测出所有文本框后,用来对这些文本框去除冗余,具体步骤如下:
(1)对所有输出的文本框进行遍历,计算两两文本框的交叠率(Intersection-over-Union,IOU),将高于阈值β1的文本框通过加权平均文本框的坐标及得分进行合并,得到合并后的文本框集合。
(2)根据合并后的文本框置信度做降序排列。
(3)从第一个文本框开始,将剩余文本框中与该文本框的交叠率IOU大于阈值β2的文本框剔除。
(4)对于剩余的文本框集合,如果仅剩一个文本框,算法结束;否则,重复执行(3)操作。

图2 检测结果示例
3 基于损失函数融合的深度神经网络(Balanced EAST)
3.1 EAST的损失函数
EAST 网络的输出包含文本得分损失Ls和几何得分损失Lg。其中Ls为1个通道的像素置信概率,置信区间为[0,1],越靠近1代表越有可能为文字。Lg由4个通道的轴对称边界框(简称AABB)和1个通道的旋转角度θ组成,其中AABB的4个通道分别表示从像素位置相对于文本框的顶部、右侧、底部、左侧边界的偏移,记作旋转角度记作。因此,损失函数可以表示为:
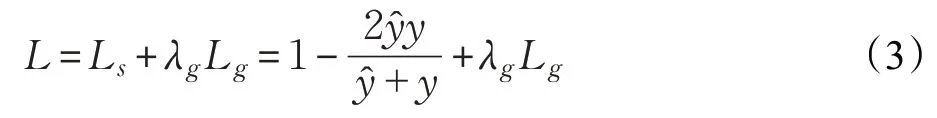
式中,Ls和Lg分别表示文本得分和几何得分的损失;Ls采用的是Dice loss[26];λg表示文本得分和几何得分损失之间的权重,在实验中设置为1;为模型预测得到的文本得分;y为像素点真实得分;Lg中AABB损失采用的是IOU损失,具体如下:

其中,代表预测得到的文本框;R为其对应的真实文本框;|·|用于计算文本框的面积;|计算的是文本框R^ 的面积;|R|计算的是文本框R的面积计算的是文本框相交区域的面积,|R^ ∪R|计算的是文本框并集的面积;IOU 计算的是两个文本框的交叠率,文中所提到的交叠率均由此计算得到。
最后,总体的几何得分损失为AABB损失和角度损失的加权和,由下式给出:

其中,Lθ为旋转角度的损失;λθ表示AABB 损失与角度损失之间的权重;是对旋转角度的预测;θ表示真实旋转角度。
3.2 损失函数融合
在神经网络的训练中,定义和优化损失函数能直接影响模型的训练结果。因此,损失函数在整个网络的设计中占有十分重要的地位。在网络的训练过程中,样本损失值越高,模型越专注于学习这些样本的特征,从而检测结果越准确。在EAST的损失函数中,文本得分所采用的是Dice loss,计算的是预测的文本框与真实的文本框的交叠率,较为单一,使得模型训练时忽视了对文本边界框的修正。同时,由于EAST在进行图像后处理之前会对每张图像检测出近万个文本框,这些文本框可分为四类:难检测正文本框、易检测正文本框、难检测负文本框和易检测负文本框。如图3所示,是四类文本框的示意图,图中红色标记1、2 代表图像的真实文本框,绿色标记3、4、5、6 代表预测的文本框。其中预测文本框中与真实文本框交叠率大于0.5 的为正文本框,其余为负文本框。正文本框分为难检测和易检测两种,难检测正文本框中不仅包含背景还包含了文字,易检测正文本框中仅包含文字,与正文本框一样,负文本框也分为难检测和易检测两种。图中标记3为难检测负文本框,标记4为难检测正文本框,标记5为易检测正文本框,标记6为易检测负文本框。由于图像中背景区域较多,将导致易检测负文本框损失值占总损失值较大比例,这些易检测文本框本身就能被模型很好地检测,模型很难从这些文本框的特征中获得更多的信息,如果训练中关注这些易检测文本框,将影响模型优化的方向,而难检测文本框更能指导模型优化的方向。因此,专注易检测文本框部分的参数更新并不会改善模型的学习能力,甚至影响模型的训练效果,从而影响模型的检测效果,这一问题是EAST中使用的损失函数无法解决的。本文正是针对这个问题,将一种损失函数Balanced loss,利用加权方法融入EAST中,构成了Balanced EAST,使网络修正文本边界框的同时专注于学习难检测文本框中的复杂特征。

图3 文本框类别示例
Focal loss是用于解决单通道目标检测过程中存在的难检测目标与易检测目标不均衡问题的损失函数,在目标检测任务中有效提高了检测的性能[27]。Focal loss的公式为:

其中,γ取值范围为大于0,用来对易检测文本框进行权重抑制;α是调节正负文本框所占权重而设置的加权因子,取值范围为[0,1],α权重越小,负文本框所占损失值将越高,在训练时会更受模型的关注,反之α越大,正文本框会更受模型关注。
目标检测是将图像中所有目标进行分类,并识别它们的边界,在文本检测问题中是识别图像中所有文本行的边界。由于文本行的文字与文字之间有空隙,如果将应用于目标检测的Focal loss 直接应用于EAST 中,存在边界检测模糊的障碍,从而会导致文本框边界定位不准。Balanced loss 在Focal loss 的基础上进行改进,加入权重抑制因子d,对于正文本框存在边界框检测不准确的情况,相对减少损失函数中靠近文本框中心区域像素的损失值,提高靠近文本框边界像素的损失值,从而弱化模型对于文字与文字间空隙的关注,使得模型更加关注于文本行的边界。Balanced loss的公式为:

其中,y∈{0,1}是真实标签,是预测值;d用来对靠近文本框中心的像素进行权重抑制,权值抑制的对象是图像中的正文本框,越靠近文本框中心的像素点损失值越低;d1、d2、d3、d4分别表示从一个像素点到其所在真实的文本框的顶部、右侧、底部和左侧边界的距离。
利用加权的方法,将Balanced loss 与EAST 的文本得分Ls进行融合,得到的Balanced EAST 损失函数的文本得分为:

其中,λ表示 Dice loss 与 Balanced loss 之间的权重,取值范围为[0,1]。实验中为验证融合损失函数对实验效果的影响,这里采用平均加权的方式,将参数λ设置为0.5。融合后的Balanced EAST损失函数为:

针对EAST 解决不了的难易文本框数量不平衡导致的检测性能不佳问题,融合后的Balanced EAST进行了解决,保留了EAST整体网络设计简洁并且可以检测多尺度文本行的优势,进一步提升了整体检测的准确性。
4 实验
4.1 数据集
CN-Text 是在数据集 http://rrc.cvc.uab.es/?ch=15 中选取的590 张中文图像,其中400 张用于训练,190 张用于测试,图像的分辨率在280×210到5 184×3 456内,场景中文本是多方向的。
为了进一步验证本文方法,还在公共竞赛数据集ICDAR 2015 上进行了实验。ICDAR 2015 是ICDAR 2015 Robust Reading Competition[22]的公开竞赛数据集,包含英文文本,一共1 500张图像,其中1 000张用于训练,500 张用于测试,分辨率均为1 280×720。这些图像是用手机随机拍摄的生活场景,存在图像模糊和低分辨率的情况,并且场景中文本是多方向的。
4.2 实验基本设置
实验硬件环境:64位Intel E5-2603 v4@1.70 GHz×6 CPU,15.6 GB RAM,显卡为NVIDIA Quadro K640 4 GB,操作系统为ubuntu16.4。
神经网络参数设置:Balanced EAST 中,根据GPU内存大小将每次迭代输入图像的数量设置为3,将CN-Text最大迭代次数设置为10万次,训练时间大约为20 h,将ICDAR 2015 最大迭代次数设置为5 万次,训练时间大约为10 h。由于文献[27]的实验中已证明γ取值为2时网络效果最好,这里设置式(8)中γ=2。由于两个数据集中前景背景占比不同,α在两个数据集上设为不同的值,在CN-Text中文字占比较多,设置α=0.5,在ICDAR 2015 中背景较多,设置α=0.3。经测试λ=0.5 时检测效果最好,因此设置式(10)中λ=0.5。CTPN 中,每次迭代输入图像的数量设置为3,其余参数值均不变。以下设置与EAST 的网络设置保持一致,采用50-layer 的ResNet作为提取特征图的通用网络,输入图像的尺寸均改变为512×512×3,使用ADAM 优化函数进行训练,学习率初始值为1E-3,每经过1 万次迭代训练后衰减为原来的0.94,到1E-5停止,式(6)中λθ=20,NMS中阈值β1和β2均设置为0.35。
4.3 评价指标
在实验中,对于CN-Text 和ICDAR 2015 这两个数据集采用相同的评估标准,即来自ICDAR 2015比赛的评估标准,有三个评估指标,分别是回归率(Recall)、准确率(Precision)和F值(F-score),计算公式如下:

其中,G是真实的文本框集合;D是预测的文本框集合;match用于计算两个集合中互相匹配的文本框数量,即检测准确的文本框数量。F-score综合Recall与指标Precision的评估指标,用于综合反映总体结果的指标。
4.4 CN-Text数据集实验结果
在CN-Text数据集上,本文对提出的Balanced EAST与EAST、CTPN算法进行实验,并对结果进行对比分析。在CN-Text 数据集上进行模型的训练,如图4 所示,是ICDAR 2015数据集的图像在本文提出的Balanced EAST与EAST、CTPN 文本检测方法上的实验结果对比图。图4(a)为CTPN实验结果图,图4(b)为EAST实验结果图,图4(c)为Balanced EAST 实验结果图,图4(d)为真实结果图。
从图4可以看出,第一张图像中文字是一个长的文本行,真实结果(d)检测出的是一个长的文本框,其中CTPN 没有检测到文本区域,EAST 检测出文本行中的三个文字,而且是小尺度的,Balanced EAST 检测的结果是三个长尺度的文本框,图像中的所有文字均包含在文本框中。第二张图像包含较长文本行与短文本行,字体大小不一,真实结果(d)检测出来的是五个文本框,包含小尺度和大尺度的文本框,CTPN仅检测出一个文本框,EAST检测出四个文本框,包含的文字为真实结果的1/2,Balanced EAST 检测的结果是五个文本框,包含图像中的所有文字。可以得出,Balanced EAST能够更加有效地检测出图像中所有文字。

图4 CN-Text数据集的结果对比
表1 列出的是在CN_Text 数据集上,采用相同评估标准,得到的 Balanced EAST 与EAST、CTPN 的评估结果。从表中结果可以得出,Balanced EAST得到的回归率、准确率、F值均优于EAST、CTPN。其中F值为综合指标,最具有说服力,在Balanced EAST 中,F值达到 0.545 6,比EAST 提高0.039 0。由于CN-Text 数据集数量较少,且为中文数据集,中文的字符复杂度较高,检测难度大,Balanced EAST表现出的优势不明显。

表1 CN-Text数据集的评估结果
4.5 ICDAR 2015数据集实验结果
在ICDAR 2015 数据集上,本文对提出的Balanced EAST 与EAST 进行实验,对实验结果进行分析。在ICDAR 2015数据集上进行模型的训练,如图5所示,是CN-Text数据集的图像在本文提出的Balanced EAST与EAST上的实验结果对比图。图5(a)为EAST实验结果图,图5(b)为 Balanced EAST 实验结果图,图5(c)为真实结果图。

图5 ICDAR 2015数据集的结果对比
从图5 第一张图像的检测结果可以看出,EAST 存在两个误检的文本框,Balanced EAST不存在误检的文本框,并且检测出的文本区域包含的文字比EAST检测出的更多。第二张图像中,EAST对边框的检测不准确,出现了文本框间重叠的现象,Balanced EAST对边框的检测较为准确,不存在文本框重叠现象,检测结果最为接近真实结果(c)。综上可以得出,Balanced EAST 相比EAST误检较少,对文本框的检测更精确。
为了进一步验证Balanced EAST的有效性,将Balanced EAST 与 EAST 的评估结果与文献[16]、文献[18]、文献[28]、ICDAR 2015 比赛的评估结果进行对比。表2列出的是在 ICDAR 2015 数据集上,Balanced EAST 与EAST,以及 Zhang 等人提出的算法 MCLAB_FCN[16]、Yao 等人提出的算法CCNF[18]、Koo 等人提出的算法AJOU[28]、ICDAR 2015 比赛的评估结果[25]对比,采用的是相同的评估标准,其中ICDAR 2015 比赛结果包括CNN MSER、NJU、StradVision1。表2 中的EAST*为重设参数后复现的实验结果。从表2 可以得出,Balanced EAST 的F值达到较高的 0.721 5,Balanced EAST 相比EAST 回归率提高0.070 3,准确率提高0.068 2,F值提高0.069 3,Balanced EAST的检测结果更好,优势明显。
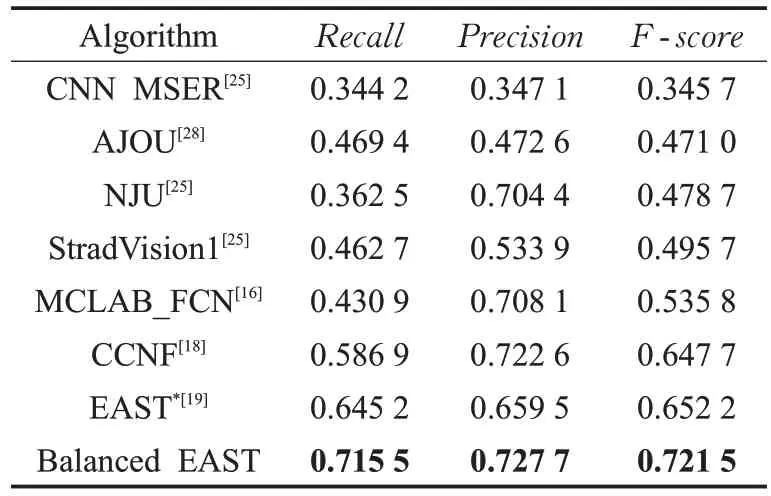
表2 ICDAR 2015数据集的评估结果
综合以上CN_Text 和ICDAR 2015 数据集的实验结果,与EAST相比,损失函数融合后的Balanced EAST整体检测效果更好,检测出的文本框边框更为精确,漏检、误检的现象较少。
5 结束语
本文提出基于损失函数融合的深度神经网络,利用加权的方法在传统深度神经网络中融合Balanced loss,对于难检测像素点,通过增加其得分在损失函数中所占的比例,使模型更关注于复杂特征,提升模型的学习能力,同时不影响迭代速度。实验结果表明,本文提出的基于特征融合的深度神经网络,在继承了传统神经网络能够检测不同尺度、多方向的文本行的基础上,整体提高了检测的准确性。
