大规模优化问题的改进花朵授粉算法*
2020-08-15刘景森
李 煜,郑 娟,刘景森
1.河南大学 管理科学与工程研究所,河南 开封 475004
2.河南大学 商学院,河南 开封 475004
3.河南大学 智能网络系统研究所,河南 开封 475004
1 引言
越来越多科学和工程应用问题由低维发展成高维,决策变量增多,计算量大,具有不确定性且一般为多目标复杂优化问题[1]。一般情况下,决策变量超过100个的函数优化问题被定义为大规模优化问题[2],如大型电力系统、视频数据处理、输电网扩展规划、大规模交通网络的车辆路径规划等。优化问题的求解难度和维度息息相关,搜索空间和问题复杂度随维度增加呈指数趋势增大,找到最优解的概率呈指数下降,极易陷入“维数灾难”,而且这些决策变量之间相互关联,使得计算复杂度和求解难度进一步加大。
大规模优化问题具有非线性、不可微的特点,传统梯度下降方法无法求解,目前的求解方法主要有两种[3]:一是将维度分组的协同进化策略,基于降维思想分组求解分解后的低维简单问题,后将各组低维解结合成高维解[4];另一种不分组方法是利用群智能算法对优化问题整体求解。群智能算法基于种群迭代机制进行优化计算,具有潜在的并行性和分布式特点[5],全局搜索能力优异,能有效求解复杂优化问题[6-7]。这种整体求解方法能克服分组策略“两步向前,合并向后”的缺点[1],如:贺桂娇等[8]提出的改进人工蜂群算法(artificial bee colony algorithm with at-tractor,BAABC)求解高维复杂优化问题的优势明显,鲁棒性很好。Binh等[9]提出改进布谷鸟搜索算法(improved cuckoo search,ICS)和混沌花朵授粉算法(chaotic flower pollination optimization algorithm,CFPA)求解多个无线传感器的网络区域覆盖优化问题。改进算法在解决传感器节点部署这个NP-Hard 问题时较其他算法具有时间优势。黄光球等[10]构造的可全局收敛蝙蝠算法(bat algorithm,BA)能求解不同类型的大规模优化问题,而且收敛速度快。
花朵授粉算法(flower pollination algorithm,FPA)[11]是Yang 于2012 年提出的一种新型群智能算法。该算法参数少,易实现,易调节,寻优结构新颖,寻优能力良好,已在函数优化[12]、无线传感网[9]、电力系统[13]、作业车间调度[14]、形状匹配[15]、背包问题[16]等领域得到广泛应用。国内外已有不少学者对其易陷入局部最优、寻优精度低、后期收敛速度缓慢等缺点进行了改进。将该算法与其他智能优化算法融合取得了不错的效果:如Abdel-Raouf 等[17]将粒子群优化算法融入到花朵授粉算法中;Lenin 等[18]将混沌和声算法与花朵授粉算法进行融合;Salgotra 等[19]提出了融合蝙蝠算法的BFP(bat flower pollination)算法。另外,Wang 等[20]认为维间干扰会减缓算法的收敛速度,影响求解质量,对解进行逐维改进并引入局部邻域搜索策略;肖辉辉等[21]融合高斯变异和Powell法改善了算法的寻优能力。
本文使用花朵授粉算法整体求解大规模优化问题。采用反向学习策略增加种群多样性,提高初始种群质量;为降低大规模优化问题的求解难度,降低算法迭代代价,避免维间干扰对算法收敛精度和速度的影响,设计了新的局部更新公式,发挥当代最优位置牵引作用,逐维动态改变配子相对受扰动程度和继承程度,并接受更优的结果作为下次迭代基础。这种新的避免维间干扰的方法很好地弥补了算法易陷入“维度灾难”的缺陷,且与逐维更新评价方法相比,这种方法的时间代价具有明显优势。最优位置的牵引作用使得改进算法仅需3~5 个种群个体即可达到满意的优化效果。15 个测试函数在3 种高维状态100、1 000 和5 000 的数值仿真结果表明:相比于FPA、PSO(particle swarm optimization)[22]和BA,IFPA(improved flower pollination algorithm)的寻优精度高、收敛速度快、鲁棒性强且适应度高,求解不同类型大规模优化问题时优势明显。
2 大规模优化问题描述
大规模优化问题用公式表示如下:

其中,X=[x1,x2,…,xD]为决策变量,其取值不同对应着优化问题的不同决策方案,D表示决策变量的个数(即问题维度),本文维度设定为100、1 000和5 000。
F(x)表示优化问题的目标函数,xi∈[xmin,xmax]表示边界约束,xmax、xmin分别表示问题上下边界。
3 花朵授粉算法
FPA 是模仿显花植物授粉过程而设计的随机全局优化算法。因花朵授粉对象的不同存在自花和异花两种授粉方式。异花授粉是指相对较远距离的不同株植物之间的授粉,该方式一般需要传粉者,传粉者的行为具有莱维飞行的特征,FPA 的全局授粉(寻优)阶段模拟了此授粉过程。自花授粉是指在较近的距离内,相邻花朵依靠非生物手段实现成熟花粉粒成功传递并能正常受精结实的过程,FPA将这种授粉方式称为局部授粉(寻优)。
一株植物能开好多花,每个花朵有百万甚至上亿的花粉配子。为简单模拟授粉过程,假设每株植物仅有一朵花,每朵花独有一个花粉配子。那么,一朵花或一个花粉配子的位置序列刚好是优化问题的一个解。算法假设条件如下:
(1)生物异花授粉被看作全局授粉过程,该规则的数学表达式为:

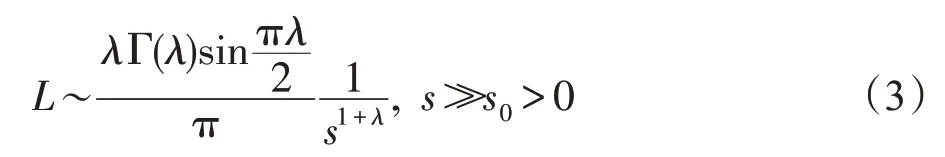
其中,λ=3/2,Γ(λ)是标准的伽马函数。
(2)非生物自花授粉即花朵的局部授粉,该演化机制的数学公式为:

其中,ε是均匀分布在[0,1]间的随机数;代表同类植物的不同花朵的花粉,即种群的两个随机解。
(3)花的繁衍概率与花朵间的类似程度存在比例关系。
(4)由p∈[0,1]来动态控制局部和全局授粉的转换。物理上的接近和风等自然因素的作用使得相邻花朵更容易授粉成功,故局部授粉在整个授粉活动中占比较大,文献[23]中已通过大量实验证明p值取0.2最为合适。
下面的伪代码描述了FPA的基本步骤:

4 改进的花朵授粉算法
4.1 基于反向学习的种群初始化
反向学习(opposition-based learning,OBL)策略[24]自2005 年出现以来,就经常作为智能优化算法的改进策略出现[25-27],并衍生出透镜成像反向学习策略[28]、正交反向学习[29]等。
反向学习策略基于对立点的定义:
定义1(对立点(opposite point))[26]假设在[Lb,Ub]上存在数x,则x的对立点为x′=Lb+Ub-x。那么,若p=(x1,x2,…,xd)为d维空间中的一个点,其中xi∈[Lbi,Ubi],i=1,2,…,d,则其对立点为p′=(x′1,x′2,…,x′d),其中x′i=Lbi+Ubi-xi。
为说明反向学习初始化对种群多样性和种群质量的影响,图1(a)和图1(b)分别给出了IFPA 求解Sphere 函数时反向学习前后种群个体分布情况。其中,绿色圆圈代表花粉位置,红色圆点代表全局最优点。问题维度为3维,变量搜索空间为[-100,100],种群数为5。

Fig.1 Initial distribution of pollen图1 花粉初始化分布图
图1清楚地显示,反向学习使花粉个体探索了更多的位置,增加了种群多样性,反向学习后有更多的花粉接近全局最优点,提高了初始种群质量,为算法奠定了更好的迭代基础。
4.2 逐维随机扰动的局部开发
FPA 在全局搜索中采用Lévy 飞行机制,它的较大跳跃和随机步长的不均匀性一定程度上能规避配子陷入局部最优点,使其全局探索能力优异[30]。图2展示了50步Lévy飞行的情况。
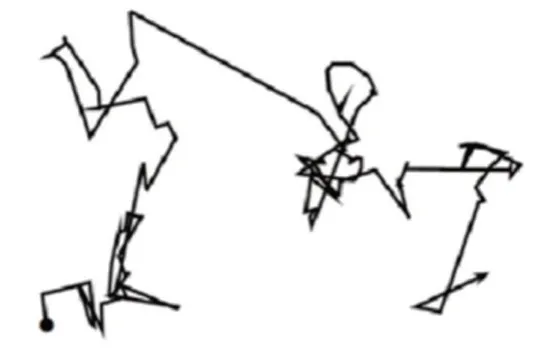
Fig.2 A series of 50 consecutive steps of Lévy flight图2 50步Lévy飞行
但局部开发能力相对不足,原因有以下两点:
(1)配子更新不受任何因素引导,过于随机,虽能增强配子的多样性,但难以满足精准开发的要求,也抑制了优化过程的收敛速度。为提高算法的求解精度,将带有随机性信息的与带有确定性信息的当前最优位置g*处理求得的差分向量代替原扰动中的,发挥当代最优位置的牵引作用,避免较大的随机性所带来的低搜索效率和较低收敛速度等问题[31]。
理论上,为达到相同的求解效果,搜索空间越大、种群规模越多,种群更新的代价越大,因此能较好地求解低维问题的智能算法在高维问题求解中表现一般。而这种改进仅需要3~5 个种群个体就可以达到满意的优化效果,这是因为在种群数量较少的情况下,改进扰动中的差分算子能够更容易地牵引整个种群朝当前最优位置靠近,有效解决了算法求解大规模优化问题迭代代价大的问题,而且能够使算法在迭代后期局部开发更加精准。
(2)局部更新过程过于平缓,缺乏跳动,易陷入局部最优,这主要归因于该算法的更新机制。算法靠转换概率p实现异花授粉和自花授粉的动态转换,简单易懂,易于执行,也能通过合理设置p值大概率地进行局部搜索,更加贴合现实。但是p值越小,进行全局搜索的概率越小,即使某次迭代选择全局搜索,也不能保证恰好发生远距离Lévy跳跃,配子初期可能逗留初始化位置附近,这种情况严重影响算法寻优精度和收敛速度。而且多维优化问题尤其是大规模优化问题维数之间的干扰也很大程度上影响着算法性能和解的质量。
原花朵授粉算法采用整体更新和评价策略求解,不能规避维间干扰现象[20]。Wang 等人为解决此问题提出逐维更新评价策略[20],但是该更新方式时间代价大,虽然对有些函数求解的精度较高,但鲁棒性并不好。本文为打破维间干扰问题,提出局部开发的逐维随机扰动策略,借鉴萤火虫算法[32]相对荧光亮度公式,设计逐维随机相对继承程度m和逐维随机相对受扰动程度2-m,m的公式表达为:

其中,k为花粉配子的最大继承程度,与原花朵授粉算法保持一致取值为1,表示对上代花粉位置完全继承;2π 是花粉粒子继承系数;|L(j)|是花粉粒子在第j维上的Lévy飞行距离。
由于每一维的Lévy 飞行距离不同,使得花粉个体的每一维不同程度地继承上代信息,受到不同程度的扰动,解决了维间干扰问题,增加了种群多样性,在当代最优位置的牵引作用下,最终提出的第j维的更新公式为:

该更新方式不仅解决了维间干扰问题,而且使得算法不会错失Lévy 飞行的良好机制,如果较大跳跃配合全局搜索执行,自然可以提升算法全局寻优能力,如果较大跳跃配合局部开发执行,就可以使花粉个体受到更大的扰动影响(Lévy 飞行距离越长,2-m的值越大)。在迭代初期种群差异较大时,花粉个体能受到更大的扰动影响,遍历更大的范围,因此不管进行全局搜索还是局部搜索,都能保证算法初期花粉个体的跳跃能力,提高算法初期的迭代质量和全局寻优能力,有效解决算法易陷入局部最优的问题。
被更新的花粉个体如果更优,就接受它并将它作为下代更新的基础,否则就舍弃该更新解,保持之前的迭代基础。局部开发的逐维随机扰动策略具体如算法1所示。


综上,IFPA优化流程如图3所示。
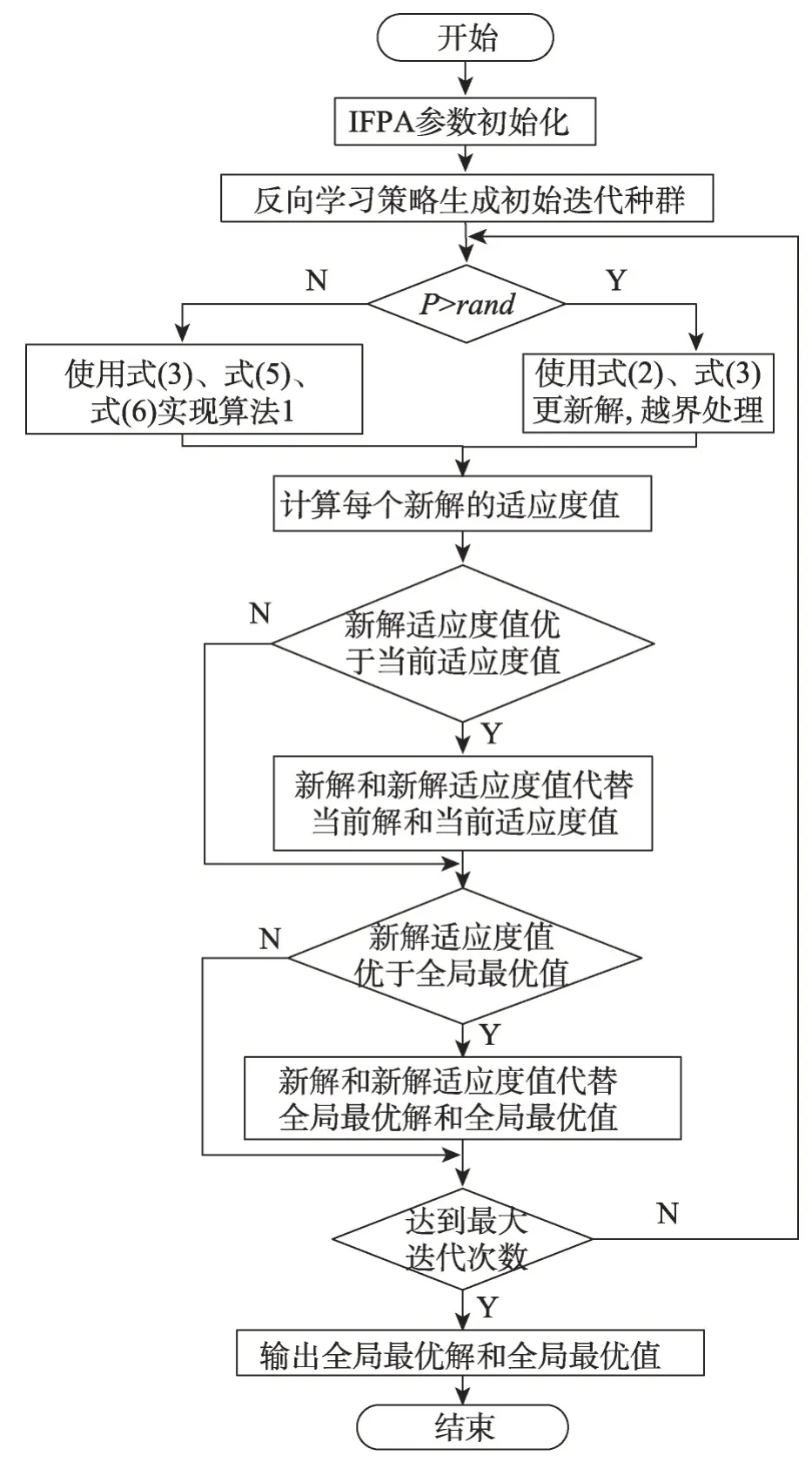
Fig.3 Flow diagram of IFPA图3 IFPA流程图
4.3 花粉粒子多样性分析
为模拟改进算法的寻优过程,仍以Sphere 函数为例,展示花粉粒子反向学习初始化、迭代10 次、50次、100次、200次和500次后的位置分布,如图4所示。为便于分析花粉粒子的多样性,设置种群规模为50。
从图4 可以看出,随着迭代次数的增加,花粉个体以较快的收敛速度朝全局最优解靠近。为分析全局最优解附近的花粉多样性,将50代、100代、200代和500代的局部放大图展示为图5所示。

Fig.4 Pollen iteration graph图4 花粉迭代分布图
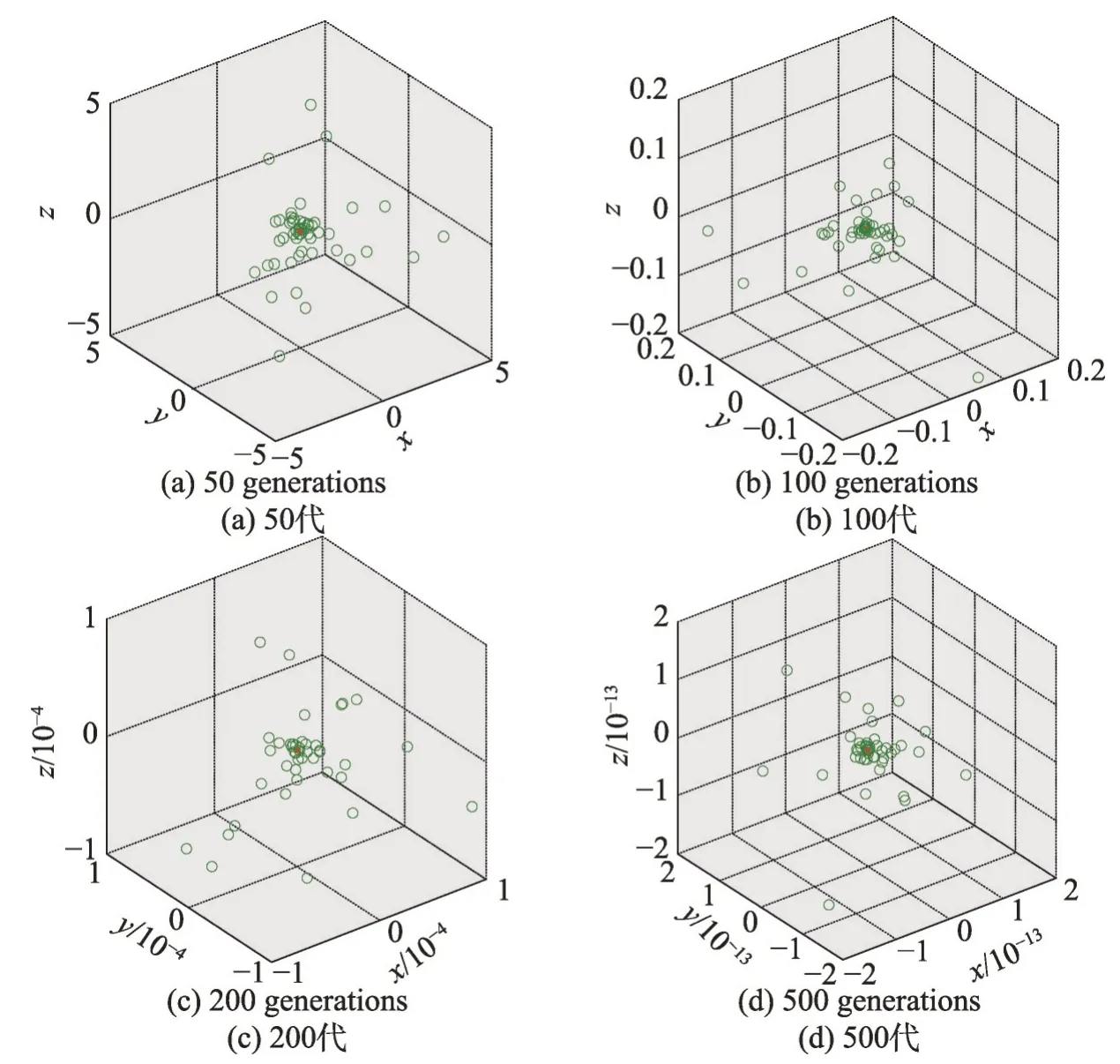
Fig.5 Partial enlarged detail图5 局部放大图
从图4 和图5 可以看出,随着迭代次数的增加,花粉离全局最优解的距离越来越近,求解精度越来越高,但是花粉种群并没有趋同,Lévy飞行的较大跳跃和随机步长的不均匀性赋予决策变量的不同扰动,使得种群多样性良好,花粉个体在迭代后期依然较为均匀地分布在全局最优解附近。
5 数值实验与分析
5.1 测试函数与性能指标
为全面客观地评价IFPA求解大规模复杂优化问题的性能,选取15 个不同类型的测试函数[5,33]在3 种高维状态下进行测试。f1~f9为高维单峰函数,可测试算法的收敛速度和寻优精度,其中f5有非凸病态特点,算法在对其优化过程中很容易陷入局部极小;f10~f15是高维多峰函数,解空间中分布着大量局部极小点,寻优过程中极易陷入局部最优,极难找到全局最优解,可有效测试算法跳离局部极值的能力及全局收敛性能,f10和f13是典型代表。测试函数的具体特征如表1所示。
本文设定结果精确度(accuracy,AC)和寻优成功率(successful ratio,SR)来评价算法性能。AC反映算法迭代结果和测试函数理论最优值的接近程度。若一个测试函数的理论最优值是Xopt,迭代结果为Sbest,则精确度为AC=|f(Sbest)-f(Xopt)|,本文设定AC<0.000 1即称此次运行寻优成功,收敛到全局最优解;SR 即多次实验中算法收敛到问题全局最优解的比例,若总实验次数为z,全局最优解被收敛到的实验次数为z′,SR=z′/z×100%。

Table 1 Benchmark functions表1 基准测试函数
5.2 实验环境及参数设置
为客观评价IFPA 处理大规模优化问题的性能,将其与经典的PSO、BA 和FPA 进行对比。在每次运行中,将迭代1 000次作为这些算法的终止准则。为防止偶然性误差,产生有统计学意义的结果,对每个函数独立运行30 次,所有实验都在相同的条件下进行,并记录结果中的均值和标准差。种群数统一设为5,其他参数设置如表2所示。
基于上述参数设置,分3 种维度100、1 000 和5 000 进行仿真实验,实验笔记本操作系统为Win-dows10,主频1.6 GHz,CPU 为Intel Core i5-8520,内存8 GB,使用Matlab R2014a实现编程。

Table 2 Parameter settings of each algorithm表2 各算法参数设置
5.3 寻优精度分析
15个测试函数100、1 000和5 000维的实验结果如表3 所示,4 种算法中的最好结果加粗表示。从表3中的统计结果可知,除f14外,本文提出的IFPA在各个维度下的求解精度均优于其他3种算法,寻优精度大幅提高,以极高的寻优成功率收敛到了f1~f4、f6、f8、f10~f13这10 个函数的全局最优解,并能收敛到f3、f10和f13的理论最优值,而3种对比算法对15个函数的寻优成功率全为0。
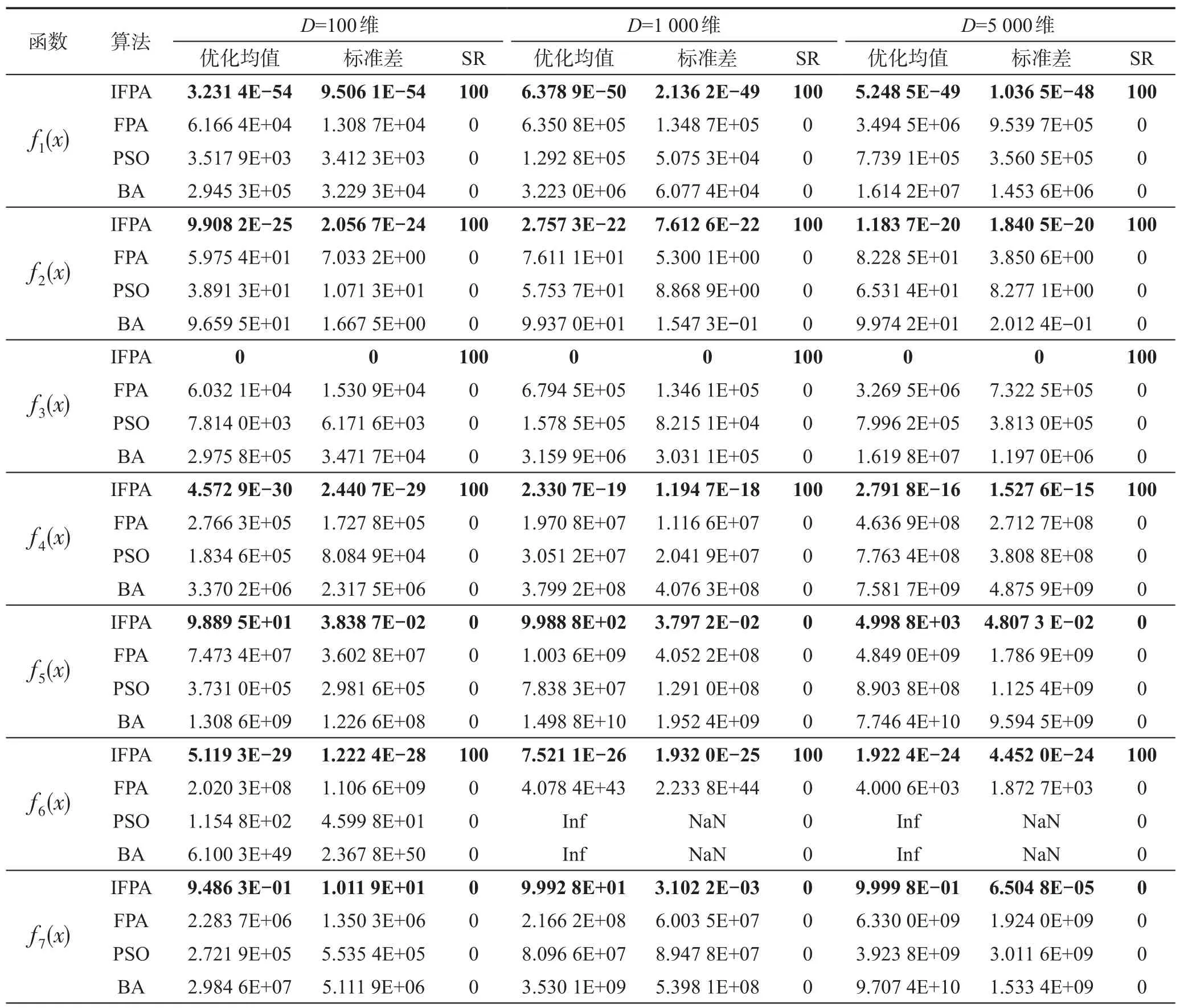
Table 3 Simulation results of different functions表3 不同函数的仿真结果
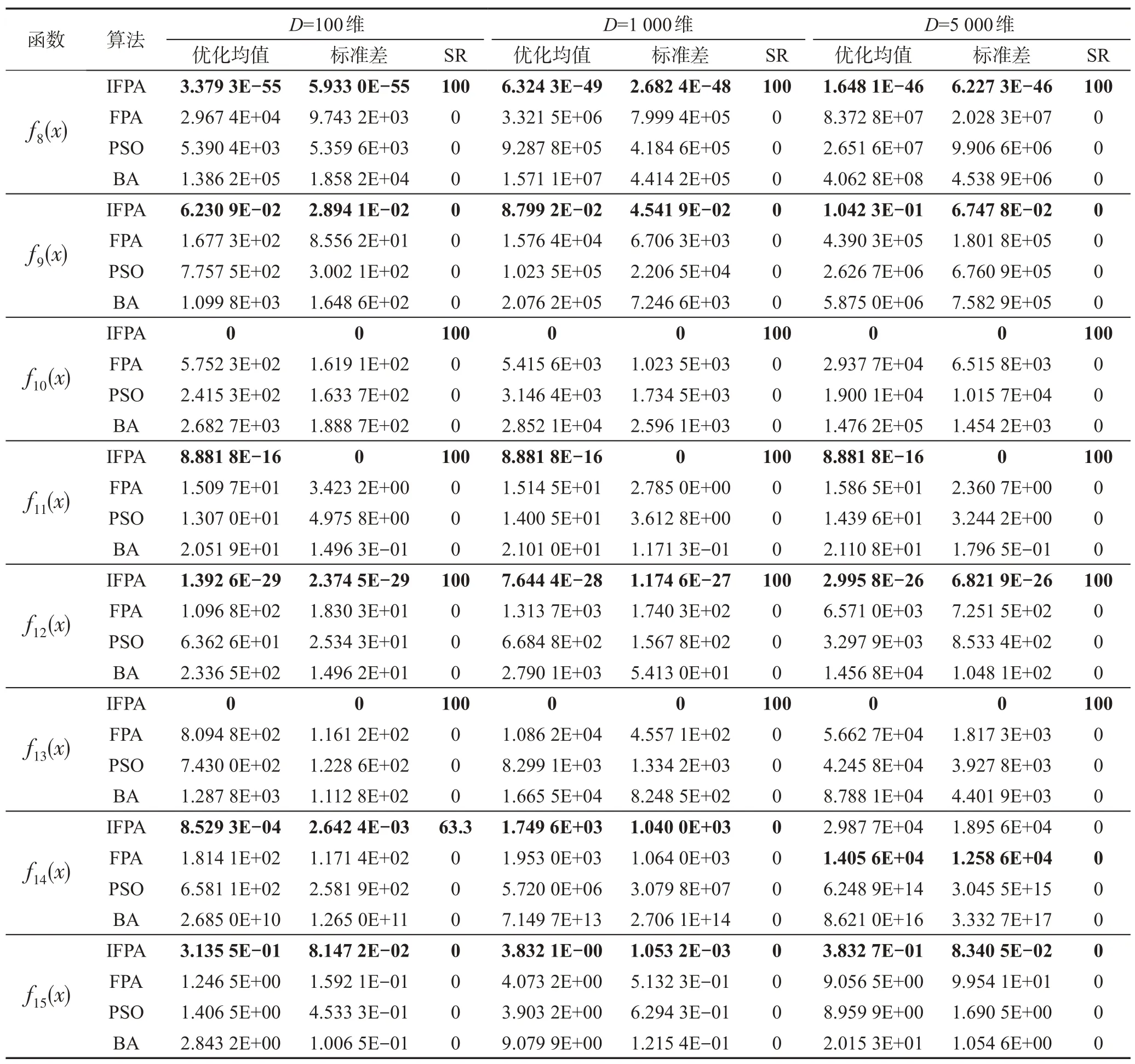
续表
IFPA 在3 种高维状态下次次都能收敛到f3、f10和f13的理论最优值。IFPA 对函数f1、f2、f4、f6、f8、f11、f12的寻优精度比对比算法中的最好结果提高了17~69个数量级。
3 种对比算法对f6的求解精度随维度升高变化极大,特别是PSO 和BA,在1 000 和5 000 维时无法对解空间进行任何有效搜索的概率高达93.4%~100%,鲁棒性很差,而IFPA 的收敛精度依然能达到10-24以上并且变化极小。
IFPA 对f7、f9和f15的求解结果已较接近理论最优值。IFPA对f7、f9的求解精度至少比对比算法提高了6、4个数量级。IFPA对f5的求解精度比对比算法提高了4~8 个数量级,对f14的求解精度也提高了0~16个数量级。
IFPA不但寻优精度高,鲁棒性也强。除f14的标准差随维度升高变化稍大以外,另14 个函数的标准差极小且基本不随维度改变,求解结果稳定,证明了IFPA 的求解性能基本不受维度和函数类型的影响,与其他3 种算法相比优势突出,成功克服了“维数灾难”问题,适合处理大规模优化问题。
5.4 收敛曲线分析
算法跳出局部极值的能力和收敛速度都可通过适应度收敛曲线直观显现。图6 给出了4 种算法1 000 维下优化8 个测试函数的适应度收敛曲线,所有收敛曲线都是对应算法30 次独立运行的平均值。除f2、f11、f12和f13外,其他函数的目标函数值取以10为底的对数。
图6 的收敛曲线清楚地显示,较3 种对比算法,IFPA收敛速度更快,寻优精度更高,跳出局部极值的能力更强。从图6(c)、图6(e)和图6(h)中可以看出,IFPA 可分别在100、400 和300 代左右收敛到f3、f10和f13的理论最优值。IFPA对f6的优化效果极好,无法看到图6(d)中BA和PSO的收敛曲线,是因为这两种算法对f6搜索不到任何有效解,而IFPA对此函数求解精度依然很高。从图6(b)、图6(f)~图6(h)可以看出,4种算法均有陷入局部最优的情况,其中BA在迭代初期就易陷入局部最优,PSO和FPA几次陷入局部最优,而IFPA的收敛曲线较为光滑,陷入局部最优的次数偏少,收敛速度也明显快于其他算法。

Fig.6 Convergence curve of 4 algorithms for different functions in 1000 dimensions图6 1 000维下求解不同函数的4种算法的收敛曲线
高维状态下,4 种算法中FPA 收敛速度较快,但求解精度偏差;PSO算法的收敛精度虽然是3个对比函数中最好的,但其收敛速度却是4 个算法中最慢的,且容易陷入局部最优;IFPA 的全局优化能力很强,不但收敛速度快,寻优精度高,而且不易陷入局部最优;BA表现最差。以f12的收敛曲线为例,IFPA迭代50 代左右求解精度已非常高,FPA 虽然前期收敛较快,但1 000次迭代后寻优结果仅在1 300左右,离函数的理论最优解相差很远,虽然PSO 的最终求解结果比FPA 更优,但其收敛速度很慢,并且在70、130、200 代左右几次陷入局部最优,BA 不管在求解精度上还是收敛速度上都是最差的。
5.5 两种改进策略的有效性分析
为了分析两种改进策略对算法性能的影响,从表1 中选取了7 个能代表寻优精度不同提高程度的测试函数在100 维下进行数值实验,将IFPA 与仅采用反向学习策略的FPA算法(记为OFPA)、仅采用逐维随机扰动的局部开发策略的FPA 算法(记为DFPA)和FPA 进行比较,算法的参数设置与5.2 节相同。表4给出了4种算法的测试结果比较,最好结果加粗表示,其中T是30 次独立运行的总时间(单位:s),B、M、W、S分别表示最优值、优化均值、最差值和标准差。
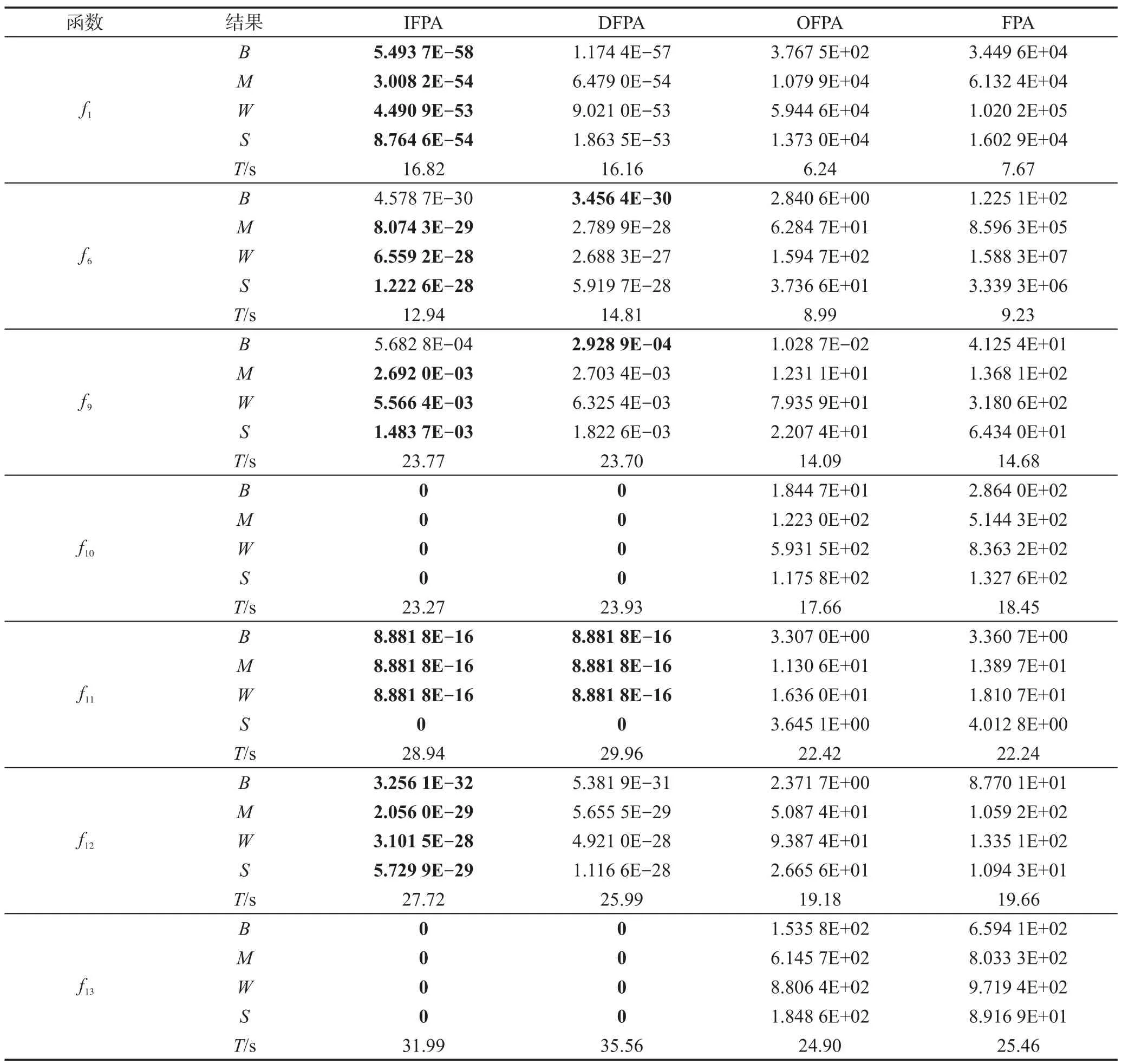
Table 4 Comparison of test results of 4 algorithms(D=100)表4 4种算法的测试结果比较(D=100 维)
由表4 的比较结果可知,OFPA 提高了算法的求解精度和鲁棒性,较FPA的求解精度更高,且不增加求解时间。例如,OFPA 在维持运行时间的前提下,仅通过反向学习初始化,对f6的求解精度就提高了4个数量级;对f9求得的最优值的精度只比IFPA低了2 个数量级。这说明反向学习初始化确实可以充分搜索解空间,保留更多的优良个体,为算法奠定高质量迭代基础,而且IFPA 的求解精度普遍比DFPA 高也证实了反向学习初始化的作用。
采用逐维随机扰动策略设计的局部更新方式是IFPA性能改进的有效算子,DFPA收敛到了f10和f13的理论最优值,使f1、f6、f9、f11、f12的求解精度分别提高了58、33、5、17、31 个数量级,且求解结果稳定,算法稳定性强。DFPA 求解单峰函数的时间代价大概为FPA 的1.5~2.1 倍,求解多峰函数的时间代价为FPA 的1.3 倍左右,很好地平衡了精度提高和时间代价两方面。
6 结束语
为有效处理大规模优化问题,本文用反向学习策略提高FPA 初始种群质量,在局部开发阶段采用逐维随机扰动策略对花粉个体进行优化,打破了维间干扰,降低了大规模优化问题的求解难度,扩大了花粉受扰动的程度,提高了算法的全局寻优能力,并发挥当代最优位置的牵引作用,减少了算法迭代代价,有效解决了FPA收敛精度低、易陷入局部极值和“维数灾难”等问题,大大提高了算法求解大规模优化问题的性能。在100、1 000 和5 000 的高维状态下,IFPA的求解精度、收敛速度、鲁棒性、对不同类型测试函数的适应性等都明显优于FPA、PSO和BA,15个测试函数的最好结果基本全部由IFPA 求得,且求解精度基本不受维度影响。在今后的研究工作中,考虑将分组策略应用其中,进一步提高算法性能;细致研究参数p如何动态变化能使算法更优;将改进算法应用于实际工程问题。
