林春杰 金苗娟

摘 要:实现高效获取互联网中特定领域信息的有效途径是使用聚焦爬虫,针对聚焦爬虫在判断主题相关时缺少语义信息的问题,提出了一个基于语义相似度计算的聚焦爬虫框架。该框架抽取网页的主题词、内容和链接信息作为网页特征,计算主题相似度。通过链接的主题相关度计算,过滤URL和判断URL的重要程度。最后给出了对比试验,验证了该方法的有效性。
关键词:聚焦爬虫;语义相似度;本体;搜索引擎
Abstract:The effective way to achieve efficient access to information in specific areas of the internet is to use focused crawler. To solve the problem of lack of semantic information when focused crawler judges the relevant topics,a focused crawler framework based on semantic similarity calculation is proposed. The framework extracts the subject words,content and link information of web pages as the features of web pages,and calculates the subject similarity. Through the calculation of topic relevance of links,we can filter URL and rank URL. Finally,the experiment result demonstrated that the proposed method has higher performance than traditional crawlers.
Keywords:focused crawler;semantic similarity;ontology;search engine
0 引 言
互联网信息的规模正在不断地增长,但人们搜集信息的效率却相对落后,搜索引擎技术可以帮助人们从海量数据中快速检索到所需要的信息。网络爬虫是搜索引擎的核心,它負责从网络中寻找和搜集资源。以Google、百度等搜索引擎为代表的通用搜索引擎目标是覆盖全网络,采用广度优先算法的爬虫搜集网页进行索引,其软硬件资源消耗较大、无法深入抓取深层网络资源。聚焦爬虫通过限定某一个主题,抓取相应的网页,从而提高抓取效率和精度,因此受到了广泛的关注。
聚焦爬虫只关注特定的主题相关的网页,无需搜索整个Web,效率较高,但如何判定网页的主题相关性是其核心问题之一。Fish-Search[1]是最早的聚焦爬虫,它采用深度优先策略,只抓取与给定的查询(关键词或正则表达式)相匹配的页面。Shark-Search[2]系统改进了Fish-Search系统,提出利用TF-IDF(term frequency-inverse document frequency)作为文件与用户查询之间相关程度的度量或评级,构建空间向量模型计算网页和主题之间的相似度。PageRank算法[3]将Web看作是有向图,通过网页之间的链接计算网页间的重要度和相似度。近年来很多新方法被引入到聚焦爬虫中,文献[4]提出了将多目标蚁群算法应用于链接选择,优化爬虫搜索方向。文献[5]给出了一个融合LDA的卷积神经网络主题爬虫方法,利用LDA提取的特征弥补神经网络缺失的主题信息,文献[6]提出基于主题建模和上位词替换的语义信息的向量空间语义相似度计算模型。然而,目前网页结构多样,语义丰富,如何利用更多的语义信息来提高聚焦爬虫的效率成为了一个待解决的问题。
针对上述问题,提出了一个基于语义相似度计算的分布式聚焦爬虫框架,该框架通过计算抽取出的网页特征间的相似度判断当前网页和主题的相似度,利用链接信息计算待爬取网页和当前主题的相似度从而实现URL过滤和排序。笔者在前期的自科基金项目资助下对本体的构建、映射、合并和语义标注等方面做了基础性的研究,提出的语义相似度计算方法是一种基于本体的方法,目的是通过本体本身蕴含的语义信息扩展网页中的特征,提高网页过滤的精度,最后通过对比实验验证了该方法的有效性。
1 网页特征描述
网页的内容通常由HTML语言描述,HTML文档是一个半结构化的文档,主要包含网页的结构信息,缺少语义。因此如何有效提取网页中的特征是影响主题分类器的性能的关键问题。网页中除正文文本以外,还包括对网页主题描述的信息,例如
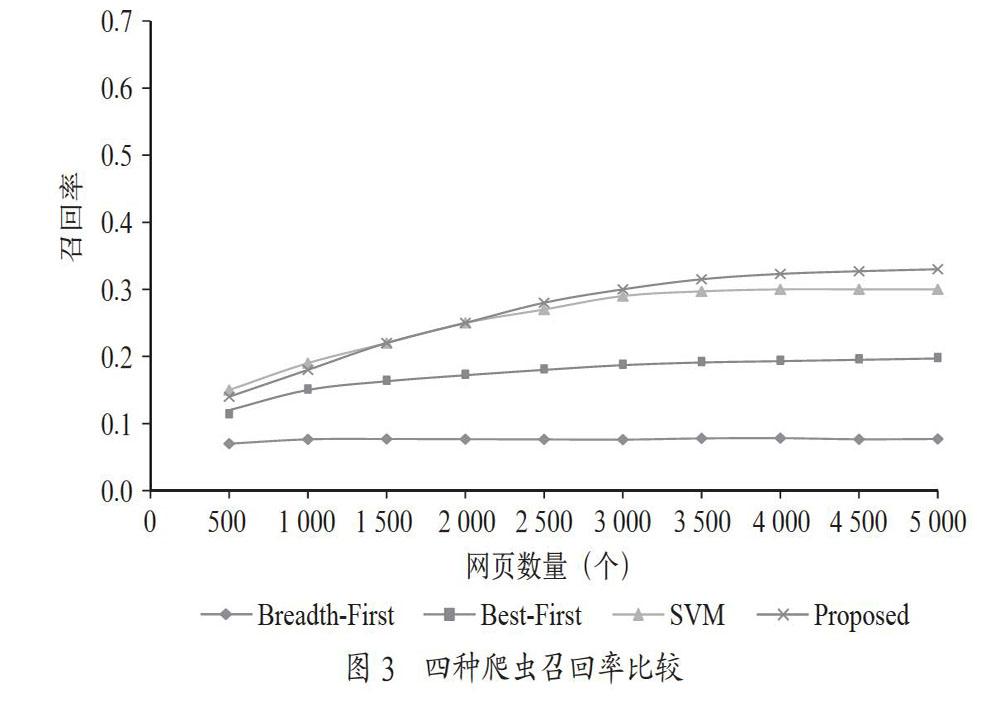
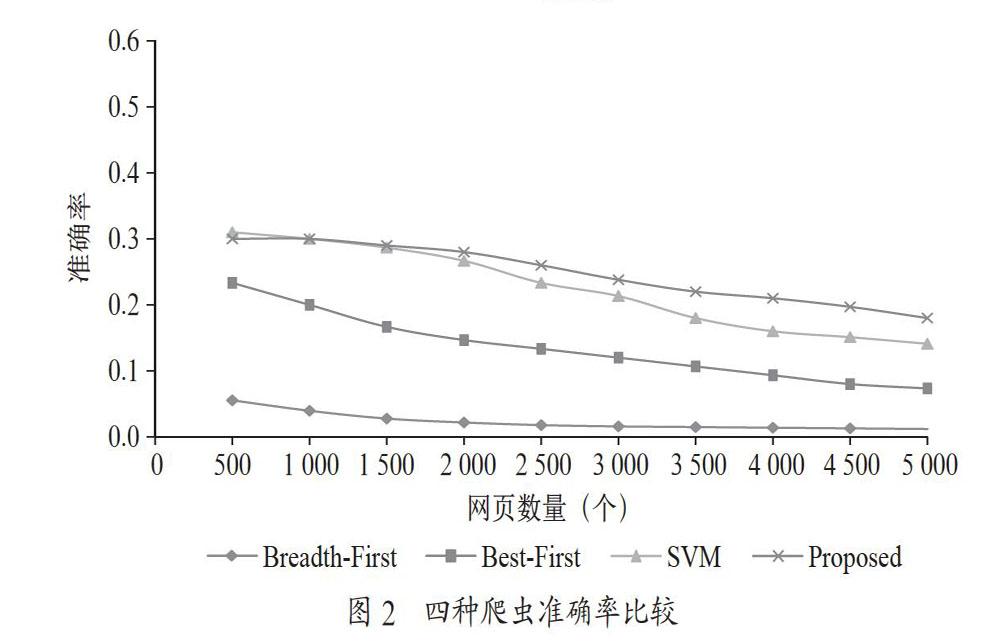
标签通常是该网页的标题;<meta>中标记搜索网站的关键词;超链接标签<a>内的文本通常反映了该链接指向网页的描述,而且链接往往链接到与当前网页相关的网页。有效地从这些信息中提取网页的特征为下一步进行相似度计算提供了基础。为了克服传统文本分类方法中基于关键词匹配带来的局限性,本文引入了领域本体,提出了基于领域本体的语义相似度计算的主题相似度计算方法。该方法综合考虑页面的内容、结构、语义等方面特征,采用启发式搜索策略选择与主题相关链接,优化爬虫效率。</p><p>定义1:网页的特征集表示为Fpage={CL,CT,CW},其中网页链接特征(指向该网页的链接来源网页和主题相似度)记为CL={l1,l2,…ln},li表示链入当前页面的网页与主题相似度;网页的主题词特征(从网页的<title>、<meta>、锚文本、URL地址等位置提取的关键词)记为CT={t1,t2,…,tn},ti表示链入当前页面的第i个主题关键词;网页的内容特征(网页正文内容中提取的关键词)记为CW={w1,w2,…,wn},wi表示当前页面的第i个关键词。</p><p>定义2:链接的特征集表示为Flink={Ca,Ct,r},其中Ca表示锚文本关键词,Ct表示URL文本关键词,r表示当前文档与主题相似度。</p><p>定义3:爬虫的上下文主题表示为T={t1,t2,…,tn},其中ti表示第i个主题关键词。</p><p>通過定义3的网页链接特征预测目标网页与爬虫上下文主题相似度,将相似度较低的链接抛弃掉,不再下载该网页,用于过滤无关网页,提高爬虫的效率;利用定义2的网页特征,计算与爬虫上下文主题相似度,用于判定该网页是否与主题相关,另外还可以为下一步链接的分析和排序提供依据。定义的特征大多以关键词形式存在,因此判断主题相似度的核心是计算关键词间的相似度。本文引入同义词本体WordNet指导相似度计算。两个词的相似度和它们在本体中的位置有关系,下面给出相似度定义:</p><p>定义4:关键词间的相似度计算公式定义如下:</p><p>其中,d(a,b)表示本体中连接两个概念的最少边数量,MaxDepth表示本体概念层次最大深度。该公式采用非线性函数的形式,因为相对于线性函数它有较高的准确性。</p><p>2 网页与上下文主题相似度计算</p><p>爬虫为了抓取主题相关网页,需要进行主题相似度计算,判断该网页与主题的相关程度,从而判断该网页是否属于该主题。然而网页是一种半结构化数据,缺乏语义信息,计算机不能了解其语义含义,因此引入领域本体计算相似度,以提高相似度计算的准确率。考虑到定义1中定义的网页的特征包含三部分:网页的链接特征、主题词特征、正文文本特征,本文综合考虑这三个特征,建立相似度计算公式。</p><p>其中Topk(),表示最大的k个值,α、β和γ是3个可调节的权重,用于调整不同类型的网页的各部分特征的权重。</p><p>主题词中往往包含网页的类别关键词,因此它对于网页于主题相似度贡献最大,正文文本也是判定相似度的重要依据,它们是式(1)前两项计算的内容,链接特征值(式(2)的第3项)表示的链入该网页与主题的相关程度,反映的是网页链接的结构相似度。</p><p>网页链接相似度计算的目的是预测该链接到的文档是否可能是与主题相关,进而确定是否下载该网页,从而提高爬虫的效率。根据网页链接的三个特征:锚文本、URL文本和当前网页的主题相似度,给出了链接与上下文主题相似度计算方法。</p><p>其中,α、β和γ是3个可调节的权重,用于调整不同特征的贡献权重。</p><p>3 主题爬虫框架</p><p>主题爬虫框架的思路是,从种子链接出发,下载网页,过滤掉与主题相关度小于阈值的网页,同时搜集下载的目标链接,根据主题相关度对链接进行排序,过滤掉与主题无关的链接,避免消耗爬虫的计算资源。通过网页过滤和链接过滤,决定下一步爬行路径,以便于尽可能缩小搜索路径,下载与主题相关的网页。分布式爬虫框架如图1所示。</p><p>3.1 爬虫调度器</p><p>爬虫调度器节点是整个系统的核心,负责任务的分发和协调,控制、协调执行器各个节点的分布式计算处理,同时,将待爬取的URL链接进行分区,分配给各执行器节点。</p><p>3.2 分布式爬虫执行器</p><p>每个节点能够独立下载网页,接收到爬虫调度器分配的任务之后,就启动相应的任务进行处理,主要包括网页下载、网页解析和预处理、网页主题相似度计算,并把下载后的与主题相关的网页保存到原始网页库中,然后在将该网页中分析新的链接,并对解析得到的链接进行粗过滤,并根据与主题的相似度设置相应的权重,存储到新解析URL库中,作为后续网页抓取的链接列表。</p><p>3.3 分布式数据库集群</p><p>是一个数据库集群,它负责存储待抓取的URL队列、待解析的URL和下载网页内容。</p><p>3.4 链接过滤器</p><p>该模块的主要任务是对网页解析模块中获得的URL进行进一步过滤。网页中的链接可能出现不规范、重复和无效的情况,这些链接必须经过规范化和去重后才可以使用,并根据优先级分配到不同的爬虫执行器上取执行。另外,通过链接相关性计算,判断该链接与主题的偏离程度,过滤后的链接再被存放到待抓取URL队列库中,等待后续的网页下载。</p><p>4 实验分析</p><p>为了验证该爬虫的有效性,开发了一个爬虫原型系统,抓取英文新闻网站,考察它在抓取准确率方面的差异。实验的待爬取队列中的种子被初始化为4个新闻网站(www.ecns.cn、www.bbc.com、www.people.cn、www.chinadaily.com.cn)。实验中,使用WordNet 3.0作为背景知识本体,用于计算网页和链接的上下文主题相似度。实验以疾病为主题,爬取网页数量上限设置为5 000,验证不同爬虫的准确率和召回率。</p><p>为了评价提出的爬虫方法的实际运行效果,选取了其他3种爬行策略。</p><p>4.1 Breadth-First Search爬虫</p><p>基于Breadth-First Search爬虫是最简单的爬虫,通常,它作为爬虫算法的比较基准。</p><p>4.2 Best-First Search爬虫</p><p>该策略使用关键词集来描述主题,使用TF-IDF作为关键词权重(从主题相关的网页中统计得出),从中选取前300个权重最高的词组成主题向量。然后将得到的网页中提取到的文本转换为向量与主题向量计算相似度,根据结果判定网页是否与主题相关。</p><p>4.3 基于SVM分类器的主题爬虫</p><p>该策略将SVM分类器和HITS算法相结合,使用SVM筛选与主题相关的网页,根据链接的authority值预测待爬取网页与主题的相似度,从而进行再次爬取。</p><p>图2的横坐标表示抓取得到网页的数量,上限是5 000,纵坐标表示抓取相应数量网页时的主题相关网页比率(准确率)。如图2所示,本文提出的算法的准确率相对较高,随着抓取网页数量的增加,准确率相对提高。Breadth-First算法的准确率相对较低,因为该算法比较简单,未识别网页的主题。</p><p>如图3所示,横坐标表示抓取得到网页的数量,上限是5 000,纵坐标表示抓取相应数量网页时的主题相关网页的召回率。本文提出的算法召回率随着抓取网页数量的增加,得到的结果较好,因为算法充分考虑了网页文本和链接结构信息,提高了检索的效率。</p><p>5 结 论</p><p>本文提出了基于本体语义相似度计算的分布式聚焦爬虫框,该方法通过综合考虑网页的主题词、内容和链接等特征计算与主题的相似度,同时通过链接信息预测目标链接网页和主题的相似度。通过两阶段的相似度度量,过滤网页,通过实验验证了该方法的有效性。该聚焦爬虫框架适合在分布式集群中运行,结合Hadoop的MapReduce计算框架可以实现对大规模数据的高效爬取。目前,提出的聚焦爬虫框架爬取单一语言网页的效率比较稳定,但是在分析多语言混合的网页场景下,主题相似度计算的精度有限,这是需要进一步研究的内容。</p><p>参考文献:</p><p>[1] BRA P D,HOUBEN G J,KORNATZKY Y,et al. Information Retrieval in Distributed Hypertexts [C]//4th International Conference,October 11-13,1994,Rockefeller University,NY,USA:DBLP,1994:481-493.</p><p>[2] BRIN S,PAGE L. The anatomy of a large-scale hypertextual Web search engine [C]//Proceedings of the seventh international conference on World Wide Web 7,Amsterdam,Netherlands:Elsevier Science Publishers,1998:107-117.</p><p>[3] KAMVAR S D,HAVELIWALA T H,MANNING C D,et al. Extrapolation Methods for Accelerating PageRank Computations [D].USA:Stanford University,2003.</p><p>[4] 東熠,刘景发,刘文杰.基于多目标蚁群算法的主题爬虫策略 [J/OL].计算机工程:1-11(2019-11-11).https://doi.org/ 10.19678/j.issn.1000-3428.0055967.</p><p>[5] 孙红光,藏润强,姬传德,等.基于语义的聚焦爬虫算法研究 [J].东北师大学报(自然科学版),2018,50(2):51-57.</p><p>[6] 汪岿,费晨杰,刘柏嵩.融合LDA的卷积神经网络主题爬虫研究 [J].计算机工程与应用,2019,55(11):123-128+ 178.</p><p>作者简介:林春杰(1981—),男,朝鲜族,吉林人,讲师,硕士,研究方向:数据挖掘;金苗娟(1982—),女,汉族,河南洛阳人,讲师,硕士,研究方向:自然语言处理。</p></div></div>
<!-- <div class="m_article_pdf"><a href="https://cimg.fx361.com/kkb.apk">查看pdf文档请下载app</a></div>--><div class="article_love_part">
<h3>猜你喜欢</h3>
<div class="article_love_keyword"><span><a href="/tags/4/0/11db5f59cadb8679/1.html" target="_blank">本体</a></span><span><a href="/tags/a/0/ffe4f7fc9624c45f/1.html" target="_blank">搜索引擎</a></span></div>
<div class="article_love_news"><dd><a href="/news/2022/0621/10482769.html" target="_blank" title="水果连连看">水果连连看</a></dd><dd><a href="/news/2022/0317/10150334.html" target="_blank" title="Chrome 99 Canary恢复可移除预置搜索引擎选项">Chrome 99 Canary恢复可移除预置搜索引擎选项</a></dd><dd><a href="/news/2021/0228/10098440.html" target="_blank" title="眼睛是“本体”">眼睛是“本体”</a></dd><dd><a href="/news/2020/1221/7764331.html" target="_blank" title="世界表情符号日">世界表情符号日</a></dd><dd><a href="/news/2018/0831/4150589.html" target="_blank" title="一种采暖散热器的散热管安装改进结构">一种采暖散热器的散热管安装改进结构</a></dd><dd><a href="/news/2017/0422/1689944.html" target="_blank" title="一种新型水平移动式折叠手术床">一种新型水平移动式折叠手术床</a></dd><dd><a href="/news/2015/0701/9254661.html" target="_blank" title="网络搜索引擎">网络搜索引擎</a></dd><dd><a href="/news/2013/1021/9035756.html" target="_blank" title="Care about the virtue moral education">Care about the virtue moral education</a></dd><dd><a href="/news/2013/0626/3716418.html" target="_blank" title="基于Lucene搜索引擎的研究">基于Lucene搜索引擎的研究</a></dd><dd><a href="/news/2009/1215/4196533.html" target="_blank" title="搜索引擎,不止有百度与谷歌">搜索引擎,不止有百度与谷歌</a></dd></div>
</div><div class="phbk_part"><h3>杂志排行</h3>
<ul><li><a href="/bk/sdjy/202410.html" class="title">《师道·教研》</a><a href="/bk/sdjy/202410.html" class="date">2024年10期</a></li><li><a href="/bk/swyzhsby/202411.html" class="title">《思维与智慧·上半月》</a><a href="/bk/swyzhsby/202411.html" class="date">2024年11期</a></li><li><a href="/bk/xdgyjjhxxh/20242.html" class="title">《现代工业经济和信息化》</a><a href="/bk/xdgyjjhxxh/20242.html" class="date">2024年2期</a></li><li><a href="/bk/wxxsyb/202410.html" class="title">《微型小说月报》</a><a href="/bk/wxxsyb/202410.html" class="date">2024年10期</a></li><li><a href="/bk/gywsw/20241.html" class="title">《工业微生物》</a><a href="/bk/gywsw/20241.html" class="date">2024年1期</a></li><li><a href="/bk/xl/20249.html" class="title">《雪莲》</a><a href="/bk/xl/20249.html" class="date">2024年9期</a></li><li><a href="/bk/sjbl/202421.html" class="title">《世界博览》</a><a href="/bk/sjbl/202421.html" class="date">2024年21期</a></li><li><a href="/bk/zxqyglykj/20246.html" class="title">《中小企业管理与科技》</a><a href="/bk/zxqyglykj/20246.html" class="date">2024年6期</a></li><li><a href="/bk/xdsp/20244.html" class="title">《现代食品》</a><a href="/bk/xdsp/20244.html" class="date">2024年4期</a></li><li><a href="/bk/wszyjy/202410.html" class="title">《卫生职业教育》</a><a href="/bk/wszyjy/202410.html" class="date">2024年10期</a></li></ul>
</div><div class="bk_part">
<div class="bk_im_b"><a href="/bk/xdxxkj/20208.html"><img src="https://img.fx361.cc/images/2021/03/06/comqkimagesxdxkxdxk202008-l_mini.webp" alt=""></a></div>
<div class="dbk_title"><a href="/bk/xdxxkj/" target="_blank">现代信息科技</a></div>
<div class="dbk_date"><a href="/bk/xdxxkj/20208.html" target="_blank">2020年8期</a></div>
</div><div class="others">
<h3><a href="/bk/xdxxkj/" target="_blank">现代信息科技</a>的其它文章</h3>
<ul><li><a href="/news/2020/0814/7633999.html" title="一类分数阶脉冲微分方程边值问题的研究">一类分数阶脉冲微分方程边值问题的研究</a></li><li><a href="/news/2020/0814/7634042.html" title="基于故障物理的电子产品可靠性分析">基于故障物理的电子产品可靠性分析</a></li><li><a href="/news/2020/0814/7634050.html" title="直流系统接地故障分析及处理">直流系统接地故障分析及处理</a></li><li><a href="/news/2020/0814/7634065.html" title="基于单片机的智能交通系统构想和实现">基于单片机的智能交通系统构想和实现</a></li><li><a href="/news/2020/0814/7634076.html" title="单片机技术在智能小车避障循迹系统设计中的应用">单片机技术在智能小车避障循迹系统设计中的应用</a></li><li><a href="/news/2020/0814/7634091.html" title="电子书包场景下多用户性能自适应优化方法研究">电子书包场景下多用户性能自适应优化方法研究</a></li></ul></div></div>
<div class="m_footer"></div>
<script>
if ('serviceWorker' in navigator) {
window.onload = function () {
navigator.serviceWorker.register('/sw.js');
};
}
</script>
<script type="text/javascript" src="https://s1.pstatp.com/cdn/expire-1-M/jquery/3.4.0/jquery.min.js"></script>
<script type="text/javascript" src="https://s2.pstatp.com/cdn/expire-1-M/Swiper/4.5.0/js/swiper.min.js"></script>
<script type="text/javascript" src="https://s1.pstatp.com/cdn/expire-1-M/jquery.lazyload/1.9.1/jquery.lazyload.js"></script>
<script type="text/javascript">
document.write('<script src="https://img.fx361.cc/js/m.index_cc.js"><\/script>');
</script>
</section>
</body>
</html>