科学论文内的科学数据组织和发现研究
2020-08-14丁培

摘 要:[目的/意义]科学论文中的图、表等科学数据(文内数据)蕴含有丰富的知识内容。基于细粒度语义组织的文内数据发现有效聚合文献、科学数据两类科研产出,为未来实现全领域、全维度、全粒度、全类型的深度知识发现奠定基础。[方法/过程]梳理、对比、分析现有3类文内数据的发现模式,尝试构建面向细粒度内容描述的文内数据本体,揭示文内数据的显性特征、内容特征以及与其他类型科学产出的关联特征。[结果/结论]从面向应用的角度,提出基于本体的文内数据知识发现技术框架,细化“信息抽取—语义标注—关联应用”技术路线,针对关键点技术进行讨论。文内数据本体为科学论文内科学数据提供语义描述和关联组织依据,人工标注结合机器学习自动标注可以解决文内数据部分特征发现问题。
关键词:文内数据;科学数据;科学论文;本体组织;数据发现
DOI:10.3969/j.issn.1008-0821.2020.02.005
〔中图分类号〕G254 〔文献标识码〕A 〔文章编号〕1008-0821(2020)02-0034-10
Research on the Organization and Discovery of
Scientific Data in Scientific Papers
Ding Pei1,2,3
(1.National Science Library,Chinese Academy of Sciences,Beijing 100190,China;
2.School of Economics and Management,University of Chinese Academy of Sciences,
Beijing 100190,China;
3.Library,Shenzhen University,Shenzhen 518060,China)
Abstract:[Purpose/Meaning]The figures,tables and other scientific data in scientific papers(Scientific data in papers,SDIP)contain abundant knowledge.SDIP discovery based on fine-grained semantic organization can effectively aggregate literature and scientific data,laying a foundation for future in-depth knowledge discovery in all fields,all dimensions,all granularity and all types.[Method/Process]By combing,comparing and analyzing the existing organization and discovery patterns of three types of SDIP,this paper attempted to construct SDIP ontology that oriented to fine-grained knowledge description,and revealed SDIPs the explicit characteristics,content characteristics and characteristics correlation with other types of scientific output.[Result/Conclusions]From the perspective of application,this paper proposed an ontology-based framework for SDIP knowledge discovery,elaborated the technical route of“information extraction-semantic annotation-relational application”,and discussed the key technologies.Ontology provided semantic description and relevance discovery basis for SDIP.Manual annotation and automatic annotation using machine learning algorithm could solve the some problem of SDIP feature discovery.
Key words:scientific data in scientific papers;scientific data;scientific literature;ontology organization;data discovery
數据驱动的科学研究范式下,科学数据的共享、发现毋庸置疑成为全球重视的问题。得益于大规模科学数据仓储及共享平台建设升级,国家、大学积极推动制定科学数据开放获取政策,科研资助机构要求科研人员提供数据管理计划,期刊出版社努力推动科学数据引用、数据链接解析、科学数据提交及科学数据出版,科学数据的共享和发现在近几年内有巨大的改善。然而,科学数据本身的敏感性、机密性,数据出版环境不成熟,文献和数据相互引用缺少统一规范,数据组织停留在粗粒度数据集的简单描述,科学文献和科学数据多基于简单的科研属性特征关联,这一系列因素导致科学数据的深度内容发现及跨类型的知识发现进展迟缓。
当前,基于关键词搜索、相关度排序算法的文献全文检索发现技术已经十分成熟。在语义出版浪潮推动下,文献细粒度语义组织、基于机器学习算法的文献细粒度内容的抽取和语义标注、论文语义功能单元的识别和抽取也逐步走向实际应用。科学文献的精准、细粒度发现为科学数据的细粒度发现提供了很好的思路。
图、表、公式等科学数据被大量应用于科学论文中。它们往往是对信息的高度概括,帮助作者清晰简洁地呈现出详细的结果和复杂的关系、模式和趋势,增加了读者对研究结果的理解,并减少了论文手稿长度。它们是科学论文中不可或缺的组成。本研究称这些数据为文内数据。文内数据是文献和科学数据的交叉点,一方面支撑科学文献的重要论点,浓缩科研精华,帮助读者理解研究框架;另一方面作为科学数据“冰山”一角,是科学工作流过程数据、科学数据仓储的延续,承载科学数据发现的职责。本研究以文内数据作为科学数据精准、细粒度发现的突破口,对文内数据多维特征进行细粒度语义组织,建立文内数据与文献、科学数据集在引用、论证作用、隶属关系、研究主张(研究假设、研究结果、研究主题等)、科学方法等方面的关联,尝试解决基于科学数据细粒度特征的文献搜索聚类和基于文献主题、研究方法等的多类型数据聚合等问题,尝试以文内数据为桥梁,建立起数据、文献两类科学产出之间的联系,促进数据的细粒度发现,为更加深刻的文献分析提供支点,为未来实现全领域、全维度、全粒度的文献和数据关联奠定基础。
2020年2月第40卷第2期现代情报Journal of Modern InformationFeb.,2020Vol.40 No.2
2020年2月第40卷第2期科学论文内的科学数据组织和发现研究
www.xdqb.net
Feb.,2020Vol.40 No.2
1 科学论文内科学数据的发现研究现状
目前,科学论文内科学数据的发现采用过3种方式,分别是基于元数据的数据发现、基于本体的数据发现以及基于信息抽取技术的数据标注与发现。
元数据模型常应用于大型的数据收集和科学数据仓储的管理中。它是描述信息资源或数据对象的数据。它通过结构化的描述,对具体的情境进行定制化的解释,实现对资源的组织、发现、互操作、归档和保藏等。其优势在于表达的多样化、门槛低,因而,元数据是最早应用于文内数据发现的组织方式。
Sandusky R J等調查发现科研人员希望可以检索发现期刊文章内的图、表、地图、照片等内容[1]。剑桥科学文摘(Cambridge Scientific Abstracts,CSA)创造性地提出“深度索引”方法,抽取文献中的表格、图片等数据,标引其元数据,建立科学数据的独立索引数据库,进而提供基于关键词、作者、单位的元数据检索服务[2]。BioText Search Engine[3]同样也采用元数据索引方式来标注文献内的图表数据。曹树金等构建细粒度聚合单元元数据框架并将其用于数据检索,实现图片标题、文献来源、上下文内容等检索,并提供颜色、发表年度、关键词、图片类别分面功能,未深入描述与揭示图表与章节、篇章及句群的联系[4]。SciData是面向通用科学数据组织的元数据模型,其描述了科学数据的方法论、系统、数据集、参数、值、单元等要素[5]。元数据发现方式并不能完全解决数据之间的语义异构问题,不同领域知识下的元数据存在误解的可能,跨学科的元数据难以交互使用,还存在描述粒度大、数据难以被计算机理解和自动处理、无法实现语义化检索和知识推理等缺点。
本体能解决元数据的上述不足,它以一种明确、形式化的方式表示信息资源,通过赋予异构数据以统一的语义信息,使得机器能够理解信息并自动处理信息之间的语义联系,从而提高异构数据之间的互操作性。
在本体组织方面,目前与科学数据相关的本体大都将科学数据作为整体对象,粗粒度描述其特征,并基于粗粒度特征建立科学数据和科学文献的关联。现有科学数据的本体组织又可分为4类。第一类是在科学研究的本体中,将数据(或数据集)作为整体对象纳入本体,描述其在科研属性方面的特征。VIVO本体,引用本体Citation Typing Ontology(CITO)、CiTO4Data本体等,工作流本体如Open Provenance Model(OPM)来源模型,Janus科研工作流本体,科研证据本体Evidence Ontology(ECO)分别在粗粒度层次揭示科学数据的科研属性特征,如机构、项目、科学工作流、数据引用、证据作用等[6]。李丹丹探索将这些属性都集成在一个本体设计中[7]。第二类是通用的科学实验本体或科学数据本体。这类本体对科学数据的科学过程场景抽象化,通过重用已有本体属性,描述科学数据在科研属性(机构、作者)、主题及与文献关联等方面的特征。如Brahaj A设计的科学调查核心本体(Core Ontology for Scientific Investigations,COSI)[8]、Chalk S J提出的Scientific Data Model[5],鲜国建提出的农业领域的科学数据与科技文献语义关联模型[9]、马雨萌等设计的科学数据语义组织框架[10]均是属于此类关联本体。第三类本体是面向具体学科领域的科学数据本体,这类本体多结合具体的领域知识(叙词表或分类法),重点关注领域知识间的相互关系,数据仅是知识的载体形式,海洋领域本体MarineTLO[11],中医胃病科学数据本体[12]、水稻基因实验本体[13],植物学基因表达实验元数据模型[14]均是此类本体或描述。第四类本体与文内数据有关。科学论文内容本体揭示科学论文各部分的属性,部分本体对文内数据提供简单描述。DoCo[15],Discourse Elements Ontology(DEO)[16]等本体定义了文献内部的图、表等组件,描述它们的标签、图表框,未深入描述图表的内容。科学论文功能单元本体[17]尝试定义文内数据的数据分析、数据描述内容,并匹配文内数据的知识类型属性(如确定性程度、情感倾向、来源),但未进一步细粒度分解文内数据内容。上述4类本体均不是专门面向文内数据组织,未能解决文内数据细粒度描述及发现问题。
近年来,得益于自然语言处理技术和机器学习算法的不断改进,加之机器学习在处理细粒度、大规模数据挖掘上的天然优势,许多研究者尝试基于计算机机器学习技术,并结合相关本体对科学论文中的图表实施信息抽取及语义标注,实现图表发现。Siegel N等设计了FigureSeer工具,它是一种新颖的端到端框架,该框架可以自动地定位、分类研究论文中的折线图、散点图、流程图、Graph Plots图块、数学算法、条形图、表格等格式图形,实现折线图数据和数据标签内容的准确提取[18]。WebPlotDigitizer(条形图、二维折线图、极坐标图、三元相位图、地图)[19]、ChartSense(线图、面积图、雷达图、条形图、饼图)[20]、ReVision(柱状图、饼图)[21]、Scatteract(散点图)[22]等半自动工具,在人工帮助确定坐标轴、颜色、基点位置等信息后,也可抽取和标注图表数据。Kembhavi A等引入了一种图解析图(Diagram Parse Graphs,DPG)的方法,识别文献中视觉插图(如食物链图、大气循环图等)的插图元素,并建立元素之间的语义关系,使之用于知识问答系统[23]。Lee P等提出一种从系统树图(Dendrograms)中提取信息的新方法,自动识别科学文献中的系统树图,提取树结构的关键成分,重建树,恢复树的层次关系[24]。SemAnn利用PDF文档解析工具PDF.js和自定义抽取算法将PDF文档中人工选中的表格转换为CSV格式,然后利用CSV-To-RDF转换工具结合嵌入本体(如DBpedia、FOAF或自定义)实现对抽取出来的表格数据进行半自动的语义标注[25]。Cao H等通过构建观测事件模型,借助本体工具,利用规范化的观测术语、实体对象,将观测数据表格转化为可理解的事件,从而进行语义标注[26]。
机器学习、抽取、标注的方法在文内数据识别、抽取、显性信息理解等方面有一定优势,但广范围应用受到限制。提取和理解数据内容需要借助本体,尤其是数据理解。同时由于面向特定对象,且机器分类、提取精准度低于85%,现有技术方法并不能移植到实际应用中。此外,现有技术也无法让机器理解文内数据和科学论文在研究属性(如论证作用、假设、结果、方法等)上的隐性关联。
综合上述调研发现,现有的3种方式均存在自身局限性。本研究试图结合本体构建和机器语义标注两种方式,构建专门面向细粒度內容描述的文内数据本体,提出基于本体的文内数据细粒度发现及关联科学论文的技术路线,推动科学数据细粒度发现。
2 文内数据定义及发现场景
文内数据是指在论文、专著、专利、会议文献、网络信息资源等科学文献中用以描述示例、内容解释、论述佐证、信息展示的异构媒体内容,比如图、表、公式、数据集等。它是科学数据在文献中的表现形式之一。文内数据是一个复合化的信息载体,它具有文章内容片段,科学数据片段的双重身份的特点,也是整个科学研究的重要组成部分。因此从复合的信息内容看,文内数据包括文章信息(例如章节位置、上下文内容、论证支持),数据信息(如数据引用,数据来源方式),科学研究信息(如支持假设、数据结论、研究方法、主题等),此外文内数据本身有固有特征(如媒体类型)。
科研人员在查看文献中的图表数据时,通常需要结合图表标题、图例、图注(包括图内和图后)、数据标签、图表的上下文解释理解图表内涵。此外,从图表数字中得出的关键推论有时不会在文本中明确地表述出来(因为人们可以很容易地从视觉上推断出来)。科研人员希望可以通过图表来访问图表的原始数据,能够检索到图表中隐藏的推论(例如数据趋势、特征点),基于关键词检索找到含有相同研究结论、使用相同研究方法的其他数据或论文,抑或是根据图表中的某个数据参数来追踪后续研究。上述需求场景涉及文内数据的多个属性以及与科学论文、科学数据集以及科学研究的关联交互。
从科研人员利用文内数据的角度,笔者描述3种文内数据发现场景。
1)基于文内数据显性特征的发现。文内数据显性特征主要包括媒体特征(图表类型)、图例,元数据(如标题、关键词)。科研人员可以基于这些特征缩小发现范围,查找特定类型、含特定图例信息的文内数据。
2)基于文内数据内容属性的发现。文内数据的内容属性包括数据参数、数据特征、数据结果、主题、学科等。既涵盖在上下文或图注部分容易获取的内容(数据结论、主题、学科),也包括需要深度理解才能得到的隐藏知识内容,如数据参数、数据特征。
3)基于关联研究属性的发现扩展。文内数据通过引用、论证作用、隶属关系(如数据隶属于某篇文章、某个研究)、研究主张(研究假设、研究结果、研究主题等)、科学方法等与其他类型的科学产出(如科学论文、科学数据集)建立关联。研究人员可以基于这些特征扩展检索范围,实现跨类型的知识发现。
基于上述理解,本研究采用本体构建的方式,尝试将文内数据所包含的多方面的信息内容形式化,以反映核心内容及其背景、语境信息、关联,方便知识的集成、推理和发现。
3 本体框架构建
借助本体构建编辑工具Protégé,在明确本体范围和应用范围的前提下,笔者分析、总结并抽象化实际科学论文中文内数据所包含、关联的相关信息,咨询领域专家,结合文献调研,借鉴已有的科学数据相关本体和描述,并复用相关本体类目和属性,构建一个专门面向文内数据发现的应用本体。
文内数据的本体框架:通过语义建模,将上文中3种场景抽象概念化,建立概念实体间的语义关系,形成细粒度文内数据的描述本体。本体主要组织框架如图1所示。
设计的本体从显性特征、内容特征以及文内数据与其他类型的科学产出的关联特征3个维度对文内数据进行描述。
揭示显性特征的概念包括媒体特征、图例、元数据等。在媒体类型部分,文内数据本体定义了图、表格、复合图、公式、图片5大类45种格式的数据类型,并尝试建立数据媒体类型和数据特征之间的关系。元数据描述是对信息实体的简单描述,这里的信息实体包括文内数据、科学数据、科学论文、科学研究。如文内数据的元数据有标题、关键词、引用、数据来源等,科学研究的元数据有角色、机构、基金、关键词等。
揭示内容特征的概念包括数据特征、数据参数、数据结果、主题、学科等。主题、学科是描述
领域知识及建立领域知识关联时常用的概念,在文内数据本体内,将其列入科学研究的科学主张概念下,用于揭示不同科学产出类型的领域知识。
数据特征、数据参数、数据结果揭示文内数据的深度理解内容。数据特征用于描述图表所特有的表达特性,例如折线图表达的趋势,柱状图表达的数值最大、最小,散点图表达的数值集中、分散情况,流程图表达的对象相关关系等。数据特征通常结合数据参数内容,共同揭示文内数据的数据结论内容。
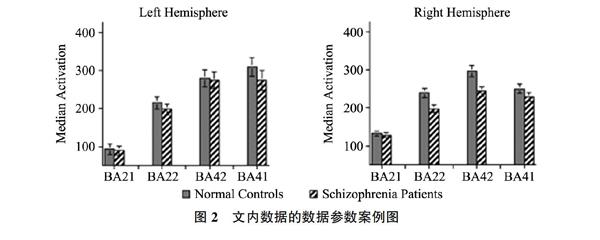
文内数据的数据展示部分比较复杂,它有不同类型,如数值、流程、关系、成像特征等,也有多重信息,如数据标题、图注标签、坐标轴标签信息。为了让计算机能够理解这些信息,本研究在本体中将其描述为参数对象在某条件下,某个度量单位的值,即数据参数概念。参数对象是指文内数据描述内容、特征的主体对象,条件则限定了参数对象所处的实验或者测量环境,一个参数可以限定零到多个条件。度量是文内数据参数对象所要衡量的维度,而度量值是在度量维度下的取值,两者共同组成了参数对象的数值描述部分。度量分为不同的类型,其对应度量值的不同类型。例如图2左侧第一条的数据可以描述为基因左侧大脑皮层颞中回BA21(参数对象)在健康情况下的(条件)左脑(条件)其激活中值(度量)为100(度量值)。又如图2中的对象可以描述为文内数据(参数对象)有属性(度量)是科学主张(度量值)。
数据结果指文内数据所阐释的研究结果。部分作者会直接在文内数据下方的图注部分或者论文的数据描述部分阐释关键的数据结果,但也存在作者不在科学论文内解释那些能从文内数据视觉特征中获取的数据结果的情况。面对这种情况,数据结果需要结合文内数据的数据特征以及数据参数推论获得。
关联特征主要揭示了文内数据和科学论文、科学数据集在引用、论证作用、隶属关系、研究主张
(研究假设、研究结果、研究主题等)、科学方法等方面的关联。文内数据隶属于科学论文,它为不同的科学论文功能模块提供多样化的论证作用(如解释说明、证据支撑、反驳观点等),文内数据是科学数据的一种类型,它和外部科学数据集存在可能的隶属、引用或相关(基于数据集数据加工而来等)关系。此外,文内数据、科学论文、科学数据集都属于科学研究的产出,它们都具有科研的属性,因此在科学主张、科学方法上存在关联,例如拥有同样主题或包含的主题存在领域相关关系,拥有同样的研究假设,所产生的研究结果存在继承、论证及相关关系,使用类似的科学方法(包括方法和流程)等。
4 基于本体的文内数据知识发现技术框架及路线
文内数据本体为科学论文内科学数据提供语义描述和关联组织依据,可以应用在专业文献发现平台或综合性的学术搜索引擎的语义组织层,帮助实现基于科学数据细粒度特征的文内数据检索及文献聚类,以及为面向跨类型、细粒度的学科知识发现、关联、推荐奠定基础。
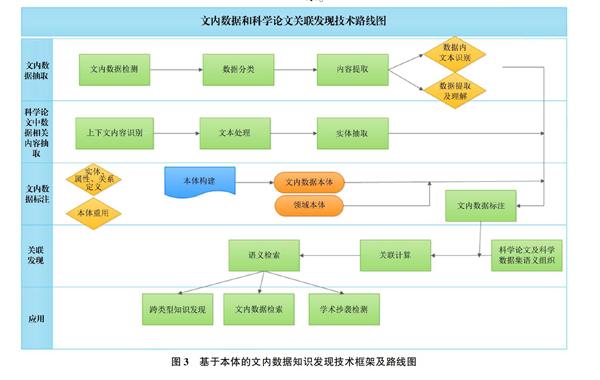
基于所设计的文内数据本体,本研究提出基于本体的文内数据知识发现技术框架路线,如图3所示。
文内数据信息抽取是文内数据发现的基础,基于本体的文内数据标注则是将现实应用中的文内数据实例和抽象化的本体概念进行关联的过程,基于领域知识及数据组织关系的文内数据细粒度检索及关联发现是本体面向应用的最终目的。
4.1 信息抽取
信息抽取的精准度直接影响到文内数据发现的查全率及查准率。文内数据信息来源分兩部分,一部分来自数据本身,如数据点、坐标轴、数据内图注、图例等,这部分内容以非文本内容为主,一部分来自数据上下文,这部分内容以纯文本为主,包括数据区域外的数据解释,科学论文上下文中的数据描述、分析及结论。因而,针对不同格式的信息,将抽取任务细分为非文本类型的文内数据信息抽取和文本类型的文内数据信息抽取两类。
非文本类型的文内数据信息抽取过程是识别文献中科学数据的边界,区分数据类型,基于数据的类型特征抽取其结构、数据点等信息,并借助一定的组织模式(如本体)建立可理解的信息展示。从技术实施看,分为数据检测、数据分类、数据内文本识别、数据提取及理解4个步骤。而基于不同数据类型,信息抽取分不同技术方法。表1对文内数据常见的图、表两类数据的抽取技术进行总结。
文本类型的文内数据信息抽取相比非文本类型抽取较为简单。其步骤有数据上下文内容识别、文本处理、实体抽取、实体标注。目前已有诸多自然语言处理技术方法用于文本信息抽取,本文也不在此进行赘述。
4.2 数据标注
文内数据标注是赋予信息抽取内容以语义,建立本体概念或实例和待标注词汇之间映射的过程。此模块涉及文内数据本体构建,基于本体的数据标注两方面。
本体详尽程度会直接影响到标注的关联及发现效果。文内数据本体对文内数据及其关联的特征进行通用化的定义,而应用于具体领域知识发现时,需要结合相关的领域知识本体(如MESH、GO本体)等来标注文内数据的领域知识属性。
人工标注和基于机器学习的自动标注是语义标注可选的两种方式。面对大规模、细粒度的数据、论文标注任务时,自动标注具有明显的优势。但自动标注并不适合所有的标注任务。在文内数据的标注任务中,文内数据的媒体类型、元数据、部分科学主张属性(如主题、方法、研究结论)可以采用机器学习算法(如支持向量机、卷积神经网络等)来帮助自动标注,而数据特征、数据参数、论证作用等内容的标注,目前适合借助GATE、Annotea等标注工具来人工标注。标注结果以RDF三元组的形式进行存储。
4.3 应 用
基于标注数据集和本体推理机,借助语义检索发现工具,可以实现文内数据的细粒度语义检索,跨类型的知识发现与推荐,知识深度聚合以及辅助检测文内数据重复。
细粒度的文内数据组织可以使文内数据能够像文献一样,通过主题词或者数据特征来直接检索特定数据,例如可以检索发现含有“精神病患者、不同大脑皮层激活区域、数据对比”或“运用本体构建方法并含有科学数据元素”的图或者表格,并关联到图表所在的文章,若图表与外部科学数据集存在引用等关系,也可建立起文章—文内数据—科学数据集的关联。在此基础上,可以实现特定知识的科学文献片段、文内数据以及数据集的聚合,帮助发现新研究思路及跨学科的研究。
此外,文内数据的细粒度组织描述还可以帮助发现在不同论文中重复使用同一个图片或表格的现象,有助于出版社检测发现剽窃抄袭图表数据等学术不端行为,这是目前出版行业需要的功能。
5 结 语
未来的知识发现是面向细粒度、跨类型、分布式仓储、计算机可理解及语义聚合。文内数据作为知识单元的一环,其价值正逐渐被重新重视。本研究对细粒度的文内数据发现进行初步探索,通过构建文内数据本体并提出基于本体的知识发现框架,尝试同时解决文内数据的深度语义理解和文内数据—文献—数据集跨类型关联发现两个问题。本研究的不足在于未深入验证文内数据本体的效果以及未对文内数据发现的技术进行实证研究,这是下一步研究工作的方向。
参考文献
[1]Sandusky R J,Tenopir C,Casado M M.Figure and Table Retrieval from Scholarly Journal Articles:User Needs for Teaching and Research[J].Proceedings of the American Society for Information Science and Technology,2007,44(1):1-13.
[2]Sandusky R J.Deep Indexing and Discovery of Tables and Figures[EB/OL].http://www.niso.org/news/events/2008/discovery08/agenda/sandusky.pdf,2019-05-02.
[3]Hearst M A,Divoli A,Guturu H,et al.Biotext Search Engine:Beyond Abstract Search[J].Bioinformatics,2007,23(16):2196-2197.
[4]曹树金,李洁娜,王志红.面向网络信息资源聚合搜索的细粒度聚合单元元数据研究[J].中国图书馆学报,2017,43(4):74-92.
[5]Chalk S J.Scidata:A Data Model and Ontology for Semantic Representation of Scientific Data[J].Journal of Cheminformatics,2016,8(1):54.
[6]丁培.科学文献与科学数据细粒度语义关联研究[J].图书馆论坛,2016,36(7):24-33.
[7]李丹丹.基于科学工作流的研究数据组织关联模型研究[D].北京:中国科学院大学,2013.
[8]Brahaj A.Semantic Representation of Provenance and Contextual Information in Scientific Research[D].Humboldt-Universitt zu Berlin,Philosophische Fakultüt I,2016.
[9]鲜国建.农业科技多维语义关联数据构建研究[D].北京:中国农业科学院,2013.
[10]马雨萌,郭进京,王昉.e-Science 环境下科学数据语义组织模型框架研究[J].現代图书情报技术,2015,(Z1):48-57.
[11]Farcas C,Meisinger M,Stuebe D,et al.Ocean Observatories Initiative Scientific Data Model[C]//Oceans11 MTS/IEEE KONA.IEEE,2011:1-10.
[12]徐坤,蔚晓慧,毕强.基于数据本体的科学数据语义化组织研究[J].图书情报工作,2015,59(17):120-126.
[13]徐潇洁,何琳,陈雅玲,等.面向关联数据的科学实验数据语义描述模型研究——以水稻基因实验为例[J].图书馆,2017,(1):61-66.
[14]常颖聪,何琳.科学实验数据元数据模型构建研究——以植物学基因表达实验为例[J].图书情报工作,2015,59(13):117-125.
[15]Constantin A,Peroni S,Pettifer S,et al.The Document Components Ontology(Doco)[J].Semantic Web,2016,7(2):167-181.
[16]The Discourse Elements Ontology(DEO)[EB/OL].https://sparontologies.github.io/deo/current/deo.html,2019-05-02.
[17]王晓光,李梦琳,宋宁远.科学论文功能单元本体设计与标引应用实验[J].中国图书馆学报,2018,(4):73-88.
[18]Siegel N,Horvitz Z,Levin R,et al.Figureseer:Parsing Result-Figures in Research Papers[C]//European Conference on Computer Vision.Springer,Cham,2016:664-680.
[19]Rogatgi A.WebPlotDigitizer[EB/OL].https://automeris.io/WebPlotDigitizer/,2019-05-02.
[20]Jung D,Kim W,Song H,et al.Chartsense:Interactive Data Extraction from Chart Images[C]//Proceedings of the 2017 Chi Conference on Human Factors In Computing Systems.ACM,2017:6706-6717.
[21]Savva M,Kong N,Chhajta A,et al.Revision:Automated Classification,Analysis and Redesign of Chart Images[C]//Proceedings of the 24th Annual Acm Symposium on User Interface Software and Technology.ACM,2011:393-402.
[22]Cliche M,Rosenberg D,Madeka D,et al.Scatteract:Automated Extraction of Data from Scatter Plots[C]//Joint European Conference on Machine Learning and Knowledge Discovery in Databases.Springer,Cham,2017:135-150.
[23]Kembhavi A,Salvato M,Kolve E,et al.A Diagram is Worth a Dozen Images[C]//European Conference on Computer Vision.Springer,Cham,2016:235-251.
[24]Lee P,Yang S T,West J D,et al.Phyloparser:A Hybrid Algorithm for Extracting Phylogenies from Dendrograms[C]//2017 14th Iapr International Conference on Document Analysis and Recognition(Icdar).IEEE,2017,(1):1087-1094.
[25]Takis J,Islam A Q M,Lange C,et al.Crowdsourced Semantic Annotation of Scientific Publications and Tabular Data in Pdf[C]//Proceedings of the 11th International Conference on Semantic Systems.ACM,2015:1-8.
[26]Cao H,Bowers S,Schildhauer M P.Approaches for Semantically Annotating and Discovering Scientific Observational Data[C]//Database and Expert Systems Applications.Springer Berlin Heidelberg,2011:526-541.
[27]Ray Choudhury S,Giles C L.An Architecture for Information Extraction from Figures in Digital Libraries[C]//Proceedings of the 24th International Conference on World Wide Web.ACM,2015:667-672.
[28]唐皓瑾.一種面向PDF文件的表格数据抽取方法的研究与实现[D].北京:北京邮电大学,2014.
[29]Huang W,Zong S,Tan C L.Chart Image Classification Using Multiple-Instance Learning[C]//2007 Ieee Workshop on Applications of Computer Vision(Wacv07).IEEE,2007:27-27.
[30]Prasad V S N,Siddiquie B,Golbeck J,et al.Classifying Computer Generated Charts[C]//2007 International Workshop on Content-Based Multimedia Indexing.IEEE,2007:85-92.
[31]Tang B,Liu X,Lei J,et al.Deepchart:Combining Deep Convolutional Networks and Deep Belief Networks in Chart Classification[J].Signal Processing,2016,124:156-161.
[32]Crestan E,Pantel P.Web-Scale Table Census and Classification[C]//Proceedings of the Fourth Acm International Conference on Web Search and Data Mining.ACM,2011:545-554.
[33]Fang J,Mitra P,Tang Z,et al.Table Header Detection and Classification[C]//Twenty-Sixth Aaai Conference on Artificial Intelligence,2012.
[34]Kim S,Liu Y.Functional-Based Table Category Identification in Digital Library[C]//2011 International Conference on Document Analysis and Recognition.IEEE,2011:1364-1368.
[35]蒋梦迪,程江华,陈明辉,等.视频和图像文本提取方法综述[J].计算机科学,2017,(2):8-18.
[36]Ye Q,Doermann D.Text Detection and Recognition in Imagery:A Survey[J].Ieee Transactions on Pattern Analysis and Machine Intelligence,2015,37(7):1480-1500.
[37]Nagy G.Learning the Characteristics of Critical Cells from Web Tables[C]//Proceedings of the 21st International Conference on Pattern Recognition(Icpr2012).IEEE,2012:1554-1557.
[38]Seth S,Nagy G.Segmenting Tables Via Indexing of Value Cells By Table Headers[C]//2013 12th International Conference on Document Analysis and Recognition.IEEE,2013:887-891.
[39]Berkley C,Bowers S,Jones M B,et al.Improving Data Discovery for Metadata Repositories Through Semantic Search[C]//International Conference on Complex,Intelligent and Software Intensive Systems.Fukuoka:IEEE,2009:1152-1159.
[40]Bischof S,Martin C,Polleres A,et al.Collecting,Integrating,Enriching and Republishing Open City Data As Linked Data[C]//International Conference on the Semantic Web-Iswc 2015.Berlin:Springer,2015:58-75.
(責任编辑:陈 媛)
