走向多元化的“堆栈”:作为技术问题的数字人文和多样性①
2020-08-14艾伦刘撰张思静译陈大龙校
[美]艾伦·刘撰 张思静译 陈大龙校
(加州大学 圣芭芭拉分校,美国 加利福尼亚州圣芭芭拉 93106-3170)
就像在一般人文领域中那样,多样性在数字人文中指的是包容不同的文化、身份、民族,不管是将其作为研究的对象,还是指研究群体本身。尤其要重视那些缺少代表的种族、性别、国家、语言、能力和社会经济阶层。和一般人文领域不同的是,数字人文的多样性还包括对各种技术方法的包容——例如,编码和转译、规划大量样品的陈列和制作一次性的展览、文本的数码转换和文本分析、研究和教学。不过,从根本上说,方法的包容也是社会文化的包容,因为它的目标是尊重全世界的各类数字人文实践。(4)关于世界各地本土化的数字人文实践,参见Earhart, Amy E, “Digital Humanities within a Global Context: Creating Borderlands of Localized Expression”, Fudan Journal of the Humanities and Social Sciences, vol. 11, no. 3, (2018), pp. 357-69, doi:10 .1007/s40647-018-0224-0. 不同的国家对不同种类的数字人文工作的投入是不平衡的。例如,那些更重视将民族或土著遗产数字化的国家会将更多的数字人文技术和资源投放在画廊、图书馆、档案馆和博物馆。虽然学界还没有对不同国家的数字人文实践和优先级进行大规模的、系统化的比较研究,一些对具体国家和数字人文部门的研究却已经展开。参见,例如,Kizhner, Inna, et al, “Accessing Russian Culture Online: The Scope of Digitization in Museums across Russia”, Digital Scholarship in the Humanities, (19 Sept. 2018), doi: 10.1093/llc/ fqy035. Lewis, Vivian, et al, Building Expertise to Support Digital Scholarship: A Global Perspective, Council on Library and Information Resources, (2015), www.clir.org/pubs/reports/pub168/pub168. Cha, Javier, “Digital Korean Studies: Recent Advances and New Frontiers”, Digital Library Perspectives, vol. 34, no. 3, (Aug. 2018), pp. 227-44, doi:10.1108/DLP-04-2018-0013. )。同时参见费尔蒙特(Fiormonte)和盖丽拿·罗塞尔(Galina Russell)对数字人文领域所谓“地理政治和……文化语言”的不平衡所作的精辟批评。Fiormonte, Domenico, “Toward a Cultural Critique of Digital Humanities”, Debates in the Digital Humanities 2016, edited by Gold, Matthew K., and Lauren F. Klein, (U of Minnesota P, 2016), pp. 438-58. Galina Russell, Isabel, “Geographical and Linguistic Diversity in the Digital Humanities”, Literary and Linguistic Computing, vol. 29, no. 3, (Sept. 2014), pp. 307-16, doi:10.1093/llc/ fqu005.
数字人文领域最包罗万象的比喻是“大帐篷”(big tent)。这一概念隐含上述所有意义上的包容性,是数字人文多样性平台在意识形态层面的一种极富野心的模因(meme)。这一复制传递方式源于数字人文联合机构(ADHO)于2011年召开的年会。(5)数字人文组织联盟会议是这个领域内最重要的年度国际会议,它每年在世界的一个不同地区举行。那次会议强调的是方法多样性。会议组织者马修·乔克斯(Matthew Jockers)和格伦·沃特希(Glen Worthey)解释说:
我们为数字人文2011年会选择的主题是“大帐篷数字人文”,这在一定程度上是为了表达我们想要包容不同形式的数字人文的愿望。眼下,在斯坦福,我们就被各种不同的数字人文实践所环绕。与此同时,数字人文在世界范围内都激发了热烈的讨论,尤其是在过去几年中,有关这一学科的意义和局限性备受争议。在我们看来,“大帐篷”是回应这些争论的恰切比喻。虽然数字人文2011年会属于每一位参与者,但是,通过选择这一主题,我们想要公开宣布我们的观点:斯坦福大学相信并希望推动的数字人文是具有广泛性和多样性、生机勃勃、千花齐放的数字人文。(6)Jockers, Matthew, and Glen Worthey, “Welcome to the Big Tent.” Introduction, Digital Humanities 2011, Conference Abstracts, p. vi. Stanford University Library, dh2011.stanford.edu/wp-content/uploads/2011/05/DH2011_BookOfAbs.pdf.本次会议的主题“大帐篷数字人文”,最初是在会议的征稿启事中公布的。“Call for Papers Announcement” DH2011, dh2011.stanford.edu/page_id=97.
2012年在汉堡举行的ADHO会议则突出了多样性的社会文化方面。会议的主题是“数字多样化:文化、语言和方法”,而组织者特别强调了其中的多文化主义和多语言主义。(7)“Call for Papers”, DH2012, www.dh2012.uni-hamburg.de/conference/archive-calls/cfps/index.html.
随后,数字人文蓬勃发展,即使不是伴随着乔克斯、沃特希呼吁的“千花”,至少是伴随着对“大帐篷”这一比喻的复制和传递。在数字人文领域,“大帐篷”被以各种基调反复提及,有些是赞扬,有些是谨慎,有些讨论它的资格,有些则表达了批评或讽刺。根据2018年现代语文学会(MLA)年会上同名小组所做的项目介绍,数字人文“具有扩张性和移动力,然而又缺乏稳定性。就多样性和可接触性而言,它是一顶还不够大的帐篷”(8)“347: Varieties of Digital Humanities”, MLA 2018 NYC. Modern Language Association, mla.confex.com/mla/2018/meetingapp.cgi/Session/2517.Varieties of Digital Humanities, MLA Annual Convention, (5 Jan. 2018, New York Hilton Midtown).。
很显然,“大帐篷”这一形象来自历史上群众经验的展示,比如19世纪的宗教营会和马戏团的帐篷表演。(9)特拉斯(Terras)将这一比喻更多地归结于宗教而非马戏团历史。我把“大帐篷”传统的宗教性(尤其是福音派教会的)和大众娱乐性放在一个单一的、更笼统的框架中来解读。基里亚迪克斯(Kyriakodis)讨论了美国发生在1858年所谓的“第三次大觉醒”期间的一系列帐篷复兴事件。也可参看下文中我关于第二次大觉醒的评论。马戏团起源于18世纪后期,但它们的鼎盛时期是19世纪,尤其是在美国。“大帐篷”(或者说“大顶”)马戏团是1825年发明的(Davis)。Terras, Melissa, “Peering inside the Big Tent: Digital Humanities and the Crisis of Inclusion”, Melissa Terras’ Blog, (26 July 2011), melissaterras.blogspot.com/2011/07/peering-inside-big-tent-digital.html. Kyriakodis, Harry, “Before the Pope, the Days of the Revivalists”, Hidden City Philadelphia, (26 Aug. 2015), hiddencityphila.org/2015/08/before-the-pope-the-days-of-the-revivalists/.Davis, Janet M, “America’s Big Circus Spectacular Has a Long and Cherished History”, Smithsonian.com, (22 Mar. 2017), www.smithsonianmag.com/history/americas-big-circus-spectacular-has-long-and-cherished-history-180962621.这只是众多例子中的两项,向我们展示了早期由帐篷构建的建筑、制度和奇观,以及其背后有关多样性“装置”——这里,我们借用了米歇尔·福柯的术语——的散漫习俗和信仰体系。在福柯的定义中,“装置”本身就具有多样化的形式,是一种“变化的多样体”(metavariety):
一个彻底混杂的集合体,包含了话语、制度、建筑形式、管理决策、法律、行政措施、科学陈述以及哲学、道德和慈善命题。简而言之,已经被表述的和没有被表述的内容同样丰富。这些就是“装置”的要素。“装置”本身就是由这些要素构成的关系网络。(10)Foucault, Michel, Power/ Knowledge: Selected Interviews and Other Writings, 1972-1977. Edited by Colin Gordon, translated by Gordon et al. (Pantheon, 1980), p.194.
尤其是,宗教营会和马戏团在建筑和制度方面那既开放又封闭的散漫结构是大规模多元“装置”在前现代时期的雏形。它们在幕后引导了一场漫长的、逐渐走向现代化的融合。这一融合同时具有宗教性和世俗性、民主性和法西斯主义,连接了古老的、基于亲缘关系而产生的民族感和逐步发展的社会、性别、种族、阶级和政治地理意识。在马戏团的例子中,这种意识尤其具有特殊性,因为它构建了物种、国家和世界的多样性。与美国“第二次大觉醒”(Second Great Awakening)有关的露营集会和帐篷复兴反映了这种融合。不同形式的露营集会和帐篷复兴吸引了黑人、妇女、区域性边缘人口的大规模参与,造成了深远的社会文化和政治影响。马戏团用另一种方式实现了同样的融合。例如,最大规模的马戏团帐篷演出使我们得以见证一种后帝国主义时代的多元化。这种多元化跨越物种、种族和民族,具有全球性的异国情调。正如19世纪晚期巴纳姆贝利马戏团的一张将世界各地的人种、国家与各种动物并置描绘的海报所宣传的那样,马戏团“让我们得以一窥伟大的种族融合”并亲临“神奇动物的园地”。(11)The Barnum and Bailey Greatest Show on Earth—A Glance at the Great Ethnological Congress and Curious Led Animals. (Circa 1895), Strobridge Lithography, Library of Congress Prints and Photographs Online Catalog, www.loc.gov/pictures/item/98500053.Chromolithograph.
我们可以很容易地将更早或更晚的装置加入正在逐步现代化的、既开放又封闭、既包容又排他的大规模多样性展示中去,就像巴黎战神广场(Champs de Mars)的例子所见证的那样。这座广场在1790年的改造中广为人知地召集了各个阶层的巴黎人。(12)奥左夫(Ozouf)研究了在这个广场以及其他法国革命纪念活动中有关开放性的意识形态,主要参考她在《节日和法国革命》中的“节日与空间”那章(126-57)。Ozouf, Mona. Festivals and the French Revolution. Translated by Alan Sheridan, (Harvard UP, 1988).位于德国纽伦堡、四周环绕着探照灯的纳粹党代会集会广场(Zepplin field)展示了纳粹党基层在地区、年龄、性别方面的多样性。还有眼下“开放源代码”的概念性结构(埃里克·S·雷蒙德曾令人难忘地指出,这种结构不是“教堂式”的,而是“集市型”的(13)Raymond, Eric S, The Cathedral and the Bazaar: Musings on Linux and Open Source by an Accidental Revolutionary, (O’Reilly Media, 2001).)都是如此。在这些例子中,即使是看起来最开放的现代大众共同体之典范,在某些对开放性持不同观点的人看来仍像是封闭的警察国家。例如,理查德·斯托曼(Richard Stallman)就曾声称,和自由软件运动(free-softward movement)相比,开放源代码的软件就是封闭的。(14)斯托曼写道:“任何宣传‘开放’二字的活动,往往会扩大遮盖了自由软件运动思想的帷幕。”Stallman, Richard, “Why Open Source Misses the Point of Free Software” (2011). GNU Operating System, Free Software Foundation, (2016), www.gnu.org/philosophy/open-source-misses-the-point.en.html.
因此,数字人文领域对“大帐篷”理念的一个意见正是这一“帐篷”还不够开放。从这一概念流行以来,“谁在帐篷里面,谁又在外面?”始终是困扰这一领域的问题。在2011年现代语言学会年会上的数字人文小组中,是否只有懂编码的人才能成为这一领域的局内人引起了争论。(15)这方面的避雷针是史蒂芬·拉姆塞(Stephen Ramsay)在2011年现代语文学会年会上的演讲《谁在里面,谁又在外面》(发布于他的博客)。Ramsay, Stephen, “Who’s In and Who’s Out”, Stephen Ramsay, (8 Jan. 2011), Internet Archive, web.archive.org/web/20121001072912/http://lenz.unl.edu/papers/2011/01/08/whos-in-and-whos-out.html.不管数字人文是多么渴望打开门户,对一些人来说,专业技能、训练方式和制度方面的标准把持住了这一学科的门槛。尤其是那些事业刚刚起步的学者,对多样性和社会公正的高度在意让他们怀疑数字人文这一领域对他们来说是否太封闭了。“#转型数字人文”(#transform DH)小组成员曾令人动容地表示:
那是2011年。那一年,“数字人文大帐篷”作为术语冒出地表。它将数字人文描绘为具有包容性、欢迎不同学科的领域。然而,对于我们这些研究性别、同性恋、种族、残障人士,并且在个人和政治工作中都用到数字技术的学者来说,“大帐篷”还是显得不够大。我们对社会公正的忧虑很少真正进入研究和讨论的视野,即使在数字人文领域的这顶“大帐篷”内仍是如此。(16)Bailey, Moya, et al, “Reflections on a Movement: #transformDH, Growing Up”, Debates in the Digital Humanities 2016, edited by Gold, Matthew K., and Lauren F. Klein, (U of Minnesota P, 2016), p. 72.据其网站所说,#transform DH是“一场学术游击运动,以求再定义大写的数字人文学科,通过收集、分享和强调那些拓展边界、追求社会公正、亲民和具有包容性的项目,使之成为推动学术变革的力量”。“About #transformDH.” #transformDH, transformdh.org/about-transformdh/.
这一小组的名称来源于其在推特上的标签。跟一般的数字人文一样,这一团体较早地将社交媒体、博客、在线平台运用于学术研究,不管这些平台是由硅谷的公司还是由学术界提供的(最先被使用的网络平台包括人文学讨论小组[Humanist Discussion Group, humanist@lists. digitalhumanities.org]和HASTAC学者论坛[www.hastac.org/initiatives/harstac-scholars]。后来则发展出更新的专业联盟,像MLA联合会[mla.hcommons.org/],它的前身是CUNY学术联盟[commons.gc.cuny.edu/])。社交媒体、博客,以及数字化联盟看起来是比“大帐篷”更开放的帐篷。
然而,在这种时候,我们应该停下来思考一下数字人文对在线平台的大量使用所透露的其他信息:“大帐篷”的比喻和在这一领域内发挥着实际作用的技术平台之间存在着明显的不匹配。“大帐篷”在意识形态层面赋予数字人文多样性的名义,但在技术层面却没有提供任何的指导。更仔细地说,问题的关键不在于意识形态和技术之间的二元差异,而是该领域还没有认识到他们需要一个融合了技术与意识形态的装置——一个在任何意义上的平台——以处理急需的工作。正如人们所使用的比喻从“大帐篷”逐渐向“公共空间”(commons)转变所显示的那样,这种急需的工作是和人文学科接洽,以回应如下问题:那些只有封闭平台的硅谷公司如何利用了各种变化的形式(variety),将其作为汇集、过滤、描述后的集合体,却没有真正专注于多样性(diversity)。
那么,对数字人文的多样性真正有效的、既具有意识形态的比喻性又能有助于实际操作的平台应该是怎样的呢?在下文中,我将提供部分答案。之所以说这个答案是“部分”的,是因为它侧重于研究和思考多样性所需要的技术革新,却没有涉及如何提高数字人文从业人员的多样性——无论是在人文领域、学术界,还是在一般的知识工作机构。(17)关于数字人文学者团体对多样性的讨论和由数据驱动的分析(尤其是ADHO年会所反映的),参见Eichmann- Kalwara, Nickoal, et al, “Representation at Digital Humanities Conferences (2000—2015)”, Bodies of Information: Intersectional Feminism and Digital Humanities, edited by Elizabeth M. Losh and Jacqueline Wernimont, (U of Minnesota P, 2018), dhdebates.gc.cuny.edu/read/untitled-4e08b137-aec5-49a4-83c0-38258425f145/section/5dcc1fee-caef-4c10-aa3c-108a9bbf0b68b#ch0.对包容性的制度化思考影响着数字人文,也受到数字人文的影响。然而,考察这个问题需要借助更多的理论和方法,例如新制度主义(neoinstitutionalism)、组织技术研究(organizational-technology studies)、思辨基础设施研究(critical infrastructure studies)等。我在其他研究场合中采取了这些视角。(18)参见,例如, Liu, Alan, “Drafts for Against the Cultural Singularity (Book in Progress).” (2 May 2016), doi:10.21972/G2B663 和由我创办并维护的“思辨基础设施研究”网站(cistudies.org)。
在这里,我的回答只是想要为数字人文展开完整意义上的“平台”概念。当前,这一概念不免要兼具意识形态性和技术操作性。特别值得一提的是,我将援用本杰明·H·布拉登(Benjamin H. Bratton)强有力的理论注释。在《堆栈:论软件和主权》一书中,布拉登对平台提出了同时兼顾其技术、社会文化和哲学属性的阐释。他令人信服地论证了“堆栈”是当前最重要的平台概念。与之相比,其他竞争对手都只是“网络”(network)。统观全书,布拉登始终用大写的“The Stack”来指称这一概念,以此强调它的终极属性是一种世界体系。“堆栈”是我们这个时代最根本的意识形态和技术平台模式。如布拉登所说,它们既是一种主权形式,又是一套安装在装置中的标准和协议,向下直达环境层面。在本书最精彩的章节之一中,布拉登将这一层面称为“地球层”(the “Earth” layer)(19)Bratton, Benjamin H., The Stack: On Software and Sovereignty, (MIT Press, 2015), pp. 75-107.。
今天,堆栈平台有各种表现形式,其范围从基本的软件结构到布拉登的世界体系“The Stack”。已经成为经典的例子是“互联网协议栈”(Internet Protocol Stack)。我在图1中给出了这一模式的简化版。(20)在描述下文所述的互联网协议栈的时候,我从网上的技术注解、布拉登的书、詹姆斯·史密斯(James Smithies)的《数字人文和数字现代》中“走向人文学的系统分析”一章获得了帮助。我的描述简化了互联网协议栈,忽略了它的一些特定协议和特征。我也没有讨论它和早期的OSI(开放系统互联)堆栈模式的异同。Smithies, James, The Digital Humanities and the Digital Modern, (Palgrave Macmillan, 2017), pp. 113-51.
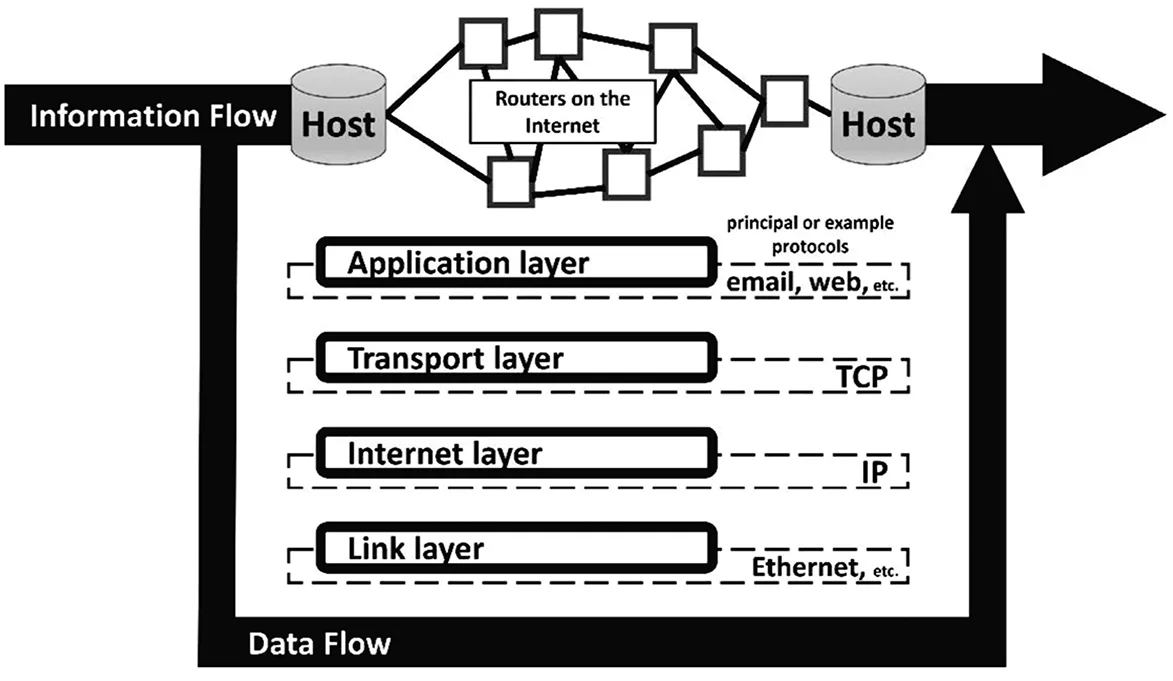
图1 国际互联网堆栈由艾伦·刘综合和改编很多其他可获得的图示绘制
该图显示了信息如何借由路由器构成的网络在主机和主机之间(以及从作为“服务器”的主机到终端用户的)横向流动。这里的“信息”是指经过排序、结构化、验证、配置之后可以被有效利用的良好通信(例如,像电子邮件和网站主页一样可以被阅读的“文件”。)然而,实际上操纵信息的数据流却是上下流动的,形成一个格式化和处理数据的垂直“协议堆栈”(stack of protocols)。用布拉登的话来说,“简而言之,一条信息由用户沿着堆栈逐层发送,直至其穿过物理层横向传输到街对面或大洋彼岸的接收节点。被接收之后,信息又沿着堆栈逆向传递,从物理层到应用层,再被下一个用户读取。”(21)Bratton, Benjamin H., The Stack: On Software and Sovereignty. (MIT Press, 2015), pp. 61-62.
每一个协议层都在其所处的层级执行标准化的数据处理方式。这种方式通过我们称之为数据抽象化(data abstraction)和模块化(modularity)的方式得以实现。抽象化是指最底部的“连接层(link layer)”在一个特定的局域网(例如某部门的以太网)中传输数据。这已经是对物理和电子信号媒体的一种最基本的抽象。然后, “国际互联网层级”(Internet layer)并不管局域系统,是一种更高层级的抽象。它的互联网协议(IP)将数据转化为标准化的数据包(data packets),这种数据包能在一个更广阔的网络中传播。“运输层级”(transport layer)则是一种更高层级的抽象。通过保障数据之间的正确序列、避免拥堵、可靠性等等,它的“运输控制协议”(TCP)将数据包以数据“流”(stream)的形式呈现。位于堆栈最顶端的是“应用层级”(application layer),这一层级的抽象支持复杂的软件应用和计算机界面,正是这些应用和界面最终将数据转变为“信息”(information)供用户使用。
模块化是指堆栈中每一个相对更低的层级都尽可能简单有效地专注于实现有限的目标,将更复杂的功能交给上面一层。与此相对,每一个相对更高的层级可以对下面一层的内部运作保持无视。最明显的例子就是对“互联网层级”和“运输层级”的模块化分离。这一分离基于所谓的端对端系统设计原则(end-to-end system-design principle)而实现。(22)虽然是在早先发展的基础上产生的,现在已成为经典的有关端到端原则的声明是斯特兹(Saltzer)等在80年代初期提出的。Saltzer, J. H., et al, “End- to- End Arguments in System Design.” ACM Transactions on Computer Systems, vol. 2, no. 4, Nov. 1984, pp. 277-88. ACM Digital Library, doi:10.1145/357401.357402.在这一语境中的“端对端”(end-to-end)指的是互联网层级的互联网协议(IP)只需专注于将数据包推送过路由器,而无须保证数据的完整性,甚至无须顾虑它们是否送达。紧接着,运输层级的TCP会在更复杂的上位机上进行操作,从而支持更高层级的任务,例如:建立连接、检查数据包的完整性,以及在收到数据包时为它们排序。
IP协议栈的抽象化和模块化原则上导致了三个后果,这些后果对互联网的技术和社会政治演变产生了重大的影响。第一个后果是层级或平台的不可知论。我的意思是说,堆栈中的每一层都不关心,甚至可能不知道它上面或下面的那一层发生了什么。这就是所谓的网络中立性的基础。这种原则规定了较低的数据层级不应该在速度上受限,或者被操纵以决定诸如“谁的视频流服务在堆栈顶端运行得最好”这类的问题。(事实上,网络中立是一个有争议的问题。因为,为了让较低层级的限制因素能优先阻碍某些服务,层级不可知论会妥协。)第二个后果是创新自由(用硅谷的术语来说)。新的软件和社交应用可以被随心所欲地插入堆栈,只要支持它们的层级仍然在按预期工作。第三个结果则是平台不可知论和创新之间的一个细微差异,我们可以称之为层级化涌现(layered emergence)。这一现象具有重大的技术和思想意义(包括,像我将要论证的那样,在多样性的语境中也是如此)。在堆栈平台底层的半自动运行中会逐步涌现出一些什么东西?这是不确定也不可预测的。它们可能变好,也可能变坏。在布拉登的描述中,和堆栈有关的平台具有17个特征。以下是其中最重要的几个特征:
1.与其他宏观治理机构不同的是,平台并不按照详细的预设性总体规划开展工作,而是通过有序的涌现为行动的展开奠定基础。(23)Bratton, Benjamin H., The Stack: On Software and Sovereignty. (MIT Press, 2015), p. 47.
7.与集权系统一样,平台将异质的行为者和事件整合成更有序的联盟,但平台本身并不一定像总体规划委员会或联邦国会大厦那样,处于这些联盟的真正中心位置。(24)Bratton, Benjamin H., The Stack: On Software and Sovereignty. (MIT Press, 2015), p. 48.
9.即使平台保证了其系统用户的身份,但无论好坏,它们提供的身份并不均匀或平等。(25)Bratton, Benjamin H., The Stack: On Software and Sovereignty. (MIT Press, 2015), p. 49.
17.平台主权可以是有计划的,也可以是无计划的;可以是普世的,也可以是具体的;可以是生成的,也可以是被动的;可以是由技术决定的,也可以是由政治保证的。平台主权在某些情况下是必然的,而在另一些情况下则具有很大的偶然性。并且,它在平台系统的不同组成部分中可能发挥不同的作用。(26)Bratton, Benjamin H., The Stack: On Software and Sovereignty. (MIT Press, 2015), p. 51.
即使是最标准化的、看起来运作良好的低层堆栈之间的相互作用也会顾及更高层级的不同系统和行为的涌现,包括布拉顿所说的,位于他的堆栈世界体系顶层的“用户”(User)。在我们有关多样性的讨论中,我们可以称之为“身份”(identity)。(27)布拉登设想了一个当前时代的“堆栈”,它具有地球、云端、城市、住址、界面和用户这些逐层向上的层级。对布拉登来说,这一“堆栈”中的“用户”包括非人类的形式,例如机器和主题。它们位于基础层上下之间新兴的、具有偶发性的连接“纵向柱”(columns,他如此称之)之上。参见Bratton, Benjamin H., The Stack: On Software and Sovereignty, (MIT Press, 2015), pp. 66-72.
使用上述有关平台堆栈的图表,我对“什么样的平台——既是比喻性的也是操作性的——适用于开展数字人文领域的多样性工作”这个问题提供了部分的答案:它不是一个大帐篷,而是一个多样化的堆栈。当然,力图在“多样化的堆栈”和具体的信息平台(如互联网协议栈)之间建立精准的对应关系也是不切实际的。在我看来,重要的只是堆栈平台的基本逻辑:模块化的抽象层及其联合结果。因此,我所勾勒的多样化堆栈是由不同的抽象层所组建的,每一层的目标都是有限的,因为它们只需要为了做好一件事而存在。增强多样性研究的能力不是任何一个具体模块层的职责。这是顶级的目标。只有作为整体的堆栈才需要为思考多样性身份的新颖而实用的方法提供支持。
一个善意的警告:我所呼吁的多样性堆栈跟数字人文之间存在矛盾,而这一矛盾并没有快速解决之道。在所有的人文学领域中,数字人文必须跟各种背景的研究者合作,包括计算机科学家、数据科学家、数字模拟STEM科学家、社会学家、档案管理员、数据记者,以及学术圈以外的,在硅谷或非政府公共服务机构(例如Datakind,[www.datakind.org])的工作者。他们的共同目标是形成一个良性循环,以使多样性研究能带动技术革新,而技术革新又能反过来设计理解和实践多样性的新方法。还有一个警告:这些甚至还不是多样性堆栈中所有需要发展的层级,而只是其中最关键的一些。在我所提出的堆栈中,从底层开始向上论述。然而,为了压缩论点,即使在较低的层级,我也将指出,在实现多样性的技术手段中,低层抽象概念如何向高层进行传递。
一、多语言数字人文
鉴于语言是很多人文学研究的原材料,有关多样性的一个基本低层级问题是多语制。(28)“更低”是一个相对的概念。我不打算讨论更低层级的技术任务,例如统一的字符编码(Unicode character encoding)和光学字符识别(optical character recognition)。这些任务对多样性研究也很重要。例如,从多语言主义的角度来说。数字人文需要协调跨学科的合作,以此来应对跨语种数字研究的技术问题。
2012年的ADHO会议在其征稿启事中强调“促进多语言和多文化”,而会议的特别小组“全球展望”(GO::DH[www.globaloutlookdh.org/])也将此作为多样性问题的核心主题。就像“全球展望”下的“翻译工具包”(Translation Toolkit)小组所说的,“多语言问题的复杂性和敏感性涉及经济不平等、殖民历史和政治因素等更大范围内的问题。这些问题塑造了我们所生存的这个世界以及我们工作的环境”(29)“About: Why a Translation Toolkit?” Global Outlook:: Digital Humanities, go-dh.github.io/translation-toolkit/about.。
今天,数字人文在跨语言工作方面遇到的困难阻碍了多样性所需的比较研究。首先,就像数字人文学者多梅尼科·菲奥蒙特(Domenico Fiormonte)和伊莎贝尔·加林娜·罗素(Isabel Galina Russell)所指出的那样,作为研究对象和专业交流的媒介,数字人文所优先使用的语言(主要是英语)只覆盖了很小的地理范围。它的技术语料库(经常被嵌入工具和编码标准中去)也主要来自英语。这不仅限制了研究的范围,还阻碍了全球数字人文学者的合作,即便是创造性的社会工程和其他解决方案已经被用于一些跨语言的学术活动。例如,GO::DH创造了一个适用于学术会议的翻译工具包。(30)“The Translation Toolkit”, Global Outlook::Digital Humanities, go-dh.github.io/translation-toolkit/.2018年在墨西哥城召开的双语ADHO会议在其征稿启事中推荐了这一工具。(31)“Digital Humanities 2018: ‘Bridges/ Puentes’—Call for Papers”, DH2018, dh2018.adho.org/en/cfp/.
从根本上说,数字人文的一个核心问题是无法同时用多种语言工作,因为数字人文的工具一般都是单语言运行的。例如,虽然文本分析的各种方法在本质上不限定语言,但它们一般在同一时间只能用一种语言进行有意义的工作。这就让比较性研究很难开展。数字人文应该以多语言集合体的方式来工作,以此发展系统化、自动化,以及规模化问题的解决方案,就像詹姆斯·李(James Lee)和保尔·迪雷(Paul Dilley)在他们的项目“挖掘文艺复兴”中对英语和拉丁文档案所做的主题建模(topic modeling)。(32)感谢李(Lee)为我提供了有关这个项目的额外信息。这一工作的目标是将机器学习运用于广泛的、多语言混合的文本集合体。这类集合体需要进行多种文化的比较研究。例如,像美国集合了英语和西班牙语的新闻报道、小说、电视对话和歌词。大卫·米诺(33)Mimno,David,et al,“Polylingual Topic Models”, Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing,vol.2, pp.880-89. Association for Computational Linguistics, dl.acm.org/ citation.cfm?id=1699627.等计算机科学家在《多语言主题模型》(“Polylingual Topic Models”)中所做的研究展示了有效的新技术取向。我们还可以想到的是,谷歌自2016年开始在其翻译平台所使用的神经网络翻译方法将会在未来的某一天允许数字人文采用多语言进行文本分析。这种方法基于各种语言交汇的“中介语”(interlingua)——一种由机器生成的、处于发展初期的、具有过渡性质的语言形式。它是纯粹比较理念(pure comparatism)的产物。(34)有关谷歌神经网络服务中的“中介语”,参见蔻德威(Coldewey)。有关谷歌如何发展其基于神经网络的翻译服务(该服务在2016年取代了原先的旧系统),参见路易斯-柯劳斯(Lewis-Kraus)所写的精彩的长文章。Coldewey, Devin, “Google’s AI Translation Tool Seems to Have Invented Its Own Secret Internal Language”, TechCrunch, (22 Nov. 2016), techcrunch.com/2016/11/22/googles-ai-translation-tool-seems-to-have-invented-its-own-secret-internal-language.Lewis-Kraus, Gideon, “The Great AI Awakening”, The New York Times Magazine, (14 Dec. 2016), www.nytimes.com/2016/12/14/magazine/the-great-ai-awakening.html.
这种努力不仅可以使多样性方面的工作在执行层面取得进展,还能使其概念在更高的抽象层面发生变化。虽然人工智能“中介语”追求的多语言主义并不真正具有“交叉性”或“接触区”(这是由金伯乐·克伦肖(35)Crenshaw, Kimberlé, “Demarginalizing the Intersection of Race and Sex: A Black Feminist Critique of Antidiscrimination Doctrine, Feminist Theory and Antiracist Politics”, University of Chicago Legal Forum, vol. 1989, no. 1, (Dec. 2015), chicagounbound.uchicago.edu/uclf/vol1989/iss1/8.、帕特里夏·希尔·柯林斯(36)Collins, Patricia Hill, Black Feminist Thought: Knowledge, Consciousness, and the Politics of Empowerment, 2nd ed., (Routledge, 2000).和玛丽·路易斯·普拉特(37)Pratt, Mary Louise, “Arts of the Contact Zone”, Profession, (1991), pp. 33-40, JSTOR, www.jstor.org/stable/25595469.等学者最初提出的,有关多样性的具有影响力的概念,后来又被路皮·卡瑞赛(38)Risam, Roopika, “Beyond the Margins: Intersectionality and the Digital Humanities”, Digital Humanities Quarterly, vol. 9, no. 2, (2015), www.digitalhumanities.org/dhq/vol/9/2/000208/000208.html.和埃里克·奥特加(39)Ortega, Élika, “Zonas de Contacto: A Digital Humanities Ecology of Knowledges”, Debates in the Digital Humanities 2019, edited by Matthew K. Gold and Lauren F. Klein, (U of Minnesota P, 2019), dhdebates.gc.cuny.edu/read/untitled-f2acf72c-a469-49d8-be35-67f9ac1e3a60/section/aeee46e3-dddc-4668-a1b3-c8983ba4d70a#ch15.等学者运用于数字人文),它还是显示了有关这些主题的有趣变化。例如,如果将“交叉性”和“接触区”类比为人工智能的人造神经网络的交叉点,人文学科将如何增进对这两个概念的理解?用于图像识别的 “卷积”(convolutional)神经网络,可以是一个特别恰当的例子(也为我转入接下来有关多媒体的讨论提供了便利)。这种神经网络工作原理是依次检测和汇集图像中的特定特征。其中的决定性因素包括神经元的层数(每一层都包含了很多处理节点),以及各层内部和层与层之间的交互作用。这种交互作用为了识别不同的特征而被激活。人文主义的多样性概念是否可以通过与身份节点(identity nodes)的分离层级在识别他人特征时进行的社会文化互动的对比来建立模型?(40)在这种情况下,另一类特别有提示性的神经网络是“生成性对抗网络”(GANs)。它也被用于图像识别。GANs所涉及的两个网络(一个是“生成性的”,另一个是“判别性的”)之间的“对抗性”(adversarial)关系为思考什么是“交叉点”、什么是“接触区”提供了另外的启示。(有关神经网络的介绍,参见“神经网络” “卷积神经网络”以及“生成对抗性网络”。)我还要感谢法宾·欧弗特(Fabian Offert),他正在撰写的博士论文让我认识到图像识别神经网络的“可解释性”(interpretability)对人文学科的意义。神经网络:“Neural Network”, Wikipedia, (20 Mar. 2019, 19:25 UTC), en.wikipedia .org/w/index .php?title=Neural_ network&oldid=888691390.卷积神经网络:“Convolutional Neural Network”, Wikipedia, (21 Mar. 2019, 21:19 UTC), en.wikipedia.org/w/index.php?title=Convolutional_neural_network&oldid =888858225.生成对抗性网络:“Generative Adversarial Network”, Wikipedia, (20 Mar. 2019, 09:18 UTC), en.wikipedia.org/w/index.php?title=Generative_adversarial_network&oldid =888618653.就此,克伦肖使用了一个令人难忘的比喻:人们在不同程度的劣势之下被一个叠一个地堆积在地下室中。(41)Crenshaw, Kimberlé, “Demarginalizing the Intersection of Race and Sex: A Black Feminist Critique of Antidiscrimination Doctrine, Feminist Theory and Antiracist Politics”, University of Chicago Legal Forum, vol. 1989, no. 1, (Dec. 2015), pp. 151-52, chicagounbound.uchicago.edu/uclf/vol1989/iss1/8.(毕竟,如果不幸的确如此的话,我们知道,神经网络已经通过有偏见的人工智能人种和种族人脸识别系统以这种方式进行算法操作了。)换句话说,在对交叉性理论的已有理解之外,人文学科还可以通过借用新的技术范式来发现哪些交叉性模式?(我们注意到,交叉性理论所使用的词汇——例如,支配的“矩阵”和“矢量”——已经是伪数学的[pseudo-mathematical],通过这些方式似乎做好了和技术模型进行对话的准备。(42)有关交叉性理论中的“矩阵”成语,参见,例如,Collins, Patricia Hill, Black Feminist Thought: Knowledge, Consciousness, and the Politics of Empowerment, 2nd ed., (Routledge, 2000), pp. 227-29.有关交叉性理论中的“矢量”,参见,比如说,Ritzer, George, and Jeffrey Stepnisky, Contemporary Sociological Theory and Its Classical Roots: The Basics, 5th ed., (SAGE Publications, 2017), pp.241-43.)反过来说,一旦熟悉了新的技术范式,人文领域的见解又将如何反向加入这些范式,从而对它们造成影响?
二、多媒体数字人文
另一个和多样性有关的低层级问题涉及数字图像和音频。数字人文一直都以文本为中心。原因是多种多样的,包括文本在人文研究领域中具有主导性,在版权法约束下使用文本具有更大的灵活性,以及文本在技术上更容易被跟踪(可以作为离散的符号来被量化和分析)。此外,与同等的图像或音频相比,借助广泛、灵活、细致和开放的分类法(例如,文本编码基础),我们可以对文本材料进行更有力和更大程度上的计算化管理。(43)Iconclass是一个艺术史图像分类系统的例子(www.iconclass.nl/home)。关于图像分类学的出色想法,参见Burford, Bryan, et al, “A Taxonomy of the Image: On the Classification of Content for Image Retrieval”, Visual Communication, vol. 2, no. 2, (June 2003), pp.123-61, doi: 10.1177/1470357203002002001.。对音乐流派或声音效果进行计算机分类的研究包括李、欧吉哈拉(Ogihara)和莫法特(Moffat)等。Li, Tao, and M. Ogihara, “Music Genre Classification with Taxonomy”, Proceedings: (ICASSP ’05): IEEE International Conference on Acoustics, Speech, and Signal Processing, 2005, vol. 5, IEEE, (2005), pp. 197-200. IEEE Xplore Digital Library, doi:10.1109/ICASSP .2005 .1416274.Moffat, David Festus Charles, et al, “Unsupervised Taxonomy of Sound Effects”, Semantic Scholar, Allen Institute for Artificial Intelligence, www .semanticscholar.org/paper/Unsupervised-Taxonomy-of-SoundEffects-Moffat/e44e2f2c60e78b930eb64bdb583654309a9b1af6.
然而,数字人文学者已经开始对人类经验的视听记录进行“远读”(distant reading)。相关项目包括HiPSTAS(口语音频文件的数字化分析digital analysis of spoken-text audio files [blogs.ischool.utexas.edu/hipstas/2012/11/14welcome-to-hiptas])、列夫·曼诺维奇(Lev Manovich)的“直接视觉化”(44)Manovich, Lev, “What Is Visualization?”, Manovich, (2010), manovich.net/index.php/projects/what-is-visualization.(由大量可缩放的图像按照其元数据排列的“图像图表”[image graphs, 20-23]),以及弗雷德里克·布罗代克(Frederic Brodbeck)的“计量电影学”(有关电影“编辑结构、色彩、语言或动作方面的信息……经由提取、分析、转换为图像呈现,这样电影就可以被作为一个整体来观看,并且很容易就能被诠释和比较”)。(45)与布罗代克(Brodbeck)的电影数据分析方法相辅相成的是电影研究中的另一种以数据为中心的方法:专注于电影产业的数据。例如,可参看计量电影学(Kinomatics)的项目(kinomatics.com/)。Brodbeck, Fredreric, “Cinemetrics”, Cinemetrics, cinemetrics.fredericbrodbeck.de/.然而,这一领域有很多新的、高速发展的技术性研究可供数字人文进一步开拓。再次重申,神经网络人工智能,像用于图像识别的人工智能,显示了新的前景。我们可以想象一下将可以识别图像的神经网络运用在对人文和艺术领域非常重要的那些视觉材料上。例如,海因里希·沃夫林(Heinrich Wölfflin)在其作于20世纪早期的深具影响力的著作《艺术史的基本原理》(46)Wölfflin, Heinrich, Principles of Art History: The Problem of the Development of Style in Later Art, Translated by M. D. Hottinger, 1932, (Dover Publications, 1950).中,将“线性的”与“开放式画风的”、“平面的”与“后退的”、“开放的”与“封闭的”风格基于正式的“主题”(motifs)进行比较。沃夫林说:“没有什么比比较两幅画中相似的手臂曲线更具启发的事了(这两幅画分别由波提切利[Botticelli]和洛伦佐·迪·克雷迪[Lorenzo di Credi])所作。锋利的肘部,前臂灵动的线条,手指在胸前放射状张开,每一条线都充满了能量——这就是波提切利。”(47)Wölfflin, Heinrich, Principles of Art History: The Problem of the Development of Style in Later Art, Translated by M. D. Hottinger, 1932, (Dover Publications, 1950),p.2.显而易见,这本书等待着机器学习的再创作,以产生和沃夫林旗鼓相当的观察。
在数字人文领域,和多样性有关的一个具体研究方向可能是在代表不同国家、文化和时代的图像集方面训练机器的学习能力。这样就可以对所描绘的对象(例如,图像中的物体是什么?每一种有多少个体?)的形式结构、色彩模式、透视系统和材料媒介进行比较性的数据分析。目标将是寻找没有被一般艺术史上的西方、东方、非洲、土著等“运动”和“风格”所容纳的图像之间的意外关系。通过将由机器学习发现的图像元数据和图像周围那些在历史文本中被命名和地理标记的实体相联系,而不仅仅是将其与图像分类法相联系,我们还可以进一步发展这类比较工作。人文学领域对“诗如画”(ut pictura poesis)和“文本的图像化再现”(ekphrasis)等“语言-视觉”层面的问题有着悠久的思考传统。通过将识别、分类和注释等方法运用于其中,特别是通过升级这个传统使之将多元性纳入考虑,数字人文还可以为图像的机器学习本身做出贡献。例如,数字人文可以为解决如下问题提供一个历史更久远、文化更多元的基线:对图像的充分文字描述要满足什么特征?(48)关于使用机器学习对图像进行文字标注的计算科学研究的例子,参见Murthy, Venkatesh N., et al, “Automatic Image Annotation Using Deep Learning Representations”, Proceedings of the Fifth ACM on International Conference on Multimedia Retrieval, Association for Computing Machinery, (2015), pp. 603-06. ACM Digital Library, doi: 10 .1145/ 2671188 .2749391.反过来,什么才是对文本的充分视觉化?
然而,如果不能在可缩放的、细微的、灵活的多媒体分析方面取得进一步的进展,数字人文将无法探索能够做到图文并茂的视觉认知(约翰娜·德鲁克[Johanna Drucker]将这种认知称为“视觉认识论”(49)还可参看我在《与古为友》(87-92)中关于“图形知识系统”和“图形知识建模系统”的讨论。Liu, Alan, Friending the Past: The Sense of History in the Digital Age, (U of Chicago P, 2018).),更不用说听觉、触觉、形体表现和其他方面的认知论。(50)Drucker, Johanna, Graphesis: Visual Forms of Knowledge Production, (Harvard UP, 2014), p. 8, MetaLABprojects.因此,完整的文化幅度仍然充满诱惑却难以触及。这包括各个民族的多媒体艺术总集,这些民族在过去和现在最灿烂的文化往往存在于文字以外的领域,例如口头表演、艺术、装饰、音乐和舞蹈。因此,同样地(从这里切换到更高层面的抽象性),有关多样性本质的新想法的潜力仍然有待开发。这些想法伴随着采样、过滤、转换、合成和其他操作方式潜藏在今天的多媒体数字实验室中。例如,如果我们探索混合、均衡或者高斯式模糊(Gaussian blurring)的数字方法——这些方法将提示包容和排斥的另类模式,我们对多样性的理解又会有什么不同?毕竟,当今的多元文化经验有很多来自多媒体音乐、视频和其他混合型表演形式。这些形式在被数字方法输送的同时也被其改变。因此,研究不能只关注它们的效果,还应将它们视为具有概念和社会重要性的、重新混合了多样性的思想。
三、具有代表性的数字人文语料库
在多样性堆栈中,在那些聚焦于文本和视听媒体的层级之上的,是专门用于做采集工作的抽象层级。在互联网协议中,传输层级比底层的互联网层级更抽象,因为它从“数据包”中制造数据“流”。与此相似,采集在多样性堆栈中的层级更高,因为它从媒体中创造语料库和档案(以及,用英联邦或其他运用数字人文的国家的术语来说,就是“遗产”[heritage])。在这一层级上,与多样性有关的关键问题不仅涉及语料的出处和规范性,还关系到它们是否具有代表性。在一个集合中,代表性的各个面向(社会、政治、经济、文化、语言、宗教、种族、民族、性格以及其他)如何做到互相交叉?(51)以下是原材料中有关“代表性”的一些方面,材料取自我正在指导的“4Humanities.org”项目“WhatEvery1Says”(we1s.ucsb.edu/)中用以评估大众如何看待人文学科的新闻和其他话语的语料库:出版的国家和地区、类型(例如报纸或杂志)、媒体(例如报纸、电视或社交媒体),发行量(受众规模)、声明的政治身份,以及自我确认的与一个性别或性群体、宗教、文化遗产或机构部门(例如大学或高等教育行业)的关联。“Bibliography—Corpus Representativeness”, What Every 1 Says, we1s.ucsb.edu/research-resources/we1s-bibliography/bibliography-corpus-representativeness/. (我要感谢阿卑哥尔·多拉吉[Abigail Droge]和林赛·托马斯[Lindsay Thomas]。他们主持创建了这个项目的原数据)。有关在解释的过程中(尤其是在数字人文领域,但同样也存在于“传统”人文学科)如何权衡代表性和消退性的一个深思熟虑的、系统化的方法,参见Tahmasebi, Nina, et al, “A Convergence of Methodologies: Notes on Data- Intensive Humanities Research”, Nina Tahmasebi, tahmasebi.se/publication/2019-aconvergenceofmethods/。有关代表性问题的其他研究,以及语料库或档案中的材料缺失问题,参见“Bibliography—Corpus Representativeness”, What Every 1 Says, we1s.ucsb.edu/research-resources/we1s-bibliography/bibliography-corpus-representativeness/.如何用计算机能够跟踪的方式来注解和衡量这些面向?更进一步说,对于遗失或沉默的档案资料,计算方法如何帮助我们推断出更全面的人类模式?最后,数字化的聚合方式对统计“规范化”(“normalization”)概念(指让不同规模和分布的数据之间具有可比性)的冲击如何影响我们今天有关社会代表性和多样性的“规范”(norms)?这些都是有关多样性和包容性的关键问题在数字人文领域的具体呈现。
虽然看起来这么说似乎是将问题简化了,并且可能引起争议,但我还是建议:数字人文学者的一个必要步骤是跨国家和跨团体的合作。他们需要和档案管理员、社会科学家,以及民族志学者进行磋商,并对国际标准化组织(ISO)、政府、非政府组织(NGO)的人口分类系统进行梳理,以期创建一个能用数字跟踪的、可扩展的多样性分类法。这一分类法能用更通用的本体协议(ontology protocols)来表达或与之建立联系,用于对那些需要对个体和群体进行分类的起源、人物和社会事件研究做出描绘。这种通用协议的例子包括:文本编码规范(TEI)P5准则(尤其是第十三章“姓名、日期、人物和地点”中的“个人特征”部分(52)“Names, Dates, People, and Places”, P5: Guidelines for Electronic Text Encoding and Interchange, version 3.4.0, Text Encoding Initiative, (23 July 2018), www.tei-c.org/release/doc/tei-p5-doc/en/html/ND.html.);公司机构、个人和家庭的档案编码语境(EAC-CPF)模式(eac.staatsbibliothek-berlin.de/);W3C PROV数据模式(53)“PROV- Overview: An Overview of the PROV Family of Documents: W3C Working Group Note”, W3C, (30 Apr. 2013), www.w3.org/TR/prov- overview/.;以及“冲突和调解事件观察”(CAMEO)框架。例如,CAMEO——在国际研究领域兴起的一种描述事件的标准——就包括了一本指定行为者和行动名称的《代码手册》(Codebook)。设计这本手册是为了帮助计算机挖掘和分析与当代政治及军事冲突有关的文本材料(以及和它们有关的事件推动者、行为和地点)。编码手册的“种族编码计划”(或称CAMEOECS),用3个字母的编码将全世界近600个种族群体与其“主要定居国”联系起来进行分类。(54)CAMEO: Conflict and Mediation Event Observations Event and Actor Codebook. Directed by Philip A. Schrodt, version 1.1b3, (Mar. 2012), Computational Event Data System, eventdata.parusanalytics.com/cameo.dir/ CAMEO.Manual.1.1b3.pdf., pp. 111, 113.有关CAMEO和更早的对冲突事件中行为者及行为编码的国际框架,见Gerner, Deborah J., et al, “Conflict and Mediation Event Observations (CAMEO): A New Event Data Framework for the Analysis of Foreign Policy Interactions”, Computational Event Data System, eventdata.parusanalytics.com/papers.dir/gerner02.pdf和Heap, Bradford, et al, “A Joint Human/Machine Process for Coding Events and Conflict Drivers”, Advanced Data Mining and Applications: ADMA 2017, edited by Gao Cong et al, (Springer, 2017), pp. 639-54, doi: 10.1007/978-3-319-69179-4_45。CAMEOECS族裔群体的完整名单见于CAMEO的图5.1(114-30)。根据我的统计(表中的行数没有编号),共有594个群体。CAMEOECS分类法是在认真思考之后创建的。这一思考过程始于查询语言的ISO代码和民族权力关系数据集(CAMEO111-112)。我要感谢司考特·克莱曼(Scott Kleinman)首先将我引至CAMEO。为人文学科调配出一种可扩展的、能被机器所阅读的多样性分类法的努力具有正确的精神导向性(考虑到自我认同和群体的多重认同),可以促进有急切需求的、由数据驱动的多样性研究。否则,彼此之间对“当我们在谈多样性的时候究竟在谈什么”这个问题的不同理解将对此研究造成阻碍。
我们为什么要冒着看起来过于简化并存在争议的风险创建一个多样性分类法?(55)我知道我所建议的以计算为导向的分类方法对多样性学术研究可能造成的风险。在这方面增强分类意识和自主性能带来社会和道德上的积极作用。(例如,参见Terras, Melissa, “On Changing the Rules of Digital Humanities from the Inside”, Melissa Terras’ Blog, 2013, melissaterras.blogspot.com/2013/05/on-changing-rules-of-digital-humanities.html.)但是,如果执行得不好,它也会导致地区、国家和群体之间的分歧,强化那些历史上有权分类和只能被分类的群体之间的权力差,并且在另一些方面造成压迫。(有关告诫性的例子,参见鲍克[Bowker]和斯达[Star]在他们的经典分类学著作《为事物分类》中的“种族隔离下的种族分类和再分类案例”, Bowker, Geoffrey C., and Susan Leigh Star, Sorting Things Out: Classification and Its Consequences,[MIT Press, 1999], pp. 195-225;以及奥斯·凯耶斯[Os Keyes]有关将数据科学运用于同性恋者的“行政暴力”讨论,Keyes, Os, “Counting the Countless: Why Data Science Is a Profound Threat for Queer People”, Real Life,[8 Apr.2019], reallifemag.com/counting-the-countless.)然而,我之所以大胆地提出我的建议,是因为我相信——尤其是在为了WhatEvery1Says项目而通过几百万篇媒体文章和社交媒体发布对公共话语进行研究之后——在数字人文的帮助之下,人文学科能够找到一种方案,将其分类观点贡献给有关多样性的无数分类法。若非如此,这些分类法就只能在流行文化和由国家或组织官僚机构操控的话语中野生发展。这是因为,就像“冲突与调解”(它的首字母缩写是“CAMEO”)框架所指示的那样,如果我们想要收集资料,用以进行有关人类整体模式和社会公正,或者其他相关课题的研究,尤其是需要大数据计算的那类,那么,为那些生活在紧张的、相互交错的关系中的群体命名就是第一步。因为,就像人口普查表或大学申请书上的种族选项一样,生活在多元社会中的人们在现实生活中也在和多样性分类法进行协调。我们需要在复杂的国家和世界的关系网中更好地理解这一分类法。也是因为,在数字人文这一领域内部,对多样性存在着很多可能的国际性的误解。在2013年,詹姆斯·史密发表了一篇博客,题为《回应美国:数字人文后殖民理论的本土化》。作为一个在后殖民讨论中对土著文化感到自豪的新西兰人,史密斯回应了一项开始于美国的,名为“后殖民数字人文”的倡议(#dhpoco[dhpoco.org/])。他反思道:“它并不代表我所理解的后殖民主义,也不代表我所知道的后殖民世界。它的确是一种批评理论,一种很有力量的混合体,融合了身份理论、女性主义、酷儿理论和激进主义政治,但它不是‘我的’后殖民主义。”“适度的本土化是必须的”,史密斯说,“因为我们需要确保我们这个地区的土著人民也能像那些被殖民地区的人民一样参与数字人文,并且在与数字人文接触的过程中充分受益于我们当地的后殖民话语。”
史密斯所说的“本土化”是可扩展的数字人文分类法想要取得的一个目标——一种“多样性可扩展标记语言”(“diversity XML”)。这种语言为特定种类或区域的多样性定义其元素和属性。与之相对的目标则是普遍化:在个人、群体、国家和更大的层面上系统地抽象出多样性概念的能力(一路向上,直至这一模式中最常见的“命名空间”[namespace],即人类)。(56)在计算机科学的意义上,“命名空间”是一个限制着一个特定区域的抽象逻辑范围(虽然它由精确统一的源头或URI所指定)。在该区域内,一个模式或其他协议建立了实体及各种属性的命名惯例。命名空间可以防止惯例之间的碰撞。因此,文本编码协议,例如XML、HTML、TEI这种,都能容纳使具体命名规则得以运作的命名空间的声明。在我的类比中,紧随身份政治而产生的多样性就是一种空间命名(namespacing)。然而,就像在被设计为强调混乱的碰撞和重叠的交叉性理论中那样,这种空间命名有时候会促进而不是防止命名空间之间的碰撞。创建一个能够被共享的、具有透明度的数字人文多样性词汇库——能够为不同的身份元素和属性提供导航的那种——将会更好地定位数字人文,以及一般的人文学科,使其能够介入目前各机构、公司和政府出于自己的目的而使用的多样性分类法。例如,这些分类法可以用以决定谁能移民、如何划分投票选区、选择目标消费者,以及从一般意义上来讲,如何分配各种资源和身份。虽然永远不会出现一种正确的分类法(因为,归根结底,对任何具体的资源和身份的政治经济分配都不具备无可争议的合理性),却可以有多种不同的分类法——或者,更好的是,具有差异性的分类法。
在可扩展的多样性分类学的帮助之下,数字人文可以继续创建计算方法来评估任何材料(或者其他研究对象)中多样性的平衡和结构;(57)例如,阿加门(Argamon)和他的合作者们分解了数据库“黑色戏剧——1850至今”(search.alexanderstreet.com/bld2)中的元数据(包括“姓名、种族、年龄、性别、国籍、民族、职业和性取向”)。就像瑞萨姆(Risam)注意到的那样,他们的研究在方法上实际是交叉性(intersectional)的。他们提出的问题是,“数据库可以做到交叉性吗?”Argamon, Shlomo, et al, “Gender, Race, and Nationality in Black Drama, 1950-2006: Mining Differences in Language Use in Authors and Their Characters”, Digital Humanities Quarterly, vol. 3, no. 2, (2009), www. digitalhumanities.org/dhqdev/vol/3/2/000043/000043.html.Risam, Roopika, “Beyond the Margins: Intersectionality and the Digital Humanities”, Digital Humanities Quarterly, vol. 9, no. 2, (2015), www.digitalhumanities.org/dhq/vol/9/2/000208/000208.html.来代表那些因为被低估、被审查或被删除而缺席的声音(例如,通过数字推理方法);来对具有代表性的语料库这一整体性概念和有关代表性的较早范式,例如“档案”“版本”“经典” 和“语料库语言学”(corpus linguistics,在与语料库相关但又有区别的意义上)进行三边测量。于是,一个“元步骤”(metastep)——在堆栈中要求向更高层级的软件应用传送——就成了创建能提高多样性并促进其评估的工具。这一目标的实现不是通过处理语料库,而是通过处理它们的采集平台:数字存储库系统(就像Samvera[samvera.org/])、“数字资产管理”(DAM)系统,以及“内容管理系统”(CMS)。例如,让我们设想一下,现在出现在CAMEOECS或TEI P5传记研究中的与多样性有关的元数据(例如,“信仰”“语言知识”“国籍”“性别”“年龄”“社会经济情况”“职业”“教育”)(58)参见TEI P5指导方针(“名称”)的13.3.2.1部分(“个人特征”)。改进版本可以作为标准化的运用输入机构的存储库和以数据库为后盾的DAM和CMS系统中去,从而允许创建一个由元数据分析工具和插件组成的完整的二级生态系统,以期根据本身就具有多样性的筛选机制(即有关多样性的看法)来计算多样性的各种方式。之后,这类评估工具可以采用链接数据或API方式来补充人文图像中的缺失元素——例如,通过使用从美国数字公共图书馆(dp.la/)、欧洲馆藏(www.europeana.eu/)或人文基础设施网(HuNi [huni.net.au])获取的材料来自动扩大语料库或者网站。
当然,最终我们可能无法获取一个具有代表性的语料库所需的全部材料,无法就代表性的规范,甚至是分类和组织的基本方案达成共识,也无法就语料库需要权衡或推论的方面达成一致。然而,仅仅只是发明更好的方法,用于申报、跟踪、测量、标准化,然后使用基于多样性的元数据的材料,就会对实现所谓“多样性系统的学术版本”(此术语改编自凯瑟琳·博德的“文学系统的学术版本”[“scholarly editions of a literary system”](59)Bode, Katherine, “The Equivalence of ‘Close’ and ‘Distant’ Reading; or, Toward a New Object for DataRich Literary History”, Modern Language Quarterly, vol. 78, no. 1, (Mar. 2017), pp. 97-102.)这一理想有很大帮助。经过适当的编辑,一个语料库不仅仅能呈现材料的集合,还能让我们看到它是如何被创造、选择、平衡、修正,并转换成社会文化多样性的代表的操作过程。
四、数字人文的时空体
从更高的抽象层级来看,语料库实际上代表的是其所覆盖材料的时间和空间“世界”(worlds)。因此,我所要求的多样性堆栈的下一层就是(用巴赫金的术语来说)改良这些集成世界之后所获得的“时空体”(chronotope),尤其需要的是一种具有数字穿透性和操作性的时空体。它能够以不同的方式切割时间和空间,以预测多样性作为人类经验——例如,季节性农民工的经验——在时间间隔和地缘政治领域的另一种分布。(60)有关“时空体”,参见巴赫金《对话想象力》中的“小说中时间和时空体的形式”。 Bakhtin, M. M., The Dialogic Imagination: Four Essays, Edited by Michael Holquist, translated by Cary Emerson and Holquist, (U of Texas P, 1981), pp. 84-258。为了简单起见,我不考虑这个问题的另一引人入胜的方面:由语料库代表的时空“世界”和机构或组织世界之间的联系。后者由档案馆根据“尊重全宗原则”(respect des fonds)或“按行政机构、组织、个人或产生记录的创造机构对记录进行分组的原则”(J.贝雷 [J. Bailey])。J. 贝雷为数据时代如何“尊重全宗原则”提供了非常精彩的批评性讨论。Bailey, Jefferson, “Disrespect des Fonds: Rethinking Arrangement and Description in Born-Digital Archives”, Archive Journal, (June 2013), web.archive.org/web/20170919162159/http://www.archivejournal.net/essays/ disrespect- des- fonds- rethinking - arrangement-and-description-in-born-digital-archives/.通过类比,我们可以说,就好像话题建模中的“话题”(topic)是一种在一系列文档中的“术语概率分布”(61)Blei, David M, “Topic Modeling and Digital Humanities”, Journal of Digital Humanities, vol. 2, no. 1, (Winter 2012), journalofdigitalhumanities.org/2-1/topic-modeling-and-digital-humanities-by-david-m-blei.,多样性也是一种在历史、人口、法律、经济、政府、新闻、文学及其他数据集等时空体中的“人类概率分布”。这种分布是过去对时空的不公正分配所产生的结果(例如国家领土和签证期限)。就像在一个妥善建构的话题模型中那样,为人类多样性主题进行时空体建模时,我们不应该只是加固既有的刻板印象,而是应该发掘那些有关人们及其代表如何在时空之中栖居的令人惊讶的事儿。
当然,数字人文及其相关领域的很多工作已经聚焦于时空分析。例如,在数字历史、文学研究、地理学和考古学领域中的强势空间研究分支已经使用了诸如制图、地理信息系统(GIS)、激光雷达现场测绘,以及话题建模等方法。(62)主题建模在数字人文中最新颖的应用之一是施密特(Schmidt)将这一方法运用于历史上的捕鲸船日志中的经纬坐标,而不是用于文档集之中的文字(Schmidt, Benjamin M, “When You Have a MALLET, Everything Looks Like a Nail”, Sapping Attention,[2 Nov. 2012], sappingattention.blogspot.com/2012/11/when-you-have-mallet-everything-looks.html )。由这类数据构成的主题模式的“主题”是船舶航行的地理路线(虽然施密特指出这些主题模式也可能具有欺骗性)。这种空间研究处理了可被称之为外部和内部的时空体的二者之一或全部。外部时空体指的是研究涉及的行为主体、事件或工作的实际地理范围,而内部时空体指的是作品内部(包括小说)对地域的指涉和表述,相当于《欧洲文学地图集》所说的“小说地理”(“geography of fiction”)(63)“Mapping and Analysing the Geography of Fiction with Interactive Tools” A Literary Atlas of Europe, (2019), www.literaturatlas.eu/en/.,以及伊丽莎白·F·伊万斯(64)Evans, Elizabeth F., and Matthew Wilkens, “Nation, Ethnicity, and the Geography of British Fiction, 1880-1940”, Journal of Cultural Analytics, (13 July 2018), doi:10.22148/16.024.和马修·威尔肯斯(Matthew Wilkens)所说的“文学地理想象”(the literary-geographic imagination)。在时间研究方面,数字人文同样做出了广泛的、跨学科的努力,尝试改变在人文研究领域可能具有典范性的“时间窗口”(time window)。传统上,日、月、年或几十年,都是研究文化现象的时间间距。但是,回到费南德·布鲁德尔所说的《漫长岁月》(65)Braudel, Fernand, “History and the Social Sciences: The Longue Durée”, On History, translated by Sarah Matthews, (U of Chicago P, 1980), pp. 25-54.,计算机远读将时间窗口开得更宽。在这方面,具有代表性的文学历史研究包括安德尔·哥德斯通和泰德·安德伍德的《文学研究的悄然转变》(66)Goldstone, Andrew, and Ted Underwood, “The Quiet Transformations of Literary Studies: What Thirteen Thousand Scholars Could Tell Us”, New Literary History, vol. 45, no. 3, (2014), pp. 359-84.,以及泰德·安德伍德和乔丹·赛勒斯的《文学声望的长时段》(67)Underwood, Ted, and Jordan Sellers, “The Longue Durée of Literary Prestige”, Modern Language Quarterly, vol. 77, no. 3, (Sept. 2016), pp. 321-44, doi:10.1215/00-267-929-3570634.。在历史学科中,同样地,乔·戈蒂曾经呼吁使用数字人文方法来重新强调“长时段”(68)Guldi, Jo, “Time Wars of the Twentieth Century and the Twenty- First Century Toolkit: The History and Politics of Longue- Durée Thinking as a Prelude to the Digital Analysis of the Past”, Between Humanitiesand the Digital, edited by Patrik Svensson and David Theo Goldberg, (MIT Press, 2015), pp. 253-65.Guldi, Jo, and David Armitage, The History Manifesto, (Cambridge UP, 2014).。与此同时,数字人文的媒体考古学和电子文献认知将时间窗口缩小到伍尔夫甘·恩斯特所谓的计算机“微时空水平”(microtemporal level)(69)Ernst, Wolfgang, “Archives in Transition: Dynamic Media Memories”, Digital Memory and the Archive, edited by Jussi Parikka, (U of Minnesota P, 2012), p. 97.的规模。例如,杰西卡·普拉斯曼,马克·C·麦里诺(Mark C. Marino)和杰瑞密·道格拉斯(Jeremy Douglass)的《阅读项目:威廉·庞德斯通的〈测速仪项目〉合作分析{无底洞}》对一部电子文学作品做出了令人瞩目的阅读,在毫秒级的水平对代码事件进行了深入发掘。(70)Pressman, Jessica, et al. Reading Project: A Collaborative Analysis of William Poundstone’s Project for Tachistoscope {Bottomless Pit}. (U of Iowa P, 2015), pp. 39-40, 128.
然而,尽管数字人文领域已经有这样基于时空的研究,该领域的各个学科分支还没有合作起来,并没有向不是专门采用时空研究方法的学者就如何描述、编辑和分析如下概念提供共同的建议:世界(以及世界体系)、国家、地方、时期、时代、潮流、运动、世代、人生,以及事件。因此,很多数字人文项目对空间和时间的塑造整体上是基于“英国”或“美国”的“19世纪”或“20世纪”作品的。或者说,他们只是接受一些语料库所划定的范围并将其作为时空研究的资料。例如,早期英语书籍在线(EEBO)、18世纪文集在线(ECCO),或者HathiTrust数字图书馆——至多只是通过简单的空间分析(例如,根据出版地或对作品中所提及的地点所做的地理标签)或时间分割(例如,将一个语料库按时代来划分)的方法来调整这种语料库的时空参数。上面提到的许多更细微的时空研究就这样被束之高阁了,还有目前在如下领域更为前沿的研究也是如此:事件建模(例如,卡尔·格罗斯诺的论文“地形时间”(71)Grossner, Karl, “Topotime: Qualitative Reasoning for Historical Time”, Kgeographer, (29 July 2013), kgeographer.com/topotime-qualitative-reasoning-for-historical-time.和“事件中心”(72)Grossner, Karl, “Event Centrality”, Kgeographer, (9 July 2016), kgeographer.com/event-centrality/.)、纵向话题建模(例如,布雷和拉菲提(73)Blei, David M., and John D. Lafferty, “Dynamic Topic Models”, Proceedings of the Twenty-Third International Conference on Machine Learning, ACM, (2006), pp. 113-20. ACM Digital Library, doi: 10 .1145/1143844 .1143859.;王和麦克考伦(74)Wang, Xuerui, and Andrew McCallum, “Topics over Time: A Non-Markov Continuous-Time Model of Topical Trends”, Proceedings of the Twelfth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, ACM, (2006), pp. 424-33. ACM Digital Library, doi:10.1145/1150402.1150450.,王等(75)Wang, Chong, et al, “Continuous Time Dynamic Topic Models”, ArXiv.org, (13 June 2012), arxiv.org/abs/1206.3298.),以及高级的时间线视觉化(例如,克罗伊特里(76)Kräutli, Florian, Visualising Cultural Data: Exploring Digital Collections through Timeline Visualisations, (2016). Royal College of Art, PhD dissertation, Florian Kräutli, www.kraeutli.com/index.php/2016/04/15/visualising-cultural-data.)。
这对多样性的工作很重要,因为空间和时间“如其所是”的整体形式在历史上正是被排斥在多样性的获取之外的。任何一种数字人文研究工作都需要这一领域,以及其他时空研究方面的专家的集合,而对于和多样性相关的研究来说则尤其如此。这种集合能创造一系列的协议、数据文件模板、脚本,以及范例。这种范例受先进的时空研究的启发,专为非时空研究专家的普通数字人文学者设计,帮助这些学者在大的整体时空之下,揭示研究的断层和改变研究的形式,以便欢迎不同的文化进入我们的时空共同体。我们需要一个有关标准的建议。换言之,这个建议需要从根本上声明:为了让你的项目在时空层面具有意义,并且对人们如何栖居于时空之中的理解保持开放,这是你至少要做的四件事。再次重申,“可扩展的标准”(extensible standards)这个概念仍然适用,因为不同规模和种类的时空描述或时空分析只能适用于不同的研究材料。然而,核心的思想仍然是:数字人文将会形成一种对如何发掘一个语料库中的时空信息的共识;利用地理志、档案文献和传记资料对这些信息进行规范化处理;使用机器学习工具推断额外的信息;并对基于上述步骤建立的时空体进行建模和转换。
这就是如何从一开始就将时空体重新想象为可以容纳多样性的时间和空间的整体,而不是在事后追溯,或只将其置于边缘位置。无论是就其对数字人文方法的创新性融合,还是聚焦于多样性时空体而言,詹姆斯·李(James Lee)、布莱尼·格莱特曼(Blaine Greteman)、杰森·李(Jason Lee)和大卫·艾琪曼(David Eichmann)发表于2018年的论文可称为典范。这篇题为《关联性阅读:数字历史主义和有关莎士比亚〈奥赛罗〉的早期现代种族论述》(77)Lee, James Jaehoon, et al, “Linked Reading: Digital Historicism and Early Modern Discourses of Race around Shakespeare’s Othello”, Journal of Cultural Analytics, (25 Jan. 2018), doi:10.22148/16.018.的论文报告了一些项目。这些项目“将主题模型和矢量空间模型嵌入历史书籍的网络中去……以探索提到摩尔人的文本中与种族相关的语言,以及由生产这些文本的书商、印刷者和出版者构成的复杂网络”。特别需要指出的是,这篇论文将早期种族多样性作为对差异性的地理想象来考察,指出“在莎士比亚时代对种族的另类定义中,相对于那些更容易被识别的因素,比如肤色和人体构造,地理和空间变量有着至少是同等的重要性”。
五、身份的数字人文理论
我将和多样性思想有关的、可能是最高级别的抽象层放置在我所建议的多样性堆栈的顶端。这一抽象层不是布拉登的世界堆栈中所谓的“用户”(User),而是当今人文学科就身份(identity)问题所做出的深度考虑。利用多语言和多媒体的材料,以及他们所建构的人文学的时空观念,数字人文学者现在拥有了为我们这个数据科学时代更新有关多样性身份知识的机会。在1900年巴黎世界博览会上的美国黑人展览中(the American Negro Exhibit),W·E·杜·波依斯(W. E. B. Du Bois)和他在亚特兰大大学的团队曾展示过这种多样性身份。通过63种视觉数据,他们报告了黑人群体的情况(这一报告最近在配有精美插图的W·E·杜·波依斯的《资料图谱:视觉化美国黑人——20世纪初的肤色线》[由怀特尼·柏特-柏皮提斯特{Whitney Battle-Baptiste}和布里特·鲁斯特{Britt Rusert}编辑]中再版(78)Du Bois, W. E. B., W. E. B. Du Bois’s Data Portraits: Visualizing Black America—The Color Line at the Turn of the Twentieth Century. Edited by Whitney Battle- Baptiste and Britt Rusert, W. E. B. Du Bois Center at the University of Massachusetts Amherst / Princeton Architectural Press, (2018).)。借助新的资料集、分析方法和视觉化手段,现在数字人文可以继续这类研究,为多样性问题揭晓更多的答案,以及,同样重要的是,为其提供新的研究框架。据推测,数字人文学科或许还可以贡献出有关多元身份的数字人文理论。
在说到“揭晓更多的答案”的时候,我指的是,数字人文正在探索的低层级的多语言、多媒体资料和时空研究将会产生一些新的资料和数据,帮助我们以各种方式确认、调整、扩展或修正学者有关过去和现在的多元文化身份的认识。(79)瑞赛(Risam)调查了一些数字人文的项目,这些项目为多样性提供了“如何通过交叉性视角来研究数字人文的模式”。这些层级(作为对杜·波依斯的“肤色线”[color-line]的即兴发挥)(80)在《黑人的灵魂》(1903)中,杜·波依斯写道:“20世纪的问题是肤色线的问题”。Du Bois, W. E. B. The Souls of Black Folk. Edited by Brent Hayes Edwards, (Oxford UP, 2007), p.3.,将会用实际数据为1990年代文学选集的封面经常使用的“马赛克” “万花筒”和“拼贴画”填补色彩。当时,这些形式就被用来象征多元文化主义。(81)在那个时代,封面上有类似马赛克、万花筒或拼布被子图像的文学“读本”包括Rico, Barbara Roche, and Sandra Mano, editors, American Mosaic: Multicultural Readings in Context, (Hough ton Mifflin, 1991). Walker, Scott, editor, Stories from the American Mosaic. (Graywolf Press, 1990). Perkins, Barbara, and George B. Perkins, editors, Kaleidoscope: Stories of the American Experience. (Oxford UP, 1993).
在说到“提供新的研究框架”的时候,我指的是数字人文能为人文学研究做出的独特甚至很有可能是最独特的贡献:成为负载数据科学和机器学习的理念的渠道,帮助我们重新思考“肤色线”,以及线、边界,或者身份的位置等概念。
例如,从数据科学和机器学习的角度来思考我所概括的多样性堆栈,在每个层级上都需要依赖在高维数学空间中运行的算法。这些都是概念性的空间。在这些空间内,由成百上千甚至更多维度组成的文档集会测算术语使用的频率及其他属性。在它们的相互关系中,这些维度会允许我们对其模式进行统计识别——例如,哪些词汇或文档更倾向于同时出现,哪些更“像”其他词汇或与其他词汇聚合在一起,等等此类。在前文中,我曾提及人工智能机器学习的神经网络。在数字人文领域引发极大兴趣的“词向量”(word embedding)是人工智能在研究高维语言空间方面的一种运用。它使用所谓的浅层神经网络将词与词之间的语义关系建模为“矢量”,在数字空间中根据词汇之间的相对关系进行定位和导向,使那些在语义上作用相当的词能彼此接近。(82)有关词汇嵌入的解释,见Schmidt, Benjamin M, “Vector Space Models for the Digital Humanities.” Ben’s Bookworm Blog, (25 Oct. 2015), bookworm.benschmidt.org/posts/2015-10-25-Word-Embeddings.html.例如,詹姆斯·李和他的合作者们曾将词向量(“矢量空间模型”)作为他们所使用的研究方法之一。他们的论文中有一张词汇在矢量空间中的图表。该图表展现了EEBO在1500年到1623年间的词向量模型,阐释了“肤色”(complexion)如何定义“一种被体貌、体格、忧郁气质、脾气,以及当地的气候所调配的表现形式,而远远不只是不可改变的基因类型”(图2)。(83)李(Lee)和他的合作者们用于创建主题模式和词向量的总语料库包括“来自25363个文本的文档,早期英语书籍在线(EEBO)/文本创造合作关系第一阶段语料库,以及,特别是……EEBO语料库中提到‘Moor’这个单词的所有变体的14708个段落(它们来自3147个文本),包括莎士比亚的戏剧和奥赛罗的版本”。然后,他们根据不同的分析目的将语料库分割成不同的时间范围。“事实上,”作者补充说,“与‘blacke moore’匹配出现的是‘行为’(behavior),而不是和身体或肤色有关的词汇。”
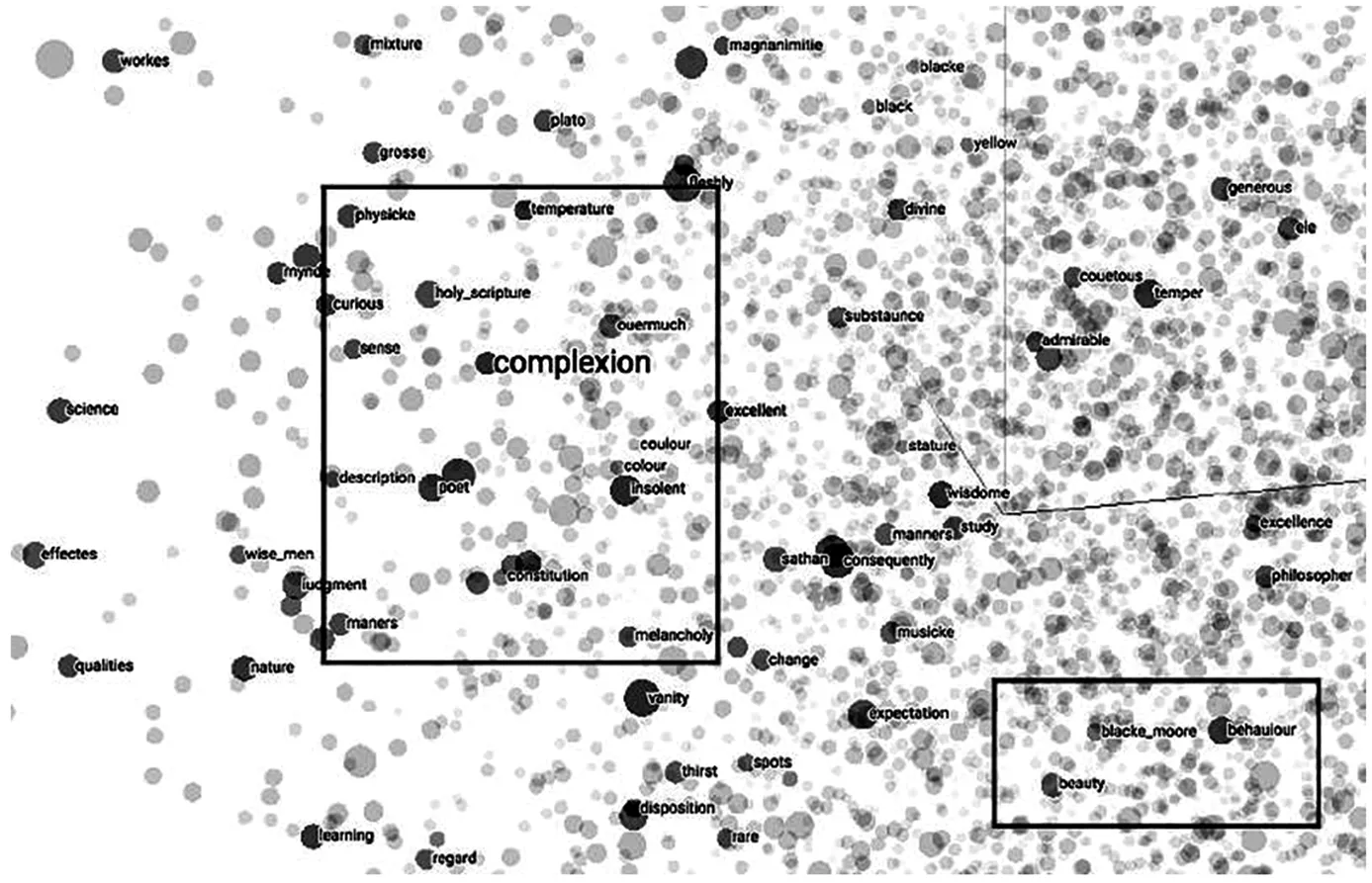
图2 詹姆斯·李等:词向量图知识共享版权归属4.0国际许可证https://creativecommons.org/licenses/by/4.0
这个例子说明,“词向量”模型具有不可思议的能力,能揭露社会上带有歧视的表达背后的文化逻辑。用来解释“词向量”的标准例子是由计算机生成的—— “国王之于皇后,正如男人之于什么”这个问题的答案。基于规范的英语文档,计算机建议的答案是高纬度语义空间中的一个区域,其中最接近的词是“女人”。当然,这是一个显而易见的问题,不需要计算机来解决。然而,在社会话语体系中,有很多不明显或者有争议的语义逻辑,读起来就像是心理分析,触及那些令多样性成为尖锐问题的偏见。数字人文要想摆脱旧式的“大帐篷”模式,转而采用现代的多样性方法,就需要解释——是的,也需要创造比喻——高纬度的数学空间。这样的空间,以及它所跨越的大数据和互联网的所有领域,就是新的“大帐篷”。
模拟空间中的物理线和社会中的肤色线,不是连接就是分割,不是沟通就是隔绝。而与它们都不同,数据线(矢量)在这样的数字人文空间中成为可见的,因此有关身份和多样性的潜在的新概念是天生存在的。而且,数据科学和机器学习通过大量的差分(differencing)和与之对等的查找相似性的方法,在高维空间中分析事物与事物之间的关系——例如,术语频率-逆文档频率(TF-IDF)、余弦相似性、主成分分析(PCA)、分层和分区聚类(30)关于这种类型的类聚,参见莱克斯米克斯(Lexomics)研究组对“类聚分析”的指导。“ClusterAnalysis”,IntheMargins,byScottKleinmanetal.,version35,(19Aug.2016),scalar.usc.edu/works/lexos/cluster-analysis?path=topics.、主题建模、词向量和社会网络分析(包括对后者的向心性、等级、距离、中间性等的度量)。虽然为了能使人类理解这一切,高维的方法必然也是“降维”的方法,但这种降维是根据幕后的各种变换的可能性而制定的,提示了新颖或不确定的思考身份的方式。
总而言之,有一整套适用于交叉性、接触区和其他理念的身份理论,可以启发我们重新提出与多样性有关的问题。例如:你和我一样吗?这一百万份由你所在的团体制作,或有关你所在的团体的文件,是否能代表我所在的团体?或者,甚至于,有没有不同又相似的方法能让我们同时保持差异性和相关性?如果说身份作为堆栈的最高层级,是我之前称之为“分层涌现”(“layered emergence”)的结果,那么,至少在概念层面,我们需要理解将其从堆栈较低层提升上来的差异性和相似性的规律。只有这样,身份才会是像我所说的那样,“不是确定的或可以预测的,并且可以变好也可以变坏。”数字人文的技术目标是挖掘差异性和相似性的规律,以探索那些会影响我们对身份思考的而又出乎意料的结构、趋势和关联。它的核心目标则是帮助人文学科追求更好,而不是更坏的可能性。
毕竟,现在各大企业的网络媒体都在使用大数据算法来审视相似性和差异性(例如,他们的用户“喜欢”什么)。他们这么做是因为他们想要掌握人们的身份,汇总到他们的资料中去。与此同时,一些政府也在审视和相似性及差异性有关的数据(例如,在边境上),用来建构他们版本的档案化的身份,然后用来否定而不是维护这些身份。当代对于差异性和相似性的寻求具有可观的力量,数字人文应该对此进行理论化并善加利用,将其作为自身研究平台的一部分——也就是说,不仅仅是审视,同时也是理解和想象——一个超越了“大帐篷”的、具有更丰富的人性、更多元化的未来。
