基于随机森林与改进极限学习机的PM2.5浓度模型
2020-08-13王鑫圆曹春萍
王鑫圆 曹春萍


摘 要: 由于PM2.5浓度预测中的影响因素过于复杂,影响因素的高维性与非线性对预测结果有着很大的干扰,容易产生PM2.5浓度预测误差高和模型泛化能力差等问题。针对上述缺陷,可通过一种基于随机森林-粒子群优化-极限学习机(RF-PSO-ELM)的PM2.5浓度预测模型解决。该模型首先使用随机森林算法对影响因素进行特征选择,选择出对于PM2.5浓度重要性高的因素构成特征;再利用提取得到的特征作为PSO-ELM算法的输入;最后对上海市的PM2.5浓度做出预测,从最终的实验数据中可以看出:该模型比支持向量机(SVM)、未优化的极限学习机(ELM)和反向神经网络(BPNN)等预测模型在预测精度和泛化能力方面有着显著的提高。
关键词: 极限学习机;随机森林;改进的粒子群优化算法;PM2.5;特征选择
中图分类号: TP39 文献标识码: A DOI:10.3969/j.issn.1003-6970.2020.06.003
本文著录格式:王鑫圆,曹春萍. 基于随机森林与改进极限学习机的PM2.5浓度模型[J]. 软件,2020,41(06):1218+62
【Abstract】: Because the factors affecting the PM2.5 concentration value are too complicated, the high dimensionality and nonlinearity of the influencing factors have a great interference with the final result of the prediction. The performance of the prediction model is prone to problems such as high prediction error of PM2.5 concentration value and poor generalization ability. In view of the above mentioned defects, which can be solved by proposing a PM2.5 concentration prediction model based on random forest-particle swarm optimization-extreme learning machine (RF-PSO-ELM). The model first uses the random forest algorithm to select the influencing factors, selects the characteristics that are important to the PM2.5 concentration, and uses the extracted features as the input of the PSO-ELM algorithm to predict the PM2.5 concentration. The prediction of PM2.5 concentration in Shanghai shows significant improvements that the model is more accurate than the traditional support vector machine (SVM) and unoptimized extreme learning machine (ELM) and back propagation neural network (BPNN) and so on in terms of prediction accuracy and generalization capabilities.
【Key words】: ELM; RF; Improved PSO algorithm; PM2.5; Feature selection
0 引言
近几年,PM2.5浓度过高被认为是大气污染危害的主要成因,其不仅对各行各业的发展造成了阻碍,还会严重危害人们的生活健康。所以,建立完善的PM2.5预测模型显得尤为重要。但是,影响PM2.5浓度的因素繁多,许多复杂的气象因素[1]与多样的空气污染物[2]都对PM2.5浓度有着显著的影响。因此如何选取可信度高的影响因素,建立可靠、高效、泛用性广、泛化能力强的PM2.5浓度预测模型就有着很大的实际意义,这种计算机科学与环境科学的交叉领域是当前机器学习的一个热门研究方向。
多年以来,已经有很多对PM2.5预测的研究成果发表在了众多的论文期刊上。其中比较典型的有多元线性回归(MLR)模型[3]以及差分整合移动平均自回归模型(ARIMA)模型[4],这两种模型易于建立,并且对预测自变量与因变量之间具有强线性相关性的数据有明显的优势。但是缺点也同样明显,以上两种模型在本质上只能捕获线性关系,而不能捕获非线性关系。由于PM2.5的影响因素相当复杂,所以线性模型不能全面理解任何多个输入变量间的相互作用,容易导致模型精度下降。随着机器学习的发展,支持向量机(SVM)和人工神经网络(ANN)在被应用到了许多场景当中,其对非线性数据能有着良好的解释性。张长江等人[5]应用SVM对PM2.5未来一小时的浓度建立了预测模型;Wei Su等人[6]應用了最小二乘支持向量机(LSSVM)建立了日常PM2.5预测模型。SVM在解决小样本和非线性数据方面有着良好的泛化能力,但由于训练样本数量不足,采用的数据样本时间跨度小且数据具有一定的特殊性,其在实际环境中的预测能力值得进一步的研讨。神经网络在预测数据能力方面可以实现非线性的映射,有一定的自学能力和概括能力,被广泛地应用于PM2.5浓度预测中[7]。Yegang Chen[8]在PM2.5浓度预测算法中运用了BP神经网络,具有一定的精度。郑海明等人[9]在预测PM2.5浓度时利用了遗传算法对BP神经网络进行了改进,李晓理等人[10]则通过改进粒子群优化BP_Adaboost神经网络预测PM2.5值。 这些基于BP神经网络的预测方法最大的问题是容易在训练模型时出现过拟合现象,上述文献中的研究虽然能加速神经网络的收敛速度,但都很难达到理想的预测效果,其泛化能力较差,实验精度有待提高。
极限学习机(Extreme Learning Machine)[11]是一种高效的神经网络算法,近年来不断地被应用到了分类、聚类和回归分析的问题当中。由于ELM只需要确定激活函数和隐含层节点后就能快速学习,比起支持向量机(Support Vector Machine)和BP神经网络(back propagation Neural Network)有着更快的训练速度和泛化能力。本文中将极限学习机和粒子群优化算法(Particle Swarm Optimization)相结合,以优化相关参数的方法进一步提高预测效果。先通过随机森林(Random Forest)选择对PM2.5浓度影响程度大的特征值,避免过多的无用特征导致模型预测误差过大;再结合经过粒子群优化算法改进的极限学习机模型对PM2.5浓度进行预测;最后通过实验数据论证本次研究建立的模型有着较强的泛化能力,且在预测性能方面优于其它预测模型。
1 相关技术
在本章节中,我们详细介绍了PM2.5模型建立所需的相关技术。其中包括了随机森林算法、极限学习机算法、改进的粒子群优化算法以及粒子群算法如何优化极限学习机的步骤。
1.1 随机森林
随机森林[12]是一种分类器集合算法,有不容易发生过拟合的优点。它不仅可以用来做分类,也可以做回归预测。同时它也是一种基于Bagging的学习方法,其中的每一棵决策树就是一个分类器,对于一个输入样本,N棵树会有N个分类结果。通过有放回地抽取原始数据产生多个样本子集,之后利用这些样本子集建立多个决策树,最终的结果由决策树组成的随机森林所决定。
随机森林的具体生成过程如下:
(1)从初始训练集中运用boostrap方法随机且有放回地抽取N个新的子样本集,并由这些样本集建立N棵分类回归树。
(2)设样本集的特征维数为M,并设定一个常数m(m<=M),在每棵树的每个节点选取m个特征,计算每个特征含有的信息量,从m个特征中选择最有分类能力的一个特征进行节点分裂。
(3)每棵树都在最大程度上生长,没有剪枝 过程。
(4)所有的树最后整合成为一个随机森林。当处理分类问题时,会根据哪一种分类结果数最多决定最终输出;当使用随机森林建立回归预测时,最终结果由所有树输出的平均值确定。
1.2 极限学习机
极限学习机在人工智能领域得到了广泛应用,它是对传统前馈神经网络的改进,其能够通过一步计算求得输出权值。它的另一大特点就是它可以随机生成从输入层到隐藏层的连接权重和隐藏层的阈值,且设置完后无需再调整;与此同时,因为隐含层和输出层之间的连接权值不需要迭代调整,而是通过解方程组的方式一次性确定,所以比起传统的机器学习算法运算速度更快。ELM的算法原理结构如图1所示。
1.3 改进的粒子群优化算法
粒子群优化算法被是一种优秀的智能优化算法,尤其在解决函数拟合与数值优化问题上有着相当显著的效果。在算法中,所有优化问题的参数寻优解都可以被视为一个粒子,每一个粒子都在一个D维空间中搜索最优解。在定义一个适应度函数之后,我们可以将每个粒子代入进这个函数,得到适应度值,并以此来作为评判粒子优劣程度的标准。
PSO-ELM具体算法流程如下:
(1)设置极限学习机参数。将输入权值设为一个-1到1之间的随机数;阈值设置成一个0到1范围内的随机数。
(2)选择粒子群参数。根据(1)中的参数范围设置粒子的寻优范围,确定种群规模数、最大迭代次数、学习因子c1与c2,惯性权重初始值和粒子维数。
(3)通过粒子信息和样本集得到极限学习机的预测值,根据得到的预测值通过式(8)计算所有粒子的适应度值,进而求出每个粒子的个体极值pbest和群体的全局极值gbest。
(4)对每个粒子的位置与速度迭代更新。在每次迭代完成后,取粒子适应度最小值与之前几次迭代的粒子适应度最小值比较,其中适应度值最低的粒子即为当前的最优参数。
(5)每当迭代更新之后,将优化后的参数传递给ELM。
(6)当迭代循环次数达到设定值时,停止对参数的寻优,得到最佳的ELM参数。
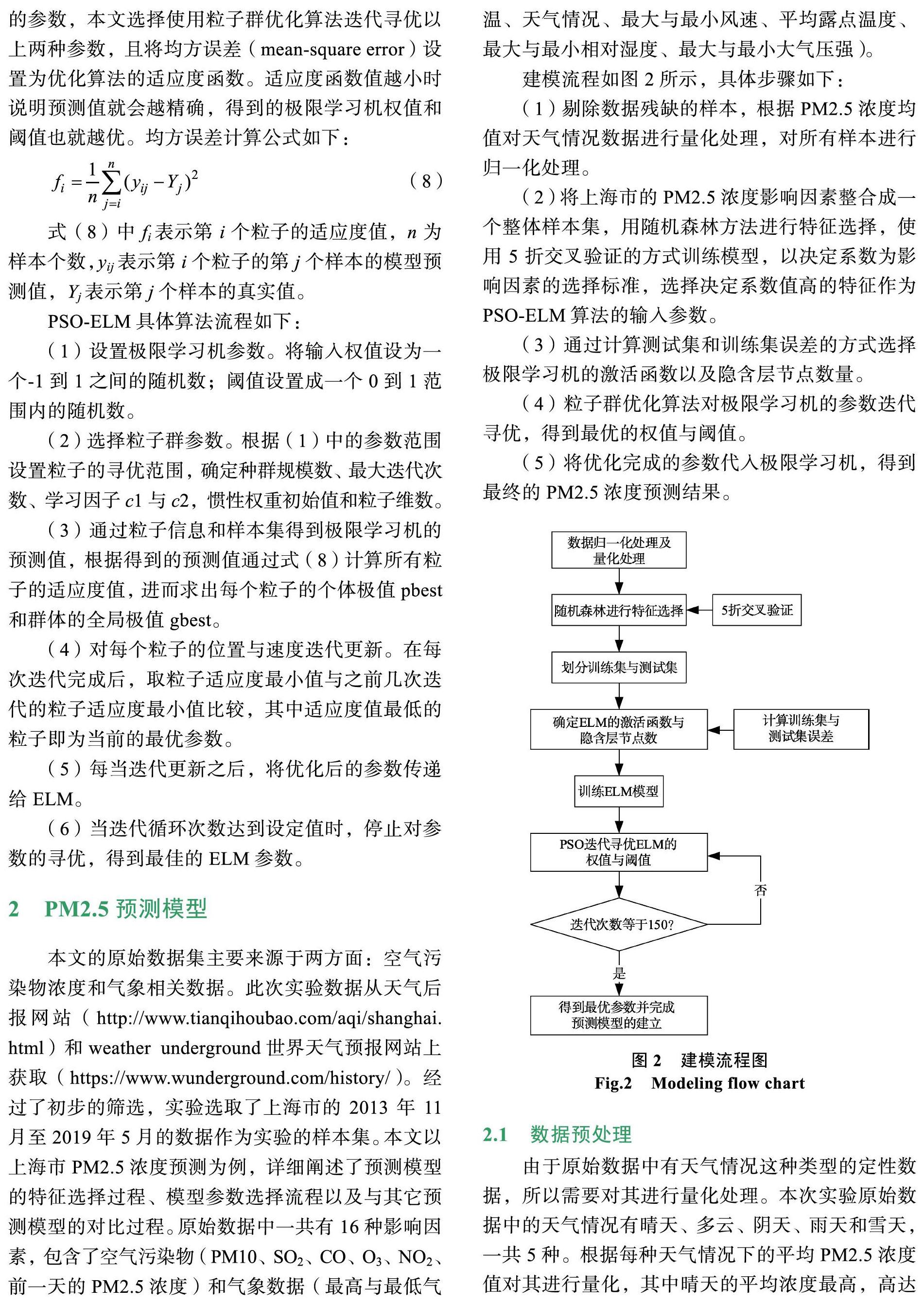
2 PM2.5预测模型
本文的原始数据集主要来源于两方面:空气污染物浓度和气象相关数据。此次实验数据从天气后报网站(http://www.tianqihoubao.com/aqi/shanghai. html)和weather underground世界天气预报网站上获取(https://www.wunderground.com/history/)。经过了初步的筛选,实验选取了上海市的2013年11月至2019年5月的数据作为实验的样本集。本文以上海市PM2.5浓度预测为例,详细阐述了预测模型的特征选择过程、模型参数选择流程以及与其它预测模型的對比过程。原始数据中一共有16种影响因素,包含了空气污染物(PM10、SO2、CO、O3、NO2、前一天的PM2.5浓度)和气象数据(最高与最低气温、天气情况、最大与最小风速、平均露点温度、最大与最小相对湿度、最大与最小大气压强)。
建模流程如图2所示,具体步骤如下:
(1)剔除数据残缺的样本,根据PM2.5浓度均值对天气情况数据进行量化处理,对所有样本进行归一化处理。
(2)将上海市的PM2.5浓度影响因素整合成一个整体样本集,用随机森林方法进行特征选择,使用5折交叉验证的方式训练模型,以决定系数为影响因素的选择标准,选择决定系数值高的特征作为PSO-ELM算法的输入参数。
(3)通过计算测试集和训练集误差的方式选择极限学习机的激活函数以及隐含层节点数量。
(4)粒子群优化算法对极限学习机的参数迭代寻优,得到最优的权值与阈值。
(5)将优化完成的参数代入极限学习机,得到最终的PM2.5浓度预测结果。
2.1 数据预处理
由于原始数据中有天气情况这种类型的定性数据,所以需要对其进行量化处理。本次实验原始数据中的天气情况有晴天、多云、阴天、雨天和雪天,一共5种。根据每种天气情况下的平均PM2.5浓度值对其进行量化,其中晴天的平均浓度最高,高达60微克/立方米,雨天和雪天的平均浓度最低,分别为37微克/立方米、32微克/立方米,多云和阴天的平均浓度值分别为49微克/立方米和42微克/立方米。故而根据以上的分析可以将雪天、雨天、阴天、多云和晴天各自量化为1、2、3、4和5表示。因为此次实验原始数据中的特征有着不同的量纲和量纲单位,为了消除特征之间的量纲影响,减少对实验模型的误差影响,本文对原始数据进行了归一化处理。通过归一化处理能够将各个数据指标处于同一量纲级,此次实验的归一化公式如下:
2.2 特征选择
因为各种各样的气象因素和污染物因素都对PM2.5浓度有着影响,且这些PM2.5影响因素具有一定的高维性,所以如果将全部的PM2.5影响因素都作为预测模型的输入,容易降低预测模型的泛化能力与预测精度,由此可以看出对初始的PM2.5影响因素进行特征筛选尤为必要。本文使用了随机森林算法来选择影响因素,由于原始数据中的影响因素和响应变量之间的关系是非线性的,基于决策树的随机森林算法可以较好地选择出对于PM2.5浓度影响程度高的特征。
此次实验使用单变量选择的方式对PM2.5影响因素进行选取,将每一个PM2.5影响因素与PM2.5浓度值建立随机森林模型,以决定系数作为随机森林模型的评价指标,则可以把决定系数视为PM2.5影响因素对于PM2.5浓度值的影响程度,决定系数的计算公式如下所示:
在选择特征的过程中,运用了5折交叉验证的模型训练方式,其是将整体数据集分解成5份数据集,交替地把其中4份作为训练集、1份作为测试集来训练模型,最后对5次训练的输出(影响系数)取平均值。这样做能提升模型的稳定性,增加特征选择结果的可信度。经过网格搜索算法进行参数寻优后,本次实验将随机森林中决策子树的个数设置为550,每颗树的最大深度设为20,叶子节点最少样本数设为2,决策树的最大特征数为11。
实验根据上文中提到的16种影响因素,以及上海市2013年11月至2018年12月的1866个样本(剔除了原始样本中具有严重数据缺失情况的样本)作为特征选择算法的输入,利用了Python语言进行编程,借助了Pycharm集成开发环境和Scikit-learn机器学习库完成此次实验。表1中的影响系数即为每一个PM2.5影响因素对于PM2.5浓度值的影响程度。各个影响因素的影响系数如表1所示。
从表1中可以看出,原始數据中的16种影响因素对于PM2.5浓度有着不同的影响系数,其中PM10浓度、SO2浓度、NO2浓度、CO浓度等特征有着较高的影响比例;而大气压强、风速、相对湿度等特征的影响比例较小。经过实验后,本文所建立的预测模型选择了影响比例大于0.1的8种特征作为模型的输入变量,选择过程在2.3节中呈现。
2.3 PSO-ELM模型参数的确定
在阅读了相关参考文献之后,此次实验对模型参数设置如下:确定粒子群规模为40;最大迭代次数为150;学习因子c1=c2=2;惯性权重ω最大值设定为0.9、最小值设定为0.4、初始值设定为0.9;由于需要优化的参数有两个,所以粒子维数为2。
为了确定模型的特征个数、激活函数与隐含层节点数,此次实验随机选取经过预处理后的1400组数据作为训练集,466组样本作为测试集,以3∶1的比例分割数据集。
在极限学习机节点数数为10且激活函数为sigmoid函数时,图3展示了影响系数在不同阈值时本文预测模型的均方根误差,故而本次实验选择影响系数大于0.1的8个特征。
假设极限学习机隐含层节点的个数为10个,通过在相同网络复杂度的情况下比较sigmoid函数、sin函数和hardlim函数哪一个更适合本次试验。从表2中可以看出,当隐含层节点数均为10时,sigmoid函数下的模型平均绝对误差为9.93,sin函数和hardlim函数分别为12.71和13.12。由于sigmoid函数在对模型的精度影响方面明显优于其它两种,因此本文选择sigmoid函数作为ELM的激活函数。
隐含层节点的选择一直都是极限学习机建立过程中的关键问题,良好的节点数不但能够降低模型的输出误差,还能够增加模型的泛用性。但是节点数的选择从来不具有一般性,几乎所有的研究都是从主观上或是根据经验公式来决定其数量。本次研究为了能够尽量提升模型的功能与性能,从训练集和测试集的均方根误差两方面来观察节点数量带来的变化。表3即为在不同节点数的情况下,上述两种数据集的均方根误差变化。
从表3中可以得出:隐含层节点数的增加会导致训练集的均方根误差越来越小,并且随着节点数的增大,训练集的均方根误差变化越小;但是,当隐含层节点数为15时,测试集的均方根误差为11.7473,是表3中测试集误差的最小值,之后随着节点数增大其误差反而增加。上述结论表明了隐含层节点的选取并不是值越大越好,对于模型而言会有一个合适的隐含层节点数。为了抑制过拟合现象的发生,本次实验将极限学习机模型的隐含层节点设置为了15。
3 实验结果分析
在完成预测模型的各种参数设置与选取之后,为了证明此次研究建立的模型具有较强的实用意义,本章节对2019年1月至5月的PM2.5浓度进行了仿真预测实验,并且与其它较为成熟的预测算法作出对比。在此之上,实验还进行了模型的泛化能力证明与特征选择的有效性验证。
3.1 PM2.5浓度预测仿真结果对比
本章节用PSO-ELM预测模型与支持向量机、BP人工神经网络和未优化的极限学习机等算法以对上海市2019年1月的PM2.5浓度值预测结果为例。为了证明对比实验的有效性,每一个预测模型的输入特征都经过了随机森林算法的筛选,输入的训练样本也相同,并且做了同样的数据预处理工作。为了能够使预测模型更加具有实用性,预测过程中的前一天PM2.5浓度特征均采用预测值。本次实验将BP神经网络中的隐含层节点设置为6(此情况下误差最小)、最大训练次数为200、学习率为0.1、训练需求精度为10–5并且将激活函数设为sigmod函数;设置SVM类型为epsilon-SVR,选择径向基函数为核函数。采用5折交叉验证优化参数,得到核函数的惩罚系数c=2.5、核函数参数g=0.07且epsilon-SVR损失函数值p=0.01;LSTM(长短期记忆网络)建模方式参照了文献[14];多元线性回归参数使用Scikit-learn中的默认值。对比实验的结果如下。
表4中以相關系数、均方根误差和平均绝对误差阐述了PSO-ELM的优越性。从表中不难得出,经过了粒子群优化算法进行参数寻优的极限学习机比起未经优化的ELM、BP人工神经网络和支持向量机等有着更加好的拟合优度和预测精确性,说明了本次研究的PSO-ELM预测模型有着良好的预测性能,比起传统的极限学习机和其它传统的机器学习预测算法有着更高的实用性。
3.2 模型泛化能力的证明
为了证明本文建立的预测模型有着较高的泛化能力,对不同的月份也有着较好的预测效果。本章节中运用了在3.1节中相同的数据处理方式预测了上海市2019年1月至5月的PM2.5浓度,并且作出了是否使用特征选择算法的对比实验。得到的结果图如下所示。
图7不仅展示了2019年1月至5月的误差数据,还表现出了特征选择的有效性。从图中可以得出结论:经过粒子群算法优化的极限学习机有着较强的泛化能力,对于不同时期的PM2.5浓度都能做出良好的预测效果,且误差范围稳定在一个区间范围内;与此同时,随机森林算法成功地对原始特征集进行了降维处理,其选择的特征能够更好地建立预测模型,有效地增加模型预测精度。
4 结论
数值预测模型的研究是机器学习领域的研究热点,本文提出了基于RF算法特征选择与PSO算法参数优化的ELM预测模型,将其应用于PM2.5浓度值的预测。最终的实验结果表明,RF算法能有效地提取出有用的影响因素,PSO优化算法可以高效地对ELM算法的参数进行寻优,RF-PSO-ELM算法比起传统的数值预测算法SVM、BP人工神经网络等有着更高的预测性能。此次研究比起其它相近研究论文选取的数据更具有普遍性,有着更强的理论指导意义。
与此同时,由于PM2.5浓度影响因素较为广泛,本次的研究过程中尚未考虑具体的日均降雨量与日照时长对PM2.5浓度值的影响;并且在泛化能力证明阶段,对于不同的测试集模型的表现能力略有起伏。日后的研究旨在考虑增加更多的基础特征与如何对模型做出更进一步的优化方法。
参考文献
[1] 徐伟嘉, 朱倩茹, 刘永红, 等. 广州PM_(2.5)污染特征及影响因素分析[J]. 中国环境监测, 2013, 29(2): 15-20.
[2] 鲍孟盈, 曹芳, 刘寿东, 等. 苏州郊区主要大气污染物的演变特征及其影响因素研究[J]. 生态环境学报, 2017, 26(1): 119-128.
[3] 张云云, 朱家明, 高子云, 等. 基于多元线性回归的PM2.5含量的影响因素研究[J]. 西昌学院学报(自然科学版), 2016, 30(1): 17-20.
[4] 彭斯俊, 沈加超, 朱雪. 基于ARIMA模型的PM2.5预测[J]. 安全与环境工程, 2014, 21(6): 125-128.
[5] 张长江, 戴李杰, 马雷鸣. 应用SVM的PM2.5未来一小时浓度动态预报模型[J]. 红外与激光工程, 2017, 46(2): 245-252.
[6] Sun W, Sun J. Daily PM2.5 concentration prediction based on principal component analysis and LSSVM optimized by cuckoo search algorithm [J]. Journal of Environmental Management, 2017, 188(1): 144-152.
[7] Fabio B, Marcella B, Marco V, et al. Recursive neural network model for analysis and forecast of PM10 and PM2.5 [J]. Atmospheric Pollution Research, 2017, 8(4): 652-659.
[8] Chen Ye-gang. Prediction algorithm of PM2.5 mass concentration based on adaptive BP neural network[J]. Computing, 2018, 100(8): 825-838.
[9] 郑海明, 商潇潇. 基于GA-BP神经网络大气中PM2.5软测量研究[J]. 计量学报, 2014, 35(6): 621-625.
[10] 李晓理, 梅建想, 张山. 基于改进粒子群优化BP_Adaboost神经网络的PM2.5浓度预测[J]. 大连理工大学学报, 2018, 58(3): 99-106.
[11] Huang Guang-Bin, Zhu Qin-yu, Chee-Kheong Siew. Extreme learning machine: Theory and applications[J]. Neurocomputing, 2006, 70(1-3): 489-501.
[12] Breiman L. Random Forests[J]. Machine Learning, 2001, 45(1): 5-32.
[13] Zheng Qin,Fan Yu,Zhewen Shi, et al. Adaptive Inertia Weight Particle Swarm Optimization[C]//Proceedings of the 8th international conference on Artificial Intelligence and Soft Computing. Springer Berlin Heidelberg, 2006: 450-459.
[14] 白盛楠, 申晓留. 基于LSTM循环神经网络的PM2.5预测[J]. 计算机应用与软件, 2019, 36(1): 67-70.
[15] 陈芳. 小型智能化车载PM2.5检测系统[J]. 软件, 2018, 39(2): 164-165.
[16] 陈婕, 金馨. 基于极限学习机的锂电池健康状态预测[J]. 软件, 2018, 39(2): 191-196.
[17] 苏志同, 汪武珺. 基于随机森林的煅烧工艺参数的研究和分析[J]. 软件, 2018, 39(4): 148-150.
[18] 赵乃刚. 惯性权重动态调整的混沌粒子群算法[J]. 软件, 2016, 37(3): 01-03.
[19] 崔仁桀. 数据挖掘在学生专业成绩预测上的应用[J].软件, 2016, 37(01): 24-27.
